Redis分布式锁解析&源码分析
Redis分布式锁解析&源码分析
- 概述
- 实战
-
- 简单的分布式锁
- Redisson实现分布式锁
- Redission源码分析
-
- 构造方法
- 获取锁lock
- 解锁
- 锁失效
- 红锁
- 案例分析
-
- 原始的写法
- 进化版一
- 进化版二(分布式锁DCL)
- 进化版三(双写)
- 终极进化版(多级缓存)
- 布隆过滤器
概述
分布式锁在分布式系统出现过后就一直是一个需要重点关注的话题,一提到分布式系统,不得不想到分布式锁和分布式事务,在以往的单体应用场景下,使用jvm内置的锁就可以解决线程安全问题,但是在分布式场景下,不得比借助一些组件来完成在分布式场景下保证线程安全,像使用数据库或者一些共享存储也可解决,但随着Redis的广泛使用,在现在的业务场景中,越来越多的公司大量使用Redis来解决在高并发场景下提供系统吞吐量的中间件之一,但是Redis能做的事情是非常多的,它不仅仅是一个数据缓存的中间件,它还能做分布式场景下的订阅于发布,分布式队列、分布式锁等一些工作,今天我们就来聊下Redis的分布式锁。
实战
我们有一个场景,在互联网的场景中,发起订单扣除库存的场景是很场景的,也是很好理解的,比如某商家做活动,拿出一批商品,比如有1000的库存来搞活动,那么程序需要保证的是 这1000个商品不能超卖,也就是这1000个商品卖给1000个用户,如果出现超卖的情况那么就是程序出现了问题,这是一个很简单的问题,但是如果在分布式场景下,这就不是一个简单的问题,程序要保证线程安全,也就是要保证所有的出库动作要按顺序来执行,也就是串行执行,不能出现并发扣减库存的情况,如果在单机情况下,可以简单通过内置锁或者AQS锁来完成,但是在分布式场景下就变的更复杂了,要考虑到的场景非常多,根据这些场景,我们来进行分析。
简单的分布式锁
我们来看一段程序,通过程序来解析分布式锁的实现
@RequestMapping("/deduct_stock")
public String deductStock() {
try {
synchronized (this){
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); // jedis.get("stock")
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + ""); // jedis.set(key,value)
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
}
}catch (Exception e){
e.printStackTrace();
return "error";
}
return "end";
}
显然这段程序不是一个线程安全的程序,在分布式场景下是有问题的,如果并发不大情况下,也有可能不会出错 ,但是作为程序员,写的代码要严谨,这个方法肯定是有问题的,只能解决单机情况的线程安全,我们修正一下程序如下:
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "product:1001";
String value = Thread.currentThread().getId() + ":" + UUID.randomUUID().toString();
stringRedisTemplate.opsForValue().setIfAbsent(lockKey, value, 30, TimeUnit.SECONDS);
try {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); // jedis.get("stock")
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + ""); // jedis.set(key,value)
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} catch (Exception e) {
e.printStackTrace();
return "error";
} finally {
if (stringRedisTemplate.opsForValue().get(lockKey).equals(value)) {
stringRedisTemplate.delete(lockKey);
}
}
return "end";
}
我们使用redis的setnx来进行分布式锁,setnx在相同的key的情况下,只有第一次能成功,在java里面调用过后,如果设置成功以后返回的true,如果key已经存在返回的false
格式: setnx key value 将 key 的值设为 value ,当且仅当 key 不存在。 若给定的 key 已经存在,则
SETNX 不做任何动作。 SETNX 是『 SET if Not eXists』 (如果不存在,则 SET)的简写。
所以上述代码:
stringRedisTemplate.opsForValue().setIfAbsent(lockKey, value, 30, TimeUnit.SECONDS);
表示的意思就是设置lockKey ,value是方法生成的一个线程Id+uuid,ttl=30s,超过30s过后自动清除,所以整句话的意思就是说这里加了一个ttl的锁,如果某个线程获取到锁以后在执行过程中万一该系统挂了,那么这个key不会清除,其他分布式部署的系统将永远获取不到锁,这导致这个业务没有办法做下去,所以加了一个30s的超时时间,也就是说当系统挂了的情况下,最多30s自动解锁的意思,我们需要注意的是这个setnx的指令是设置key和设置超时时间是一起执行的,因为这两个动作要具有原子性,否则就有可能出现其他情况,比如当设置了key过后,准备设置超时时间时,挂了,那么也会有问题,所以这需要一起执行,当成是一个原子指令;
如果程序正常执行了,在finally里面执行解锁,其他线程就能获取到锁,但是这样程序就真的没有问题了吗?
问题1:finally里面的的代码是解锁代码,解锁代码先获取这个key,然后判断这个key对应的value是不是我这个线程设置的值,如果是就释放锁,咋一看确实没有问题,但是我们做分布式系统的时候一定要有分布式思维?这两行代码没啥问题,但是从分布式场景的思维去思考就知道,这两行代码不是一个原子操作,虽然导致这两行代码执行出现异常的情况非常少,但是从程序的严谨度来看,它还是有可能会出现问题的,所以我们要把它变成一个原子操作,怎么变?redis是一个单线程的任务执行,但是没有提供命令去获取key然后判断传入的value是否相等,解决方案只有采用lua脚本将它作为一个原子指令去封装执行;
问题2:从上面的设置的超时时间来看会有什么问题呢?那么会不会出现一个问题就是线程拿到锁以后,开始执行,其他线程被阻塞,但是你设置的超时时间是30s,那么会不会出现30s后,拿到锁的线程没有执行完成,这个时候锁失效了,那么其他线程也就获取到锁了,也可以执行了,那么出现的问题就是在这个场景下,数据安全问题得不到 保证了,也就是在一些并发较高的情况下,万一程序执行出现点慢的情况就会出现线程安全问题,虽然这种情况出现的概率不会太高,但是作为一个严谨的开发者来说,这也不是不能容忍的一件事。
基于上面的两种问题,我们该如何解决了,需要解决的是指令执行的原子问题和锁续命的事情,如果能解决的话并且性能较高的话就能解决这个分布式场景下线程安全的问题了,那么怎么解决呢?
