python爬虫之爬取网页基础知识及环境配置概括
记:python爬虫是爬取网页数据、统计数据必备的知识体系,当我们想统计某个网页的部分数据时,就需要python爬虫进行网络数据的爬取,英文翻译为 spider
爬虫的核心
1.爬取网页:爬取整个网页 包含了网页中所有得内容
2.解析数据:将网页中你得到的数据 进行解析
3.难点:爬虫和反爬虫之间的博弈
爬虫的用途
1、数据分析/人工数据集
2、社交软件冷启动
3、舆情监控
4、竞争对手监控
5、爬虫分类
6、通用爬虫
爬虫实例 :百度、360、google、sougou等搜索引擎‐‐‐伯乐在线
功能:访问网页‐>抓取数据‐>数据存储‐>数据处理‐>提供检索服务
robots协议:一个约定俗成的协议,添加robots.txt文件,来说明本网站哪些内容不可以被抓取,起不到限制作用自己写的爬虫无需遵守
网站排名(SEO):根据pagerank算法值进行排名(参考个网站流量、点击率等指标)
百度竞价排名
缺点:
1、抓取的数据大多是无用的
2、不能根据用户的需求来精准获取数据
聚焦爬虫
功能 :根据需求,实现爬虫程序,抓取需要的数据
设计思路
1.确定要爬取的url
如何获取Url
2.模拟浏览器通过http协议访问url,获取服务器返回的html代码
如何访问
3.解析html字符串(根据一定规则提取需要的数据)
如何解析
反爬手段
1、使用 User Agent :User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
2.代理IP 西次代理 、快代理
什么是高匿名、匿名和透明代理?它们有什么区别?
1.使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
2.使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
3.使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
3.验证码访问:打码平台、云打码平台、超级鹰
4.动态加载网页 网站返回的是js数据 并不是网页的真实数 :selenium驱动真实的浏览器发送请求
5.数据加密:分析js代码
爬虫整套环境
1、python3.x :https://www.python.org/ 可官网下载 指定操作系统版本 如 版本:Python 3.7.0rc1
2、配置环境变量:windows装完后 需要配置环境变量,python.exe的路径和python script路径(存放python库)在命令窗口输入 python -v,
mac 下安装完成后 需要在命令窗口 输入 : python3 -v mac 下的库是在 ~/Library/Python/3.7/lib/python/site-packages/ 文件夹下
3、安装pip : pip 是一个现代的,通用的Python包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能,便于我们对Python的资源包进行管理。
查看pip 版本 windows 使用 pip -V 。 mac 下使用pip3 -V
4、 pip使用镜像资源:运行pip install 命令会从网站上下载指定的python包,默认是从 https://files.pythonhosted.org/ 网站上下载。这是个国外的网站,遇到网络情况不好的时候,可能会下载失败,我们可以通过命 令修改pip现在软件时的源。 格式: pip install 包名 -i 国内源地址 示例: pip install ipython -i https://pypi.mirrors.ustc.edu.cn/simple/ 就是从中国科技大学(ustc)的服务器上下载requests(基于python的第三方web框架) 国内常用的pip下载源列表:
1、阿里云 http://mirrors.aliyun.com/pypi/simple/
2、中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
3、豆瓣(douban) http://pypi.douban.com/simple/
4、清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
5、中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
5、运行python 程序:
(1)终端运行,直接在命令窗口输入 python 就会进入到python 解释器中 ,在mac命令窗口中,输入python 是2.x版本 输入 python3 是 3.x 版本
(2)使用ipython解释器编写代码 :pip install ipython 。 mac 下使用pip3 install ipython
(3)退出python环境:exis() 或者 ctrl+z
6、IDE环境搭建Pycharm : 集成开发环境 下载地址:
(1)下载地址:http://www.jetbrains.com/pycharm/download 选择社区版本进行安装
