机器学习深版09:贝叶斯网络
机器学习深版09:贝叶斯网络
文章目录
- 机器学习深版09:贝叶斯网络
-
- 1. 复习
-
- 1. 信息熵(熵)
- 2. 交叉熵
- 3. 相对熵(KL散度)
- 4. 互信息
- 5. 信息增益
- 6. 概率三公式
- 7. 金条问题
- 2. 朴素贝叶斯
-
- 以文本分类为例
- 3. 贝叶斯网络
-
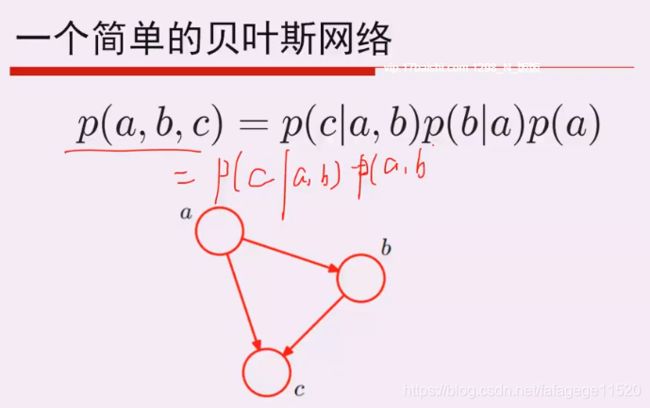
- 一个简单的贝叶斯网络
- 全连接贝叶斯网络
- 正常的贝叶斯网络
- 实际案例分析
- 特殊的贝叶斯网络
- 其他解释说明
- 4. 马尔科夫模型
- 5. 实际代码
-
- 1. 鸢尾花
-
- 1. Pipeline
- 2. np.stack
- 3. array.flat
- 4. matplotlib
- 5. meshgrid、pcolormesh方法的学习
- 2. 文本数据的处理流程-20个类别的新闻组数据
-
- 1.数据采集
- 2. print和pprint两者的区别
- 3. Sklearn中CountVectorizer,TfidfVectorizer详解
-
- CountVectorize:
- TfidfVectorizer:
- 4. 模型调参利器 gridSearchCV(网格搜索)
- 3. Word2Vec
-
- 1. 引言
- 2. one-hot encoding
- 3. 词嵌入的理论基础
- 4. word2vec模型的初始结构
1. 复习
1. 信息熵(熵)
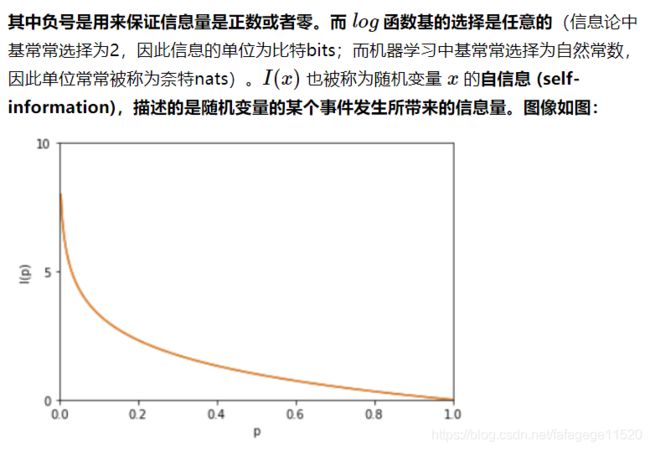
**一条信息的信息量大小和它的不确定性有直接的关系。**我们需要搞清楚一件非常非常不确定的事,或者是我们一无所知的事,就需要了解大量的信息。相反,如果我们对某件事已经有了较多的了解,我们就不需要太多的信息就能把它搞清楚。所以,从这个角度,我们可以认为,信息量的度量就等于不确定性的多少。


2. 交叉熵

3. 相对熵(KL散度)