1、锁的原子问题可借助于lua脚本,将所有的在一个事物里面的指令都放在lua脚本里面执行,保证所有的指令都不要么全部执行,要么不执行,反正就是不能一个成功,一个失败的情况;
2、锁续命的问题:这个就是要开发者自己去实现了,你可以在获取到一个锁以后开启一个线程任务去判断任务是否执行完成,如果没有执行完成,就行锁的续命,如果执行完成了,设置的锁就不存在了,其他线程就能得到锁了。
Redisson实现分布式锁
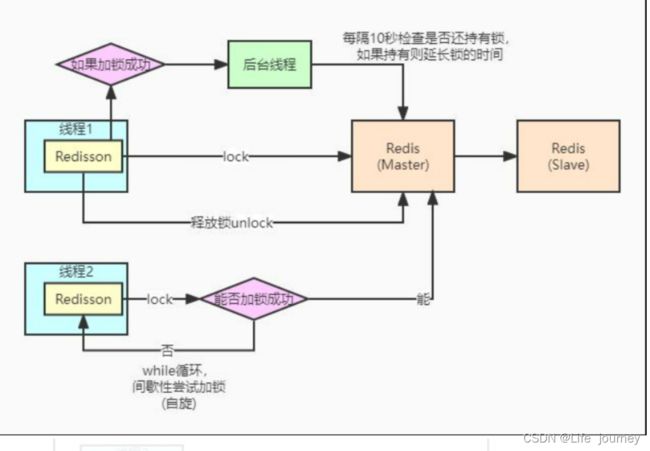
Redisson解决了分布式锁的问题,它就是对Redis的一个高度封装,Redisson是架设在Redis基础上的一个Java驻内存数据网格(In-Memory Data Grid)。Redisson在基于NIO的Netty框架上,充分的利用了Redis键值数据库提供的一系列优势,在Java实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作.
Redssion使用就非常简单了,使用越是简单的框架,底层封装的越多,我是这么认为的,该成Redssion的程序如下:
@RequestMapping("/deduct_stock")
public String deductStock() {
String lockKey = "product:1001";
RLock lock = redisson.getLock(lockKey);
lock.lock();
try {
int stock = Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); // jedis.get("stock")
if (stock > 0) {
int realStock = stock - 1;
stringRedisTemplate.opsForValue().set("stock", realStock + ""); // jedis.set(key,value)
System.out.println("扣减成功,剩余库存:" + realStock);
} else {
System.out.println("扣减失败,库存不足");
}
} catch (Exception e) {
e.printStackTrace();
return "error";
} finally {
lock.unlock();
}
return "end";
}
就三行代码,加锁解锁就2行代码,非常简单,但是它解决了我们上述没有解决的问题, 原子指令的问题和锁续命问题,它的使用和我们的Aqs的锁使用一样,因为它作为一个分布式锁,实现了jdk的标准接口Lock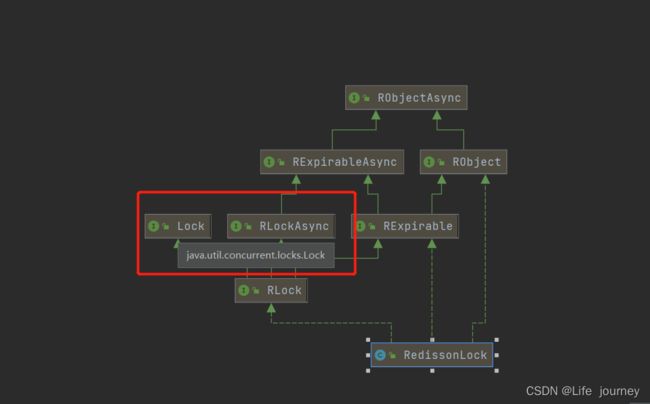
所以它的使用和AQS的锁使用是一样的,在java生态中,Lock已经是一个标准的,任何的好的分布式锁都应该实现这个标准,来指定的自己的锁。
Redission源码分析
构造方法
当我们在上面的程序中调用getLock(lockKey)过后就会进入Redisson中的getLock方法,其中name就是我们传入的lockKey
public RLock getLock(String name) {
return new RedissonLock(this.connectionManager.getCommandExecutor(), name);
}
//构造一个RedissonLock对象,包括执行器commandExecutor和我们传入的lockKey
public RedissonLock(CommandAsyncExecutor commandExecutor, String name) {
super(commandExecutor, name);
this.commandExecutor = commandExecutor;
this.id = commandExecutor.getConnectionManager().getId();
//这里初始化了一个看门狗时间,watch dog,就是用来续命的watch dog,默认是30s,这值是可以改的,在构建RedssionClient的时候可以动态传入
//watch dog的续命时间
this.internalLockLeaseTime = commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout();
}
获取锁lock
org.redisson.RedissonLock#lock()
public void lock() {
try {
this.lockInterruptibly();
} catch (InterruptedException var2) {
Thread.currentThread().interrupt();
}
}
调用的是一个可中断的获取锁逻辑,就是参照了jdk的锁标准
public void lockInterruptibly() throws InterruptedException {
this.lockInterruptibly(-1L, (TimeUnit)null);
}
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
long threadId = Thread.currentThread().getId();
//这里会调用尝试获取锁,传入了一个线程ID,leaseTime为-1,和时间单位,该方法调用完成以后会返回一个ttl
//ttl如果为空就代表获取锁成功,可直接返回了,如果获取锁失败则返回的ttl就是代表大概需要等待多久才能获取到锁
//比如去获取锁的时候如果失败,就会返回上个获取锁的剩余时间
Long ttl = this.tryAcquire(leaseTime, unit, threadId);
if (ttl != null) {
//获取锁失败,订阅一个频道,等频道有消息写入,当有消息写入过后进行信号量的解锁
RFuture<RedissonLockEntry> future = this.subscribe(threadId);
this.commandExecutor.syncSubscription(future);
try {
while(true) {
//进入死循环的时候尝试获取锁,如果ttl返回null代表获取锁成功,否则继续循环
ttl = this.tryAcquire(leaseTime, unit, threadId);
if (ttl == null) {
return;
}
if (ttl >= 0L) {
//ttl就是返回的代表还需要等待多久释放锁,所以这里就getLatch返回了一个信号量进行
//lock,这个调用的tryAcquire是jdk的信号量的锁,这里有锁就代表有地方解锁
//getLatch()是一个Semaphore
this.getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
