C++ std::unordered_map
- 总结:
unordered_map底层基于哈希表实现,内部是无序的。unordered_map是STL中的一种关联容器。容器中元素类型为std::pair,pair.first对应键-key,pair.second对应值-value。- I. 容器中
key具有唯一性,插入和查询速度接近于O(1)(在没有冲突的情况下)。- II. 通过
key来检索value,因为会有rehash操作,而不是通过绝对地址(和顺序容器不同)- III. 使用内存管理模型来动态管理所需要的内存空间
- 1. unordered_map 底层原理
- 2. 功能函数
-
- 2.1 构造函数
- 2.2 常用函数
- 3. bucket_* 与 load_factor
-
- 3.1 bucket_* 函数
- 3.2 load_factor 函数
- 4. reserve、rehash
-
- 4.1 reserve函数
- 4.2 rehash函数
- 5. 与 map 的区别
1. unordered_map 底层原理
unordered_map内部采用hashtable的数据结构存储,容器中每个key会通过特定的哈希运算(哈希函数)映射到一个特定的位置。
一般来说,hashtable是可能存在冲突的,即不同的key值经过哈希函数计算后得到相同的结果(多个key通过计算映射到同一个位置)。
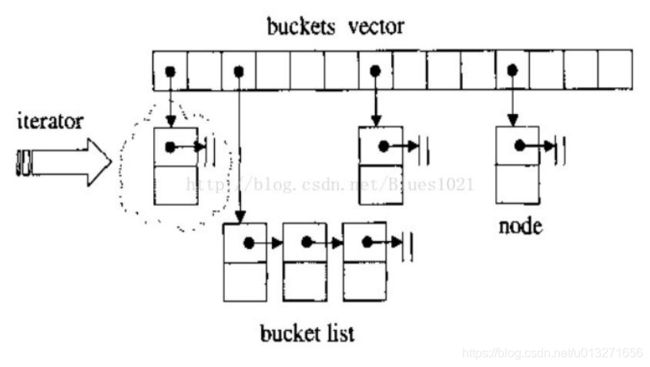
上述问题解决方法为: 在每个位置放一个桶(bucket),用于存放映射到此位置的元素, 在同一个位置的元素会按顺序链在后面。下图为哈希表结构。
unordered_map内部是一个hash_table(一般是一个vector结构)。bucket_vector中每个元素对应一个桶,据了解-当桶内数据量在8以内使用链表来实现桶,当数据量大于8 则自动转换为红黑树结构 也就是有序map的实现结构。
hash_table中查询(插入、删除) 过程是:
1、得到 key、 hash 函数得到 hash 值;
3、找到桶号(一般都为 hash 值对桶数求模);
4、在桶内使用链表或红黑树进行查询;
- 常见哈希函数:
- I. 直接定址法
取关键字的某个线性函数为散列地址:
hash(key) = A*Key +B或hash(key) = A*Key
其中a和b为常数。- II. 除留余数法:
取关键字被某个不大于散列表长度m的数p求余,得到的作为散列地址。
hash(key) = key % p, p < m- 此外还有数字分析法 、平方取中法、折叠法等。
- 哈希冲突的解决:常用的主要有两种方法解决冲突:
- I. 链接法
将所有哈希地址相同的结点链接在同一个单链表中。- II. 开放定址法:
当冲突发生时,使用某种探查(亦称探测)技术在hash_table中寻找下一个空的地址,只要hash_table足够大,总能找到空的地址。根据不同方法,可将开放定址法区分为线性探查法、二次探查法、双重散列法等。
2. 功能函数
使用std::unordered_map需包含头文件#include 。
2.1 构造函数
std::unordered_map的构造函数原型如下所示(C++11):
// 1. empty (1)
explicit unordered_map( size_type n = /* see below */,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type() );
explicit unordered_map( const allocator_type& alloc );
// 2. range
template <class InputIterator>
unordered_map( InputIterator first, InputIterator last,
size_type n = /* see below */,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type() );
// 3. copy
unordered_map( const unordered_map& ump );
unordered_map( const unordered_map& ump, const allocator_type& alloc );
// 4. move
unordered_map( unordered_map&& ump );
unordered_map( unordered_map&& ump, const allocator_type& alloc );
// 5. initializer list
unordered_map( initializer_list<value_type> il,
size_type n = /* see below */,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type() );
例子:构造函数序号与上述相同
#include
2.2 常用函数
std::unordered_map全部成员函数如下所示:
at 返回索引处元素的引用
begin 返回指向容器头的迭代器
cbegin 返回指向容器头的迭代器-const
bucket 返回key所对应的桶(bucket)的编号
bucket_count 返回容器中桶(bucket)的个数
bucket_size 返回对应桶(bucket)中的元素个数
cend 返回指向容器尾元素后一个位置的迭代器 - const
clear 清空容器
count 返回key对应元素的个数,因为unordered_map不允许有重复key,所以返回0或1
emplace move
emplace_hint 过迭代器位置进行emplace, 因此可以从参数位置开始搜索,速度更快
empty 判断容器是否为空
end 返回指向容器尾的迭代器
equal_range
erase 删除元素
find 查找
get_allocator
hash_function
insert 插入元素
key_eq
load_factor 返回容器当前负载系数
max_bucket_count 返回容器所能包含的桶的最大数量
max_load_factor 容器最大负载系数
max_size 返回容器可以容纳的最大元素数
operator= 重载运算符 =
operator[] 重载运算符 [],通过索引可返回对应元素的引用
rehash 参数n大于当前桶数,rehash,否则容器无变化
reserve n大于bucket_count*max_load_factor,rehash,否则容器无变化
size 返回容器中元素个数
swap 当前容器与参数容器中元素交换
3. bucket_* 与 load_factor
3.1 bucket_* 函数
- <1>.