相对熵就是回答以上的问题,它给出了两个分布之间的差异程度的量化,也就说相对熵代表的是这个两个分布的“距离”。
4. 互信息




如果随机变量独立,那么互信息是多少呢?应该是0,这意味着,知道事实Y并没有减少 X的信息量,这是符合直觉的因为独立本来就是互不影响的。

5. 信息增益
说“互信息”的时候,两个随机变量的地位是相同的;说“信息增益”的时候,是把一个变量看成减小另一个变量不确定度的手段。但其实二者的数值是相等的。
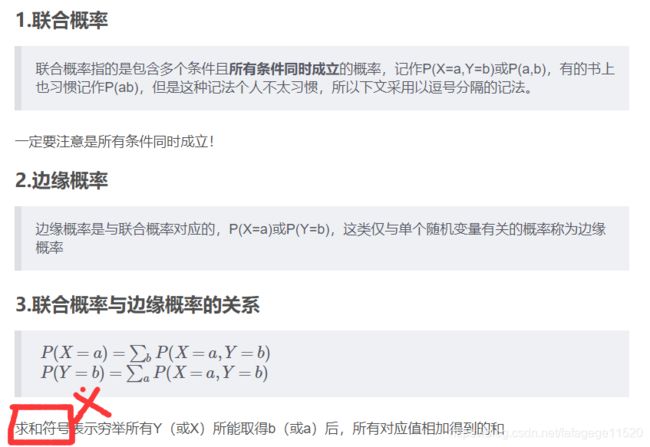
6. 概率三公式

