Git项目管理工具
版本控制
在公司中,一般以团队的形式进行项目的开发。在一个团队中,每一个团队成员都需要一份相同的代码,而大家又都基于这份代码去开发着不同的功能,过程中就会产生相当多的问题,针对这些问题,我们可以采用版本控制的方式来解决,也因此诞生了很多的版本控制工具,如市面上比较常见的 cvs/svn/git 等等
团队开发中的问题
- 小明负责的模块就要完成了,就在即将发布上线之前的一瞬间,电脑突然蓝屏,硬盘光荣牺牲!几个月来的努力付之东流——需求之一:备份到服务器!
- 这个项目中需要一个很复杂的功能,老王摸索了一个星期终于有眉目了,可是这被改得面目全非的代码已经回不到从前了。什么地方能买到哆啦A梦的时光机啊?需求之二:代码还原!
- 小刚和小强先后从文件服务器上下载了同一个文件:
Analysis.java。小刚在Analysis.java文件中的第30行声明了一个方法,叫count(),先保存到了文件服务器上;小强在Analysis.java文件中的第50行声明了一个方法,叫sum(),也随后保存到了文件服务器上,把小刚的代码覆盖了,于是,count()方法就只存在于小刚的记忆中了——需求之三:协同修改! - 老许是一位项目经理,他需要把每一个版本的项目都保存一份, 而且这些工程里其实有很多文件都是重复的,导致电脑空间经常不足 , 要找某个版本的时候也很麻烦——需求之四:多版本项目文件的管理!
- 老王是另一位项目经理,每次因为项目进度挨骂之后,他都不知道该扣哪个程序员的工资!就拿这次来说吧,有个该死的
Bug调试了30多个小时才知道是因为相关属性没有在应用初始化时赋值!可是小强、小明、小刚和小军都不承认是自己干的!——需求之五:追溯问题代码的编写人和编写时间! - 小温这两天幸福的如同掉进了蜜罐里,因为他成功的得到了前台MM丽丽的芳心,可他郁闷的是这几天总是收到
QA小组的邮件,要求他修正程序中存在的Bug,可他自己本地电脑上是没有这些Bug的,“难道我的代码被哪个孙子给改了?”。是的,小温没来上班的时候,丽丽是QA小组小郑的女朋友啊!——需求之六:权限控制,不能让人随便改服务器分支中的代码!
版本控制深入程序员在团队配合中,如果你的项目没有版本控制:
一、 代码管理混乱。
二、 解决代码冲突困难。
三、 在代码整合期间引发BUG。
四、 无法对代码的拥有者进行权限控制。
五、 项目不同版本发布困难。
…
Git
很多人都知道,Linus在1991年创建了开源的Linux,从此,Linux系统不断发展,已经成为最大的服务器系统软件了。
Linus虽然创建了Linux,但Linux的壮大是靠全世界热心的志愿者参与的,这么多人在世界各地为Linux编写代码,那Linux的代码是如何管理的呢?
事实是,在2002年以前,世界各地的志愿者把源代码文件通过 diff 的方式发给Linus,然后由Linus本人通过手工方式合并代码!
你也许会想,为什么Linus不把Linux代码放到版本控制系统里呢?不是有CVS、SVN这些免费的版本控制系统吗?因为Linus坚定地反对CVS和SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比CVS、SVN好用,但那是付费的,和Linux的开源精神不符。
不过,到了2002年,Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统。
安定团结的大好局面在2005年就被打破了,原因是Linux社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发Samba的Andrew试图破解BitKeeper的协议(这么干的其实也不只他一个),被BitMover公司发现了(监控工作做得不错!),于是BitMover公司怒了,要收回Linux社区的免费使用权。
Linus可以向BitMover公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是这样的:
Linus花了两周时间自己用C语言写了一个分布式版本控制系统,这就是Git!一个月之内,Linux系统的源码已经全部交由Git管理了!牛是怎么定义的呢?大家可以体会一下。
Git迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub网站上线了,它为开源项目免费提供Git存储,无数开源项目开始迁移至GitHub,包括jQuery,PHP,Ruby等等。
历史就是这么偶然,如果不是当年BitMover公司威胁Linux社区,可能现在我们就没有免费而超级好用的Git了。
集中式vs分布式
Linus一直痛恨的 CVS 及 SVN 都是集中式的版本控制系统,而 Git 是分布式版本控制系统,集中式和分布式版本控制系统有什么区别呢?
集中式版本控制系统
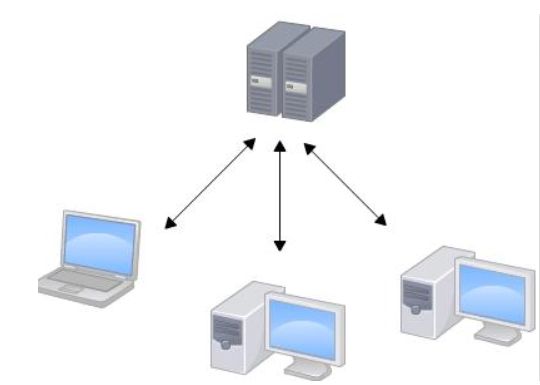
先说集中式版本控制系统,版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。
缺点:
集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这还不得把人给憋死啊。
分布式版本控制系统