this.getEntry(threadId).getLatch().acquire();
}
}
} finally {
//移除订阅功能
this.unsubscribe(future, threadId);
}
}
}
//往频道里面订阅一个消息
protected RFuture<RedissonLockEntry> subscribe(long threadId) {
return PUBSUB.subscribe(this.getEntryName(), this.getChannelName(), this.commandExecutor.getConnectionManager().getSubscribeService());
}
//频道名称
String getChannelName() {
return prefixName("redisson_lock__channel", this.getName());
}
org.redisson.pubsub.LockPubSub#onMessage订阅消息通知方法
protected void onMessage(RedissonLockEntry value, Long message) {
//就是判断发布的解锁消息是否订阅的消息一致,发布的消息是一个0
if (message.equals(unlockMessage)) {
//如果是,就获取lockey对应的Semaphore信号量进行解锁,信号量的解锁就是调用的jdk的代码去解锁的
value.getLatch().release();
while(true) {
Runnable runnableToExecute = null;
synchronized(value) {
Runnable runnable = (Runnable)value.getListeners().poll();
if (runnable != null) {
if (value.getLatch().tryAcquire()) {
runnableToExecute = runnable;
} else {
value.addListener(runnable);
}
}
}
if (runnableToExecute == null) {
return;
}
runnableToExecute.run();
}
}
}
private Long tryAcquire(long leaseTime, TimeUnit unit, long threadId) {
return (Long)this.get(this.tryAcquireAsync(leaseTime, unit, threadId));
}
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
if (leaseTime != -1L) {
return this.tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
//异步获取锁
RFuture<Long> ttlRemainingFuture = this.tryLockInnerAsync(this.commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
//添加一个监听器,来监听锁获取的情况
ttlRemainingFuture.addListener(new FutureListener<Long>() {
public void operationComplete(Future<Long> future) throws Exception {
if (future.isSuccess()) {
//返回的这个ttlRemaining 就是上面获取锁返回的,如果返回null代表获取成功,否则获取锁
//失败,所以从这里可以看出这个监听器是为了获取锁成功以后对锁进行续命
Long ttlRemaining = (Long)future.getNow();
if (ttlRemaining == null) {
//开启一个循环调度进行续命
RedissonLock.this.scheduleExpirationRenewal(threadId);
}
}
}
});
return ttlRemainingFuture;
}
}
//执行lua脚本获取锁
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
//计算锁的时间,换算为毫秒
this.internalLockLeaseTime = unit.toMillis(leaseTime);
//执行lua脚本
return this.commandExecutor.evalWriteAsync(this.getName(), LongCodec.INSTANCE, command,
//下面的lua脚本有三个逻辑:
//第一个if判断传进来的key=lockKey是否存在,如果不存在,那不用说,直接用hash结构set,其中
//KEYS[1]=lockKey,ARGV[2]=redission用uuid+线程id生成一个value作为hash的field,值为1,为什么这里要用
//1呢?因为redission考虑到了重入锁,所以在
//第二个if语句里面:
//redis.call('hexists', KEYS[1], ARGV[2]) == 1这句话的意思就是说hash表里面lockKey的fieldARGV[2]
// 是否是等于1,如果是就代表是同一个线程的重入,所以通过hincrby进行加1,然后重置锁的失效时间,这就是
// 锁的可重入锁逻辑,锁的重入次数+1,锁的失效时间重置,和aqs的重入锁逻辑类似
前面两个if都是能够满足获取锁的逻辑,所以返回null,在redis中返回nil在java里面就是null,返回null代表获取锁
第三个if就是获取锁失败了,通过指令redis.call('pttl', KEYS[1])可返回lockKey的剩余失效时间
"if (redis.call('exists', KEYS[1]) == 0)
then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);"
//第一个参数代表key的数组,后面的参数都是value,对应上面的ARGV
Collections.singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
//锁续命
private void scheduleExpirationRenewal(final long threadId) {
if (!expirationRenewalMap.containsKey(this.getEntryName())) {
//使用netty中的timetask对锁进行续命