7. 金条问题
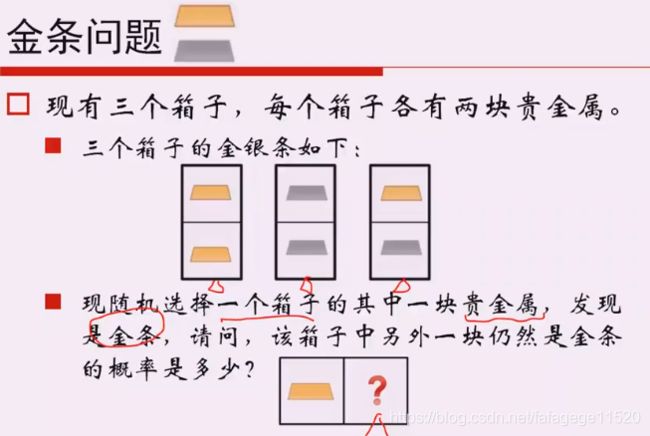
答案是2/3
就是一个条件概率
2. 朴素贝叶斯



以文本分类为例




3. 贝叶斯网络

PGM概率图模型:分类:1.无向图:Markov Network 2. 有向图:Bayesian Network

一个简单的贝叶斯网络
全连接贝叶斯网络

正常的贝叶斯网络

实际案例分析

但是不一定全是这种离散的情况。
只考虑父节点不考虑爷节点之类的。

特殊的贝叶斯网络

其他解释说明

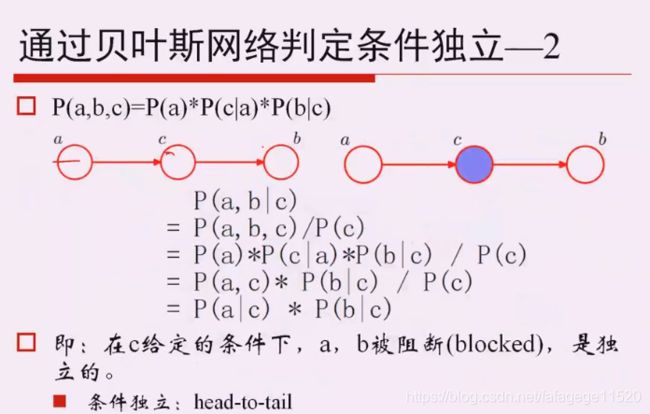

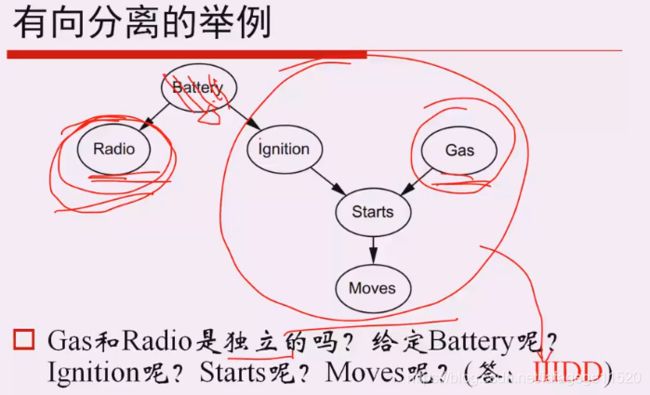
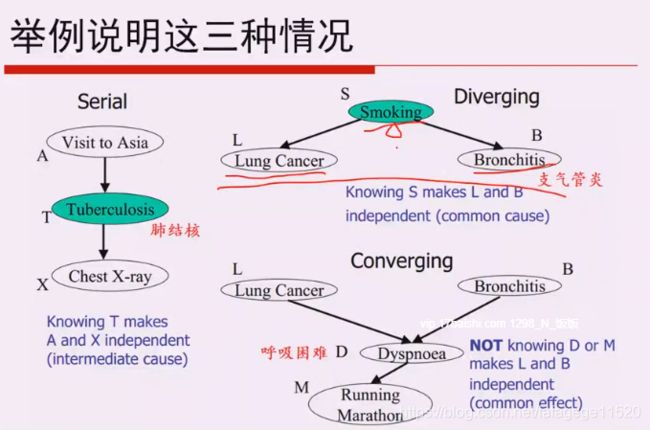
真正的理解这个公式的意义。
4. 马尔科夫模型
暂时不仔细研究,估计会在后面的HMM学习中提到。
5. 实际代码
1. 鸢尾花
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
from sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures
from sklearn.naive_bayes import GaussianNB, MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
if __name__ == "__main__":
data = pd.read_csv('..\\Regression\\iris.data', header=None)
x, y = data[np.arange(4)], data[4]
y = pd.Categorical(values=y).codes
# pd.Categorical( list ).codes 这样就可以直接得到原始数据的对应的序号列表,通过这样的处理可以将类别信息转化成数值信息
print(y)
feature_names = u'花萼长度', u'花萼宽度', u'花瓣长度', u'花瓣宽度'
features = [0,1] # 可以换
x = x[features]
print(x)
x, x_test, y, y_test = train_test_split(x, y, train_size=0.7, random_state=0)
# random_state就是一个随机的意思
priors = np.array((1,2,4), dtype=float)
print(priors)
priors /= priors.sum()
# 管道,详见上文
gnb = Pipeline([
('sc', StandardScaler()),
('poly', PolynomialFeatures(degree=1)),
('clf', GaussianNB(priors=priors))])
# 由于鸢尾花数据是样本均衡的,其实不需要设置先验值
# gnb = KNeighborsClassifier(n_neighbors=3).fit(x, y.ravel())
gnb.fit(x, y.ravel()) # y.ravel()将多维数组转变为一维数组
y_hat = gnb.predict(x)
print('训练集准确度: %.2f%%' % (100 * accuracy_score(y, y_hat)))
y_test_hat = gnb.predict(x_test)
print('测试集准确度:%.2f%%' % (100 * accuracy_score(y_test, y_test_hat))) # 画图
N, M = 500, 500 # 横纵各采样多少个值
x1_min, x2_min = x.min() # !!!一开始以为这俩是一样的值后来发现对应不同的列
x1_max, x2_max = x.max()
print(x1_min)
print(x2_min)
t1 = np.linspace(x1_min, x1_max, N) # 用来创建等差数列
t2 = np.linspace(x2_min, x2_max, M)
x1, x2 = np.meshgrid(t1, t2) # 通过前面的等差数列生成网格采样点(此处很玄乎)
print(x1.shape) # (500,500)
print(t1.shape) # (500,)
print(x1.flatten().shape) #(250000,)
x_grid = np.stack((x1.flat, x2.flat), axis=1) # 测试点
print(x_grid.shape) # (250000, 2)
print(x_grid)
mpl.rcParams['font.sans-serif'] = [u'simHei']#设置字体为SimHei显示中文
mpl.rcParams['axes.unicode_minus'] = False #设置正常显示字符
cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF']) #见plt的第二行
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_grid_hat = gnb.predict(x_grid) # 预测值
print(y_grid_hat.shape)
y_grid_hat = y_grid_hat.reshape(x1.shape)
print(y_grid_hat.shape)
plt.figure(facecolor='w')
plt.pcolormesh(x1, x2, y_grid_hat, cmap=cm_light) # 预测值的显示
plt.scatter(x[features[0]], x[features[1]], c=y, edgecolors='k', s=50, cmap=cm_dark)# 画点点子
plt.scatter(x_test[features[0]], x_test[features[1]], c=y_test, marker='^', edgecolors='k', s=120, cmap=cm_dark)
plt.xlabel(feature_names[features[0]], fontsize=13)
plt.ylabel(feature_names[features[1]], fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(u'GaussianNB对鸢尾花数据的分类结果', fontsize=18)
plt.grid(True)
plt.show()

1. Pipeline



举例:

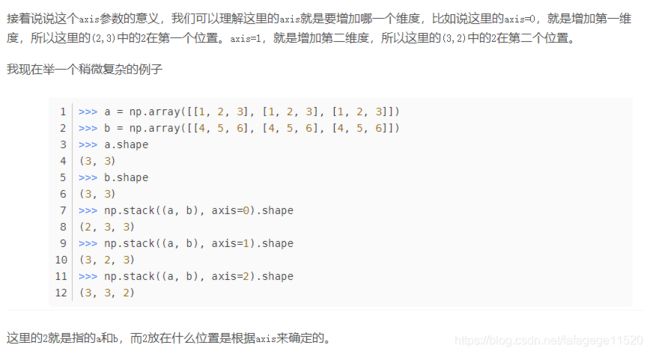
2. np.stack
本文为转载,原博客地址:https://blog.csdn.net/qq_17550379/article/details/78934529


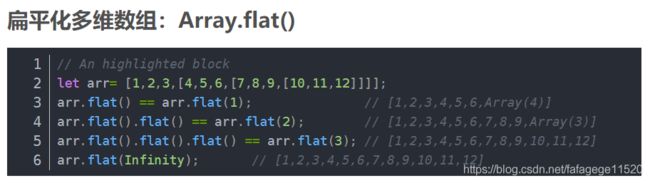
3. array.flat
4. matplotlib
import numpy as np
import matplotlib.pyplot as plt
###%matplotlib inline #jupyter可以用,这样就不用plt.show()
#生成数据
x = np.linspace(0, 4*np.pi)
y = np.sin(x)
#设置rc参数显示中文标题
#设置字体为SimHei显示中文
plt.rcParams['font.sans-serif'] = 'SimHei'
#设置正常显示字符
plt.rcParams['axes.unicode_minus'] = False
plt.title('sin曲线')
#设置线条样式
plt.rcParams['lines.linestyle'] = '-.'
#设置线条宽度
plt.rcParams['lines.linewidth'] = 3
#绘制sin曲线
plt.plot(x, y, label='$sin(x)$')
plt.savefig('sin.png')
plt.show()
5. meshgrid、pcolormesh方法的学习


