复旦黄萱菁:顶会也喜欢“搞事情”文章,提示学习等已成为NLP领域的研究重点...
导读:近年来,顶会投稿数量稳步增长,一些热门会议甚至出现投稿数破万的情况,“顶会热”成为AI领域关注的话题。同时,预训练模型等技术快速发展,推动着NLP领域的范式变革。
进入2022年,NLP研究者需要关注哪些重点领域?而AI顶会又该如何发展,解决面临的诸多挑战?近日,智源社区采访了复旦大学教授黄萱菁,请她介绍近期的研究热点。在2022年智源大会(报名链接:https://2022.baai.ac.cn/)上,黄萱菁老师将在自然语言处理论坛上做主题演讲。

黄萱菁,复旦大学计算机科学系教授。1998年获得复旦大学计算机科学博士学位,2008年至2009年在美国麻省大学阿默斯特分校智能信息检索中心(CIIR)做访问学者。她的研究兴趣包括自然语言处理、信息检索、人工智能和深度学习等,在重要会议和期刊上发表了130多篇论文。她还将《现代信息检索》第二版翻译成中文。在研究界,她是EMNLP 2021、CCL 2019、NLPCC 2017、CCL 2016、SMP 2015和SMP 2014的程序主席,NLPCC2020的联合总主席,WSDM 2015的组织者,CIKM 2014的竞赛主席,并参与了近期WSDM、SIGIR、WWW、CIKM、ACL、IJCAI、KDD、EMNLP、COLING等会议的组织等工作。

01
关注创新、完善制度:国际AI顶会带来的启发
2021年,黄萱菁老师担任EMNLP程序主席。智源社区就顶会相关的话题与黄老师交流。
1.顶会趋向:讲究方向的多样性,也喜欢“搞事情”研究
问及顶会论文的研究话题,黄萱菁表示,近年来预训练模型成为顶会投稿中的人们研究领域,甚至有一些顶会的最佳论文给了预训练模型。但是顶会更讲究的是研究方向的多样性。在模型规模逐渐增大的同时,如果能够实现规模不变的情况下,如何做性能的调优等。
她说:“我们还是挺喜欢‘搞事情’(的文章),比如说同一届会议,有人说大模型怎么怎么好,但还有人能够找出一些证据,说明大模型怎么耗能,并非真正理解语言的含义,我们肯定很开心。”
从2021到2022年,每年顶会上流行的方法都会有变化。2022年,提示学习在顶会论文中大量出现,但2021年的比例比较低。此外,顶会也会鼓励研究者探索关注较少的领域,如模型分析和可解释性、人工智能伦理等。顶会也会关注语言学理论、认知科学、认知语言学等重要领域,让这些领域的文章被更多人看到。而对于渐进式创新(Incremental)的研究,顶会可能会更加从严审稿。
2.双管齐下解决投稿过多问题:完善制度、活用技术
近年来,顶会投稿热不减。继CVPR202投稿数破万后,ICLR2021投稿数量也超过万份,以至于组委会不得不将录取率降低10%。
面对投稿数大幅增长而审稿人不足的问题。黄萱菁认为应该采用制度设计+技术辅助结合的众包方式解决。例如,在顶会投稿的研究者,也需要参与审稿工作,但给投稿文章分配审稿人时,也会采用技术手段——用黄老师的话来说:“用人工智能技术来办人工智能会议。”
以去年的EMNLP为例,组委会准备了一个9000人的审稿人池,其中包括会议投稿者和往年的审稿人。然后设定审稿人的权威度、资深度指标,并根据其论文发表情况,结合其职业生涯记录、职位等,来评判该审稿人的级别。此外,也会结合一些NLP的技术,比如Embedding等,为审稿人和投稿计算Embedding的相似度,确保审稿人的专业知识和文章匹配。
同时,顶会也采用了数据挖掘的方式,如根据Google Scholar上的信息记录,判断审稿人的学术圈情况,尽量保证文章给没有利害冲突的审稿人审校。
此外,为了避免出现“本科生审稿人”的情况,虽然所有投稿作者都是潜在的审稿人,但会议会要求作者填写调查表,包括学历、以往的发表情况和Google Scholar的记录等,保证审稿人有过发表的经验。在这些措施的帮助下,平均每位审稿人的审稿数量在3-4篇左右,不算太重的负担。
当然,即使能够增加很多审稿人,也会出现部分审稿人不能按时交稿、需要紧急找人Review的情况。为了从根本上解决投稿数量过多的问题,顶会主办方提出了很多新颖的方法。
从去年起,EMNLP组委会启动了先导计划,采用ACL Rolling Review(ARR)审稿系统,该系统采用OpenReview作为审稿平台,但不会公开审稿意见。论文作者可以在每个月的15日前,将论文提交到ARR的审稿池中,由Action Editor(AE)处理,并且允许论文修改后重新提交(与期刊编辑提出反馈后修改类似),这样的审稿能够留下修改的轨迹,避免作者被拒后立刻转投其他会议,从而降低了每个顶会收到的投稿数量。