Timeout task = this.commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
public void run(Timeout timeout) throws Exception {
RFuture<Boolean> future = RedissonLock.this.commandExecutor.evalWriteAsync(
RedissonLock.this.getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
//判断lockKey是否还在,还在的话代表锁还没释放,也就是获取锁的线程还没执行完成,通过
//pexpire进行续命,也就是重置锁失效时间,pexpire设置的时间是毫秒,expire是秒
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
//重置锁失效时间,续命
then redis.call('pexpire', KEYS[1], ARGV[1]);
//redis返回的1,在java里面代表true,0代表为false
return 1; end;
return 0;",
//getName()就是最外面传入的lockKey,我们例子里面的lockKey=product:1001
Collections.singletonList(RedissonLock.this.getName()), new Object[]{RedissonLock.this.internalLockLeaseTime, RedissonLock.this.getLockName(threadId)});
future.addListener(new FutureListener<Boolean>() {
public void operationComplete(Future<Boolean> future) throws Exception {
RedissonLock.expirationRenewalMap.remove(RedissonLock.this.getEntryName());
if (!future.isSuccess()) {
RedissonLock.log.error("Can't update lock " + RedissonLock.this.getName() + " expiration", future.cause());
} else {
//返回true代表锁续命成功,线程还未执行完成,继续递归调用进行锁续命,否则就是
//完成了,可以获取锁了
if ((Boolean)future.getNow()) {
RedissonLock.this.scheduleExpirationRenewal(threadId);
}
}
}
});
}
//这个调度器是watch dog的时间3,如果30s,就是10s执行一次
}, this.internalLockLeaseTime / 3L, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(this.getEntryName(), task) != null) {
task.cancel();
}
}
}
解锁
org.redisson.RedissonLock#unlock
public void unlock() {
Boolean opStatus = (Boolean)this.get(this.unlockInnerAsync(Thread.currentThread().getId()));
if (opStatus == null) {
throw new IllegalMonitorStateException("attempt to unlock lock, not locked by current thread by node id: " + this.id + " thread-id: " + Thread.currentThread().getId());
} else {
//opStatus=true代表解锁成功
if (opStatus) {
//这里是取消锁续命的调度器
this.cancelExpirationRenewal();
}
}
}
void cancelExpirationRenewal() {
Timeout task = (Timeout)expirationRenewalMap.remove(this.getEntryName());
if (task != null) {
//取消锁续命的调度器
task.cancel();
}
}
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return this.commandExecutor.evalWriteAsync(this.getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
//解锁逻辑
//第一个if判断lockKey是否存在,如果不不存在则锁失效了直接往频道发布一个消息,告知lock那边可以解锁了
//第二个if判断lockkey的field是否是传入的ARGV[3],就是判断是不是你这个线程加的锁,如果不是就不能解锁
//接下来对lockkey-1,在加锁的时候是设置的1,如果重入是+1,所以这里减一,if判断counter是否为0,如果为0表示没有重入
//则正常解锁,删除lockKey,往频道发布一个消息通知lock那边进行解锁,如果不为0,代表是重入锁,又开始
//重置锁的失效时间
"if (redis.call('exists', KEYS[1]) == 0)" +
" then redis.call('publish', KEYS[2], ARGV[1]);" +
" return 1; " +
"end;" +
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then" +
" return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);" +
" if (counter > 0) then" +
" redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; else redis.call('del', KEYS[1]);" +
" redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;",
// this.getChannelName():频道名称,和订阅那边对应
//LockPubSub.unlockMessage发布的消息,是一个0
Arrays.asList(this.getName(), this.getChannelName()), new Object[]{LockPubSub.unlockMessage, this.internalLockLeaseTime, this.getLockName(threadId)});
