Docker安装ElasticSearch,并进行ik和hanlp分词
我按装的目标: 利用ElastiSearch存储数据,ik和hanlp分词插件 对搜索词进行分词,在ES存储的库中找到与搜索词相近的内容。
安装感受: 原始环境安装老版本的ES,BUG不断,ES相关解答博客对新手有点不友好,完整的解释不多, 也许是我比较菜。
ElasticSearch是什么?
答:ES是分布式的搜索和分析引擎。
ElasticSearch有什么作用?
答: ES 为所有类型的数据提供近乎实时的搜索和分析。ES可以高效存储结构和非结构化数据;ES可以用简单的数据检索和聚合信息;随着数据的查询量和数据量存储的增涨,ES的分布式特性可以解决对应问题。
Elasticsearch的适用场景?
答:(1)维基百科,类似百度百科全文检索,搜索推荐
(2)搜狐新闻,用户行为日志(点击,浏览,收藏,评论)
(3)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买)
…还有很多
一、安装说明
1、
ElasticSearch单机安装;
2、IK分词器和hanlp分词器安装;
3、Kibana安装; (操作ES的时,可视化界面。ps: 一开始安装时候,很多博客都默认知道Kibana,导致我当时看演示案例时,一脸懵逼)
二、Docker安装ElasticSearch
当前ElasticSearch版本已经更新到了8.0,版本越高,对应性能和功能都有大幅提升。我要用到hanlp,所以我这里采用7.10.1版本。
2.1 ElasticSearch安装
友情提示:先查看系统存储占比情况,如果是下图占比达到了90%以上,建议删掉不必要内容降低占比,或者直接换一台机子。因为ES占比要求是不超过90%,否则无法进行。

第一步:修改vm.max_map_count:(这里是修改本机的内容)
# 编辑sysctl.conf
vi /etc/sysctl.conf
#最后一行修改或新增下面命令
vm.max_map_count = 262144
#立即生效
sysctl -p
vm.max_map_count解释:设置虚拟内存大小,供程序运行时产生的临时数据存储。
第二步:挂载目录
# 创建目录(自定义存储目录)
mkdir /mydata/elasticsearch/data/ -p
# 创建目录(自定义存储目录)
mkdir /mydata/elasticsearch/plugins/ -p
# 设置目录权限
chmod 777 /mydata/elasticsearch/data
chmod 777 /mydata/elasticsearch/plugins
第三步: ElasticSearch安装
(1)拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.10.1
(2)建立容器
docker run -d \
--name elasticsearch \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-e "cluster.name=elasticsearch" \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
--privileged \
-p 9200:9200 \
-p 9300:9300 \
-d elasticsearch:7.10.1
命令说明:
- -e
"cluster.name=elasticsearch":设置集群名称 - -e
"ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小 - -e
"discovery.type=single-node":非集群模式 - -v
/mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定elasticsearch的数据目录 - -v
/mydata/elasticsearch/data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定elasticsearch的插件目录 - –
privileged:授予逻辑卷访问权 - -p
9200:9200:端口映射配置
2.2 ElasticSearch安装成功检验
在浏览器中输入:http://服务器地址:9200/(我自己定义端口是8110,按上面来你们是9200) 即可看到elasticsearch的响应结果:

三、安装Kibana
可以基于Http请求操作ElasticSearch,但基于Http操作比较麻烦,我们可以采用Kibana实现可视化操作。
3.1 Kibana安装
安装命令如下:
docker run -d \
--name kibana \
--link=elasticsearch:elasticsearch \
-p 5601:5601 \
-d kibana:7.10.1
命令说明:
--link=elasticsearch:elasticsearch设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch,也可以写IP地址实现访问。- -p
5601:5601:端口映射配置
3.2 Kibana安装成功检验
访问http://服务器IP:5601效果如下:
 点击
点击Add data 就能进入使用页面了:

3.3 Kibana中文配置
我们发现Kibana是英文面板,看起来不是很方便,但Kibana是支持中文配置,所以我们可以把Kibana配置成中文版,便于我们操作。
切换中文操作如下:
#进入容器
docker exec -it kibana /bin/bash
#进入配置文件目录
cd /usr/share/kibana/config
#编辑文件kibana.yml
vi kibana.yml
#在最后一行添加如下配置
i18n.locale: zh-CN
#保存退出
exit
#并重启容器
docker restart kibana
等待Kibana容器启动,再次访问http://服务器IP:5601效果如下:


四、安装IK分词器和hanlp分词器
4.1 IK分词器和hanlp分词器插件安装
# 1.下载ik安装包到本地服务器
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.1/elasticsearch-analysis-ik-7.10.1.zip
# 2.将ik安装包转移到 elastic服务器中
docker cp ./elasticsearch-analysis-ik-7.10.1.zip elasticsearch:/usr/share/elasticsearch
# 3.进入elasticsearch容器
docker exec -it elasticsearch bash
# 4.压缩ik安装包
unzip elasticsearch-analysis-ik-7.10.1.zip -d ./plugins/ik/
# 5.再直接安装hanlp分词器
./bin/elasticsearch-plugin install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v7.10.1/elasticsearch-analysis-hanlp-7.10.1.zip
查看分词器是否安装成功
./bin/elasticsearch-plugin list
显示如下图,表示安装成功

退出和重启elasticsearch,再进行下面的测试
# exit退出es容器
exit
# 重启es容器
docker restart elasticsearch
4.2 Ik和hanlp分词测试
在使用Kibana测试 http://你自己服务器ip:5601/app/dev_tools#/console
ik分词测试:
ik分词更多的操作
ik测试结果如下:

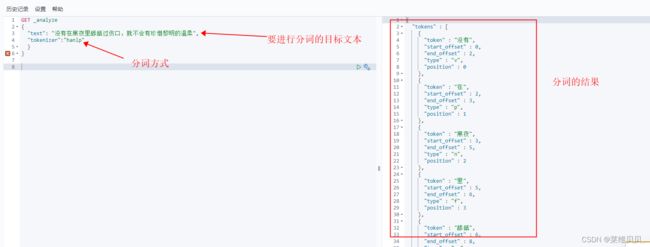
hanlp分词测试:
hanlp分词更多操作
hanlp测试结果如下:
参考链接
https://blog.csdn.net/scmagic/article/details/123500533
https://blog.csdn.net/qinghuidu/article/details/107841436
https://blog.csdn.net/LXWalaz1s1s/article/details/111697177
https://blog.csdn.net/weixin_43649997/article/details/106875269