2. 文本数据的处理流程-20个类别的新闻组数据
独立同分布(iid,independently identically distribution)在概率统计理论中,指随机过程中,任何时刻的取值都为随机变量,如果这些随机变量服从同一分布,并且互相独立,那么这些随机变量是独立同分布。
# 文本数据的处理流程-20个类别的新闻组数据
# MultinomialNB、BernoulliNB、KNeighborsClassifier、RidgeClassifier、RandomForestClassifier分类器及调参
%matplotlib inline
import numpy as np
from sklearn.naive_bayes import MultinomialNB, BernoulliNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from time import time
from pprint import pprint
import matplotlib.pyplot as plt
import matplotlib as mpl
def test_clf(clf):
print(u'分类器:', clf)
alpha_can = np.logspace(-3, 2, 10)
model = GridSearchCV(clf, param_grid={'alpha': alpha_can}, cv=5)
m = alpha_can.size
if hasattr(clf, 'alpha'):
model.set_params(param_grid={'alpha': alpha_can})
m = alpha_can.size
if hasattr(clf, 'n_neighbors'):
neighbors_can = np.arange(1, 15)
model.set_params(param_grid={'n_neighbors': neighbors_can})
m = neighbors_can.size
if hasattr(clf, 'C'):
C_can = np.logspace(1, 3, 3)
gamma_can = np.logspace(-3, 0, 3)
model.set_params(param_grid={'C':C_can, 'gamma':gamma_can})
m = C_can.size * gamma_can.size
if hasattr(clf, 'max_depth'):
max_depth_can = np.arange(4, 10)
model.set_params(param_grid={'max_depth': max_depth_can})
m = max_depth_can.size
t_start = time()
model.fit(x_train, y_train)
t_end = time()
t_train = (t_end - t_start) / (5*m)
print( u'5折交叉验证的训练时间为:%.3f秒/(5*%d)=%.3f秒' % ((t_end - t_start), m, t_train))
print( u'最优超参数为:', model.best_params_)
t_start = time()
y_hat = model.predict(x_test)
t_end = time()
t_test = t_end - t_start
print(u'测试时间:%.3f秒' % t_test)
acc = metrics.accuracy_score(y_test, y_hat)
print (u'测试集准确率:%.2f%%' % (100 * acc))
name = str(clf).split('(')[0]
index = name.find('Classifier')
if index != -1:
name = name[:index] # 去掉末尾的Classifier
if name == 'SVC':
name = 'SVM'
return t_train, t_test, 1-acc, name
if __name__ == "__main__":
print( u'开始下载/加载数据...')
t_start = time()
# remove = ('headers', 'footers', 'quotes')
remove = ()
categories = 'alt.atheism', 'talk.religion.misc', 'comp.graphics', 'sci.space'
print(categories)
# 可以注意一下这种赋值方式
# categories = None # 若分类所有类别,请注意内存是否够用
data_train = fetch_20newsgroups(subset='train', categories=categories, shuffle=True, random_state=0, remove=remove)
data_test = fetch_20newsgroups(subset='test', categories=categories, shuffle=True, random_state=0, remove=remove)
t_end = time()
print( u'下载/加载数据完成,耗时%.3f秒' % (t_end - t_start))
print (u'数据类型:', type(data_train))
print (u'训练集包含的文本数目:', len(data_train.data))
print (u'测试集包含的文本数目:', len(data_test.data))
print (u'训练集和测试集使用的%d个类别的名称:' % len(categories))
categories = data_train.target_names
pprint(categories)
y_train = data_train.target
y_test = data_test.target
print(u' -- 前10个文本 -- ')
for i in np.arange(10):
print( u'文本%d(属于类别 - %s):' % (i+1, categories[y_train[i]]))
print (data_train.data[i])
print ('\n\n')
vectorizer = TfidfVectorizer(input='content', stop_words='english', max_df=0.5, sublinear_tf=True)
x_train = vectorizer.fit_transform(data_train.data) # x_train是稀疏的,scipy.sparse.csr.csr_matrix
x_test = vectorizer.transform(data_test.data)
print(u'训练集样本个数:%d,特征个数:%d' % x_train.shape)
print(u'停止词:\n',)
pprint(vectorizer.get_stop_words())
feature_names = np.asarray(vectorizer.get_feature_names())
print(u'\n\n===================\n分类器的比较:\n')
clfs = (MultinomialNB(), # 0.87(0.017), 0.002, 90.39%
BernoulliNB(), # 1.592(0.032), 0.010, 88.54%
KNeighborsClassifier(), # 19.737(0.282), 0.208, 86.03%
RidgeClassifier(), # 25.6(0.512), 0.003, 89.73%
RandomForestClassifier(n_estimators=200), # 59.319(1.977), 0.248, 77.01%
SVC() # 236.59(5.258), 1.574, 90.10%
)
result = []
for clf in clfs:
a = test_clf(clf)
result.append(a)
print('\n')
result = np.array(result)
time_train, time_test, err, names = result.T
time_train = time_train.astype(np.float)
time_test = time_test.astype(np.float)
err = err.astype(np.float)
x = np.arange(len(time_train))
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 7), facecolor='w')
ax = plt.axes()
b1 = ax.bar(x, err, width=0.25, color='#77E0A0')
ax_t = ax.twinx()
b2 = ax_t.bar(x+0.25, time_train, width=0.25, color='#FFA0A0')
b3 = ax_t.bar(x+0.5, time_test, width=0.25, color='#FF8080')
plt.xticks(x+0.5, names)
plt.legend([b1[0], b2[0], b3[0]], (u'错误率', u'训练时间', u'测试时间'), loc='upper left', shadow=True)
plt.title(u'新闻组文本数据不同分类器间的比较', fontsize=18)
plt.xlabel(u'分类器名称')
plt.grid(True)
plt.tight_layout(2)
plt.show()
分类器的比较:
分类器: MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
5折交叉验证的训练时间为:0.540秒/(5*10)=0.011秒
最优超参数为: {'alpha': 0.003593813663804626}
测试时间:0.004秒
测试集准确率:89.58%
分类器: BernoulliNB(alpha=1.0, binarize=0.0, class_prior=None, fit_prior=True)
5折交叉验证的训练时间为:0.862秒/(5*10)=0.017秒
最优超参数为: {'alpha': 0.001}
测试时间:0.009秒
测试集准确率:88.54%
分类器: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
5折交叉验证的训练时间为:4.213秒/(5*14)=0.060秒
最优超参数为: {'n_neighbors': 3}
测试时间:0.193秒
测试集准确率:86.03%
分类器: RidgeClassifier(alpha=1.0, class_weight=None, copy_X=True, fit_intercept=True,
max_iter=None, normalize=False, random_state=None,
solver='auto', tol=0.001)
5折交叉验证的训练时间为:7.214秒/(5*10)=0.144秒
最优超参数为: {'alpha': 0.001}
测试时间:0.002秒
测试集准确率:89.28%
分类器: RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=None, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
5折交叉验证的训练时间为:27.850秒/(5*6)=0.928秒
最优超参数为: {'max_depth': 9}
测试时间:0.147秒
测试集准确率:77.16%
分类器: SVC(C=1.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
5折交叉验证的训练时间为:170.046秒/(5*9)=3.779秒
最优超参数为: {'C': 100.0, 'gamma': 0.03162277660168379}
测试时间:1.795秒
测试集准确率:90.10%