unordered_map::bucket返回key所对应的桶(bucket)的编号,函数原型如下:
size_type bucket( const key_type& k ) const;
int main() {
std::unordered_map<std::string,std::string> mymap = {
{"us","United States"},
{"uk","United Kingdom"},
{"fr","France"},
{"de","Germany"} };
// 打印每个key对应的桶的编号
for (auto& x: mymap) {
std::cout << "Element [" << x.first << ":" << x.second << "]";
std::cout << " is in bucket #" << mymap.bucket (x.first) << std::endl;
}
return 0;
}
打印结果:
Element [us:United States] is in bucket #1
Element [de:Germany] is in bucket #2
Element [fr:France] is in bucket #2
Element [uk:United Kingdom] is in bucket #4
- <2>.
unordered_map::bucket_count返回当前容器中桶的个数。 - <3>.
unordered_map::max_bucket_count返回容器可以包含桶的最大数量。 - <4>.
unordered_map::bucket_size通过桶号查找并返回对应桶中元素的个数,函数原型分别为:
size_type bucket_count() const noexcept; // 1. bucket_count
size_type max_bucket_count() const noexcept; // 2. max_bucket_count
size_type bucket_size( size_type n ) const; // 3. bucket_size
int main () {
std::unordered_map<std::string,std::string> mymap = {
{"house","maison"},
{"apple","pomme"},
{"tree","arbre"},
{"book","livre"},
{"door","porte"},
{"grapefruit","pamplemousse"} };
unsigned n = mymap.bucket_count();
// 1. bucket_count
std::cout << "mymap中当前包含 " << n << " 个桶.\n";
// 2. max_bucket_count, 打印桶的个数
std::cout << "mymap最多能包含 " << mymap.max_bucket_count() << " 个桶.\n\n";
// 3. bucket_size, 打印对应序号的桶的元素个数
for (unsigned i=0; i<n; ++i) {
std::cout << "bucket #" << i << " has " << mymap.bucket_size(i) << " elements.\n";
}
return 0;
}
打印结果:
mymap中当前包含 7 个桶.
mymap最多能包含 115292150460684697 个桶.
bucket #0 has 1 elements.
bucket #1 has 2 elements.
bucket #2 has 1 elements.
bucket #3 has 0 elements.
bucket #4 has 1 elements.
bucket #5 has 0 elements.
bucket #6 has 1 elements.
3.2 load_factor 函数
- <1>.
unordered_map::load_factor返回容器当前负载系数。 - <2>.
unordered_map::load_factor返回容器最大负载系数,函数原型如下:
float load_factor() const noexcept; // 2. load_factor
float max_load_factor() const noexcept; // 3.1 get-max_load_factor
void max_load_factor( float z ); // 3.2 set-max_load_factor
此处要有必要解释一下这个负载系数
load_factor。负载系数
load_factor是 容器中当前元素数量size与桶的数量bucket_count的比值:
l o a d . f a c t o r = s i z e / b u c k e t . c o u n t load.factor =size / bucket.count load.factor=size/bucket.count
load_factor会影响哈希表中发生冲突的概率(即,两个元素位于同一存储桶中的概率)。
1. 因此,容器会自动增加桶数,以此将负载系数保持在特定阈值(其max_load_factor)以下。每次需要扩充桶数时都会rehash()。
2. 要检索或更改此阈值,请使用成员函数max_load_factor,一般情况下默认值为1.0.
