MMDetection框架的anchor_generators.py解析与船数据解析
anchor_generators.py解析
import mmcv
import numpy as np
import torch
from torch.nn.modules.utils import _pair
from .builder import ANCHOR_GENERATORS
@ANCHOR_GENERATORS.register_module()
class AnchorGenerator(object):
"""Standard anchor generator for 2D anchor-based detectors.
Args:
strides (list[int] | list[tuple[int, int]]): Strides of anchors
in multiple feature levels in order (w, h).
多个特征层次中锚点的步长按(w, h)排序,每个特征图步长,可以理解为感受野或者下采样率
多个特性级别锚按(w, h)的步长。
ratios (list[float]): The list of ratios between the height and width
of anchors in a single level.单个水平线上锚的高度和宽度的比率列表。每个anchor的宽高比
scales (list[int] | None): Anchor scales for anchors in a single level.
It cannot be set at the same time if `octave_base_scale` and
`scales_per_octave` are set.
base_sizes (list[int] | None): The basic sizes
of anchors in multiple levels.
If None is given, strides will be used as base_sizes.
(If strides are non square, the shortest stride is taken.)
scale_major (bool): Whether to multiply scales first when generating
base anchors. If true, the anchors in the same row will have the
same scales. By default it is True in V2.0
octave_base_scale (int): The base scale of octave.# base_anchor的大小
scales_per_octave (int): Number of scales for each octave.
`octave_base_scale` and `scales_per_octave` are usually used in
retinanet and the `scales` should be None when they are set.# 每个base_anchor有3个比例
centers (list[tuple[float, float]] | None): The centers of the anchor
relative to the feature grid center in multiple feature levels.
By default it is set to be None and not used. If a list of tuple of
float is given, they will be used to shift the centers of anchors.
center_offset (float): The offset of center in proportion to anchors'
width and height. By default it is 0 in V2.0.
Examples:
>>> from mmdet.core import AnchorGenerator
>>> self = AnchorGenerator([16], [1.], [1.], [9])
>>> all_anchors = self.grid_anchors([(2, 2)], device='cpu')
>>> print(all_anchors)
[tensor([[-4.5000, -4.5000, 4.5000, 4.5000],
[11.5000, -4.5000, 20.5000, 4.5000],
[-4.5000, 11.5000, 4.5000, 20.5000],
[11.5000, 11.5000, 20.5000, 20.5000]])]
>>> self = AnchorGenerator([16, 32], [1.], [1.], [9, 18])
>>> all_anchors = self.grid_anchors([(2, 2), (1, 1)], device='cpu')
>>> print(all_anchors)
[tensor([[-4.5000, -4.5000, 4.5000, 4.5000],
[11.5000, -4.5000, 20.5000, 4.5000],
[-4.5000, 11.5000, 4.5000, 20.5000],
[11.5000, 11.5000, 20.5000, 20.5000]]), \
tensor([[-9., -9., 9., 9.]])]
"""
def __init__(self,
strides,
ratios,
scales=None,
base_sizes=None,
scale_major=True,
octave_base_scale=None,
scales_per_octave=None,
centers=None,
center_offset=0.):
# check center and center_offset
if center_offset != 0:
assert centers is None, 'center cannot be set when center_offset' \
f'!=0, {centers} is given.'
if not (0 <= center_offset <= 1):
raise ValueError('center_offset should be in range [0, 1], '
f'{center_offset} is given.')
if centers is not None:
assert len(centers) == len(strides), \
'The number of strides should be the same as centers, got ' \
f'{strides} and {centers}'
# calculate base sizes of anchors
self.strides = [_pair(stride) for stride in strides]
self.base_sizes = [min(stride) for stride in self.strides
] if base_sizes is None else base_sizes
assert len(self.base_sizes) == len(self.strides), \
'The number of strides should be the same as base sizes, got ' \
f'{self.strides} and {self.base_sizes}'
# calculate scales of anchors
assert ((octave_base_scale is not None
and scales_per_octave is not None) ^ (scales is not None)), \
'scales and octave_base_scale with scales_per_octave cannot' \
' be set at the same time'
if scales is not None:
self.scales = torch.Tensor(scales)
elif octave_base_scale is not None and scales_per_octave is not None:
octave_scales = np.array(
[2**(i / scales_per_octave) for i in range(scales_per_octave)])
scales = octave_scales * octave_base_scale
self.scales = torch.Tensor(scales)
else:
raise ValueError('Either scales or octave_base_scale with '
'scales_per_octave should be set')
self.octave_base_scale = octave_base_scale
self.scales_per_octave = scales_per_octave
self.ratios = torch.Tensor(ratios)
self.scale_major = scale_major
self.centers = centers
self.center_offset = center_offset
self.base_anchors = self.gen_base_anchors()
@property
def num_base_anchors(self):
"""list[int]: total number of base anchors in a feature grid"""
return [base_anchors.size(0) for base_anchors in self.base_anchors]
@property
def num_levels(self):
"""int: number of feature levels that the generator will be applied"""
return len(self.strides)
def gen_base_anchors(self):
"""Generate base anchors.
Returns:
list(torch.Tensor): Base anchors of a feature grid in multiple \
feature levels.
"""
multi_level_base_anchors = []
for i, base_size in enumerate(self.base_sizes):
center = None
if self.centers is not None:
center = self.centers[i]
multi_level_base_anchors.append(
self.gen_single_level_base_anchors(
base_size,
scales=self.scales,
ratios=self.ratios,
center=center))
return multi_level_base_anchors
def gen_single_level_base_anchors(self,
base_size,
scales,
ratios,
center=None):
"""Generate base anchors of a single level.
