Yolov5(1):Detect源码逐行解析
开学时,给自己定的学习任务,直到今天才有闲空来完成。一方面是yolo代码初看觉得乱糟糟的,不想读;其次,yolo算法对于初触深度学习的我而言,还是有较大的难度。
今天学习成果就是弄懂了,yolov5的Idea+模型的构建+实现源码
类似ViT的阅读,阅读完后觉得,还是自顶向下解析比较清晰。
YOLOv5系列:解析索引
一、Yolo v5 模型结构
模型整体分为:
1.BackBone
2.Neck
3.Head(在代码中,直观上看似乎作者将Neck和Head放在一起实现了)
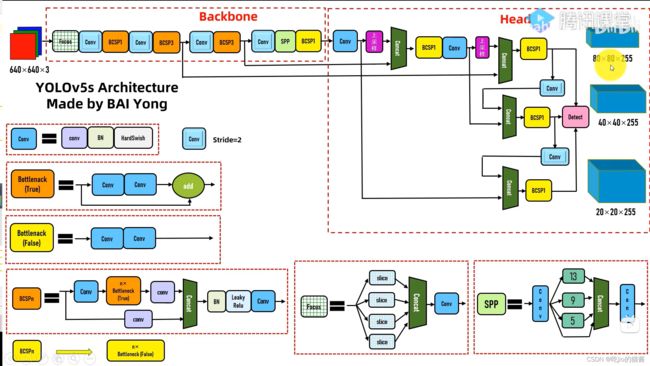
下方的图中,用四个黄颜色圈出来的部分,分别表示为4个Head部分。

二、Yolo v5 的模块
作者实现为了保证模型的灵活可调,将几乎所有的参数都预设到yaml文件中了,因此在构建模型的时候,只要清楚模块的实现即可,对应参数在yaml文件中已经给出。
核心子模块:
1.Focus: Slice=interlace-stride2-DownSample 步长为2的横纵向交错采样
2.Conv: conv+BN+HardSwish
3.Bottleneck-True:
+ Conv*2 4.Bottleneck-False: Conv*2
5.C3-True: BCSP3-True
6.C3-False: BCSP3-False
7.BCSPn-True:
Concate
Conv+Bottleneck-True*n+conv Concate
conv 8.BCSPn-False:
Bottleneck-False*n
9.SPP:金字塔池化--通过不同kernal_size的池化结果的拼接
三、Yolo v5 Detect部分源码详解
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
# 每一个 预选框预测输出,前nc个01字符对应类别,后5个对应:是否有目标,目标框的中心,目标框的宽高
self.no = nc + 5 # number of outputs per anchor
# 表示预选层数,yolov5是3层预选
self.nl = len(anchors)
# 预选框数量,anchors数据中每一对数据表示一个预选框的宽高
self.na = len(anchors[0]) // 2
# 初始化grid列表大小,空列表
self.grid = [torch.zeros(1)] * self.nl
# 初始化anchor_grid列表大小,空列表
self.anchor_grid = [torch.zeros(1)] * self.nl
# 注册常量anchor,并将预选框(尺寸)以数对形式存入 ---- 实际存的是框的宽高
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2))
# 每一张进行三次预测,每一个预测结果包含nc+5个值
# (n, 255, 80, 80),(n, 255, 40, 40),(n, 255, 20, 20) --> ch=(255, 255, 255)
# 255 -> (nc+5)*3 ===> 为了提取出预测框的位置信息以及预测框尺寸信息
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
# 输入的x是来自三层金字塔的预测结果(n, 255, 80, 80),(n, 255, 40, 40),(n, 255, 20, 20)
for i in range(self.nl):
# 下面3行代码的工作:
# (n, 255, _, _) -> (n, 3, nc+5, ny, nx) -> (n, 3, ny, nx, nc+5)
# 相当于三层分别预测了80*80、40*40、20*20次,每一次预测都包含3个框
x[i] = self.m[i](x[i])
bs, _, ny, nx = x[i].shape
# contiguous 将数据保证内存中位置连续
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# self.training 作为nn.Module的参数,默认是True,因此下方代码先不考虑
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
# 为每一层划分网格
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
# 改变原数据
if self.inplace:
# grid[i] = (3, 20, 20, 2), y = [n, 3, 20, 20, nc+5]
# grid实际是 位置基准 或者理解为 cell的预测初始位置,而y[..., 0:2]是作为在grid坐标基础上的位置偏移
# anchor_grid实际是 预测框基准 或者理解为 预测框的初始位置,而 y[..., 2:4]是作为预测框位置的调整
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
# stride应该是一个grid cell的实际尺寸
# 经过sigmoid,值范围变成了(0-1),下一行代码将值变成范围(-0.5,1.5),
# 相当于预选框上下左右都扩大了0.5倍的移动区域,不易大于0.5倍,否则就重复检验了其他网格的内容了
# 此处的1表示一个grid cell的尺寸,尽量让预测框的中心在grid cell中心附近
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
# 范围变成(0-4)倍,设置为4倍的原因是下层的感受野是上层的2倍
# 因下层注重检测大目标,相对比上层而言,计算量更小,4倍是一个折中的选择
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
# 网格标尺坐标
# indexing='ij' 表示的是i是同一行,j表示同一列
# indexing='xy' 表示的是x是同一列,y表示同一行
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')
else:
yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])
# grid --> (20, 20, 2), 拓展(复制)成3倍,因为是三个框 -> (3, 20, 20, 2)
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
# 与grid同理
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid