数据分析一般过程笔记
在开始之前,使用 iPython 笔记本时有几点需要注意一下:
- 如果代码单元格被运行之后,在单元格的左侧方框中会有数字出现。
- 当你启动一个新的笔记本会话时,请确保运行所有单元格(从第1个到你上次离开的单元格)。即使笔记本中依然可以看到上次运行所得到的输出,你重新运行的笔记本内核却处于一个完全新的状态,所以你需要重载数据和运行代码。
- 上一条注意事项特别重要。当你的答案和课程中的练习不一致时,请试着重载数据并一个一个运行代码单元格,以确保你所操作的变量和数据和练习中的一致。
从 CSV 加载数据
import unicodecsv
## 长代码版本 (该版本与短代码版本功能一致)
# enrollments = []
# f = open('enrollments.csv', 'rb') "b"代表改变文件读取格式
# reader = unicodecsv.DictReader(f)
# for row in reader:
# enrollments.append(row)
# f.close()
def read_csv(filename):
with open(filename, 'rb') as f:##计算机速成课,软件是一项工程,如何用别人写好的代码,别人给你开个接口,就可以直接用,open函数就相当于接口
reader = unicodecsv.DictReader(f) ## reader 返回的是一个对象,是DictReader的实例,不能作为对象访问,
#在迭代时,会生成可以相应访问的字典 ,可以创建一个空列表,将每个字典添加到列表中
#for r in reader: 也可以直接list(reader) 同样的效果
return list(reader)## 从 daily_engagement.csv 和 project_submissions.csv 载入数据并存
## 储至下面的变量中,然后检查每张表的第1行。
enrollments_filename = r'C:\My documents\Learning file\Udacity\Introductory course for Data analysis\project 2\practice\enrollments.csv'
engagements_filename = r'C:\My documents\Learning file\Udacity\Introductory course for Data analysis\project 2\practice\daily-engagement.csv'
submissions_filename = r'C:\My documents\Learning file\Udacity\Introductory course for Data analysis\project 2\practice\project-submissions.csv'
enrollments = read_csv(enrollments_filename)
daily_engagement = read_csv(engagements_filename)
project_submissions = read_csv(submissions_filename)
print(enrollments[0])
print(daily_engagement[0])
print(project_submissions[0])
# csv库并不检测个列的类型OrderedDict([('account_key', '448'), ('status', 'canceled'), ('join_date', '2014-11-10'), ('cancel_date', '2015-01-14'), ('days_to_cancel', '65'), ('is_udacity', 'True'), ('is_canceled', 'True')])
OrderedDict([('acct', '0'), ('utc_date', '2015-01-09'), ('num_courses_visited', '1.0'), ('total_minutes_visited', '11.6793745'), ('lessons_completed', '0.0'), ('projects_completed', '0.0')])
OrderedDict([('creation_date', '2015-01-14'), ('completion_date', '2015-01-16'), ('assigned_rating', 'UNGRADED'), ('account_key', '256'), ('lesson_key', '3176718735'), ('processing_state', 'EVALUATED')])
为防止出现如下错误:(unicode error) ‘unicodeescape’ codec can’t decode bytes in position 29-33:
在路径前加r,路劲就直接系统的路径复制过来就好了
print(enrollments[0])OrderedDict([('account_key', '448'), ('status', 'canceled'), ('join_date', '2014-11-10'), ('cancel_date', '2015-01-14'), ('days_to_cancel', '65'), ('is_udacity', 'True'), ('is_canceled', 'True')])
print(daily_engagement[0]) OrderedDict([('acct', '0'), ('utc_date', '2015-01-09'), ('num_courses_visited', '1.0'), ('total_minutes_visited', '11.6793745'), ('lessons_completed', '0.0'), ('projects_completed', '0.0')])
print(project_submissions[0]) OrderedDict([('creation_date', '2015-01-14'), ('completion_date', '2015-01-16'), ('assigned_rating', 'UNGRADED'), ('account_key', '256'), ('lesson_key', '3176718735'), ('processing_state', 'EVALUATED')])
修正数据类型
from datetime import datetime as dt
# 将字符串格式的时间转为 Python datetime 类型的时间。
# 如果没有时间字符串传入,返回 None
def parse_date(date):
if date == '':
return None
else:
return dt.strptime(date, '%Y-%m-%d')
# 将可能是空字符串或字符串类型的数据转为 整型 或 None。
def parse_maybe_int(i):
if i == '':
return None
else:
return int(i)
# 清理 enrollments 表格中的数据类型
for enrollment in enrollments:
enrollment['cancel_date'] = parse_date(enrollment['cancel_date'])
enrollment['days_to_cancel'] = parse_maybe_int(enrollment['days_to_cancel'])
enrollment['is_canceled'] = enrollment['is_canceled'] == 'True'
enrollment['is_udacity'] = enrollment['is_udacity'] == 'True'
enrollment['join_date'] = parse_date(enrollment['join_date'])
enrollments[0]OrderedDict([('account_key', '448'),
('status', 'canceled'),
('join_date', datetime.datetime(2014, 11, 10, 0, 0)),
('cancel_date', datetime.datetime(2015, 1, 14, 0, 0)),
('days_to_cancel', 65),
('is_udacity', True),
('is_canceled', True)])
# 清理 engagement 的数据类型
for engagement_record in daily_engagement:
engagement_record['lessons_completed'] = int(float(engagement_record['lessons_completed']))
engagement_record['num_courses_visited'] = int(float(engagement_record['num_courses_visited']))
engagement_record['projects_completed'] = int(float(engagement_record['projects_completed']))
engagement_record['total_minutes_visited'] = float(engagement_record['total_minutes_visited'])
engagement_record['utc_date'] = parse_date(engagement_record['utc_date'])
daily_engagement[0]OrderedDict([('acct', '0'),
('utc_date', datetime.datetime(2015, 1, 9, 0, 0)),
('num_courses_visited', 1),
('total_minutes_visited', 11.6793745),
('lessons_completed', 0),
('projects_completed', 0)])
# 清理 submissions 的数据类型
for submission in project_submissions:
submission['completion_date'] = parse_date(submission['completion_date'])
submission['creation_date'] = parse_date(submission['creation_date'])
project_submissions[0]OrderedDict([('creation_date', datetime.datetime(2015, 1, 14, 0, 0)),
('completion_date', datetime.datetime(2015, 1, 16, 0, 0)),
('assigned_rating', 'UNGRADED'),
('account_key', '256'),
('lesson_key', '3176718735'),
('processing_state', 'EVALUATED')])
注意:当我们在运行上方的单元格时,我们已经改变了数据变量中的内容。如果你试着在同一个会话多次运行这些单元格时,可能会出错。
探索数据
以上数据格式已经清洗为python所用格式,接下来思考,通过这个数据能够回答什么问题–从数据库设计角度,设计三个数据表,每个表的内容包括什么
1.研究学生通常多长时间提交他们的项目;
2.通过项目和未通过项目的学生的特点;
调查数据
成功加载数据并确保数据格式良好,说明你已经开始数据整理过程了。下一步就是调查,看看数据中是否存在不一致处或问题,如果有,你需要清理它们。
对于你加载的每个文件(一共有三个),找到 csv 中的总行数以及不重复学员的数量。要在每个数据表中查找不重复学员数,你可能会需要创建一组帐号键值。
以下代码在写的时候注意点:
1.len函数前不需要加print函数
2.一个运行单元中不能同时写两个len函数,不然运行时只能显示一个结果
for engagement in daily_engagement:
engagement["account_key"] = engagement["acct"]
del engagement["acct"]
## 将 daily_engagement 表中的 "acct" 重命名为 ”account_key"
## 删除字典中的元素----account_key相同之后,可以将之前的代码写成函数def get_unique_students(datas):
unique_students = set()
for data in datas:
unique_students.add(data["account_key"])
return unique_students #之后可能要用到这个集合本身,所以不需要更进一步的获取到该集合的数量,只要获取集合就可以了len(enrollments)1640
unique_enrolled_students = get_unique_students(enrollments)
len(unique_enrolled_students)1302
len(daily_engagement)136240
unique_engagement_students = get_unique_students(daily_engagement)
len(unique_engagement_students) 1237
len(project_submissions)3642
unique_project_submitter = get_unique_students(project_submissions)
len(unique_project_submitter) 743
数据中的问题
1.注册表中去重后学生人数比参与表中学生人数多;参与表中的注册人数应该对应注册表中的人数,两者数量应该相等;
2.含有学生账号值的那列数据,在两个表中是account_key,在另一个表中是acct;—已更改,提到前边了
为什么参与表的数据有缺失,如何调查此类问题:
1.找出异常的数据点–在这里就是没有相应参与数据的注册记录,
2.接下来要打印出一个或多个异常数据点,
有时可以通过观察,直接找出问题。
在注册表中找出在参与表中没有相应学生的任意一行。
缺失的互动(Engagement)记录
for enrollment in enrollments:
student = enrollment["account_key"]
if student not in unique_engagement_students:
print(enrollment)
break
## 找到任意一个 enrollments 中的学生,但不在 daily engagement 表中。
## 打印出这条 enrollments 记录
## break 只要找到一条信息就停下来
##由下边的运行结果来看,参与时间John_date = cancle_date,因为学生可能需要登录一整天,才会在参与表中有记录
## 因为是要查看记录,所以不能直接用 注册表的去重的账号与参与表中去重账号相匹配
## not_engagement_students = set()
## for engagemnt in get_unique_students(enrollments):
## if engagement not in get_unique_students(daily_engagement):
## not_engagement_students.add(engagement)
## print(not_engagement_students)
OrderedDict([('account_key', '1219'), ('status', 'canceled'), ('join_date', datetime.datetime(2014, 11, 12, 0, 0)), ('cancel_date', datetime.datetime(2014, 11, 12, 0, 0)), ('days_to_cancel', 0), ('is_udacity', False), ('is_canceled', True)])
检查更多的问题记录
not_engagement_students = 0
for enrollment in enrollments:
student = enrollment["account_key"]
if (student not in unique_engagement_students and
enrollment["join_date"] != enrollment["cancel_date"]): ## 注意此处的括号,and链接记得加括号
print(enrollment)
not_engagement_students += 1
print(not_engagement_students)
## 计算5种不同的数据点条数(在 enrollments 中存在,但在 engagement 表中缺失)
## 发现的问题,学生在注册的当天就注销掉了--这点很重要,因为接下来的数据分析,我们需要排除此类学生,或者需要知道此类问题
## 以便防止代码边际问题的产生
## 排查除了是当天注册注销的学生外,是否有其他的异常点
OrderedDict([('account_key', '1304'), ('status', 'canceled'), ('join_date', datetime.datetime(2015, 1, 10, 0, 0)), ('cancel_date', datetime.datetime(2015, 3, 10, 0, 0)), ('days_to_cancel', 59), ('is_udacity', True), ('is_canceled', True)])
OrderedDict([('account_key', '1304'), ('status', 'canceled'), ('join_date', datetime.datetime(2015, 3, 10, 0, 0)), ('cancel_date', datetime.datetime(2015, 6, 17, 0, 0)), ('days_to_cancel', 99), ('is_udacity', True), ('is_canceled', True)])
OrderedDict([('account_key', '1101'), ('status', 'current'), ('join_date', datetime.datetime(2015, 2, 25, 0, 0)), ('cancel_date', None), ('days_to_cancel', None), ('is_udacity', True), ('is_canceled', False)])
3
追踪剩余的问题
# 为所有 Udacity 测试帐号建立一组 set -----优达的测试账号不一定在参与表中体现出来
udacity_test_accounts = set()
for enrollment in enrollments:
if enrollment['is_udacity']:
udacity_test_accounts.add(enrollment['account_key'])
len(udacity_test_accounts)6
# 通过 account_key 删除所有 Udacity 的测试帐号
def remove_udacity_accounts(data):
non_udacity_data = []
for data_point in data:
if data_point['account_key'] not in udacity_test_accounts:
non_udacity_data.append(data_point)
return non_udacity_data# 从3张表中移除所有 Udacity 的测试帐号 -----为剩下的数据建立了新的变量,之所以没有删除数据,是因为防止以后需要原始数据
non_udacity_enrollments = remove_udacity_accounts(enrollments)
non_udacity_engagement = remove_udacity_accounts(daily_engagement)
non_udacity_submissions = remove_udacity_accounts(project_submissions)
print(len(non_udacity_enrollments))
print (len(non_udacity_engagement))
print (len(non_udacity_submissions))1622
135656
3634
此时已经完成了数据再加工,需要进行数据探索 exploration phase但是此后可能还会发现问题,到时会再解决他们
我想先研究对于通过和未通过第一个项目的学生而言,他们在每日参与表中的数据有何不同,但是这个问题,有些地方不够明确,比较奇怪。
- 如果我要观察每日参与表中的所有记录,那就包括项目提交后的数据,但是项目提交后的数据对于我们的研究没有什么关联,所以我们只观察首个项目提交前的参与数据。
2.如果我只看第一次提交前的参与情况,以及学生在一段时间后的提交情况,那么我需要比较的就是不同时间段的参与数据。但是学生的参与度可能会随时间变化–比如在最开始的几天之后,参与度可能会有所下降。如果是这样,那么将某学生一个月中的平均参与率与另一个学生两个月的参与情况相比较,可能会有误导性。
3.第三个问题是,我们使用的每日参与表含有整个纳米学位项目的参与数据,它也包括了与第一个项目无关的课程,这就比较奇怪了。
为了解决前两个问题,我只需要查看学生注册第一周的数据,我要把在一周内注销的学生排除在外。这样一来比较的时间段就相同了,这样做也有利于在收集数据时,排除在7天免费试用期过后注销的学生。
第三个问题也不难处理,我要查看纳米学位项目所有课程的参与数据,如果你只想看纳米学位第一节课的参与数据,可以下载每日参与数据的完整表格,其中包括按照课程分类,
首先,创建未注销学生字典或注销前注册超过七天的学生的字典,如果学生还没有注销,则days_to_cancel一列应该是None;如果学生注册超过7天,则该字段应该大于7;字典的键应该是account_keys,值应为学生注册的日期,因为,该日期此后还需要用于寻找第一周的参与记录。你应该将字典命名为paid_students
重新定义问题
paid_students = {}
for enrollment in non_udacity_enrollments:
if (not enrollment["is_canceled"] or enrollment["days_to_cancel"] > 7):
account_key = enrollment["account_key"]
enrollment_date = enrollment["join_date"]
if (account_key not in paid_students or enrollment_date > paid_students[account_key]):
paid_students[account_key] = enrollment_date
len(paid_students)
##筛选出付费的学生,建立一个字典
## 创建一个叫 paid_students 的字典,并在字典中存储所有还没有取消或者注册时间超过7天的学生。
## 字典的键为帐号(account key),值为学生注册的时间。
## 写代码时注意单词的拼写
## 如果写成if (enrollment_date > paid_students[account_key] or account_key not in paid_students)
## 会出错,python 中or的执行逻辑 https://stackoverflow.com/questions/13960657/does-python-evaluate-ifs-conditions-lazily995
获取第1周的数据
获取第1周的数据
# 基于学生的加入日期和特定一天的互动记录,若该互动记录发生在学生加入1周内,则反回 True
def within_one_week(join_date, engagement_date):
time_delta = engagement_date - join_date
return time_delta.days < 7 and time_delta.days >=0##在三张表中筛选中付费学生的记录,是记录,不是之前的单独付费学生字典
def remove_free_trail_cancel(data):
new_data = []
for data_record in data:
if data_record["account_key"] in paid_students:
new_data.append(data_record)
return new_data
paid_enrollment = remove_free_trail_cancel(non_udacity_enrollments)
paid_engagement = remove_free_trail_cancel(non_udacity_engagement)
paid_submissions = remove_free_trail_cancel(non_udacity_submissions)
print(len(paid_enrollment))
print(len(paid_engagement))
print(len(paid_submissions))
## 创建一个 engagement 记录的列表,该列表只包括付费学生以及加入的前7天的学生的记录
## 输入符合要求的行数
for engagement_record in paid_engagement:
if engagement_record["num_courses_visited"] > 0:
engagement_record["has_visited"] = 1 ##字典中添加新元素的方法,记住,要会使用此方法
else:
engagement_record["has_visited"] = 0
paid_engagement_in_first_week = []
for engagement_record in paid_engagement: ##注意此处是在付费的学生记录中,不是non_udacity_engagement
account_key = engagement_record["account_key"] ##一个字典跟一个列表链接,中间必须要有相同的东西---关系,搭建桥梁,
##就像SQL中多张表连接一样
##为什么写成account_key = engagement["account_key"] 也可以运行,结果是134549 ,相当于没有进行条件筛选了
join_date = paid_students[account_key]
engagement_date = engagement_record["utc_date"] ## utc_date 是注册之后的参与日期
if within_one_week(join_date,engagement_date):## 不需要写成(within_one_week(join_date,engagement_date))