Args:
base_size (int | float): Basic size of an anchor.
scales (torch.Tensor): Scales of the anchor.
ratios (torch.Tensor): The ratio between between the height
and width of anchors in a single level.
center (tuple[float], optional): The center of the base anchor
related to a single feature grid. Defaults to None.
Returns:
torch.Tensor: Anchors in a single-level feature maps.
"""
w = base_size
h = base_size
if center is None:
x_center = self.center_offset * w
y_center = self.center_offset * h
else:
x_center, y_center = center
h_ratios = torch.sqrt(ratios)
w_ratios = 1 / h_ratios
if self.scale_major:
ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
else:
ws = (w * scales[:, None] * w_ratios[None, :]).view(-1)
hs = (h * scales[:, None] * h_ratios[None, :]).view(-1)
# use float anchor and the anchor's center is aligned with the
# pixel center
base_anchors = [
x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws,
y_center + 0.5 * hs
]
base_anchors = torch.stack(base_anchors, dim=-1)
return base_anchors
def _meshgrid(self, x, y, row_major=True):
"""Generate mesh grid of x and y.
Args:
x (torch.Tensor): Grids of x dimension.
y (torch.Tensor): Grids of y dimension.
row_major (bool, optional): Whether to return y grids first.
Defaults to True.
Returns:
tuple[torch.Tensor]: The mesh grids of x and y.
"""
# use shape instead of len to keep tracing while exporting to onnx
xx = x.repeat(y.shape[0])
yy = y.view(-1, 1).repeat(1, x.shape[0]).view(-1)
if row_major:
return xx, yy
else:
return yy, xx
def grid_anchors(self, featmap_sizes, device='cuda'):
"""Generate grid anchors in multiple feature levels.
Args:
featmap_sizes (list[tuple]): List of feature map sizes in
multiple feature levels.
device (str): Device where the anchors will be put on.
Return:
list[torch.Tensor]: Anchors in multiple feature levels. \
The sizes of each tensor should be [N, 4], where \
N = width * height * num_base_anchors, width and height \
are the sizes of the corresponding feature level, \
num_base_anchors is the number of anchors for that level.
"""
assert self.num_levels == len(featmap_sizes)
multi_level_anchors = []
for i in range(self.num_levels):
anchors = self.single_level_grid_anchors(
self.base_anchors[i].to(device),
featmap_sizes[i],
self.strides[i],
device=device)
multi_level_anchors.append(anchors)
return multi_level_anchors
def single_level_grid_anchors(self,
base_anchors,
featmap_size,
stride=(16, 16),
device='cuda'):
"""Generate grid anchors of a single level.
Note:
This function is usually called by method ``self.grid_anchors``.
Args:
base_anchors (torch.Tensor): The base anchors of a feature grid.
featmap_size (tuple[int]): Size of the feature maps.
stride (tuple[int], optional): Stride of the feature map in order
(w, h). Defaults to (16, 16).
device (str, optional): Device the tensor will be put on.
Defaults to 'cuda'.
Returns:
torch.Tensor: Anchors in the overall feature maps.
"""
# keep as Tensor, so that we can covert to ONNX correctly
feat_h, feat_w = featmap_size
shift_x = torch.arange(0, feat_w, device=device) * stride[0]
shift_y = torch.arange(0, feat_h, device=device) * stride[1]
shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)
shifts = shifts.type_as(base_anchors)
# first feat_w elements correspond to the first row of shifts
# add A anchors (1, A, 4) to K shifts (K, 1, 4) to get
# shifted anchors (K, A, 4), reshape to (K*A, 4)
all_anchors = base_anchors[None, :, :] + shifts[:, None, :]
all_anchors = all_anchors.view(-1, 4)
# first A rows correspond to A anchors of (0, 0) in feature map,
# then (0, 1), (0, 2), ...
return all_anchors
def valid_flags(self, featmap_sizes, pad_shape, device='cuda'):
"""Generate valid flags of anchors in multiple feature levels.
Args:
featmap_sizes (list(tuple)): List of feature map sizes in
multiple feature levels.
pad_shape (tuple): The padded shape of the image.
device (str): Device where the anchors will be put on.
Return:
list(torch.Tensor): Valid flags of anchors in multiple levels.
"""
assert self.num_levels == len(featmap_sizes)
multi_level_flags = []
for i in range(self.num_levels):
anchor_stride = self.strides[i]
feat_h, feat_w = featmap_sizes[i]
h, w = pad_shape[:2]
valid_feat_h = min(int(np.ceil(h / anchor_stride[1])), feat_h)
valid_feat_w = min(int(np.ceil(w / anchor_stride[0])), feat_w)
flags = self.single_level_valid_flags((feat_h, feat_w),
(valid_feat_h, valid_feat_w),
self.num_base_anchors[i],
device=device)
multi_level_flags.append(flags)
return multi_level_flags
def single_level_valid_flags(self,
featmap_size,
valid_size,
num_base_anchors,
device='cuda'):
"""Generate the valid flags of anchor in a single feature map.
Args:
featmap_size (tuple[int]): The size of feature maps.
valid_size (tuple[int]): The valid size of the feature maps.
num_base_anchors (int): The number of base anchors.
device (str, optional): Device where the flags will be put on.
Defaults to 'cuda'.
Returns:
torch.Tensor: The valid flags of each anchor in a single level \
feature map.