那分布式版本控制系统与集中式版本控制系统有何不同呢?首先,分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
Git 的优势
当然,Git的优势不单是不必联网这么简单,后面我们还会看到Git极其强大的分支管理,把SVN等远远抛在了后面。
CVS作为最早的开源而且免费的集中式版本控制系统,直到现在还有不少人在用。由于CVS自身设计的问题,会造成提交文件不完整,版本库莫名其妙损坏的情况。同样是开源而且免费的SVN修正了CVS的一些稳定性问题,是目前用得最多的集中式版本库控制系统。
除了免费的外,还有收费的集中式版本控制系统,比如IBM的ClearCase(以前是Rational公司的,被IBM收购了),特点是安装比Windows还大,运行比蜗牛还慢,能用ClearCase的一般是世界500强,他们有个共同的特点是财大气粗。
微软自己也有一个集中式版本控制系统叫VSS,集成在Visual Studio中。由于其反人类的设计,连微软自己都不好意思用了。
分布式版本控制系统除了Git以及促使Git诞生的BitKeeper外,还有类似Git的Mercurial和Bazaar等。这些分布式版本控制系统各有特点,但最快、最简单也最流行的依然是Git!
安装 Git
最早Git是在Linux上开发的,很长一段时间内,Git也只能在Linux和Unix系统上跑。不过,慢慢地有人把它移植到了Windows上。现在,Git可以在Linux、Unix、Mac和Windows这几大平台上正常运行了。
要使用Git,第一步当然是安装Git了。
从 https://git-for-windows.github.io下载(网速慢的请移步国内镜像),安装64位程序,然后按默认选项安装完成即可。
安装完成后,鼠标在桌面右键,或者在开始菜单里找到“Git”->“Git Bash”,蹦出一个类似命令行窗口的东西,就说明Git安装成功!