(2)配置参考如下图:
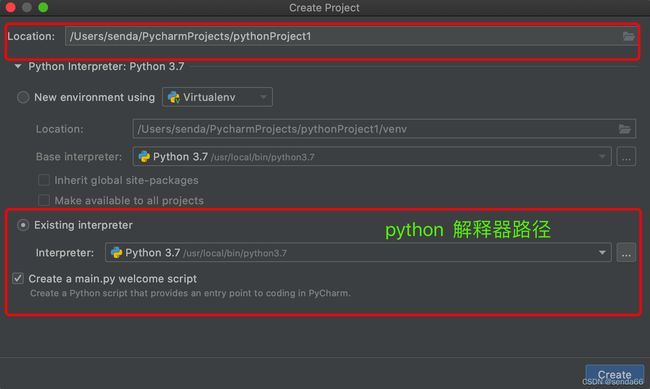
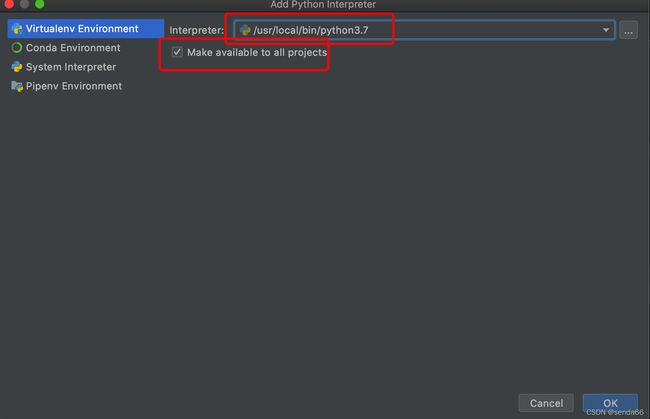
python 库使用
urllib库
安装,pip install urllib : 主要用来 模拟浏览器向服务器发送请求
解析库xpath :
需要结合 浏览器插件使用,浏览器插件 xpath :
1、为了在谷歌浏览器中使用xpath ,则需要在 谷歌浏览器中 加入xpath Helper 插件
“”"
1、下载插件
2、将插件进行解压,我在访达里面直接双击就解压了
3、打开谷歌浏览器,选择右上方三个小点,找到更多工具,找到扩展程序点击进去
4、打开右上角的开发者模式
5、将解压好的插件包拖进来就OK,注意:跟Windows不同的是这个就是一个文件夹,名为xpath,将这一整个文件夹拖进去
6、将xpath插件选择启用就完成了,如果浏览器上还是没有出现xpath插件,将插件重新加载就OK
xpath在mac上的打开与关闭的快捷键为
command + shift + x
“”"
安装lxml 库
“”"
xml是XML和HTML的解析器,其主要功能是解析和提取XML和HTML中的数据;lxml和正则一样,也是用C语言实现的,是一款高性能的python HTML、XML解析器,也可以利用XPath语法,来定位特定的元素及节点信息
HTML是超文本标记语言,主要用于显示数据,他的焦点是数据的外观
XML是可扩展标记语言,主要用于传输和存储数据,他的焦点是数据的内容
1、使用pip命令查看库列表
mac 下的库是在 ~/Library/Python/3.7/lib/python/site-packages/ 文件夹下,Windows的是在 python/script/文件夹下
pip3 list 此命令会出现警告,这时需要执行如下命令
python3 -m pip list
2、使用pip 升级lxml (最新版本为4.7.1)
python3 -m pip install --upgrade --user
“”"
xpath 解析
“”"
xpath 解析的文件包括两部分文件
(1)本地文件 使用 etree.parse()
(2)服务器响应文件 response.read().decode(‘utf-8’) 使用etree.HTML()
“”"
jsonpath 库
安装jsonpath : pip3 install jsonpath
jsonpath 只能解析本地数据,所以网络请求返回json 后 需要保存到本地再进行解析
BeautifulSoup 库
解析html 类似xpath
缺点:效率低,优点:接口人性化。用的比较少,但是有时候也会解决一些问题。
安装 pip install bs4
Selenium自动化工具库
如果我们通过url 直接访问,而不通过定制对象,那么此时有些网站会校验浏览器的,所以有些数据是无法获取到的,比如京东的首页。
这个时候 selenium 就会派上用场了,selenium能够模拟浏览器的功能,支持各种浏览器驱动,自动执行网页中的js代码,实现动态加载。自动化测试工具
安装及使用selenium
“”"
1、谷歌浏览器驱动下载:http://chromedriver.storage.googleapis.com/index.html 根据谷歌浏览器的版本进行下载
并解压,将驱动程序拷贝到项目的根目录下。
2、导入selenium : from selenium import webdriver
3、创建浏览器操作对象 :
path = “chromedriver”
browser = webdriver.chrome(path)
4、访问网站
“”"
Python requests库
官网说明文档:https://docs.python-requests.org/zh_CN/latest/ 它是python自带的库。
安装及使用 pip install requests
服务器代理
代理的常用功能
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源
3.提高访问速度
扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲
区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
4.隐藏真实IP
扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击。
代码配置代理
创建Reuqest对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求
常用框架
Scrapy 框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
包括:引擎、调度器、下载器、spiders、管道
总结
爬虫的重点与难点 在于如何找到合适的、有规律的界面进行数据爬取 以及 如何破解各种反爬手段:如cookie登录,绕过权限、提取界面隐藏属性等