"""
feat_h, feat_w = featmap_size
valid_h, valid_w = valid_size
assert valid_h <= feat_h and valid_w <= feat_w
valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
valid_x[:valid_w] = 1
valid_y[:valid_h] = 1
valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
valid = valid_xx & valid_yy
valid = valid[:, None].expand(valid.size(0),
num_base_anchors).contiguous().view(-1)
return valid
def __repr__(self):
"""str: a string that describes the module"""
indent_str = ' '
repr_str = self.__class__.__name__ + '(\n'
repr_str += f'{indent_str}strides={self.strides},\n'
repr_str += f'{indent_str}ratios={self.ratios},\n'
repr_str += f'{indent_str}scales={self.scales},\n'
repr_str += f'{indent_str}base_sizes={self.base_sizes},\n'
repr_str += f'{indent_str}scale_major={self.scale_major},\n'
repr_str += f'{indent_str}octave_base_scale='
repr_str += f'{self.octave_base_scale},\n'
repr_str += f'{indent_str}scales_per_octave='
repr_str += f'{self.scales_per_octave},\n'
repr_str += f'{indent_str}num_levels={self.num_levels}\n'
repr_str += f'{indent_str}centers={self.centers},\n'
repr_str += f'{indent_str}center_offset={self.center_offset})'
return repr_str
@ANCHOR_GENERATORS.register_module()
class SSDAnchorGenerator(AnchorGenerator):
"""Anchor generator for SSD.
Args:
strides (list[int] | list[tuple[int, int]]): Strides of anchors
in multiple feature levels.
ratios (list[float]): The list of ratios between the height and width
of anchors in a single level.
basesize_ratio_range (tuple(float)): Ratio range of anchors.
input_size (int): Size of feature map, 300 for SSD300,
512 for SSD512.
scale_major (bool): Whether to multiply scales first when generating
base anchors. If true, the anchors in the same row will have the
same scales. It is always set to be False in SSD.
"""
def __init__(self,
strides,
ratios,
basesize_ratio_range,
input_size=300,
scale_major=True):
assert len(strides) == len(ratios)
assert mmcv.is_tuple_of(basesize_ratio_range, float)
self.strides = [_pair(stride) for stride in strides]
self.input_size = input_size
self.centers = [(stride[0] / 2., stride[1] / 2.)
for stride in self.strides]
self.basesize_ratio_range = basesize_ratio_range
# calculate anchor ratios and sizes
min_ratio, max_ratio = basesize_ratio_range
min_ratio = int(min_ratio * 100)
max_ratio = int(max_ratio * 100)
step = int(np.floor(max_ratio - min_ratio) / (self.num_levels - 2))
min_sizes = []
max_sizes = []
for ratio in range(int(min_ratio), int(max_ratio) + 1, step):
min_sizes.append(int(self.input_size * ratio / 100))
max_sizes.append(int(self.input_size * (ratio + step) / 100))
if self.input_size == 300:
if basesize_ratio_range[0] == 0.15: # SSD300 COCO
min_sizes.insert(0, int(self.input_size * 7 / 100))
max_sizes.insert(0, int(self.input_size * 15 / 100))
elif basesize_ratio_range[0] == 0.2: # SSD300 VOC
min_sizes.insert(0, int(self.input_size * 10 / 100))
max_sizes.insert(0, int(self.input_size * 20 / 100))
else:
raise ValueError(
'basesize_ratio_range[0] should be either 0.15'
'or 0.2 when input_size is 300, got '
f'{basesize_ratio_range[0]}.')
elif self.input_size == 512:
if basesize_ratio_range[0] == 0.1: # SSD512 COCO
min_sizes.insert(0, int(self.input_size * 4 / 100))
max_sizes.insert(0, int(self.input_size * 10 / 100))
elif basesize_ratio_range[0] == 0.15: # SSD512 VOC
min_sizes.insert(0, int(self.input_size * 7 / 100))
max_sizes.insert(0, int(self.input_size * 15 / 100))
else:
raise ValueError('basesize_ratio_range[0] should be either 0.1'
'or 0.15 when input_size is 512, got'
f' {basesize_ratio_range[0]}.')
else:
raise ValueError('Only support 300 or 512 in SSDAnchorGenerator'
f', got {self.input_size}.')
anchor_ratios = []
anchor_scales = []
for k in range(len(self.strides)):
scales = [1., np.sqrt(max_sizes[k] / min_sizes[k])]
anchor_ratio = [1.]
for r in ratios[k]:
anchor_ratio += [1 / r, r] # 4 or 6 ratio
anchor_ratios.append(torch.Tensor(anchor_ratio))
anchor_scales.append(torch.Tensor(scales))
self.base_sizes = min_sizes
self.scales = anchor_scales
self.ratios = anchor_ratios
self.scale_major = scale_major
self.center_offset = 0
self.base_anchors = self.gen_base_anchors()
def gen_base_anchors(self):
"""Generate base anchors.
Returns:
list(torch.Tensor): Base anchors of a feature grid in multiple \
feature levels.