还有文件图标显示程序,要不要安装看自身需要了
初始化设置
因为Git是分布式版本控制系统,所以,每个机器都必须自报家门:你的名字和Email地址。你也许会担心,如果有人故意冒充别人怎么办?这个不必担心,首先我们相信大家都是善良无知的群众,其次,真的有冒充的也是有办法可查的。
注意git config命令的--global参数,用了这个参数,表示你这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址。
将一个目录变成一个本地仓库,一般一个项目一个仓库,在新建的目录右键–>选择Git Bash Here打开git命令窗口
git config --global user.name "Your Name" // 用户名
git config --global user.email "[email protected]" // 设置git仓库的邮箱
git init // 初始化,会将该目录变成git管理的一个仓库
运行成功后:
可以发现当前目录下多了一个.git的目录(隐藏文件夹,需要打开文件设置显示隐藏文件夹才能看到),这个目录是Git来跟踪管理版本库的,没事千万不要手动修改这个目录里面的文件,不然改乱了,就把Git仓库给破坏了。
怎么添加文件到仓库
在目录里新建一个文件
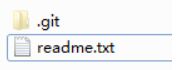
新添加的文件需要先存到暂存区才能提交,可以理解为暂存区的文件是我接下来要一次性保存的文件
git add readme.txt // 将aa.txt文件添加到
git add aa.txt bb.txt // 将多个文件添加到暂存区
git add . // 将该目录中所有文件添加到暂存区。
执行上面的命令,没有任何显示,这就对了,Unix的哲学是**“没有消息就是好消息”**,说明添加成功。
第二步:用命令git commit告诉Git,把暂存区所有文件提交到本地仓库:
git commit -m "提交信息,后续可以查看这次提交的说明" // 将暂存区内容添加到本地仓库中。
提交成功后会告诉你一些信息

工作区和暂存区和本地仓库


查看工作区与暂存区文件未提交到仓库的文件
git status
查看提交日志
实际工作中,我们脑子里怎么可能记得一个几千行的文件每次都改了什么内容,不然要版本控制系统干什么。版本控制系统肯定有某个命令可以告诉我们历史提交信息,在Git中,我们用git log命令查看:
git log

commit id:版本号,用来回退版本的
Author:提交的用户
Date:提交的时间
最上面的 HAED 表示当前所在的版本
git log 命令显示从最近到最远的提交日志,如果嫌输出信息太多,看得眼花缭乱的,可以试试加上--pretty=oneline参数:将所有历史提交信息一起打印出来
git log --pretty=oneline

为什么 commit id 要使用这么长一串字符而不是数字?
当两个人同时在一个代码上工作时候,分别往各自的本地的版本库提交时,相同的提交号对应着不同的修改,如果使用1,2,3这样的数字不能保证唯一性,所以Git使用SHA-1算法产生唯一标识符,保证全球唯一。
比如程序员甲和乙负责共同开发一个聊天软件,使用Git来版本控制。 Git是分布式版本控制,每个人都有一个版本库。如果Git版本控制用1,2,3这样的数字来生成版本号,那么程序员甲和乙代码合并的时候就会出现问题。版本1到底是谁的?
SVN 是集中式的版本控制,只有一个版本库,所以版本号可以从1,2,3开始。Git是分布式版本控制,每个人都有一个版本库,所以不能从1,2,3开始。
版本回退
我们不断修改文件,不断的往版本库中提交文件。就好比玩RPG游戏时,每通过一关就会自动把游戏状态存盘,如果某一关没过去,你还可以选择读取前一关的状态。有些时候,在打Boss之前,你会手动存盘,以便万一打Boss失败了,可以从最近的地方重新开始。Git也是一样,每当你觉得文件修改到一定程度的时候,就可以**“保存一个快照”**,这个快照在Git中被称为 commit。一旦你把文件改乱了,或者误删了文件,还可以从最近的一个commit 恢复,然后继续工作,而不是把几个月的工作成果全部丢失。
如果想回到上一个版本,应该怎么做呢?
首先,Git必须知道当前版本是哪个版本,在Git中,用HEAD表示当前版本,上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100,一般这种方式也不会用。
现在,我们要把当前版本回退到上一个版本,就可以使用git reset命令:
git reset --hard HEAD^
回到指定版本
先查看提交日志,查看想要回退版本的commit id,然后执行下面代码
git reset --hard commit id
回到之前版本后,又想回到刚刚的版本
在我们回到之前版本后,再查看提交日志是不会有这个版本记录的,使用下面命令查看所有版本信息
git reflog