1.数据采集
那么这里最重要的就是这个fetch_20newsgroups方法了,下面我们来详细讲解
##函数原型是这样的。
fetch_20newsgroups(data_home=None,subset='train',categories=None,shuffle=True,random_state=42,remove=(),download_if_missing=True)
data_home指的是数据集的地址,如果默认的话,所有的数据都会在’~/scikit_learn_data’文件夹下.
subset就是train,test,all三种可选,分别对应训练集、测试集和所有样本。
categories:是指类别,如果指定类别,就会只提取出目标类,如果是默认,则是提取所有类别出来。
shuffle:是否打乱样本顺序,如果是相互独立的话。
random_state:打乱顺序的随机种子
remove:是一个元组,用来去除一些停用词的,例如标题引用之类的。
download_if_missing: 如果数据缺失,是否去下载。
2. print和pprint两者的区别

print打印时加u的含义:u:表示unicode字符串
3. Sklearn中CountVectorizer,TfidfVectorizer详解
词袋法:不考虑词语出现的顺序,每个出现过的词汇单独作为一列特征,这些不重复的特征词汇集合为词表,每一个文本都可以在很长的词表上统计出一个很多列的特征向量, 如果每个文本都出现的词汇,一般被标记为 停用词 不计入特征向量。
主要有两个api来实现 CountVectorizer 和 TfidfVectorizer
CountVectorizer:只考虑词汇在文本中出现的频率,属于词袋模型特征。
TfidfVectorizer: 除了考量某词汇在文本出现的频率,还关注包含这个词汇的所有文本的数量。能够削减高频没有意义的词汇出现带来的影响, 挖掘更有意义的特征。属于Tfidf特征。
CountVectorize:
CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。
CountVectorizer会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数。

CountVectorizer类的参数很多,分为三个处理步骤:preprocessing、tokenizing、n-grams generation.
一般要设置的参数是:ngram_range,max_df,min_df,max_features,analyzer,stop_words,token_pattern等,具体情况具体分析
ngram_range:例如ngram_range(min,max),是指将text分成min,min+1,min+2,…max 个不同的词组。比如 ‘我 爱 中国’ 中ngram_range(1,3)之后可得到’我’ ‘爱’ ‘中国’ ‘我 爱’ ‘爱 中国’ 和’我 爱 中国’,如果是ngram_range (1,1) 则只能得到单个单词’我’ ‘爱’和’中国’。
max_df:可以设置为范围在[0.0 1.0]的float,也可以设置为没有范围限制的int,默认为1.0。这个参数的作用是作为一个阈值,当构造语料库的关键词集的时候,如果某个词的document frequence大于max_df,这个词不会被当作关键词。如果这个参数是float,则表示词出现的次数与语料库文档数的百分比,如果是int,则表示词出现的次数。如果参数中已经给定了vocabulary,则这个参数无效。
min_df:类似于max_df,不同之处在于如果某个词的document frequence小于min_df,则这个词不会被当作关键词。
max_features:默认为None,可设为int,对所有关键词的term frequency进行降序排序,只取前max_features个作为关键词集。
analyzer:一般使用默认,可设置为string类型,如’word’, ‘char’, ‘char_wb’,还可设置为callable类型,比如函数是一个callable类型。
stop_words:设置停用词,设为english将使用内置的英语停用词,设为一个list可自定义停用词,设为None不使用停用词,设为None且max_df∈[0.7, 1.0)将自动根据当前的语料库建立停用词表。
token_pattern:过滤规则,表示token的正则表达式,需要设置analyzer == ‘word’,默认的正则表达式选择2个及以上的字母或数字作为token,标点符号默认当作token分隔符,而不会被当作token。
decode_error:默认为strict,遇到不能解码的字符将报UnicodeDecodeError错误,设为ignore将会忽略解码错误,还可以设为replace,作用尚不明确。
binary:默认为False,一个关键词在一篇文档中可能出现n次,如果binary=True,非零的n将全部置为1,这对需要布尔值输入的离散概率模型的有用的。
其他参数详细参考:https://blog.csdn.net/weixin_38278334/article/details/82320307
# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['我 爱 中国 中国','爸爸 妈妈 爱 我','爸爸 妈妈 爱 中国']
# corpus = ['我爱中国','爸爸妈妈爱我','爸爸妈妈爱中国']
vectorizer = CountVectorizer(min_df=1, ngram_range=(1, 1)) ##创建词袋数据结构,里面相应参数设置
features = vectorizer.fit_transform(corpus) #拟合模型,并返回文本矩阵
print("CountVectorizer:")
print(vectorizer.get_feature_names()) #显示所有文本的词汇,列表类型
print(vectorizer.vocabulary_) #词汇表,字典类型
print(features) #文本矩阵
print(features.toarray()) #.toarray() 是将结果转化为稀疏矩阵
print(features.toarray().sum(axis=0)) #统计每个词在所有文档中的词频