"""
multi_level_base_anchors = []
for i, base_size in enumerate(self.base_sizes):
base_anchors = self.gen_single_level_base_anchors(
base_size,
scales=self.scales[i],
ratios=self.ratios[i],
center=self.centers[i])
indices = list(range(len(self.ratios[i])))
indices.insert(1, len(indices))
base_anchors = torch.index_select(base_anchors, 0,
torch.LongTensor(indices))
multi_level_base_anchors.append(base_anchors)
return multi_level_base_anchors
def __repr__(self):
"""str: a string that describes the module"""
indent_str = ' '
repr_str = self.__class__.__name__ + '(\n'
repr_str += f'{indent_str}strides={self.strides},\n'
repr_str += f'{indent_str}scales={self.scales},\n'
repr_str += f'{indent_str}scale_major={self.scale_major},\n'
repr_str += f'{indent_str}input_size={self.input_size},\n'
repr_str += f'{indent_str}scales={self.scales},\n'
repr_str += f'{indent_str}ratios={self.ratios},\n'
repr_str += f'{indent_str}num_levels={self.num_levels},\n'
repr_str += f'{indent_str}base_sizes={self.base_sizes},\n'
repr_str += f'{indent_str}basesize_ratio_range='
repr_str += f'{self.basesize_ratio_range})'
return repr_str
@ANCHOR_GENERATORS.register_module()
class LegacyAnchorGenerator(AnchorGenerator):
"""Legacy anchor generator used in MMDetection V1.x.
Note:
Difference to the V2.0 anchor generator:
1. The center offset of V1.x anchors are set to be 0.5 rather than 0.
2. The width/height are minused by 1 when calculating the anchors' \
centers and corners to meet the V1.x coordinate system.
3. The anchors' corners are quantized.
Args:
strides (list[int] | list[tuple[int]]): Strides of anchors
in multiple feature levels.
ratios (list[float]): The list of ratios between the height and width
of anchors in a single level.
scales (list[int] | None): Anchor scales for anchors in a single level.
It cannot be set at the same time if `octave_base_scale` and
`scales_per_octave` are set.
base_sizes (list[int]): The basic sizes of anchors in multiple levels.
If None is given, strides will be used to generate base_sizes.
scale_major (bool): Whether to multiply scales first when generating
base anchors. If true, the anchors in the same row will have the
same scales. By default it is True in V2.0
octave_base_scale (int): The base scale of octave.
scales_per_octave (int): Number of scales for each octave.
`octave_base_scale` and `scales_per_octave` are usually used in
retinanet and the `scales` should be None when they are set.
centers (list[tuple[float, float]] | None): The centers of the anchor
relative to the feature grid center in multiple feature levels.
By default it is set to be None and not used. It a list of float
is given, this list will be used to shift the centers of anchors.
center_offset (float): The offset of center in propotion to anchors'
width and height. By default it is 0.5 in V2.0 but it should be 0.5
in v1.x models.
Examples:
>>> from mmdet.core import LegacyAnchorGenerator
>>> self = LegacyAnchorGenerator(
>>> [16], [1.], [1.], [9], center_offset=0.5)
>>> all_anchors = self.grid_anchors(((2, 2),), device='cpu')
>>> print(all_anchors)
[tensor([[ 0., 0., 8., 8.],
[16., 0., 24., 8.],
[ 0., 16., 8., 24.],
[16., 16., 24., 24.]])]
"""
def gen_single_level_base_anchors(self,
base_size,
scales,
ratios,
center=None):
"""Generate base anchors of a single level.
Note:
The width/height of anchors are minused by 1 when calculating \
the centers and corners to meet the V1.x coordinate system.
Args:
base_size (int | float): Basic size of an anchor.
scales (torch.Tensor): Scales of the anchor.
ratios (torch.Tensor): The ratio between between the height.
and width of anchors in a single level.
center (tuple[float], optional): The center of the base anchor
related to a single feature grid. Defaults to None.
Returns:
torch.Tensor: Anchors in a single-level feature map.
"""
w = base_size
h = base_size
if center is None:
x_center = self.center_offset * (w - 1)
y_center = self.center_offset * (h - 1)
else:
x_center, y_center = center
h_ratios = torch.sqrt(ratios)
w_ratios = 1 / h_ratios
if self.scale_major:
ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
else:
ws = (w * scales[:, None] * w_ratios[None, :]).view(-1)
hs = (h * scales[:, None] * h_ratios[None, :]).view(-1)
# use float anchor and the anchor's center is aligned with the
# pixel center
base_anchors = [
x_center - 0.5 * (ws - 1), y_center - 0.5 * (hs - 1),
x_center + 0.5 * (ws - 1), y_center + 0.5 * (hs - 1)
]
base_anchors = torch.stack(base_anchors, dim=-1).round()
return base_anchors
@ANCHOR_GENERATORS.register_module()
class LegacySSDAnchorGenerator(SSDAnchorGenerator, LegacyAnchorGenerator):
"""Legacy anchor generator used in MMDetection V1.x.
The difference between `LegacySSDAnchorGenerator` and `SSDAnchorGenerator`
can be found in `LegacyAnchorGenerator`.
"""
def __init__(self,
strides,
ratios,
basesize_ratio_range,
input_size=300,
scale_major=True):
super(LegacySSDAnchorGenerator,
self).__init__(strides, ratios, basesize_ratio_range, input_size,
scale_major)
self.centers = [((stride - 1) / 2., (stride - 1) / 2.)
for stride in strides]
self.base_anchors = self.gen_base_anchors()
@ANCHOR_GENERATORS.register_module()
class YOLOAnchorGenerator(AnchorGenerator):
"""Anchor generator for YOLO.
Args:
strides (list[int] | list[tuple[int, int]]): Strides of anchors
in multiple feature levels.
base_sizes (list[list[tuple[int, int]]]): The basic sizes
of anchors in multiple levels.
