论文:Mask R-CNN
论文:https://arxiv.org/abs/1703.06870
代码:原配、pytorch 1、pytorch 2
更多 目标检测
更多 图像分割
回顾 Faster R-CNN
Faster R-CNN 包括两个阶段:
- 第一阶段:称为区域提议网络(RPN),提出候选目标边界框。
- 第二阶段:本质上是Fast R-CNN,使用 RoIPool 从每个候选框中提取特征,并进行分类和边界框回归。
这两个阶段使用的特征可以共享,以更快地进行推断。
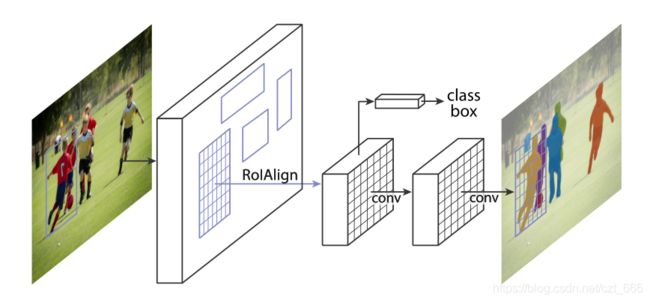
Mask R-CNN
Faster R-CNN对每个候选目标有两个输出,一个类标签和一个边界框偏移量;为此,我们添加了第三个分支输出目标 Mask Mask。Mask R-CNN 包括两个阶段:
- 第一阶段:RPN
- 第二阶段:预测类、边框偏移和二进制 Mask
损失函数
在训练过程中,将每个采样 RoI 上的多任务损失定义为 L = L c l s + L b o x + L m a s k L = L_{cls}+ L_{box}+ L_{mask} L=Lcls+Lbox+Lmask 。
分类损失 L c l s L_{cls} Lcls 和边界框损失 L b o x L_{box} Lbox 与 Faster R-CNN 中定义的相同。** Mask 分支对 K 个分辨率为 m × m 的二进制 Mask 进行编码,每个 Mask 对应K个类。为此,我们应用了逐像素的sigmoid,并定义 L m a s k L_{mask} Lmask 为平均二元交叉熵损失。对于与ground-truth class k相关的RoI, L m a s k L_{mask} Lmask 只定义在第k个 Mask 上**(其他 Mask 输出不会造成损失)。
我们 对 L m a s k L_{mask} Lmask 的定义允许网络为每个类生成 Mask ,而不存在类之间的竞争;我们依赖于专用的分类分支来预测用于选择输出 Mask 的类标签。这就解耦了 Mask 和类预测。这不同于将 FCNs 应用于语义分割时的常见做法,后者通常使用逐像素的softmax和多项式交叉熵损失。在这种情况下,不同类的 Mask 相互竞争;在我们的例子中,对于逐像素的sigmoid和二进制损失,它们没有。实验表明,该方法是获得良好的实例分割结果的关键。
Mask 表示
Mask 对输入目标的空间布局进行编码。因此,不同于类标签或盒偏移量不可避免地被全连接(fc)层压缩成短的输出向量,提取 Mask 的空间结构可以通过卷积提供的像素到像素对应来自然解决。具体来说,使用 FCN 从每个 RoI 中预测出一个 m × m Mask 。这允许 Mask 分支中的每一层保持 m × m 目标的明确空间布局,而不将其折叠成缺乏空间维度的向量表示。与以往依靠fc层进行 Mask 预测的方法不同,我们的全卷积表示需要的参数更少,实验证明更准确。这种像素到像素的行为要求我们的RoI特征(它们本身是小的特征映射)很好地对齐,以忠实地保持显式的像素空间对应。这促使我们开发以下在 Mask 预测中起关键作用的RoIAlign层。
RoIAlign
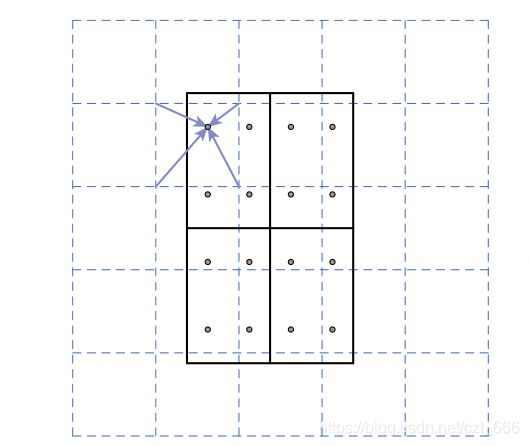
RoIPool 是从每个RoI中提取小特征图(例如7×7)的标准操作。RoIPool首先将一个浮点的RoI量化为 feature map 的离散粒度,然后将量化后的RoI再细分为空间盒,这些空间盒本身也被量化,最后将每个bin覆盖的特征值进行聚合(通常采用最大池化方法)。量化,例如在连续坐标x上计算[x/16],其中16是feature map stride,[·]是四边形;同样地,在划分为箱子(例如7×7)时也会执行量化。这些量化引入了感兴趣区域和提取的特征之间的偏差。虽然这可能不会影响分类,鲁棒变化很小,但它对预测像素精确的 Mask 有很大的负面影响。