从上面可以看出,我们当前回退的版本,左边的id和下面最后一行是一样的,这个时候我们再使用命令回到 e153e9f 就回到回退前的版本了
git reset --hard e153e9f
撤销修改
git checkout -- 文件名加拓展名可以丢弃工作区的修改:– 后面是一个空格
如: 命令 git checkout -- readme.txt 意思就是,把 readme.txt 文件在工作区的修改全部撤销,这里有两种情况:
一:readme.txt 暂存区有这个文件,撤销修改就是将暂存区的这个文件拷贝到工作区;
二:readme.txt 暂存区没有这个文件,撤销修改就是将版本库的这个文件拷贝到工作区。
总之,就是让这个文件回到最近一次 git commit 或 git add 时的状态。
注意:
git checkout -- file 命令中的 -- 很重要,没有 -- ,就变成了**“切换到另一个分支”**的命令,我们在后面的分支管理中会再次遇到 git checkout 命令
删除文件
一般情况下,你通常直接在文件管理器中把没用的文件删了,或者用rm命令删了:
git rm test.txt
查看暂存区的其他内容有没有问题
git status
没有问题就可以提交到仓库删除了
git commit -m "删除了xxx"
分支管理
Git 拥有强大的分支管理系统,且推荐在项目开发过程中大量的使用分支来解决各种项目中的问题
分支相关命令
查看分支:git branch
创建分支:git branch 分支名
切换分支:git checkout 分支名
创建 + 切换分支:git checkout -b 分支名
将某分支合并到当前所在分支:git merge 分支名
删除分支:git branch -d 分支名
分支合并文件修改冲突
两个分支同时修改同一个文件,并进行合并就会产生冲突,当前分支的文件内容会按下面图片形式进行内容合并,这个时候你可以选择手动修改合并其中的内容,并再次添加到暂存区,然后再提交,使用IDEA开发工具就界面内容更清晰些

远程仓库
Git是分布式版本控制系统,同一个Git仓库,可以复制到不同的机器上。怎么复制呢?最早,肯定只有一台机器有一个原始版本库,此后,别的机器可以复制这个原始版本库,而且每台机器的版本库其实都是一样的,并没有主次之分。
远程仓库其实就是找一台电脑充当服务器的角色,每天24小时开机,其他每个人都从这个“服务器”仓库克隆一份到自己的电脑上,并且各自把各自的提交推送到服务器仓库里,也从服务器仓库中拉取别人的提交。
可以自己搭建一台运行Git的服务器,不过现阶段,为了学Git先搭个服务器绝对是小题大作。好在这个世界上有个叫 GitHub 的神奇的网站,从名字就可以看出,这个网站就是提供Git仓库托管服务的,所以,只要注册一个GitHub 账号,就可以免费获得Git远程仓库。
一般我们有可能接触到比较多的几种 Git 远程仓库平台:
GitHub:国外/免费创建公有仓库,私有仓库需要收费,在国际上来说 GitHub 是最活跃的开源社区
GitLab:国外/免费创建公有仓库,私有仓库需要收费,不过 GitLab 提供了开源版本的企业版本,企业可以部署一套 GitLab 的私服在自己的服务器中
Gitee:国内/免费创建公有|私有仓库/私有仓库限制成员不得超过5人
Gitee(码云)的使用
GitHub 虽然好,在国外的使用率也很高,但毕竟是国外的。在网速上效率还是比较低,经常会出现访问页面变得很慢,下载项目很慢的情况,于是国内慢慢发展起了一个类似 GitHub 的 Git 开源平台 Gitee。,他是国内公司 CSDN 的产品,从访问效率上来讲要高很多,另一个是他的中文界面相对于 GitHub 来说对英文不好的也相对友好一些。但当你会用 Gitee 之后再想去用 GitHub,也基本上不会有太大区别。
要使用 Gitee,首先还是需要创建一个账户,下图是创建完成后登录进个人主页的页面
创建仓库
点击右上角头像左边的 + 号,再点击新建仓库即可创建一个仓库