"""
def __init__(self, strides, base_sizes):
self.strides = [_pair(stride) for stride in strides]
self.centers = [(stride[0] / 2., stride[1] / 2.)
for stride in self.strides]
self.base_sizes = []
num_anchor_per_level = len(base_sizes[0])
for base_sizes_per_level in base_sizes:
assert num_anchor_per_level == len(base_sizes_per_level)
self.base_sizes.append(
[_pair(base_size) for base_size in base_sizes_per_level])
self.base_anchors = self.gen_base_anchors()
@property
def num_levels(self):
"""int: number of feature levels that the generator will be applied"""
return len(self.base_sizes)
def gen_base_anchors(self):
"""Generate base anchors.
Returns:
list(torch.Tensor): Base anchors of a feature grid in multiple \
feature levels.
"""
multi_level_base_anchors = []
for i, base_sizes_per_level in enumerate(self.base_sizes):
center = None
if self.centers is not None:
center = self.centers[i]
multi_level_base_anchors.append(
self.gen_single_level_base_anchors(base_sizes_per_level,
center))
return multi_level_base_anchors
def gen_single_level_base_anchors(self, base_sizes_per_level, center=None):
"""Generate base anchors of a single level.
Args:
base_sizes_per_level (list[tuple[int, int]]): Basic sizes of
anchors.
center (tuple[float], optional): The center of the base anchor
related to a single feature grid. Defaults to None.
Returns:
torch.Tensor: Anchors in a single-level feature maps.
"""
x_center, y_center = center
base_anchors = []
for base_size in base_sizes_per_level:
w, h = base_size
# use float anchor and the anchor's center is aligned with the
# pixel center
base_anchor = torch.Tensor([
x_center - 0.5 * w, y_center - 0.5 * h, x_center + 0.5 * w,
y_center + 0.5 * h
])
base_anchors.append(base_anchor)
base_anchors = torch.stack(base_anchors, dim=0)
return base_anchors
def responsible_flags(self, featmap_sizes, gt_bboxes, device='cuda'):
"""Generate responsible anchor flags of grid cells in multiple scales.
Args:
featmap_sizes (list(tuple)): List of feature map sizes in multiple
feature levels.
gt_bboxes (Tensor): Ground truth boxes, shape (n, 4).
device (str): Device where the anchors will be put on.
Return:
list(torch.Tensor): responsible flags of anchors in multiple level
"""
assert self.num_levels == len(featmap_sizes)
multi_level_responsible_flags = []
for i in range(self.num_levels):
anchor_stride = self.strides[i]
flags = self.single_level_responsible_flags(
featmap_sizes[i],
gt_bboxes,
anchor_stride,
self.num_base_anchors[i],
device=device)
multi_level_responsible_flags.append(flags)
return multi_level_responsible_flags
def single_level_responsible_flags(self,
featmap_size,
gt_bboxes,
stride,
num_base_anchors,
device='cuda'):
"""Generate the responsible flags of anchor in a single feature map.
Args:
featmap_size (tuple[int]): The size of feature maps.
gt_bboxes (Tensor): Ground truth boxes, shape (n, 4).
stride (tuple(int)): stride of current level
num_base_anchors (int): The number of base anchors.
device (str, optional): Device where the flags will be put on.
Defaults to 'cuda'.
Returns:
torch.Tensor: The valid flags of each anchor in a single level \
feature map.
"""
feat_h, feat_w = featmap_size
gt_bboxes_cx = ((gt_bboxes[:, 0] + gt_bboxes[:, 2]) * 0.5).to(device)
gt_bboxes_cy = ((gt_bboxes[:, 1] + gt_bboxes[:, 3]) * 0.5).to(device)
gt_bboxes_grid_x = torch.floor(gt_bboxes_cx / stride[0]).long()
gt_bboxes_grid_y = torch.floor(gt_bboxes_cy / stride[1]).long()
# row major indexing
gt_bboxes_grid_idx = gt_bboxes_grid_y * feat_w + gt_bboxes_grid_x
responsible_grid = torch.zeros(
feat_h * feat_w, dtype=torch.uint8, device=device)
responsible_grid[gt_bboxes_grid_idx] = 1
responsible_grid = responsible_grid[:, None].expand(
responsible_grid.size(0), num_base_anchors).contiguous().view(-1)
return responsible_grid



自己的图像分析统计代码
import os
import glob
import tqdm
from argparse import ArgumentParser
from pydoc import classname
import numpy as np
import pandas as pd
import json
import cv2
from PIL import Image,ImageFont, ImageDraw
Image.MAX_IMAGE_PIXELS = None
import matplotlib.pyplot as plt
from matplotlib import category
from itertools import groupby
plt.rcParams['font.sans-serif']=['FangSong'] #用来正常显示中文标签
shipdata_classnames=['nimizi', 'ship', 'huangfeng', 'shengandongniao', 'boke',
'liuyisikelake', 'tikangdeluojia', 'cunyu', 'huitebeidao', 'meiguo',
'jingang', 'zhumuwoerte', 'duli', 'ziyou', 'fute',
'henglikaize', 'aidang', 'zhaowu', 'rixiang', 'lanling', 'chuyun', 'gaobo']
def plot_class_statistics(class_statistics,save_dir):
###每一个目标个数统计饼状图
x = list(class_statistics.keys())
y = list(class_statistics.values())
fig=plt.subplots(figsize = (12,6))#创建画布
plt.bar(range(1,len(y)+1), y, tick_label=x, facecolor='blue', edgecolor='white')