为了解决这个问题,我们提出了一个RoIAlign层,它可以去除RoIPool的粗糙量化,正确地将提取的特征与输入对齐。我们提出的改变很简单:我们避免对RoI边界或盒子进行任何量化(即,我们使用x/16代替[x/16])。我们使用双线性插值计算每个 RoI 盒中4个定期采样位置的输入特征的准确值,并将结果汇总(使用max或average),具体见下图。我们注意到,只要不执行量化,结果对精确的采样位置或多少点被采样不敏感。
网络架构:为了演示我们的方法的通用性,我们用多个架构实例化了Mask R-CNN。为了清晰起见,我们区分了以下两种类型:
- 用于整个图像特征提取的卷积主干架构
- 用于边界框识别(分类和回归)和 Mask 预测的网络头,分别应用于每个RoI。
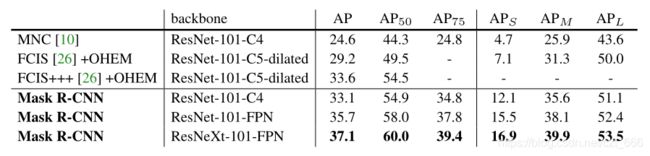
我们用网络深度特征(network-depth-features)来表示骨干架构。我们评估深度为50或101层的ResNet和ResNeXt网络。使用 ResNets 的 Faster R-CNN 最初的实现是从第4阶段的最后一个卷积层中提取特征,我们称之为C4。例如,ResNet-50的主干被表示为ResNet-50- c4。
FPN(特征金字塔网络)采用自顶向下的体系结构,通过横向连接从单一规模的输入构建网络内特征金字塔。Faster R-CNN 采用 FPN 骨架,根据特征金字塔的规模从不同层次提取RoI特征。使用 ResNet-FPN 骨干与 Mask RCNN 进行特征提取,在准确性和速度方面都有很好的提高。
FPN 融合低层次和高层次的特征。
对于网络头,我们密切遵循前面工作中提出的架构,我们添加了一个完全卷积 Mask 预测分支。具体来说,我们从 ResNet 和 FPN 论文中扩展了Faster R-CNN 边框头。详细信息如下图所示。在ResNet- c4主干上的头包括ResNet的第5阶段(即9层的“res5”),这是计算密集型的。对于FPN,主干网已经包含了res5,因此允许使用更少过滤器的更高效的磁头。
我们注意到 Mask 分支有一个简单的结构。更复杂的设计有提高性能的潜力,但不是本工作的重点。

Implementation Details
我们根据现有的Fast/Faster R-CNN工作设置超参数[12,36,27]。虽然在原始论文[12,36,27]中,我们对目标检测做出了这些决定,但我们发现我们的实例分割系统对这些决定是鲁棒的。
训练:就像在Fast R-CNN中一样,如果一个RoI是正的,那么它的底色盒子至少是0.5,否则就是负的。 Mask 丢失Lmaskis仅定义在正的路由。 Mask 目标是RoI与其相关联的ground-truth Mask 之间的交集。
我们采用以图像为中心的[12]训练。图像被调整大小,使其比例(较短的边缘)为800像素[27]。每个小批处理每个GPU有2张图像,每个图像有N个采样的roi,正的[12]与负的[12]的比例为1:3。C4主干的N为64(如[12,36]),FPN为512(如[27])。我们在8个gpu上训练(有效的小批量大小是16)160k次迭代,学习速率为0.02,在120k次迭代时降低了10。我们用0。0001的重量衰减和0。9的动量。使用ResNeXt[45],我们用每个GPU 1张图像和相同的迭代次数进行训练,初始学习率为0.01。
RPN锚跨5个尺度和3个高宽比,紧随[27]。为了方便消融,RPN是单独训练的,除非有特别说明,否则不与Mask R-CNN共享特征。对于本文中的每个条目,RPN和Mask R-CNN有相同的主干,所以它们是可共享的。
推论:在测试时,C4主干的建议编号是300(如[36]),FPN的建议编号是1000(如[27])。我们对这些建议运行框预测分支,然后运行非最大抑制[14]。然后将 Mask 分支应用到得分最高的100个检测盒上。尽管这与训练中使用的并行计算不同,但它加快了推理速度并提高了准确性(由于使用了更少、更准确的roi)。 Mask 分支可以根据每个RoI预测tk Mask ,但我们只使用第k个 Mask ,其中k是分类分支预测的类。然后将m×m浮点 Mask 输出调整为RoI大小,并在阈值0.5处进行二值化。
请注意,因为我们只在前100个检测框上计算 Mask ,所以 Mask R-CNN给对应的更快的R-CNN增加了较小的开销(例如,在典型的模型上,约占20%)。