《跨模态检索Summary3.19》
Summary
- 问题重述
- 论文篇
问题重述
看了一周的跨模态论文,还是只能略知一二,但不积跬步无以至千里,下面概括一下所看所想。
跨模态数据呈现底层特征异构(text and image)、高层语义(class)相关的特点,既要表示底层特征,又要对高层语义建模以及关联模态之间的联系。
跨模态检索在方法上主要分为两大类:一类是实值表示学习,一类是二值表示学习(跨模态哈希方法),实值表示学习直接对从不同模态提取特征进行学习,而二值表示学习是把特征先映射到汉明二值空间(在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数),在空间中进行学习。
另外主流方法也可分为四类:子空间方法、深度学习方法、哈希变换的方法和主题模型的方法。
1.子空间方法:下面我看的四篇论文基本都是用的子空间方法,
基本思想:利用不同模态的成对样本,共生信息学习投影矩阵,将不同模态的特征投影到一个共同潜在子空间,然后在该子空间度量不同模态的相似性,从而实现跨模态搜索。
所看论文的做法:在有类标信息的条件下,使得同类样本在潜在子空间投影尽量接近而非同类样本的投影尽量远离。
提出多视角判别分析,该方法直接在投影空间计算类内、类间散度矩阵。提出用低秩和稀疏约束学习相关判别式特征,提高潜在子空间的判别性。
高层语义综合考虑文本、图像和语义3个模态,最大化两两之间的相关性学习到公共的潜在子空间。
优点:主要目的是学习到判别性的共享子空间,主要途径是最大化相关性。但未能考虑模态内的数据局部结构和模态间的结构匹配。一个模态的领域对应于另一模态内的样本也应该具有相邻关系。子空间方法学习到的都是线性映射,无法有效的建模不同模态的高阶相关性。
2.深度学习
利用深度学习的特征抽取能力,在底层提取不同模态的有效表示,在高层建立不同模态的语义关联
下面论文还未学习到就不做深入思考
3.基于哈希变换的跨模态方法:哈希映射学习的基本依据是相似样本 的哈希编码是相似的
4.主题模型方法:基于主题模型的方法通过生成式模型来发掘跨模态数据中隐含主题空间,学习得到的“主题 ”具有较强的可解释性 。
个人思考:跨模态要更好的关联两种模态的相关性,找到共同空间以度量相关性,最小化模态内,最大化模态间,使其有判别性。
论文篇
1《Deep Adversarial Metric Learning for Cross-Modal Retrieval》
本文是2019年的一篇SCI,后面的几篇论文也是在此基础上继续优化改进的,现有跨模式检索方法的核心是通过找到最大相关的嵌入空间来缩小不同模式之间的差距。本文提出了一个新的深度对抗网络度量学习方法(DAML)
将子空间学习过程分解为三个损失项:
1)利用对抗性损失:来最小化来自两个不同模态的表示的两个未知分布之间的“模态差距”,以促进模态不变;
2)特征判别损失,它通过类别信息对模态内相似性进行建模,并确保学习的表示具有判别性;
3)特征相关损失,其使类内交叉模态样本之间的距离最小化并且使类间交叉模态样本之间的距离最大化;
Model architecture

————————————————
参考链接:https://blog.csdn.net/uestc_huhu/article/details/114984584
2《Ternary Adversarial Networks With Self-Supervision for Zero-Shot Cross-Modal Retrieval》
本文是一片2019,SCI一区的文章,受到zero-shot learning的启发,提出了一种新模型,Ternary Adversarial Networks With Self-Supervision(三元自监督的对抗网络跨模态搜索TANSS)