plt.xticks(rotation=70)
# 设置横纵坐标的边界,去掉横坐标的线
plt.xlim(0, len(y)+1)
plt.ylim(0, 2000)
for x, y in zip(range(1,len(y)+1), y):
# ha: horizontal alignment 横向对齐
# va: vertical alignment 纵向对齐
plt.text(x , y + 0.05, '%.1f' % y, ha='center', va='bottom')#添加标注文本信息
plt.savefig(save_dir+"/class_statistic.png",dpi=300)
plt.show()
def plot_classwh_statistics(class_statistics,save_dir):
fig=plt.figure(figsize=(18,20))
classnames= list(class_statistics.keys())
for id,classname in enumerate(classnames):
x = list(class_statistics.get(classname).keys())
y = list(class_statistics.get(classname).values())
plt.subplot(4,6,id+1)
plt.bar(range(1,len(y)+1), y, tick_label=x, facecolor='blue', edgecolor='white')
plt.title(classname)
plt.show()
plt.savefig(save_dir+"/classhw_statistic.png",dpi=300)
def classnames_statistic(txt_dir):
txt_list = glob.glob(txt_dir + "/*.txt")
class_list = []
for txt in txt_list:
f = open(txt)
txt_lines = f.readlines()
for txt_line in txt_lines:
per_cls = txt_line.strip().split(" ")[-2]
if per_cls not in class_list:
class_list.append(per_cls)
if per_cls == "None":
print(txt)
print(class_list)
def class_statistic(txt_dir, out_dir,class_name_dict):
txt_filelist = glob.glob(os.path.join(txt_dir, '*.txt'))
categories=[category for category in class_name_dict.keys()]
class_names=[class_name for class_name in class_name_dict.values()]
##目标类名name集合
labeles_name = []
for txt_file in txt_filelist:
with open(txt_file,'r') as f:
labels = f.readlines() #获取裁剪影像的标注文件信息
f.close()
for label in labels:
label = label.replace('\n', '')#去掉每一行的换行符
category_name=label.split(' ')[-2]
if category_name in class_names:
labeles_name.append(category_name)
else:
continue
###每一个目标NAME个数统计
classes_num={}
for class_name in class_names:
classes_num.update({class_name:labeles_name.count(class_name)})
print(classes_num)
with open(out_dir+os.sep+"class_statistic.txt",'w') as f:
f.write(json.dumps(classes_num))
plot_class_statistics(classes_num,out_dir)
def imagesize_statistics(train_annjson_path):
'''
dataset = json.load(open(train_annjson_path, 'r'))
for img in dataset['images']:
hw=(img['height'],img['width'])
total.append(hw)
unique=set(total)
for k in unique:
print('长宽为(%d,%d)的图片数量为:'%k,total.count(k))##可以看出visdrone图片长宽是多样的
'''
dataset = glob.glob(os.path.join(train_annjson_path, '*.jpg'))
total=[]
for img in dataset:
image=cv2.imread(img)
hw=(image.shape[0],image.shape[1])
total.append(hw)
unique=set(total)
for k in unique:
print('长宽为(%d,%d)的图片数量为:'%k,total.count(k))##可以看出ship图片长宽是多样的
def collect_wh(args):
txt_dir=args.txt_dir
save_dir=args.outpngdir
txt_filelist = glob.glob(os.path.join(txt_dir, '*.txt'))
wh_all = list()
for txt_file in txt_filelist:
with open(txt_file,'r') as f:
labels = f.readlines() #获取裁剪影像的标注文件信息
f.close()
for label in labels:
label=label.strip().split(' ')
points=label[:8]
points = np.float32(np.array(points).reshape(-1,2))
category_name=label[-2]
rect = cv2.minAreaRect(points) #得到最小外接矩形的(中心(x,y), (宽,高), 旋转角度)
w = rect[1][0]
h = rect[1][1]
object = (int(w),int(h), category_name)
wh_all.append(object)
wh_ratio_all = list()
wh_ratio_num=list()
for wh_record in wh_all:
wh_ratio = round(wh_record[0] / wh_record[1],0) # anchor里面的ratio就是h/w比例
if wh_ratio < 1:
wh_ratio = round(wh_record[1] / wh_record[0],0) # anchor里面的ratio就是h/w比例
classname=wh_record[-1]
wh_ratio_all.append((classname, wh_ratio))
wh_ratio_num.append(wh_ratio)
classehw_num={}
for ratio in set(wh_ratio_num):
classehw_num.update({ratio:wh_ratio_num.count(ratio)})
# print(classehw_num)
x = list(classehw_num.keys())
y = list(classehw_num.values())
fig=plt.subplots(figsize = (12,6))#创建画布
plt.bar(range(1,len(y)+1), y, tick_label=x, facecolor='blue', edgecolor='white')
# plt.xticks(rotation=70)
# 设置横纵坐标的边界,去掉横坐标的线
plt.xlim(0, len(y)+1)
plt.ylim(0, 2000)
for x, y in zip(range(1,len(y)+1), y):
# ha: horizontal alignment 横向对齐
# va: vertical alignment 纵向对齐
plt.text(x , y + 0.05, '%.1f' % y, ha='center', va='bottom')#添加标注文本信息
plt.savefig(save_dir+"/hwratio_statistic.png",dpi=300)
#每一个类别目标宽高比率个数统计柱状图
list0=[]
for id ,name in enumerate(shipdata_classnames):
for wh_ratio in wh_ratio_all:
classname=wh_ratio[0]
if classname==name:
list0.append(wh_ratio)
# print(list0)
dict_list={}
user_group = groupby( list0, key=lambda x: (x[0]))
for key, group in user_group:
list1=[]
dict={}
# print(key, list(group))
for record in list(group):
list1.append(record[-1])
for ratio in set(list1):
dict.update({ratio:list1.count(ratio)})
print(key,dict)
dict_list.update({key:dict})
plot_classwh_statistics(dict_list,save_dir)
def statistics_hw_ratio(hw_all):
print('----------统计宽高分布---------可视化内容是所有种类的长边和短边的比例')
'''
ratios (list[float]): The list of ratios between the height and width
of anchors in a single level.