paid_engagement_in_first_week.append(engagement_record)
print(len(paid_engagement_in_first_week))1293
134549
3618
6919
满足好奇心:
根据我想回答的问题,接下来的任务应该是将数据分成两组:
一组是最终通过第一个项目的学生;
一组是没有通过项目的学生;
但我有这么多有关学生第一周参与情况的数据,我很好奇,想观察一下数据
如果对数据好奇就去调查它,熟悉你的数据总是有用的
我想研究的又一个问题是,学生第一周上课的平均时间:
现在我有不同学生的参与记录,它们并未按顺序排列。
首先,我要对参与记录进行分组,使各组分别含有某学生的所有参与记录
我用字典来表现这些组,将键设为学生账号值,值设为该学生的参与记录表,
接下来,要把各学生的所有参与记录数据相加,以计算各学生上课的总时间,
最后,我要计算总数的平均值,以获得我想要的答案
要计算第一周学生的学习平均时间:
1.统计出每个学生的学习时间—defaultdict(list)来实现,按照学生分类
2.将每个学生的不同分类的学习时间汇总,到一个字典中
3.将字典中的所有值相加–利用numpy库来解决
Exploring Student Engagement
from collections import defaultdict
# 创建基于 student 对 engagement 进行分组的字典,字典的键为帐号(account key),值为包含互动记录的列表
#engagement_by_account = defaultdict(list)##用这个字典,主要是为了,当键不存在时,能返回空列表
#for engagement_record in paid_engagement_in_first_week:
# account_key = engagement_record['account_key']
#engagement_by_account[account_key].append(engagement_record)##官方写法,比较简洁
def group_data(data,filed_name):
group_data = defaultdict(list)
for data_piont in data:
account_key = data_piont[filed_name]
group_data[account_key].append(data_piont)
return group_data
engagement_by_account = group_data(paid_engagement_in_first_week,"account_key")认识defaultdict:
当我使用普通的字典时,用法一般是dict={},添加元素的只需要dict[element] =value即,调用的时候也是如此,dict[element] = xxx,但前提是elemen在字典里,如果不在字典里就会报错,
这时defaultdict就能排上用场了,defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值,这个默认值是什么呢,下面会说
如何使用defaultdict
defaultdict接受一个工厂函数作为参数,如下来构造:
dict =defaultdict( factory_function)
这个factory_function可以是list、set、str等等,作用是当key不存在时,返回的是工厂函数的默认值,比如list对应[ ],str对应的是空字符串,set对应set( ),int对应0,如下举例:
from collections import defaultdict
dict1 = defaultdict(int)
dict2 = defaultdict(set)
dict3 = defaultdict(str)
dict4 = defaultdict(list)
dict1[2] =‘two’
print(dict1[1])
print(dict2[1])
print(dict3[1])
print(dict4[1]】
输出:
0
set()
[]
用法:
from collections import defaultdict
l=[(‘a’,2),(‘b’,3),(‘a’,1),(‘b’,4),(‘a’,3),(‘a’,1),(‘b’,3)]
d=defaultdict(list)
for key,value in l:
d[key].append(value)d
defaultdict(,{‘a’:[2,1,3,1],‘b’:[3,4,3]}
原文:https://blog.csdn.net/liufang0001/article/details/54618484
# 创建一个包含学生在第1周在教室所花总时间和字典。键为帐号(account key),值为数字(所花总时间)
#total_minutes_by_account = {}
#for account_key, engagement_for_student in engagement_by_account.items():
#total_minutes = 0
#for engagement_record in engagement_for_student:
# total_minutes += engagement_record['total_minutes_visited']
#total_minutes_by_account[account_key] = total_minutes
def total_sth(group_data,filed_name):
total_sth = {}
for key,data_piont in group_data.items():
total = 0
for data_record in data_piont:
total += data_record[filed_name]
total_sth[key] = total
return total_sth
total_minutes_by_account = total_sth(engagement_by_account,'total_minutes_visited')##用法示例
from collections import defaultdict
l=[(‘a’,2),(‘b’,3),(‘a’,1),(‘b’,4),(‘a’,3),(‘a’,1),(‘b’,3)]
d=defaultdict(list)
for key,value in l:
d[key].append(value)
print(d)
print(d.items())
defaultdict(
dict_items([(‘a’, [2, 1, 3, 1]), (‘b’, [3, 4, 3])])
%pylab inline
import matplotlib.pyplot as plt
import numpy as np
