MySQL视图+存储过程+触发器
第一部分.视图
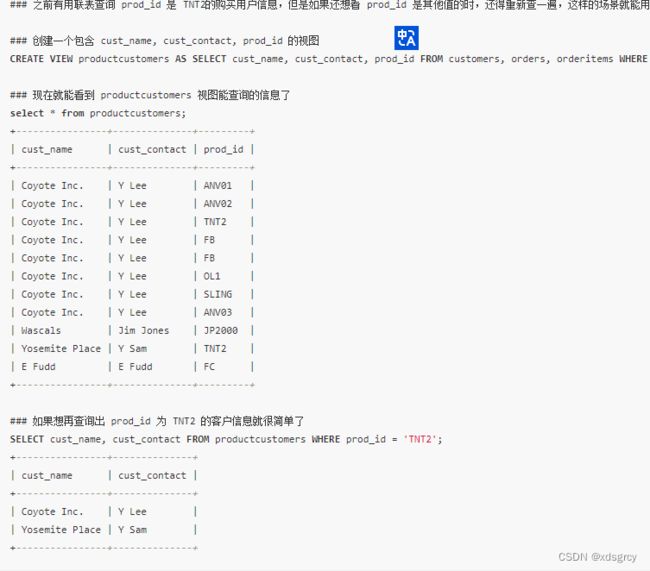
视图仅仅是用来查看存储在别处的数据的一种设施,本身不包含数据,返回的数据都是从其他表中检索出来的,视图能更改数据格式和表示,最常见的应用就是重用 SQL 语句,简化复杂的 SQL 操作。
操作视图
创建视图
CREATE VIEW
查看创建视图的语句
SHOW CREATE VIEW viewname
删除视图
DROP VIEW viewname
更新视图时,可以先 DROP 然后再 CREATE 或者使用 CREATE OR REPLACE VIEW
注意
- 视图必须唯一命名(不能跟别的视图和表重名)
- 对于可以创建的视图数量没有限制。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造一个新的视图。
- ORDER BY 可以用在视图中,但如果从该视图检索数据的 SELECT 中也含有 ORDER BY ,那么视图中的 ORDER BY 会被覆盖。
- 视图不能索引,也不能有关联的触发器或默认值。
- 视图可以和表一起使用。
- 视图一般用于检索(SELECT)而不用于更新(INSERT, UPDATE, DELETE),因为更新一个视图相当于更新其基表,如果不能正确地确定被更新的基数据,则不允许更新。
第二部分.存储过程:
概述
由MySQL5.0 版本开始支持存储过程。
如果在实现用户的某些需求时,需要编写一组复杂的SQL语句才能实现的时候,那么我们就可以将这组复杂的SQL语句集提前编写在数据库中,由JDBC调用来执行这组SQL语句。把编写在数据库中的SQL语句集称为存储过程。
存储过程:(PROCEDURE)是事先经过编译并存储在数据库中的一段SQL语句的集合。调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是很有好处的。
就是数据库 SQL 语言层面的代码封装与重用。
存储过程就类似于Java中的方法,需要先定义,使用时需要调用。存储过程可以定义参数,参数分为IN、OUT、INOUT类型三种类型。
IN类型的参数表示接受调用者传入的数据;
OUT类型的参数表示向调用者返回数据;
INOUT类型的参数即可以接受调用者传入的参数,也可以向调用者返回数据。
优点:
存储过程是通过处理封装在容易使用的单元中,简化了复杂的操作。
简化对变动的管理。如果表名、列名、或业务逻辑有了变化。只需要更改存储过程的代码。使用它的人不用更改自己的代码。
通常存储过程都是有助于提高应用程序的性能。当创建的存储过程被编译之后,就存储在数据库中。
但是,MySQL实现的存储过程略有所不同。
MySQL存储过程是按需编译。在编译存储过程之后,MySQL将其放入缓存中。
MySQL为每个连接维护自己的存储过程高速缓存。如果应用程序在单个连接中多次使用存储过程,则使用编译版本,否则存储过程的工作方式类似于查询。
存储过程有助于减少应用程序和数据库服务器之间的流量。
因为应运程序不必发送多个冗长的SQL语句,只用发送存储过程中的名称和参数即可。
存储过程度任何应用程序都是可重用的和透明的。存储过程将数据库接口暴露给所有的应用程序,以方便开发人员不必开发存储过程中已支持的功能。
存储的程序是安全的。数据库管理员是可以向访问数据库中存储过程的应用程序授予适当的权限,而不是向基础数据库表提供任何权限。
缺点:
如果使用大量的存储过程,那么使用这些存储过程的每个连接的内存使用量将大大增加。
此外,如果在存储过程中过度使用大量的逻辑操作,那么CPU的使用率也在增加,因为MySQL数据库最初的设计就侧重于高效的查询,而不是逻辑运算。
存储过程的构造使得开发具有了复杂的业务逻辑的存储过程变得困难。
很难调试存储过程。只有少数数据库管理系统允许调试存储过程。不幸的是,MySQL不提供调试存储过程的功能。
开发和维护存储过程都不容易。
开发和维护存储过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能导致应用程序开发和维护阶段的问题。
对数据库依赖程度较高,移值性差。
MySQL存储过程的定义
存储过程的基本语句格式:
DELIMITER $$
CREATE
/*[DEFINER = { user | CURRENT_USER }]*/
PROCEDURE 数据库名.存储过程名([in变量名 类型,out 参数 2,...])
