flinksql流批一体计算平台为什么选型是Streamx
flink实时计算平台为什么选型是Streamx
一、概述
1.1 背景
Apache Flink被普遍认为是下一代大数据流计算引擎, 我们在使用 Flink 时发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方, 我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力终于诞生了今天的框架 —— StreamX, 项目的初衷是 —— 让 Flink 开发更简单, 使用StreamX开发,可以极大降低学习成本和开发门槛, 让开发者只用关心最核心的业务,无需关心idea开发完打包jar到集群执行。
1.2 特点
- 多版本Flink支持(1.11,x, 1.12.x, 1.13 )
- 一系列开箱即用的connectors
- 支持项目编译功能(maven 编译)
- 在线参数配置
- 支持
Applicaion模式,Yarn-Per-Job模式启动 - 快捷的日常操作(任务
启动、停止、savepoint,从savepoint恢复) - 支持火焰图
- 支持
notebook(在线任务开发) - 项目配置和依赖版本化管理
- 支持任务备份、回滚(配置回滚)
- 在线管理依赖(maven pom)和自定义jar
- 自定义udf、连接器等支持
- Flink SQL WebIDE
- 支持catalog、hive
- 任务运行失败发送告警邮件
- 支持失败重启重试
- 从任务
开发阶段到部署管理全链路支持 - …
二、系统架构
2.1 架构图

2.2 架构说明
streamx-core 定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发时 RunTime Content和一系列开箱即用的Connector,扩展了DataStream相关的方法,融合了DataStream和Flink sql api,简化繁琐的操作,聚焦业务本身,提高开发效率和开发体验
#2️⃣ streamx-pump
pump 是抽水机,水泵的意思,streamx-pump的定位是一个数据抽取的组件,类似于flinkx,基于streamx-core中提供的各种connector开发,目的是打造一个方便快捷,开箱即用的大数据实时数据抽取和迁移组件,并且集成到streamx-console中,解决实时数据源获取问题,目前在规划中
#3️⃣ streamx-console
streamx-console 是一个综合实时数据平台,低代码(Low Code)平台,可以较好的管理Flink任务,集成了项目编译、发布、参数配置、启动、savepoint,火焰图(flame graph),Flink SQL, 监控等诸多功能于一体,大大简化了Flink任务的日常操作和维护,融合了诸多最佳实践。旧时王谢堂前燕,飞入寻常百姓家,让大公司有能力研发使用的项目,现在人人可以使用, 其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案
三、对比其他开源实时计算平台
以下图片出自:https://mp.weixin.qq.com/s/yrYC8CowDGTefJWdiVtK5Q
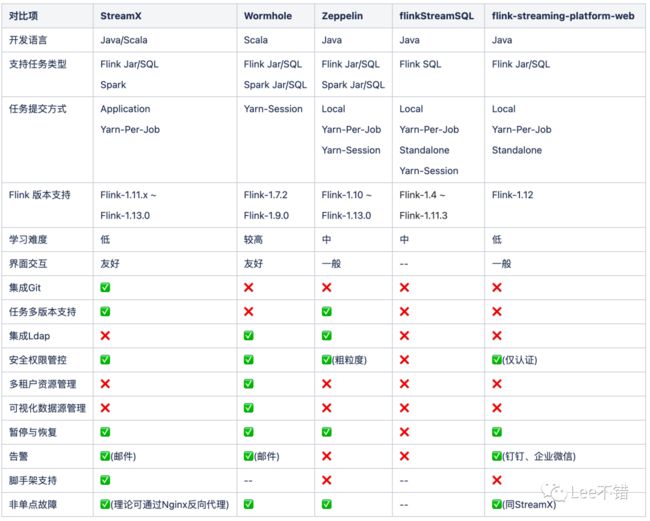
从上面的对比可以看出,StreamX、Wormhole、Zeppelin 都可以算得上不错的选择。但是因为 Wormhole 学习难度高,Flink-SQL不是原生语法,且当前社区已经停止更新维护;而 Zeppelin 的定位是一个交互式数据分析与可视化平台,对项目的管理和运维等并未很好的支持。最终 StreamX 成为了最好的选择。虽说 StreamX 是唯一的选择,但 StreamX 并不差,当前所有的功能可以说都是刚需;
四、优点
1.开发成本降低:多数 ETL 工作直接通过在平台创建 Flink-SQL 任务,学习成本低,检验数据方便,省去中间繁琐流程
2.部署&运维简单:代码开发完成提交到 Git 后,直接从平台侧完成构建与发布,做到开发、测试、部署、运维一体化
3.安全性提升:取消 Flink-Client 主机,避免任务提交管理混乱
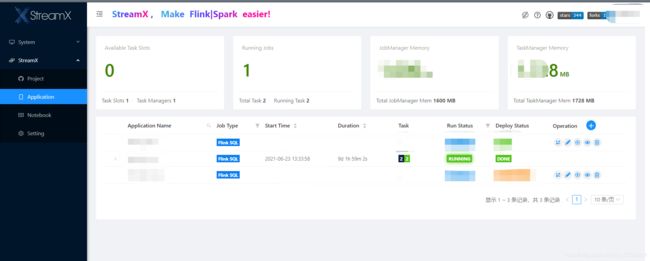
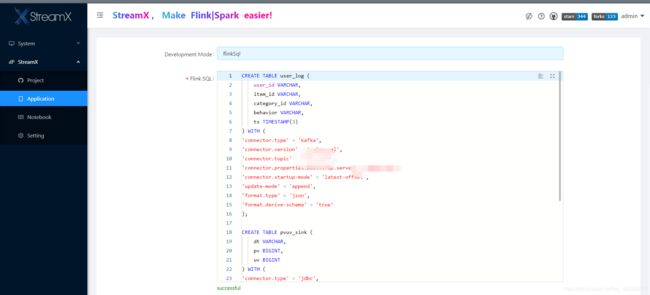
五、快速开始
详情请查看官网
http://www.streamxhub.com/zh/doc/console/quickstart/