填写好仓库名称,路径,选择一个分支模型(自动给你创建哪些分支),就可以了点击创建了,目前是私有仓库,等创建完之后可以修改
项目初始化(新项目上传)
一般这个事情都是领导做:
有的时候,可能我们有一个项目在本地已经创建好了,但是远程还没有仓库,此时我们即需要将本地仓库初始化为 git 仓库,并将其提交到远程仓库中去
首先进入到你需要进行初始化的项目根目录,右键进入git命令窗口,并按照如下步骤进行操作:
步骤1:设置名字与邮箱
git config --global user.name "码云上的名称"
git config --global user.email "码云上面注册邮箱"
步骤2:初始化本地仓库
git init
步骤3: 设置提交忽略文件
这一步的意义是为了避免项目中有些本地环境特有的文件,或密码等文件信息被传入到远程仓库,这些文件每个人的电脑都有可能不一致,如果提交到远程仓库,可能会导致出现泄密或者频繁冲突的问题
在项目根目录下创建一个名为.gitignore的文件把下面代码复制进去,这样在提交时就会忽略这些文件
# Created by .ignore support plugin (hsz.mobi)
# Operating System Files
*.DS_Store
Thumbs.db
*.sw?
.#*
*#
*~
*.sublime-*
# Build Artifacts
.gradle/
build/
target/
bin/
dependency-reduced-pom.xml
# Eclipse Project Files
.classpath
.project
.settings/
# IntelliJ IDEA Files
*.iml
*.ipr
*.iws
*.idea
步骤4:在本地提交代码, 初始化项目
git add .
git commit -m “项目初始化”
步骤5:配置远程仓库路径

git remote add origin https://xxx/xxx.git
步骤6:将本地仓库master分支代码推送到远程仓库
git push -u origin master
执行之后会弹出一个框让你输入gitee的账号密码,输入好之后点击确定就可以了,有些电脑系统可能在输入账号或密码错误后再次推送不再弹出框,根据下面控制面板修改相应凭证就可以了

完成以上步骤,就基本完成将本地仓库的项目初始化到远程仓库了,可以访问远程仓库查看
添加团队成员
创建好项目以后,就可以添加团队成员了,公司的项目通常都是私有仓库,大部分公司会利用类似 Gitlab 的开源平台搭建公司专属的 Git 远程仓库,其配置也基本都差不多,即进入项目管理/设置页面,找到成员管理并邀请成员,为其设置权限等等操作即可

在 Idea 中克隆远程仓库
通常来说,进入公司以后会发给你一个远程 Git 仓库的账号密码,以及仓库地址,当你得到仓库地址后,即可在开发工具当中将该仓库下载到本地
idea中自带一个git,如果idea版本太旧了就在设置中更改指定我们刚刚安装的git,点击ok

打开 Idea,在初始化界面克隆远程仓库

填写要克隆的地址,以及在本地存放的位置后点击克隆

弹出git远程仓库账号登录,勾选记住我,登录
以上操作就成功从远程仓库克隆到本地了
PS:需要注意的是,在微服务开发或者按模块开发的情况下,因为一个仓库下可能包含多个项目文件,因此建议使用命令 git clone 先将远程仓库克隆到本地,然后再将仓库中的项目一个个导入到 idea
在idea中文件新增编辑和删除,怎么提交保存
在我们开发过程当中,经常会涉及到进行新增/编辑或删除文件的操作。在 idea 中,使用不同的颜色来标识文件的不同状态。
通常情况下,有这样几种颜色:
**橙色:**色代表未被 Git 管理(未添加到暂存区)
**绿色:**代表新增的文件且已经被加入到暂存区了
**蓝色:**代表该文件被编辑过
**黑色:**代表该文件在当前版本与远程仓库是一致的
**灰色:**表示该文件之前被提交到仓库过(不管是远程还是本地),但是他已经被删除了
**红色:**表示该文件的内容出现了冲突
首次创建新文件时,idea 会弹出一个提示框,确认是否要添加到 git 暂存区,我们勾选记住我的选择,再点击取消
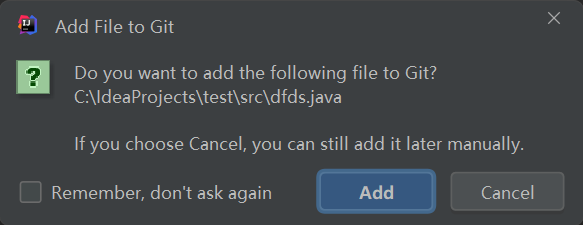
那我们怎么添加到暂存区呢,右击一个目录或一个模块,找到git,点击add会将这个目录或模块下的所有新增或修改的文件放入暂存区