在上面可以看到一些词语它会因为出现的很频繁自动忽略不统计
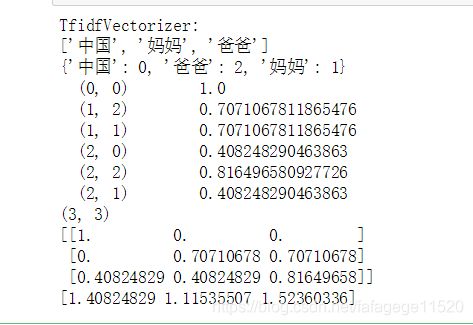
TfidfVectorizer:
什么是TF-IDF
TF-IDF(term frequency-inverse document frequency)词频-逆向文件频率。在处理文本时,如何将文字转化为模型可以处理的向量呢?TF-IDF就是这个问题的解决方案之一。字词的重要性与其在文本中出现的频率成正比(TF),与其在语料库中出现的频率成反比(IDF)。
TF为某个词在文章中出现的总次数。为了消除不同文章大小之间的差异,便于不同文章之间的比较,我们在此标准化词频:TF = 某个词在文章中出现的总次数/文章的总词数。越大说明该词在本篇文章中出现的次数多。
IDF为逆文档频率。逆文档频率(IDF) = log(词料库的文档总数/包含该词的文档数+1)。 越大说明包含该词的文章数目很少,该词很重要。
为了避免分母为0,所以在分母上加1。
TF-IDF值 = TF * IDF。

# -*- coding: utf-8 -*-
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['我 爱 中国 中国','爸爸 妈妈 爱 我','爸爸 爸爸 妈妈 爱 中国']
# corpus = ['我爱中国','爸爸妈妈爱我','爸爸妈妈爱中国']
print("TfidfVectorizer:")
vectorizer = TfidfVectorizer(min_df=1,
norm='l2',
smooth_idf=True,
use_idf=True,
ngram_range=(1, 1))
features = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names()) #显示所有文本的词汇,列表类型
print(vectorizer.vocabulary_) #词汇表,字典类型
print(features) #文本矩阵,得到tf-idf矩阵,稀疏矩阵表示法
print(features.shape) #(3, 3)
print(features.toarray()) #.toarray() 是将结果转化为稀疏矩阵
print(features.toarray().sum(axis=0)) #统计每个词在所有文档中的词频
4. 模型调参利器 gridSearchCV(网格搜索)
在机器学习模型中,需要人工选择的参数称为超参数。
1,为什么叫网格搜索(GridSearchCV)?
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。这两个名字都非常好理解。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。
GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,他要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。
2,什么是Grid Search网格搜索?
Grid Search:一种调参手段;穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。其原理就像是在数组里找到最大值。这种方法的主要缺点是比较耗时!
所以网格搜索适用于三四个(或者更少)的超参数(当超参数的数量增长时,网格搜索的计算复杂度会呈现指数增长,这时候则使用随机搜索),用户列出一个较小的超参数值域,这些超参数至于的笛卡尔积(排列组合)为一组组超参数。网格搜索算法使用每组超参数训练模型并挑选验证集误差最小的超参数组合。
3. Word2Vec
1. 引言
在聊 Word2vec 之前,先聊聊 NLP (自然语言处理)。NLP 里面,最细粒度的是 词语,词语组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀。
举个简单例子,判断一个词的词性,是动词还是名词。用机器学习的思路,我们有一系列样本(x,y),这里 x 是词语,y 是它们的词性,我们要构建 f(x)->y 的映射,但这里的数学模型 f(比如神经网络、SVM)只接受数值型输入,而 NLP 里的词语,是人类的抽象总结,是符号形式的(比如中文、英文、拉丁文等等),所以需要把他们转换成数值形式,或者说——嵌入到一个数学空间里,这种嵌入方式,就叫词嵌入(word embedding),而 Word2vec,就是词嵌入( word embedding) 的一种。