图注:ARR系统
将不同质量的稿件进行分流,转投其他渠道也是近年来顶会正在探索的思路。从去年开始,EMNLP组委会推出了Findings的发表渠道,对于论文质量不错、实验结果扎实,但创新性或其他方面略有差距的稿件,可以推荐作者通过Findings发表。尽管Findings不算主会,但也可以被认可为正式出版物。
由于Findings是一个软性Offer,作者可以选择接受或者不接受。黄萱菁表示,从近年来的经验看,80%-90%的作者都会接受,这样能够减少存留的稿件数量。
还有一种方式是将审稿和顶会录用本身分开。例如对一篇文章在审稿阶段进行打分,高分可以投向顶会,分数相对较低但满足要求的,可以投向级别稍低一点的会议或Workshop等其他的渠道。由于文章具有时效性,越早录用越好,这种分流的方式也能够较大程度减少留存。
3.办好国内顶会,需要时间积累成熟
什么时候我国才会有NeuralPS级别的顶会?黄萱菁介绍了很多国际顶会方面的经验。
一是在规章制度方面,顶会的主办方都会预备一套完整的流程文档(Wiki等),例如ACL有一本非常厚的会议手册。在出现情况时,组织者都可以查阅规章制度,寻找解决方案。二是设立专门的指导委员会,在应对学术不端、行为不端等情况时,可以通过组委会指导,直接向相关机构报告问题。
三是设立涵盖全球各区的程序主席。例如2021 EMNLP组委会就同时设立了三位程序主席,横跨美洲、欧洲和亚洲,能够解决一些紧急情况。最后,顶会也会积极招募志愿者,能够帮助主办方节省很多的精力。黄萱菁认为,这需要时间慢慢积累经验,逐渐走向成熟。

图注:2021年EMNLP设置的三位程序主席(Program Chairs,PC)
当然,她认为国内的会议也有很多值得推广的地方。例如国内主办的会议,会相对“人性化”一些,在对参会者的生活和非正式交流方面,照顾得比国际顶会好。
在多样性方面,AI顶会还可以有很多探索的地方。例如2021 EMNLP在加勒比海岛国多美尼加举办,采用线上线下结合的形式。除了主管论文的区域主席外,还设立了很多委员会,主办了很多有趣的活动,如学生研讨活动、面向女性的自然语言处理、非洲自然语言处理等,通过建立各种各样的小社区,提升会议的包容性,让大家活跃起来。
02
NLP领域的新趋势:提示学习、Seq2seq,及其他
去年,黄萱菁老师的团队公开了论文“Paradigm Shift in Natural Language Processing”( https://arxiv.org/pdf/2109.12575.pdf),其中谈到了NLP领域的范式转变。

