Coursera-吴恩达-机器学习-(第10周笔记)大数据训练
此系列为 Coursera 网站Andrew Ng机器学习课程个人学习笔记(仅供参考)
课程网址:https://www.coursera.org/learn/machine-learning
Week 10 ——Large Scale Machine Learning
目录
- Week 10 Large Scale Machine Learning
- 目录
- 一 大数据的梯度下降
- 1-1 大数据
- 1-2 随机梯度下降
- 1-3 mini-batch 梯度下降
- 1-4 随机梯度下降的收敛性
- 二 大数据的高级技巧
- 2-1 在线学习
- 2-2 映射约简map reduce
一 大数据的梯度下降
在接下来的几个视频里 ,我们会讲大规模的机器学习, 就是用来处理大数据的算法。 如果我们看近5到10年的机器学习的历史 ,现在的学习算法比5年前的好很多, 其中的原因之一就是我们现在拥有很多可以训练算法的数据 。
1-1 大数据
为什么我们喜欢用大的数据集呢?
我们已经知道 得到一个高效的机器学习系统的最好的方式之一是 用一个低偏差的学习算法 ,然后用很多数据来训练它.
当然 ,在我们训练一个上亿条数据的模型之前 ,我们还应该问自己: 为什么不用几千条数据呢 ?也许我们可以随机从上亿条的数据集里选个一千条的子集,然后用我们的算法计算。
通常的方法是画学习曲线 :

- 如果你要绘制学习曲线,并且如果你的训练目标看起来像是左边的,而你的交叉验证集目标,theta的Jcv,那么这看起来像是一个高方差学习算法,所以加入额外的训练样例 提高性能。
- 右边看起来像传统的高偏见学习算法,那么看起来不大可能增加1亿到1亿将会更好,然后你会坚持n等于1000,而不是花费很多的精力弄清楚算法的规模如何。
- 正确的做法之一是增加额外的特性,或者为神经网络增加额外的隐藏单位等等,这样你就可以得到更接近于左边的情况,在这种情况下可能达到n 等于1000,这样就给了你更多的信心,试图添加基础设施(下部构造)来改变算法,使用更多的例子,可能实际上是一个很好的利用你的时间。
1-2 随机梯度下降
对于很多机器学习算法, 包括线性回归、逻辑回归、神经网络等等, 算法的实现都是通过得出某个代价函数 或者某个最优化的目标来实现的, 然后使用梯度下降这样的方法来求得代价函数的最小值。
当我们的训练集较大时 ,梯度下降算法则显得计算量非常大 ,在这段视频中 我想介绍一种跟普通梯度下降不同的方法 随机梯度下降(stochastic gradient descent) 。
他的主要思想是:
在每次迭代中不需要看所有的训练样例,但是在一次迭代中只需要看一个训练样例
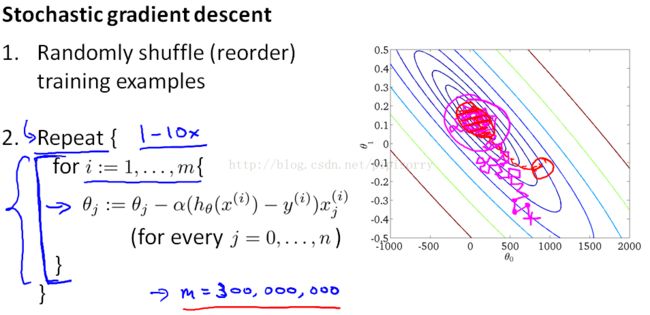
与梯度下降相比,每次迭代都要快得多,因为我们不需要总结所有的训练样例。但是每次迭代只是试图更好地适应单个训练样例。
随即梯度下降的劣势:当你运行随机梯度下降时,你会发现它通常会将参数向全局最小值的方向移动,但并不总是如此。事实上,当运行随机梯度下降时,它实际上并没有收敛到相同的固定值,最终做的是在一些接近全局最小值的区域连续四处流浪,但是它不会达到全局最小值并停留在那里。对于任何最实际的目的来说,这都是一个很好的假设。
所以:选择随机梯度下降还是批梯度下降?
答案:数据量大的时候使用随机梯度下降,而数据量不那么大的话还是用批梯度下降吧。
1-3 mini-batch 梯度下降
在之前的视频中 我们讨论了随机梯度下降 ,以及它是怎样比批量梯度下降更快。 在这次视频中, 让我们讨论基于这些方法的另一种变形, 叫做小批量梯度下降。 这种算法有时候甚至比随机梯度下降还要快一点 。

尤其是,小批量梯度下降可能要超过随机梯度下降,只有当你有一个良好的实现时,通过使用适当的向量化来计算余下的项
1-4 随机梯度下降的收敛性
现在你已经知道了随机梯度下降算法 ,但是当你运行这个算法时 你如何确保调试过程已经完成 并且能正常收敛呢? 还有 同样重要的是 你怎样调整随机梯度下降中学习速率α的值?
在这段视频中 我们会谈到一些方法来处理这些问题 ,确保它能收敛 以及选择合适的学习速率α 。
在过去的1000个示例中绘制平均成本的平均值,这些图可能看起来像几个例子,看图修正模型
如果你想要随机梯度下降实际收敛到全局最小值,那么你可以做的一件事是你可以慢慢地降低α的学习速率。迭代次数是你运行的随机梯度下降的迭代次数 ,所以这真的是你见过的培训例子的数量。
二 大数据的高级技巧
2-1 在线学习
什么情况下使用在线学习?如果你运行一个主要的网站有一个连续的用户流,在线学习算法是非常合理的。因为数据本质上是免费的,如果你有这么多的数据,那么数据本质上是无限的当然,如果我们只有少量的用户,而不是使用在线学习算法,那么最好将所有的数据保存在一个固定的训练集中,然后运行一些算法。但是如果你真的有一个连续的数据流,那么在线学习算法可以是非常有效的。
这种在线学习算法的一个有趣效果就是,它能够适应不断变化的用户偏好。尤其是,如果随着时间的推移,由于经济的变化,用户的价格敏感度会降低,他们愿意支付更高的价格。如果你开始有新类型的用户来到你的网站。这种在线学习算法也可以适应不断变化的用户喜好,并跟踪你不断变化的用户愿意支付的种类。而且,因为如果你的用户池发生了变化,那么这些更新到你的参数theta将只是适应你的参数,
在线学习的优势:
1. 可以适应用户的品味变化。
2. 允许我们对流数据进行学习。
2-2 映射约简map reduce
在上面几个视频中 我们讨论了 随机梯度下降 以及梯度下降算法的 其他一些变种, 包括如何将其 运用于在线学习 ,然而所有这些算法 都只能在一台计算机上运行 。
但是 有些机器学习问题 太大以至于不可能 只在一台计算机上运行 ,有时候 它涉及的数据量如此巨大 以至于不论你使用何种算法 ,你都不希望只使用 一台计算机来处理这些数据 。
因此 在这个视频中 我希望介绍 进行大规模机器学习的另一种方法 称为映射约减 (map reduce) 方法。

注意:
1. 如果没有网络延迟,并且没有网络通信的费用来回发送数据,则可以达到4倍的速度。
2. 如果您只有一台具有多个处理内核的计算机,则MapReduce也可以适用。因此,与在数据传感器内的不同计算机上使用这种方法相比,网络延迟的问题要少得多。
3. 一些好的MapReduce开源实现,叫做Hadoop,使用你自己的实现或者使用别人的开源实现,你可以使用这些想法来并行化学习算法,并让它们在更大的数据集上运行。