}
锁失效
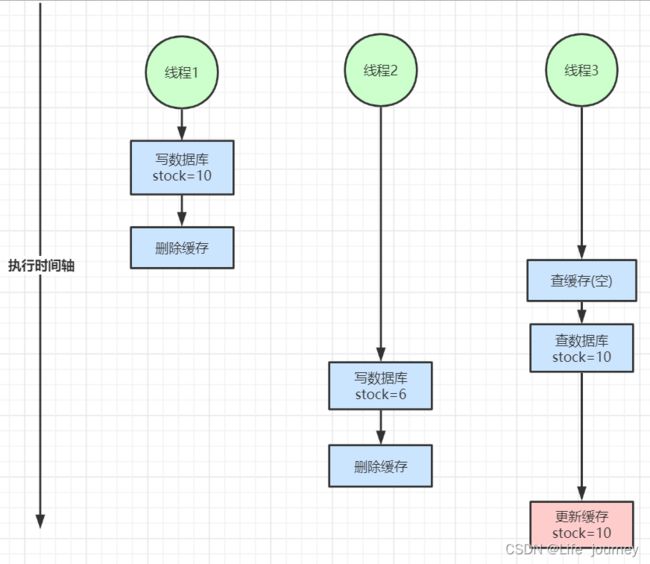
使用Redisson真的就是没有问题的吗?现在很多公司在使用分布式锁场景下,基本上都会采用Redisson,使用它是因为基于Redis的高性能,因为Redis是基于内存的一个数据库,而且最最重要的是Redis在CAP架构体系中是一个AP架构,也就是保证了可用性,在一定程度上牺牲了一致性,所以从Redis的架构来说,我们可以反向分析下Redis的分布式锁真的就是非常可靠的吗?其实这个和Redssion关系不大,Redisson是基于Redis封装的一个框架,因为Redis是一个AP架构,像Nacos也是默认AP架构,在AP架构下,可用性是非常好的,就算架构里面出现问题也能及时调整过来然后也能提供服务,但是它的数据就不能保证,不能完全保证一致性,所以基于这个问题,我们可以思考下为什么Redis做分布式锁总会有些问题,但是这些问题都是可能在极端情况下会出现,不一定会出现,只是分析在AP架构下的问题,我们知道不管Reids是主从架构、哨兵架构还是集群架构都会有主节点和从节点,从节点基本上都是为了容灾而设计的,如下图:
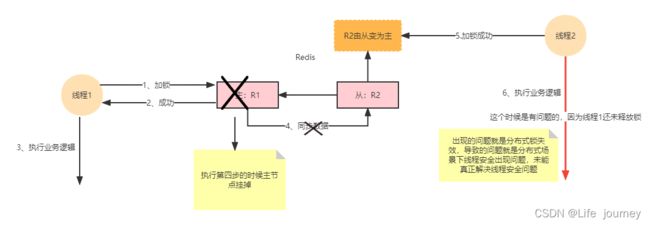
如上图,redis的架构在做分布式锁的时候在一些极端的情况下真的是会出现这种问题的,我们都知道redis的持久化方案有两种,一种是RDB,也就是在多少时间内执行了多少次命令会持久化一个rdb快照,还有一种是aof,aof的选项有好几个,但是如果为了redis的高性能基本都会选择在没1s执行一次aof,不会每次指令都会执行aof,所以对于采用aof持久化方案来说,最多丢失1s的数据,对于并发不是很高的系统来说,问题不大,如果并发量特别高的情况下,这1s数据就有可能是分布式锁的数据,所以在上图中描述的时候当线程1获取到锁以后执行业务逻辑,但是这个时候主节点还未进行同步数据到从节点,主节点挂掉,从节点丢失线程1的分布式锁数据,这个时候R2选举为主节点,它是没有线程1的锁数据的,所以线程2可以正常获取到锁,这样就将一个串行执行变成了并行执行,已经失去了对共享资源的保护,这种情况在分布式场景下也可称为分布式线程安全问题;
但是还是要说这种情况出现的概率太小了,只是在分析问题的时候要全面,自己实现的时候也要严谨,严谨点总会没错,根据自己的业务体量去分析,也不要过度的分析和设计,如果并发量很小的情况下不用考虑太多。
红锁
RedLock在网上说是可以解决的,我不这么认为,红锁就是搞了几个redis的没有任何关系的节点来做分布式锁,只有半数以上的节点加锁成功才会认为加锁成功,但是如果在极端情况下也是不行的,比如有3个redis的毫不相干的节点就是用来做红锁的,加锁成功的条件是3个redis节点的半数节点加锁成功代表加锁成功,但是如果加锁成功以后有一个节点挂了,另外的线程去加锁的时候这个时候只有2个节点,可能不会成功,但是如果由于一些原因导致重启的redis节点数据未能持久化丢失锁数据,第二个线程也一样的能加锁成功,就算你redis加从节点也同样会有问题,分布式锁这种业务场景下没有百分之百的方案,只能尽可能保证,再我看来,用redis的红锁还不如直接采用zookeeper来做分布式锁,zookeeper天生的CP架构,保证了数据的一致性协议,它的ZAB协议能保证分布式锁正确性,因为Zookeeper每次写节点数据是要半数以上节点成功以后才会认为成功,这样就算leader挂了,新的leader节点也有之前的节点数据,所以Zookeeper在分布式锁场景下,稳定性是比Redis好,但是为什么很少有人用Zookeeper来做分布式锁呢?
1、项目中redis是很常用的中间件,而且Redis基于内存数据库的高性能是首选,主要是性能高啊,这是最重要的,就算偶尔出现点缓存问题也能接受。
2、zookeeper如果在整个架构中没有其他用处,只是为了做一个分布式锁而引入的话,会加大系统的维护成本,而且它的性能肯定是不如Redis的。
红锁例子:
public String redlock() {
String lockKey = "product_001";
//这里需要自己实例化不同redis实例的redisson客户端连接,这里只是伪代码用一个redisson客户端简化了
RLock lock1 = redisson.getLock(lockKey);
RLock lock2 = redisson.getLock(lockKey);
RLock lock3 = redisson.getLock(lockKey);
/**
* 根据多个 RLock 对象构建 RedissonRedLock (最核心的差别就在这里)
*/
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
try {
/**
* waitTimeout 尝试获取锁的最大等待时间,超过这个值,则认为获取锁失败
* leaseTime 锁的持有时间,超过这个时间锁会自动失效(值应设置为大于业务处理的时间,确保在锁有效期内业务能处理完)
*/
boolean res = redLock.tryLock(10, 30, TimeUnit.SECONDS);
if (res) {
//成功获得锁,在这里处理业务
}
} catch (Exception e) {
throw new RuntimeException("lock fail");
} finally {
//无论如何, 最后都要解锁
redLock.unlock();
}
return "end";
}
案例分析
我这边有个简单的案例,这个案例在大多数的业务场景中都存在的,就是一个简单的redis缓存的案例,案例描述如下:
有个产品的业务,类似于电商网站的商品业务,我们都知道在京东上有很多的产品,起码过亿,但是京东上不可能所有的产品都放到缓存中,其实在网站上每天浏览的人很多,但是不是所有的产品都是热的,大多数人都是只浏览商品,下单的时候是比较少的,还要考虑到被别人攻击,虽然说前端可以做限流,防止攻击,但是作为后端也要考虑到攻击的情况,首先明确的时候不是所有的商品都是放入缓存的,只是热的商品放入缓存,而且还要考虑到对一些商品做缓存重建,也就是说刚开始不热的商品,随着访问上来了也要放缓存,简单来说就是对于热的商品首先要取缓存查询下,如果缓存不存在,然后再去数据库取,数据库取到了然后放缓存,下次就从缓存读取了,但是这里要考虑的问题是:
1、如何保证通过攻击手段一直访问一个不存在的商品,这样会导致缓存穿透到数据库,而且数据库也是不存在的;
2、数据库和缓存的双写不一致问题。
3、保证数据的一致性问题的前提下如何保证高性能。
4、缓存创建问题。
基于这个案例,我们将这个案例一步一步的细化
原始的写法
我们来先看下最原始的写法,最原始的写法肯定是有一些问题的,但是这些问题还是具体问题具体分析,具体场景具体分析,也不是说不好,如果你站在学者的角度去看待肯定是有问题的,但是从不同的角度,它不一定有问题,比如这个系统每天就几十个人访问,而且很少写数据,那么也不会有什么问题,提供了两个方法,一个是更新商品,一个是获取商品,这个很常见,用户查看商品详情,后台小二更新商品,代码如下:
@Transactional
public Product update(Product product) {
Product productResult = null;
productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),
genProductCacheTimeout(), TimeUnit.SECONDS);
return productResult;
}
public Product get(long productId){
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = null;
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
product = JSON.parseObject(productStr, Product.class);
}else{
product = productDao.get(productId);
}
return product;
}
update:更新商品,更新商品以后,先在数据库更新完成以后,再更新到缓存中,这种做法很常见,也是非常平常的一种做法,可能大多数人也是这样写;
get:获取商品,用户在网站上或者app上浏览商品,这个并发量很大,但是从逻辑上分析很快就会明白,获取商品,不修改商品,先从缓存取,如果没有再从数据库获取,获取到了放到缓存,最后返回,这样是没有问题
我们这里从学者的角度去分析问题,不站在业务角度去分析这个问题,首先来看这两个方法肯定是有问题,首先就是缓存和数据库双写不一致的问题和攻击问题;
1、后台小二在更新商品的同时,用户获取到的商品是旧的商品;
2、黑客通过一个不存在的商品进行攻击,会打穿缓存,全部穿透到数据库;
3、商品热度退减和新的热的商品加入缓存,就是缓存重建问题。
进化版一
public Product get(long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = null;
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
//如果缓存数据是空的,那么进行缓存续期,防止相同的攻击穿透到数据库
if (productStr.equals(EMPTY_CACHE)) {
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
}
product = JSON.parseObject(productStr, Product.class);
//缓存读延期,当有人访问直接续期缓存
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
} else {
product = productDao.get(productId);
//如果数据库为空,证明这个商品是根本不存在的,从大的角度来说可以认为是被攻击了,往缓存放一个空的数据,下次从缓存中获取,防止穿透到数据库
if(product == null){
//设置空缓存解决缓存穿透问题
redisUtil.set(productCacheKey,EMPTY_CACHE,genEmptyCacheTimeout(),TimeUnit.SECONDS);
}else{
redisUtil.set(productCacheKey, JSON.toJSONString(product),
genProductCacheTimeout(), TimeUnit.SECONDS);
}
}
return product;
}
private Integer genProductCacheTimeout() {
//加随机超时机制解决缓存批量失效(击穿)问题
return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(5) * 60 * 60;
}
private Integer genEmptyCacheTimeout() {
return 60 + new Random().nextInt(30);
}
我们将获取商品进行改造了,代码如上,我们来思考下这样改造过后还有问题吗?问题是解决了不少,但是还是有问题,首先我们解决的是缓存重建问题:
1、在商品初始化到缓存以后,必须设置一个有效期,因为如果一个大的电商平台,商品是很多的,不可能把所有的商品都放入到缓存,只会放一些热的商品,但是我这里没有写太复杂,一般实际的开发中,那些热的商品会放入缓存是有另外的模块去做的,它会监听所有的商品,比如搞促销活动,会批量将一批商品放入缓存,所以这把就不考虑到如何找到热的商品放入缓存了,首先商品放入缓存的时候需要设置一个有效期,如果在有效期过后了,这个商品会被清除,下次访问上来了又可以放,但是注意的时候放入的商品有效期不要设置为一致,否则到时候会出现缓存穿透问题,要设置一个不一样的,比如加入一个随机数;
2、在获取商品详情过后,如果商品从缓存获取成功以后,进行续期,代表目前还是热的,可以续期;如果一些商品放入缓存以后一直没有被访问,有效期过后就自动清除了,这样也可以被称为热度退减自动清除;
3、如果黑客通过不存在的商品id一直访问到后端,这样每次都要跑两次io,缓存和数据库,所以要考虑到这种问题,所以这里的改造是如何穿透到数据库了,然后设置一个空的值,如果下次取出来的数据是空的,自动续期,保证不能穿透到数据库
上面的代码解决的是1 2 3描述的问题,但是还没有解决在分布式场景下缓存重建的问题,会有安全问题,所以这里加入分布式锁的概念
进化版二(分布式锁DCL)
public Product get(long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
//这个分布式锁解决的是缓存重建问题和dcl
RLock lock = redisson.getLock(productCacheKey);
lock.lock();
try {
if ((product = getProductFromCache(productCacheKey)) != null) {
return product;
}
product = productDao.get(productId);
//如果数据库为空,证明这个商品是根本不存在的,从大的角度来说可以认为是被攻击了,往缓存放一个空的数据,下次从缓存中获取,防止穿透到数据库
if (product == null) {
//设置空缓存解决缓存穿透问题
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(productCacheKey, JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