2. one-hot encoding
one-hot encoding(独热编码)认为,语料中的type(这里使用这个单词的目的是避免混淆,type的意思是词汇表中的一个词语)构成了一个离散的取值空间,我们可以用一个长度为词汇表大小的向量来表示一个type,除了这个type的位置为1,其余位置全都为0——这样就得到了一个type的独热编码。
具体是怎么做的呢?我们假设语料不大,里面只有4个type:
我,人,中国,是
用4维向量来表示他们:

有了词语的编码,我们就可以基于这份编码去表示文本了。假设我们有一篇文档:
我是人。
分词后得到的结果是:
我/是/人/。
基于独热编码的文本表示就是:
[1,0,0,0]+[0,0,0,1]+[0,1,0,0]=[1,1,0,1]
这样,我们就把文本表示成了一个长度为词汇表大小的向量,接下来就可以进行聚类或者分类了。这其实就是词袋模型。
缺点:
1.现在我们经常会面对巨大的词汇表,动不动就是上百万个type,必须做细致的特征工程,把维度降下来,要不然再好的机器也算不过来。
2.独热编码的另一个重要缺陷,就是忽略了词语在文本中的顺序。自然语言文本实际上是一种序列数据,相邻的文字或者词语之间有着密切的关联。独热编码的假设过于粗暴,将这种关联省略了,导致了信息的丢失。直白地讲,独热编码里没有语义信息。
3. 词嵌入的理论基础
英语中有一句俗语:
You shall know a person by the company it keeps.
这与《孔子家语》中的一句话含义相同:“不知其人视其友”。如果我们知道了一个人周围有什么样的朋友,也就可以推测出这个人是什么样的人了——如果两个人有着在一些方面相似的朋友圈,那么这两个人就在某些方面是相似的。推荐系统中常用的协同过滤也是基于这个道理。
如果两个词语具有相似的语境,那么这两个词语就有着相似的语义。这就是词嵌入技术的理论基础。
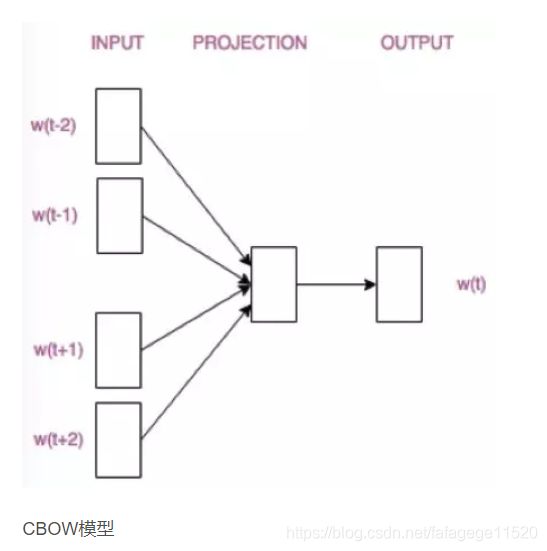
4. word2vec模型的初始结构
我们把一个词语的上下文(前面k个词语和后面k个词语)词语编码输入神经网络,而神经网络的输出,是这个词语的编号,那么,这个神经网络是一个分类器,可以基于上下文来猜出当前词语。
word2vec模型其实就是简单化的神经网络。

输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。
Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。