# 汇总和描述关于教室所花时间的数据
#total_minutes = list(total_minutes_by_account.values())##字典的value方法是将所有值列出,是字典值,直接用numpy计算平均值是会返回错误的,
##转成字典就好了
#print( 'Mean:',np.mean(total_minutes))
#print ('Standard deviation:', np.std(total_minutes))##标准偏差用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少
##print ('Maximum:', np.max(total_minutes))
total_minutes = list(total_minutes_by_account.values())
def describe_data(data):
print('Mean:', np.mean(data))
print('Standard deviation:', np.std(data))
print('Minimum:', np.min(data))
print('Maximum:', np.max(data))
plt.hist(data)
describe_data(total_minutes)
Populating the interactive namespace from numpy and matplotlib
Mean: 306.70832675342825
Standard deviation: 412.99693340852957
Minimum: 0.0
Maximum: 3564.7332644989997
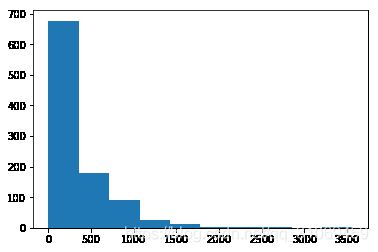
标准偏差的值很大,比平均值还大
最小值0,最大值10568,比一周的总时间都长,肯定有问题
调试数据分析代码
解决这个问题的过程与之前缺失参与记录的过程是一样的:
确定哪些数据点属于异常点
打出异常点,看是否发现问题
找出异常点并打印出来
找到异常的分钟数,找到异常的学生
纠错现有的数据分析代码
max_minutes_student = None
max_minutes = 0
for student,total_minutes in total_minutes_by_account.items(): ##要学会用这种方法
if total_minutes > max_minutes:
max_minutes = total_minutes
max_minutes_student = student
print(max_minutes)
for engagement_record in paid_engagement_in_first_week:
if engagement_record["account_key"] == max_minutes_student:
print(engagement_record)
## 通过之前的方法检查是否有问题数据存在。
## 定位至少一条异常数据,打印出来并检查。
3564.7332644989997
OrderedDict([('utc_date', datetime.datetime(2015, 7, 9, 0, 0)), ('num_courses_visited', 4), ('total_minutes_visited', 850.519339666), ('lessons_completed', 4), ('projects_completed', 0), ('account_key', '163'), ('has_visited', 1)])
OrderedDict([('utc_date', datetime.datetime(2015, 7, 10, 0, 0)), ('num_courses_visited', 6), ('total_minutes_visited', 872.633923334), ('lessons_completed', 6), ('projects_completed', 0), ('account_key', '163'), ('has_visited', 1)])
OrderedDict([('utc_date', datetime.datetime(2015, 7, 11, 0, 0)), ('num_courses_visited', 2), ('total_minutes_visited', 777.018903666), ('lessons_completed', 6), ('projects_completed', 0), ('account_key', '163'), ('has_visited', 1)])
OrderedDict([('utc_date', datetime.datetime(2015, 7, 12, 0, 0)), ('num_courses_visited', 1), ('total_minutes_visited', 294.568774), ('lessons_completed', 2), ('projects_completed', 0), ('account_key', '163'), ('has_visited', 1)])
OrderedDict([('utc_date', datetime.datetime(2015, 7, 13, 0, 0)), ('num_courses_visited', 3), ('total_minutes_visited', 471.2139785), ('lessons_completed', 1), ('projects_completed', 0), ('account_key', '163'), ('has_visited', 1)])
OrderedDict([('utc_date', datetime.datetime(2015, 7, 14, 0, 0)), ('num_courses_visited', 2), ('total_minutes_visited', 298.778345333), ('lessons_completed', 1), ('projects_completed', 0), ('account_key', '163'), ('has_visited', 1)])
OrderedDict([('utc_date', datetime.datetime(2015, 7, 15, 0, 0)), ('num_courses_visited', 0), ('total_minutes_visited', 0.0), ('lessons_completed', 0), ('projects_completed', 0), ('account_key', '163'), ('has_visited', 0)])
结果中的数据远非7条,因为只是在第一周付费参与的,应该只包含一周的数据,此外数据点也不在一周范围内,
可以看到第一个数据点是在2015.1.7,底部最后一个日期是4.26.