'''
#部分参考:https://zhuanlan.zhihu.com/p/108885033
#https://zhuanlan.zhihu.com/p/259963010
'''
# 对所有标注长宽做统计
total_size=[]
total_height=[]
total_wh=[]
for im in data: # 每张图的信息
for b in im['annotations']: # 每张图的每个标注
# total_width += [b['bbox'][2]]
# total_height += [b['bbox'][3]]
wh = round(b['bbox'][2]/b['bbox'][3], 0)
if wh < 1 :
wh = round(b['bbox'][3]/b['bbox'][2],0)
total_wh += [wh]
# 所有标签的长宽高比例
box_wh_unique = list(set(total_wh))
box_wh_count=[total_wh.count(i) for i in box_wh_unique]
bbox_wh_dict = {}
for i, key in enumerate(box_wh_unique):
print('宽高比{}: 数量:{}'.format(key, box_wh_count[i]))
# 绘图
wh_df = pd.DataFrame(box_wh_count,index=box_wh_unique,columns=['宽高比数量'])
wh_df.plot(kind='bar',color="#55aacc")
plt.show()
'''
'''
# 对所有标注面积比做统计
total_size704_676=[]
total_size1920_1080=[]
total_size3840_2160=[]
total_size720_405=[]
total_size586_481=[]
total_wh=[]
for im in data: # 每张图的信息
for b in im['annotations']: # 每张图的每个标注
if (im['width'], im['height']) == list(unique)[0]:
size = round(b['bbox'][2] * b['bbox'][3])
total_size704_676 += [size]
elif (im['width'], im['height']) == list(unique)[1]:
size = round(b['bbox'][2] * b['bbox'][3])
total_size1920_1080 += [size]
elif (im['width'], im['height']) == list(unique)[2]:
size = round(b['bbox'][2] * b['bbox'][3])
total_size3840_2160 += [size]
elif (im['width'], im['height']) == list(unique)[3]:
size = round(b['bbox'][2] * b['bbox'][3])
total_size720_405 += [size]
elif (im['width'], im['height']) == list(unique)[4]:
size = round(b['bbox'][2] * b['bbox'][3])
total_size586_481 += [size]
max_size = max(total_size704_676)
gap = 1000
group_names = list(range(0,20000,gap))
size_cuts = pd.cut(total_size704_676,bins=group_names,labels=group_names[:-1])
total_df=pd.DataFrame({'704_676':size_cuts.value_counts()})
total_df.plot(kind='bar')
max_size = max(total_size1920_1080)
gap = 1000
group_names = list(range(0,90000,gap))
size_cuts = pd.cut(total_size1920_1080,bins=group_names,labels=group_names[:-1])
total_df=pd.DataFrame({'1920_1080':size_cuts.value_counts()})
total_df.plot(kind='bar')
max_size = max(total_size3840_2160)
gap = 1000
group_names = list(range(0,60000,gap))
size_cuts = pd.cut(total_size3840_2160,bins=group_names,labels=group_names[:-1])
total_df=pd.DataFrame({'3840_2160':size_cuts.value_counts()})
total_df.plot(kind='bar')
max_size = max(total_size720_405)
gap = 500
group_names = list(range(0,25000,gap))
size_cuts = pd.cut(total_size720_405,bins=group_names,labels=group_names[:-1])
total_df=pd.DataFrame({'720_405':size_cuts.value_counts()})
total_df.plot(kind='bar')
max_size = max(total_size586_481)
gap = 100
group_names = list(range(0,max_size,gap))
size_cuts = pd.cut(total_size586_481,bins=group_names,labels=group_names[:-1])
total_df=pd.DataFrame({'586_481':size_cuts.value_counts()})
total_df.plot(kind='bar')
'''
hw_all=np.array(hw_all)
hw_ratio = hw_all[:, 0] / hw_all[:, 1] # anchor里面的ratio就是h/w比例
# 分成两部分单独统计
hw_ratio_larger = hw_ratio[hw_ratio >= 1].astype(np.int) # 会损失些精度