总结:
I. 负载系数过大:每个桶存放的元素数量会变多,查找等操作效率变低;
II. 负载系数过小:每增加一些元素,就需要增加桶数来保持load_factor小于阈值,会频繁 rehash,导致性能降低。
所以加载因子的大小需要结合时间和空间效率考虑。
下述例子中:
unordered_map::max_size返回容器可以包含的元素的最大数量。
unordered_map::size返回容器中当前元素个数。
int main() {
std::unordered_map<std::string,std::string> mymap = {
{"Au","gold"},
{"Ag","Silver"},
{"Cu","Copper"},
{"Pt","Platinum"}
};
std::cout << "current max_load_factor: " << mymap.max_load_factor() << std::endl;
std::cout << "current size: " << mymap.size() << std::endl;
std::cout << "current bucket_count: " << mymap.bucket_count() << std::endl;
std::cout << "current load_factor: " << mymap.load_factor() << std::endl;
float z = mymap.max_load_factor();
mymap.max_load_factor ( z / 2.0 );
std::cout << "[---------------]" << std::endl;
std::cout << "new max_load_factor: " << mymap.max_load_factor() << std::endl;
std::cout << "new size: " << mymap.size() << std::endl;
std::cout << "new bucket_count: " << mymap.bucket_count() << std::endl;
std::cout << "new load_factor: " << mymap.load_factor() << std::endl;
return 0;
}
打印结果:
current max_load_factor: 1
current size: 4
current bucket_count: 5
current load_factor: 0.8
[---------------]
new max_load_factor: 0.5
new size: 4
new bucket_count: 11
new load_factor: 0.363636
4. reserve、rehash
4.1 reserve函数
- 记一下:
std::map没有这个成员函数 reserve()函数将容器中的桶数(bucket_count)设置为最适合的桶数量(包含至少n个元素),其函数原型如下所示。
void reserve( size_type n ); // n 为元素数量
- I. 如果参数
n大于bucket_count*max_load_factor,则增加容器的bucket_count并强制进行rehash操作。 - II. 如果参数
n小于上述值,则函数可能无效。
例子如下:
int main() {
std::unordered_map<std::string,std::string> mymap;
mymap.reserve(6); // 元素个数 6
// 该操作避免了后续多次的 rehash
std::cout << "mymap bucket_count: " << mymap.bucket_count() << std::endl;
mymap["house"] = "maison";
mymap["apple"] = "pomme";
mymap["tree"] = "arbre";
mymap["book"] = "livre";
mymap["door"] = "porte";
mymap["grapefruit"] = "pamplemousse";
for (auto& x: mymap) {
std::cout << x.first << ": " << x.second << std::endl;
}
return 0;
}
打印结果:
mymap bucket_count: 7
grapefruit: pamplemousse
door: porte
tree: arbre
book: livre
apple: pomme
house: maison
4.2 rehash函数
rehash()函数可重新设置桶的数量,其函数原型如下所示。
void rehash( size_type n );
- 若参数
n大于容器中的当前桶数(bucket_count),则将强制进行重建哈希表(rehash)。 新的桶数将等于或大于n。 - 若参数
n小于容器中当前的桶数,则该函数可能对桶数没有影响,可能不会强制进行重建哈希表。
重建哈希表 (
rehash):容器中的所有元素均根据其哈希值重新排列到新的存储桶集中。 这可能会更改容器内元素的迭代顺序。
此外: 当容器的负载系数(load factor)大于阈值,容器便会自动执行重建哈希表(rehash)操作。
例子如下:
int main () {
std::unordered_map<std::string,std::string> mymap; // bucket_count=1
mymap.rehash(20); // bucket_count>20, 为23
mymap["house"] = "maison";
mymap["apple"] = "pomme";
mymap["tree"] = "arbre";
mymap["book"] = "livre";
mymap["door"] = "porte";
mymap["grapefruit"] = "pamplemousse";
std::cout << "current bucket_count: " << mymap.bucket_count() << std::endl;
return 0;
}
打印结果:current bucket_count: 23
5. 与 map 的区别
std::map底层是用红黑树实现的
优点:
I. 内部元素有序,其元素的有序性在很多应用中都会简化很多的操作。
II. 红黑树结构使得map中的插入、删除、查找都可在O(logn)下完成。
缺点:
I. 占用的空间大,map内部实现了红黑树,每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间。
std::unordered_map底层是哈希表实现
优点:
I. 查找速度非常的快,复杂度接近O(1),插入和删除操作复杂度也接近O(1),最差情况为O(n)。
缺点:
I. 哈希表结构使得其内部元素无序。
II. 内存方面,红黑树 VS 哈希表:unordered_map占用的内存要高一些。
- 无论是查找效率还是插入、删除效率
unordered_map都优于map。因此通常情况下使用unordered_map会更加高效一些,当对于那些有顺序要求的问题,用map会更高效一些。