图注:论文中关注的范式转变
论文中发现:“(1)近年来范式转变的频率正在增加,尤其是在预训练语言模型(PTM)出现之后。为了充分利用这些 PTM 的力量,更好的方法是将各种 NLP 任务转为 PTM 擅长的范式。(2) 越来越多的 NLP 任务已经从 Class、SeqLab、Seq2ASeq 等传统范式转向更通用、更灵活的范式:(M)LM、Matching、MRC 和 Seq2Seq。”
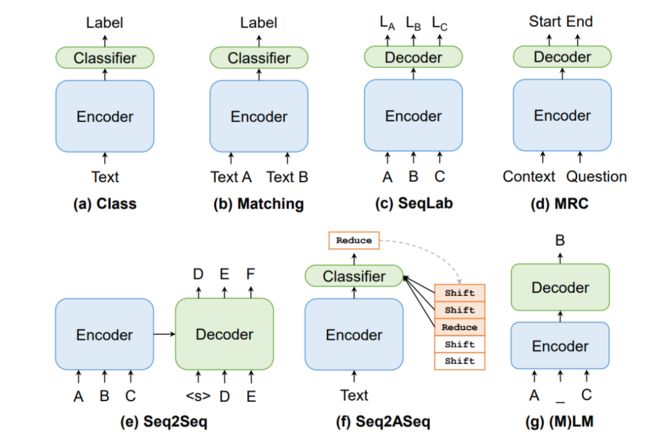
采访中,黄萱菁以提示学习(Prompt Learning)、Seq2Seq(序列到序列)等为例,介绍了NLP领域的范式转变趋势。
1.提示学习成为预训练领域新型训练范式
近年来,以提示学习为代表的方法已成为NLP的新研究趋势。提示学习具有以下优势,成为了一种流行的方法。一是用户只需要提供少量的标注样本,能够减少标注的成本,这对于翻译等任务而言具有很大的优势。二是提示学习能够推动AI领域的节能减排。Fine-tune对于研究机构而言成本较高,但提示学习所需的算力资源较少,还能够降低模型的Tuning门槛。
更重要的是,提示学习为研究者在追求大模型参数军备竞赛之外的另一条研究路径。例如,提示学习提供了人类和预训练模型进行自然的交互和交流的方法——人类提供简短的提示,模型提供所需要的信息。
此外,提示学习有助于人类在不接触模型参数(如梯度)的情况下,进行黑盒模型的优化。她认为,当前很多预训练模型都采用API的方式,通过云端部署提供服务。由于不能接触模型的内核,就无法进行反向传播。但采用提示学习的方法,就可以从用户端调优模型。
2.Seq2seq架构具有解决多种NLP任务的能力
Seq2seq架构是黄萱菁认为另一个值得关注的范式转变。Seq2seq框架是深度学习刚刚兴起的那几年出现的一种架构,采用编码器-解码器的形式,早期是基于RNN类型架构,在机器翻译等领域实现应用。
近年来Transformer成为主流的算法后,基于该算法的Seq2Seq模型在NLP领域广泛发展。黄萱菁认为,序列-序列架构在多种任务上体现出了性能优势。例如,在信息提取方面,黄萱菁团队将序列到序列模型用于信息提取,能够从非结构化的文本中提取结构化信息,发现该种架构适合复杂的结构预测任务。
此外,黄老师提到,中科院软件所和百度研究者提出的Unified Structure Generation for Universal Information Extraction(https://arxiv.org/abs/2203.12277)。UIE采用序列到序列的方式,用一个模型统一了多种信息提取的任务,包括实体提取、关系提取、事件信息分类等,采用的架构便是Text-to-structure(文本到结构)。该模型在13个数据集上进行了测试,取得了最佳的性能表现,而采用低资源的方式,在小样本学习上也取得了不错的表现。

图注:Universal Information Extraction的基本架构
3.鲁棒性、环保等领域的进展
鲁棒性方面,研究者近年来会研究使用数据增强的方法,测试和提升模型对抗攻击的能力。例如,复旦自然语言处理团队发布了名为Textflint的模型鲁棒性检测平台。每年315的时候,实验室会发布测评文章,评价一些模型的鲁棒性。

图注:Textflint平台的工作流程
为了应对模型规模增大带来的能源消耗,近年来在技术上也有很多发展。一是提示学习,黄萱菁认为这本身也是一种节能环保的做法,因为提示学习不需要对模型进行大的调整。二是采用分布式低功耗的研究,将模型部署在端侧。三是研究可持续的人工智能,如模型的效率(Efficiency)研究等。
03
对本次大会的期待
2022年智源大会上,黄萱菁老师将作为演讲嘉宾出席自然语言处理论坛。谈到对本次大会的期待,她将关注NLP和信息检索领域的最新进展,特别是多模态预训练和提示学习这两个话题领域。此外,黄萱菁也对脑启发的人工智能非常感兴趣。
技术之外,她对人工智能的可解释性、伦理、隐私保护、节能减排,以及在智慧医疗(抗击疫情)、自动驾驶等方面也有期待。
在交叉学科方面,近年来AI for Science领域研究的火热。她认为,AI for Science的研究已经超出了当前计算机科学的范畴,它可以更加深入,走进各行各业中,帮助研究者从大规模的数据中发现科学规律,并开展模拟实验,建立各种各样的模型。“我会从一种科普角度的去关注,觉得很有意思。”
采访最后,黄萱菁老师对2022智源大会表达了自己的美好祝愿:
"祝智源大会越办越好,促进人工智能的跨越式发展,成为科技创新的智慧之源。"
2022年5月31日-6月2日,第四届北京智源大会将在中关村国家自主创新示范区展示中心召开,并将同步向全球线上直播。
本届大会采用线上+线下模式,注册通道已经开启,更多信息和大会动态欢迎登录大会官网(https://2022.baai.ac.cn),或扫描下方二维码和点击左下角阅读原文。

人工智能领域不容错过的内行盛会,等你一同见证!