hw_ratio_larger_uq = np.unique(hw_ratio_larger)
box_hw_larger_count = [np.count_nonzero(hw_ratio_larger == i) for i in hw_ratio_larger_uq]
plt.subplot(2, 1, 1)
plt.title('hw_ratio>=1')
plt.xlabel('hw_ratio')
plt.ylabel('num')
plt.bar(hw_ratio_larger_uq, box_hw_larger_count, 0.1) # 0-20之间
# # wh_df = pd.DataFrame(box_hw_larger_count, index=hw_ratio_larger_uq, columns=['hw_ratio>=1'])
# # wh_df.plot(kind='bar', color="#55aacc")
hw_ratio_small = hw_ratio[hw_ratio < 1].round(1)
hw_ratio_small_uq = np.unique(hw_ratio_small)
box_hw_small_count = [np.count_nonzero(hw_ratio_small == i) for i in hw_ratio_small_uq]
plt.subplot(2, 1, 2)
plt.title('hw_ratio<1')
plt.xlabel('hw_ratio')
plt.ylabel('num')
plt.bar(hw_ratio_small_uq, box_hw_small_count, 0.05) # 0-1之间
plt.show()
hw_ratio = np.concatenate((hw_ratio_small, hw_ratio_larger), axis=0).round(1)
hw_ratio_uq = np.unique(hw_ratio).tolist()
box_hw_count = [np.count_nonzero(hw_ratio == i) for i in hw_ratio_uq]
print('按照num数从大到小排序输出')
data = sorted(zip(hw_ratio_uq, box_hw_count), key=lambda x: x[1], reverse=True)
hw_ratio_uq, box_hw_count = zip(*data)
print('hw_ratio', hw_ratio_uq)
print('num', box_hw_count)
def parse_args():
parser = ArgumentParser()
parser.add_argument('--txt_dir',type=str, default='./data/DOTA/shippadd/labels', help='Sample labeling dir')
parser.add_argument('--imgdir',type=str, default='./data/DOTA/shippadd/images', help='Image dir')
parser.add_argument('--outpngdir',type=str, default='./data_process/analy_result',help='Sample statistical results')
parser.add_argument('--statisticstype',type=str, default='class_statistic',help='class_statistic(统计标注的类别列表),classnumber_statistic(统计类别)、imagesize_statistic(统计图像分辨率、whratio_statistic(统计目标长宽比))')
args = parser.parse_args()
return args
def main(args):
############################################
#类别
############################################
# shipdata_classnames = ['nimizi', 'ship', 'huangfeng', 'zhumuwoerte', 'boke', 'henglikaize', 'tikangdeluojia',
# 'huitebeidao','shengandongniao', 'meiguo', 'jingang','liuyisikelake', 'duli', 'ziyou', 'fute',
# 'None', 'zhaowu', 'chuyun', 'lanling', 'cunyu', 'gaobo']
# print("all class is:",len(shipdata_classnames))
class_name_dict = dict(zip(range(1,len(shipdata_classnames)+1), shipdata_classnames))
txt_dir=args.txt_dir
imgdir=args.imgdir
outpngdir=args.outpngdir
statisticstype=args.statisticstype
if statisticstype == 'class_statistic':
print("开始执行类别数目与名称统计!")
classnames_statistic(txt_dir)
if statisticstype == 'classnumber_statistic':
print("开始执行类别统计!")
class_statistic(txt_dir, outpngdir, class_name_dict)
elif statisticstype == 'imagesize_statistic':
print("开始执行统计图像分辨率统计!")
imagesize_statistics(imgdir)
elif statisticstype == 'whratio_statistic':
print('开始统计目标长宽比')
collect_wh(args)
if __name__ == '__main__':
args = parse_args()
main(args)
1、类别的统计结果
发现模型数据集的类别极不均衡,需要应用focalloss,ohem等trick平衡正负以及困难样本

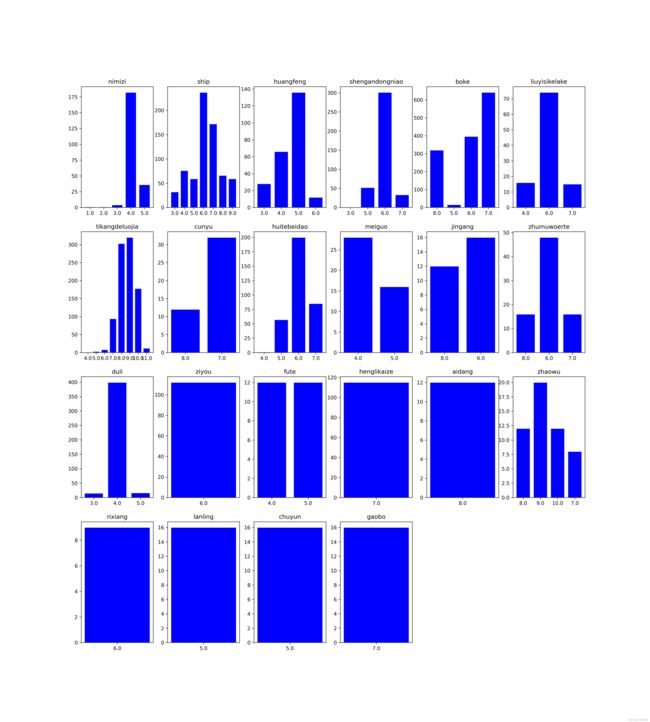
2、各个类别的高宽比率统计结果
有些类别标签有多个尺度
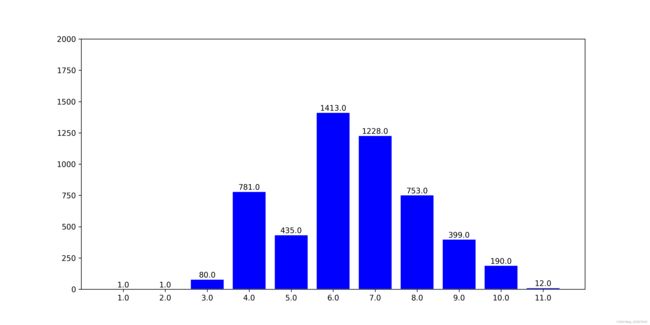
3、总体高宽比率出现次数统计结果