Model architecture
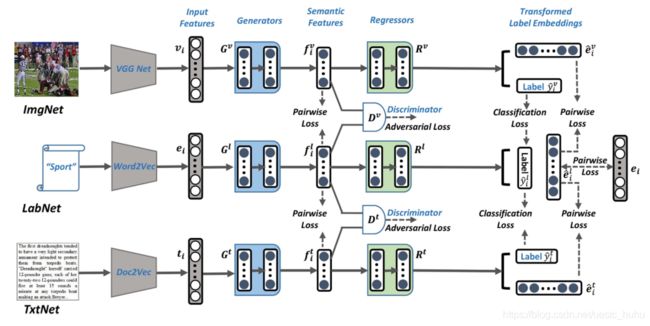
1.两个语义特征学习子网络,获取不同模态的内部数据结构,在公共语义空间保留模态关系。
2.一个自监督的语义子网络,运用可见和不可见的类别标签作为guide指导知识从可见到不可见迁移。
3.利用多抗学习的方案来最大化不同模态之间语义特征的相关性和一致性。
可实现
三个子网已集成到的TANSS中,以制定可实现高效迭代参数优化的端到端网络体系结构。
TANSS的结构优势
1.三只对抗网络能够提取在公共子空间的类别语义,和概括可见标签和不可见标签。
2.TANSS能够准确利用标签的词向量使得从看的见的向看不见的进行知识迁移。
3.TANSS中的两个判别器能够更好地消除模态差距。
————————————————
参考链接:https://blog.csdn.net/uestc_huhu/article/details/114890004
3《Learning Cross-Aligned Latent Embeddings for Zero-Shot Cross-Modal Retrieval》
这是一篇2020年的CCF A佳作,提出的新方法:Learn- ing Cross-Aligned Latent Embeddings (LCALE),特定于模态的变分自动编码器寻求输入多模态特征和类嵌入的共享低维潜在空间。
Model architecture
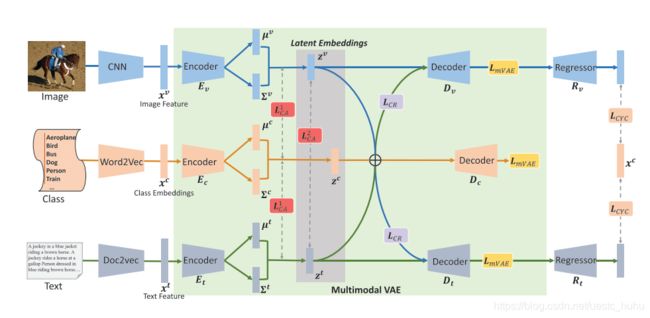
方法:
1.提出一种替代基于GAN的ZS-CMR方法,而是通过自编码器在低维的潜在空间中生成潜在嵌入。
2.对于不同的模态数据和类别嵌入,提出了交叉重建和交叉对齐的方法,有效的实现了低维空间中,将知识传递到空间中的不可见类。
最后目标函数如下
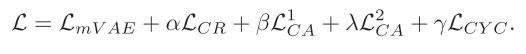
损失值分别为 mVAE模态类重构,跨模态重构,跨模态对齐,循环一致约束类嵌入。
————————————————
参考链接:https://blog.csdn.net/uestc_huhu/article/details/114849290
4《Correlated Features Synthesis and Alignment for Zero-shot Cross-modal Retrieval》
本文是一篇2020的CCF A的佳作,提出了一种相关特征整合对齐的方法,(Correlated Feature Synthesis and Alignment (CFSA),把综合特征送入公共语义空间进行学习,提取不同跨模态相关的特征,并且在循环一致的约束下,迁移到哪些看不到的类中去。
Model Architecture
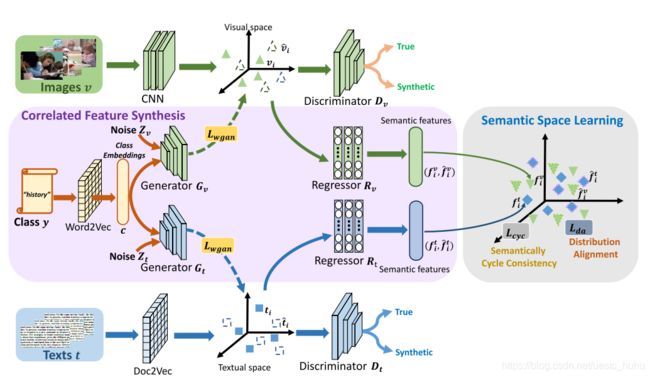
将可见于不可见的类的类嵌入用作语义特征
(1)两个回归器将不同模态数据的true和synthetic特征映射到公共语义空间
(2)分布对齐减少了不同模态数据之间的差异性
(3)循环一致约束减少了语料特征和最初特征之间的差异性
本文使用了迁移学习,用可以看见的类别和看不见的类别共同训练,其中利用了gan来修正结果,几个loss来保证信息不丢失,判别器完成true与syn的判定。
————————————————
参考链接:https://blog.csdn.net/uestc_huhu/article/details/114807161
总结
感觉自己还只是了解了一个大概,对于真正的开窍还需要很长一段路去走。