/*LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'*/
BEGIN
[DECLARE 变量名 类型 [DEFAULT 值];]
存储过程的语句块;
END$$
DELIMITER ;● 存储过程中的参数分别是 in,out,inout三种类型;
in代表输入参数(默认情况下为in参数),表示该参数的值必须由调用程序指定。
ou代表输出参数,表示该参数的值经存储过程计算后,将out参数的计算结果返回给调用程序。
inout代表即时输入参数,又是输出参数,表示该参数的值即可有调用程序制定,又可以将inout参数的计算结果返回给调用程序。
● 存储过程中的语句必须包含在BEGIN和END之间。
● DECLARE中用来声明变量,变量默认赋值使用的DEFAULT,语句块中改变变量值,使用SET 变量=值;
调用存储过程:
CALL 存储过程名();
第三部分.触发器:
一、基本概念:
1. 触发器是一种特殊类型的存储过程,它不同于存储过程,主要是通过事件触发而被执行的,即不是主动调用而执行的;而存储过程则需要主动调用其名字执行
2. 触发器:trigger,是指事先为某张表绑定一段代码,当表中的某些内容发生改变(增、删、改)的时候,系统会自动触发代码并执行。
二.作用:
可在写入数据前,强制检验或者转换数据(保证护数据安全)
触发器发生错误时,前面用户已经执行成功的操作会被撤销,类似事务的回滚
三.创建触发器
基本语法
delimiter 自定义结束符号
create trigger 触发器名字 触发时间 触发事件 on 表 for each row
begin
-- 触发器内容主体,每行用分号结尾
end
自定义的结束符合
delimiter ;on 表 for each:
触发对象,触发器绑定的实质是表中的所有行,因此当每一行发生指定改变时,触发器就会发生
四.触发时间
当 SQL 指令发生时,会令行中数据发生变化,而每张表中对应的行有两种状态:数据操作前和操作后
before:表中数据发生改变前的状态
after:表中数据发生改变后的状态
PS:如果 before 触发器失败或者语句本身失败,将不执行 after 触发器(如果有的话)
五.触发事件
触发器是针对数据发送改变才会被触发,对应的操作只有
INSERT
DELETE
UPDATE
注意事项:
1. 在 MySQL 5 中,触发器名必须在每个表中唯一,但不是在每个数据库中唯一,即同一数据库中的两个表可能具有相同名字的触发器
2.每个表的每个事件每次只允许一个触发器,因此,每个表最多支持 6 个触发器,before/after insert、before/after delete、before/after update
六.查看触发器:
1.查看全部触发器
语法:
show triggers;
2.查看触发器的创建语句:
show create trigger 触发器名字;
七.触发触发器:
基本语法:
drop trigger 触发器名字
触发不是自动手动触发的,而是在对应的事件发生后才会触发。比如我们创建的触发器,只有在对订单表进行数据操作的时候,触发器才会执行
八.删除触发器
触发器不能修改,只能删除
语法:
drop trigger + 触发器名字
九.触发器应用
触发器针对的是数据库中的每一行记录,每行数据在操作前后都会有一个对应的状态,触发器将没有操作之前的状态保存到 old 关键字中,将操作后的状态保存到 new 中
语法:old/new.字段名
需要注意的是,old 和 new 不是所有触发器都有
十.优缺点
优点
触发器可以通过数据库中的关联表实现级联更改,即一张表数据的改变会影响其他表的数据
可以保证数据安全,并进行安全校验
缺点
过分依赖触发器,影响数据库的结构,增加数据库的维护成本
如果总结的不到位,欢迎评论区指正改正。谢谢观看!!