提交到本地仓库
可以像上面一样右击,点击commit Directory,或者点击右上角绿色勾的图标

点击提交后会弹出框,可以填写本次提交的信息,点击修改的文件,还会像下面这个展示本次修改了哪些代码

推送到远程仓库
在主分支中,右击项目模块目录,找到git ==>repository ==> push,这样就把代码保存到远程仓库了

在idea中分支切换与合并
在 idea 中,分支的相关操作都在 idea 项目界面的右下角最角落的位置,你可以通过这边去新建本地分支/切换本地或远程分支,创建/删除/合并分支等等操作

新建分支
有时候网络不好啊,我们可以将刚拉下的分支,再新建一个分支,在这个分支上去写代码,这样如果不小心删掉了某些文件,还可以从本地主分支找回来,

分支切换,删除分支
点击要切换的分支,点击checkout,就切换到这个分支了,点击delete则删除分支

重新拉取远程仓库分支代码,合并分支
如果我们每天要获取远程仓库中的其他同事代码的功能,则需要去重新拉取代码,我们先切换到本地主分支,右击项目模块目录,找到git ==>repository ==> pull,或者点击右上角这个图标就把远程仓库代码拉取到当前分支了

如果我们自己有单独备份一个分支,则先切换到自己的分支,再点击主分支合并到我们的备份分支
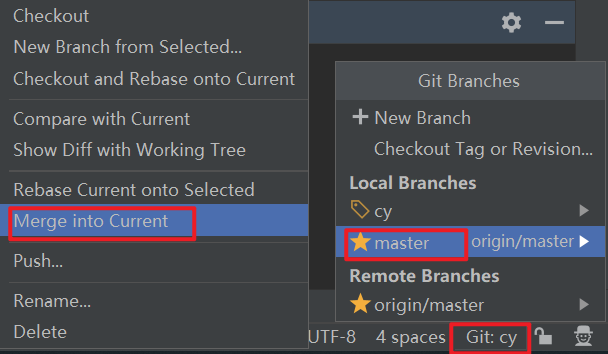
我们在备份分支修改完文件后需要合并到主分支,使用主分支推送到远程仓库,使用备份分支直接推送,则会在远程仓库创建一个对应的分支保存(如果公司允许开放路径,还可以在家拉取这个分支,偷偷卷,哈哈)
推送到远程仓库时代码冲突
在开发当中,不可避免的会遇到代码冲突的问题,比如张三和李四同时修改 User.java 文件,李四先修改 User.java 并且已经提交,张三不知道李四修改了 User.java 文件,此时没有更新远程的代码,然后直接对 User.java 进行修改并提交,这时候就会出现冲突的问题了
提示推送被拒绝,需要合并冲突内容,我们点击merge

针对冲突文件出现三个选项,
- 用我本地的代码
- 用远程仓库的代码
- 合并代码
我们点击合并代码
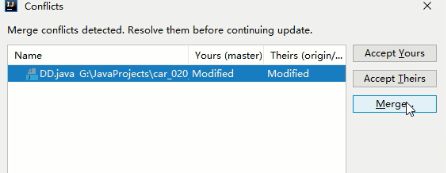
出现下面界面,左边是本地代码,右边是远程仓库的代码,中间是想合并成什么样,可以点击两边箭头快速修改,也可以手动编辑,合并后点击应用,再次提交本地,再次推送到远程仓库

idea中查看操作信息,运行命令
可以查看分支的操作信息

可能idea插件功能出问题,可以在这里执行git命令

本地硬备份
建议开发时,自己建一个文件夹cv保存每个项目版本,这样随便怎么玩都不会出事了