}
} finally {
lock.unlock();
}
return product;
}
private Product getProductFromCache(String productCacheKey) {
String productStr = redisUtil.get(productCacheKey);
Product product = null;
if (!StringUtils.isEmpty(productStr)) {
//如果缓存数据是空的,那么进行缓存续期,防止相同的攻击穿透到数据库
if (productStr.equals(EMPTY_CACHE)) {
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
}
product = JSON.parseObject(productStr, Product.class);
//缓存读延期,当有人访问直接续期缓存
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
}
return product;
}
private Integer genProductCacheTimeout() {
//加随机超时机制解决缓存批量失效(击穿)问题
return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(5) * 60 * 60;
}
private Integer genEmptyCacheTimeout() {
return 60 + new Random().nextInt(30);
}
getProductFromCache:该方法是处理的从缓存读取数据以及解决缓存重建问题;
上面的代码改造了并发用户访问同一个商品的时候,加了分布式锁过后,如果这个商品是在缓存中是有的,那么下面的所有代码都不执行,直接返回了,返回的时候也进行了缓存重建,进行了缓存续期,假如这个商品在缓存中不存在,那么都会进入分布式锁的获取,当然只有最先进入的能获取到锁,当获取到锁的线程再看下有没有,如果有,进行缓存重建然后返回,因为在分布式锁外面还阻塞了很多的线程,要是这些线程都获取到了锁,还是会进入下面的代码去数据库获取,那么这样是有数据安全问题的,因为第一个线程已经把商品放入缓存,这个逻辑就和单例类的DCL是一样的概念,所以后续的线程获取到锁过后都先判断下是否存在,如果不存在再去数据库获取,但是同时并发过来,一般只有一个线程能穿透到数据库,其他都会从缓存获取,这里说的是在同一时刻很多线程都阻塞到分布式锁上面,所以上面的代码这样写法是很有必要的,从根本上解决了攻击、缓存重建、数据安全等问题。
但是你觉得上面的这样写就没有问题了吗?遇到突然变热的商品,很多线程都会阻塞到分布式锁上,你想个问题,假如分布式锁上同时有1万个线程过来,只有第一个线程能进入,其他线程都阻塞到锁上,那么web服务器的线程是有限的,不可能接受这么多线程,先不说限流,那么如果这样去lock的话,从性能上是不是有点问题的,其实加了DCL过后,可能拿到锁的线程查询数据到放入缓存的时间很短,因为有dcl,所以就算获取到锁线程没有执行完成,那么这个时候缓存可能也有了,那么是不是可以改造下,评估下从数据库拿到数据到放入缓存的时间,比如大概是1s,那么是不是所有阻塞的线程只让它阻塞1s,就不阻塞了,直接去缓存中取,这种方案有点冒险,但是也是提升性能的一种方式,这样很多线程很快就结束了,对于资源的节约是很有必要的,当然了,这样冒险的做法要根据自己的实际业务情况去分析,我这里大概写下:
public Product get(long productId) throws InterruptedException {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
//这个分布式锁解决的是缓存重建问题和dcl
RLock lock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + productId);
//lock.lock();
lock.tryLock(1,TimeUnit.SECONDS);
try {
if ((product = getProductFromCache(productCacheKey)) != null) {
return product;
}
product = productDao.get(productId);
//如果数据库为空,证明这个商品是根本不存在的,从大的角度来说可以认为是被攻击了,往缓存放一个空的数据,下次从缓存中获取,防止穿透到数据库
if (product == null) {
//设置空缓存解决缓存穿透问题
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(productCacheKey, JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
}
} finally {
lock.unlock();
}
return product;
}
lock.tryLock(1,TimeUnit.SECONDS)在trylock完成以后就可以去缓存拿了,那么是不是就我默认第一个获取锁的线程在1s内是放入了缓存的,那么所有的线程都阻塞个1s获取不到就直接去缓存拿,这种方案是有风险的, 需要团队一起讨论是否可行,包括进行大量的压力测试。这只是一种提升程序性能的一种方式,凡事都是双面的,想要安全、高性能、串行就要牺牲一些额外的东西,比如风险,_。
进化版三(双写)
上面的是解决了缓存数据的安全问题,通过分布式锁来解决的,但是还有没有问题呢?从宏观上还是有问题的,比如数据库和缓存的双写问题
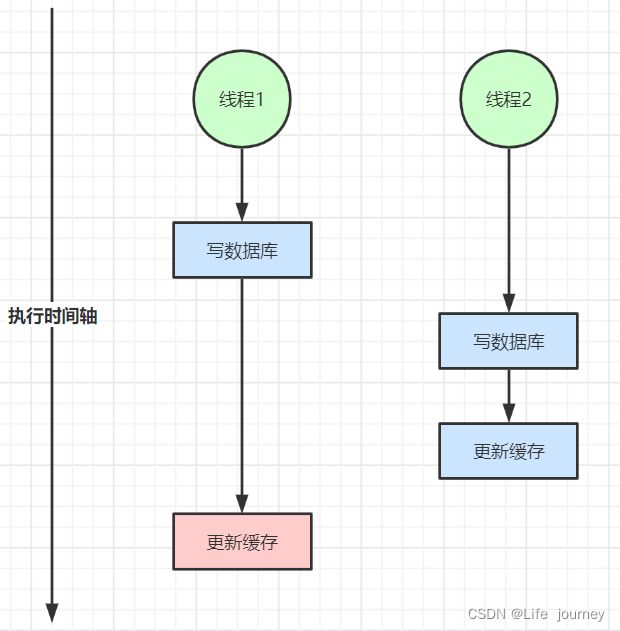
缓存与数据库双写不一致
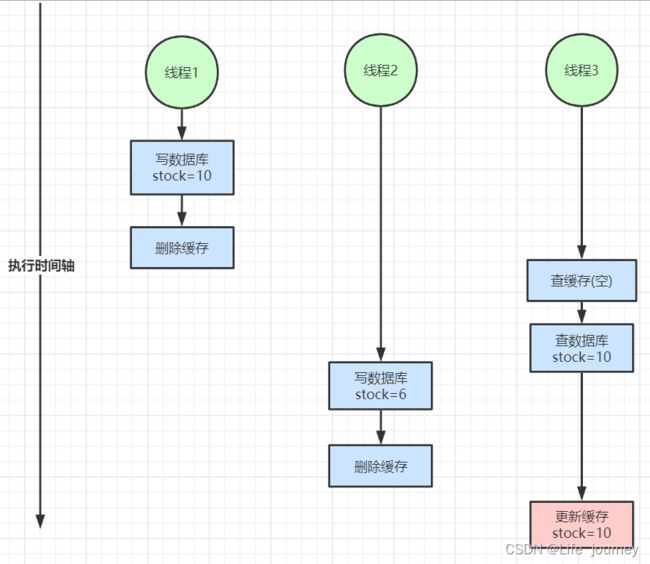
在大并发下,同时操作数据库与缓存会存在数据不一致性问题
1、双写不一致情况
2、读写并发不一致
解决方案:
1、对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
2、就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
3、如果不能容忍缓存数据不一致,可以通过加读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
4、也可以用阿里开源的canal通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。
总结:
以上我们针对的都是读多写少的情况加入缓存提高性能,如果写多读多的情况又不能容忍缓存数据不一致,那就没必要加缓存了,可以直接操作数据库。放入缓存的数据应该是对实时性、一致性要求不是很高的数据。切记不要为了用缓存,同时又要保证绝对的一致性做大量的过度设计和控制,增加系统复杂性!
针对上面的问题,我们这把通过Redisson的读写锁来解决,读写锁就是读读相对于无锁,当有写的时候全部加锁,代码实现如下:
@Transactional
public Product update(Product product) {
Product productResult = null;
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + product.getId());
RLock rLock = readWriteLock.writeLock();
//加写锁,当写数据时,所有的写线程和读线程都被阻塞
rLock.lock();
try {
productResult = productDao.update(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(), JSON.toJSONString(productResult),
genProductCacheTimeout(), TimeUnit.SECONDS);
} finally {
rLock.unlock();
}
return productResult;
}
public Product get(long productId) {
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
Product product = getProductFromCache(productCacheKey);
if (product != null) {
return product;
}
//这个分布式锁解决的是缓存重建问题和dcl,比如第一个线程
RLock lock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_CREATE_PREFIX + productId);
lock.lock();
try {
if ((product = getProductFromCache(productCacheKey)) != null) {
return product;
}
//读锁,解决缓存的双写不一致的问题
RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE_PREFIX + productId);
RLock rLock = readWriteLock.readLock();
try {
product = productDao.get(productId);
//如果数据库为空,证明这个商品是根本不存在的,从大的角度来说可以认为是被攻击了,往缓存放一个空的数据,下次从缓存中获取,防止穿透到数据库
if (product == null) {
//设置空缓存解决缓存穿透问题
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS);
} else {
redisUtil.set(productCacheKey, JSON.toJSONString(product), genProductCacheTimeout(), TimeUnit.SECONDS);
}
} finally {
rLock.unlock();
}
} finally {
lock.unlock();
}
return product;
}
上述的代码就解决了大部分的问题了,双写不一致的问题得到解决,数据安全问题得到解决,而且性能也较好,其实对于同一个商品,大部分的线程都是在代码开始的位置就结束了,因为缓存是有的,只有突然变热的商品会全流程走一遍。
终极进化版(多级缓存)
我们思考一个问题,上面的代码基本解决了我们所讨论的问题,但是大家有没有感觉的时候每次至少都要去redis去跑一次,所以我们思考下一个问题,就是对于一些特热的商品,热中热的是不是可以考虑放入到jvm的缓存里面呢?jvm的缓存肯定是最快的,查询过后先到jvm缓存查询一遍,没有再去redis查询,最后再到数据库,但是jvm内存是非常可贵的,只能放热中热的商品,这里还有一个问题就是怎么来判断热中热的商品呢?还有就是jvm缓存的数据如何同步?其实根据的我经验来看,商品的热度是有单独的团队或者模块去维护的,它会将一些热中热的商品同步到对应服务的jvm缓存里面,这样也可以做隔离和解耦等工作,在实际的工作中不可能在一个查询商品的业务逻辑中去做这些事情,要体现java编程的特性,职责要单一,不要在一个方法中做很多和业务逻辑无关的事情,像如何判断商品热不热,或者热中热是可以通过其他模块来完成,这些模块的职责需要完成的就是商品的热度控制,并将控制的热度商品同步到所有的微服务服务器,当查询商品的时候,通过热度缓存(jvm缓存)去查询,如果有就直接返回,这样的性能是极高的,没有任何的操作,就是一个本地内存的操作,代码如下:
private Product getProductFromCache(String productCacheKey) {
Product product = null;
//多级缓存查询,jvm级别缓存可以交给单独的热点缓存系统统一维护,有变动推送到各个web应用系统自行更新
//productMap就是一个map,但是实际的真实业务,不可能通过一个map来做,比如可以用memcached google 的guava缓存
//有自己的清除策略,防止占用太多jvm内存
product = productMap.get(productCacheKey);
if (product != null) {
return product;
}
String productStr = redisUtil.get(productCacheKey);
if (!StringUtils.isEmpty(productStr)) {
//如果缓存数据是空的,那么进行缓存续期,防止相同的攻击穿透到数据库
if (productStr.equals(EMPTY_CACHE)) {
redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS);
return new Product();
}
product = JSON.parseObject(productStr, Product.class);
//缓存读延期,当有人访问直接续期缓存
redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS);
}
return product;
}
布隆过滤器
其实上面的因对空商品的攻击,还可以使用布隆过滤器来实现,布隆过滤器在一定程度上是可以解决大部分的攻击的问题,就是系统初始化将所有的商品id通过redis的bit 位操作放入redis,耗的内存非常少的,因为根据id计算出来的占bit位,0表示不存在,1表示存在;
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
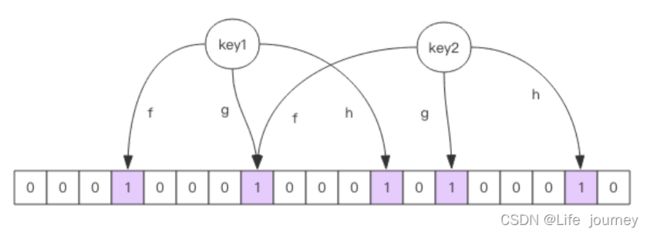
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
可以用redisson实现布隆过滤器
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,布隆过滤器缓存过滤伪代码:
//初始化布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
//把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
String get(String key) {
// 从布隆过滤器这一级缓存判断下key是否存在
Boolean exist = bloomFilter.contains(key);
if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据。
在实际的业务场景中,布隆顾虑器可以在拦截器来做或者做一个aop,拦截缓存的获取,写一个aop来做都是可以的,只是数布隆过滤器可以在一定程度上解决大量不存在的商品问题。
有道云笔记地址如下:
https://note.youdao.com/s/IVIoqrva