所以within_one_week函数可能出问题了。
在这个函数中,我校验了参与日期与注册日期,最多相隔7天,并没有校验参与日期在注册日期之后,所以对于注册后注销,再注册的学生,其第一次注册的所有数据都会被算作第一周的数据。为确保这个问题,我要确保注册日期和参与日期之间,至少相隔0天。这样一来,我只考虑最近的注册数据
第1周完成的课程数(Lessons)
lessons_completed_in_first_week_account = total_sth(engagement_by_account,'lessons_completed')
total_lessons = list(lessons_completed_in_first_week_account.values())
describe_data(total_lessons)
## 修改之前的代码,找出第1周学生完成课程数的 平均值、标准差、最小值、最大值。尝试创建一个或更多的函数来复用之前的代码
Mean: 1.636180904522613
Standard deviation: 3.002561299829423
Minimum: 0
Maximum: 36
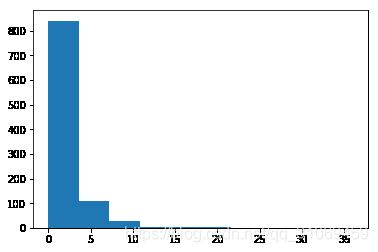
第1周的访问次数
##统计一周中有几天在访问,而num_courese_visited字段是每天访问了几节课,并不等于上课的天数
##所以需要创建一个字段 has_visited
course_visited_account = total_sth(engagement_by_account,'has_visited')
total_courses = list(course_visited_account.values())
describe_data(total_courses)
## 找出第1周学生访问教室天数的平均值、标准差、最小值、最大值。Mean: 2.8673366834170855
Standard deviation: 2.2551980029196814
Minimum: 0
Maximum: 7

区分项目通过的学生
######################################
# 11 #
######################################
##将每日参与数据分为两个列表,一个是通过首个项目的学生参与数据,另一个是未通过首个项目的学生参与数据
## 创建两个付费学生第1周的互动数据列表(engagement)。第1个包含通过项目的学生,第2个包含没通过项目的学生。
subway_project_lesson_keys = ['746169184', '3176718735']
pass_students_list = set()
for submission_record in paid_submissions:
if((submission_record["lesson_key"] in subway_project_lesson_keys)
and (submission_record["assigned_rating"] in ["PASSED","DISTINCTION"])):#如果此处单独有一个accoutn值,可以直接在engagement_record["account_key"]中等于钙质
pass_students_list.add(submission_record["account_key"]) ##但是此处值很多,需要建立一个列表,但是不能 有重复值,所以写成集合
## passed and distiction都是通过的,所以要写两个条件,其余都是不满足的
print(len(pass_students_list))
#for submission in paid_submissions:
# project = submission['lesson_key'] 写成这样会更直观
# rating = submission['assigned_rating']
#if ((project in subway_project_lesson_keys) and
#(rating == 'PASSED' or rating == 'DISTINCTION')):
# pass_subway_project.add(submission['account_key'])
passing_engagement = [] ##在第一周的参与数据中,通过项目的学生通过条件筛选出来了,则剩下的是未通过的
non_passing_engagement = []
for engagement_record in paid_engagement_in_first_week:
if engagement_record["account_key"] in pass_students_list:
passing_engagement.append(engagement_record)
else:
non_passing_engagement.append(engagement_record)
#non_pass_students_list = set()
#non_passing_engagement = []
#for submission_record in paid_submissions:
#if((submission_record["lesson_key"] in subway_project_lesson_keys)
#and (submission_record["assigned_rating"] in ["INCOMPLETE","blank","UNGRADED"])):
#non_pass_students_list.add(submission_record["account_key"])
#for engagement_record in paid_engagement_in_first_week:
# if engagement_record["account_key"] not in pass_students_list:
# non_passing_engagement.append(engagement_record)
print(len(passing_engagement))
print(len(non_passing_engagement))647
4527
2392
对比两组学生数据
需要计算两组的一些数据指标,可以从之前研究过的三个指标入手,学生上课的分钟数,完成的课程数,以及上课的天数
还可以再研究其他问题,比如这些学生是否更有可能完成其他项目,选择你认为差异最突出的数据指标
######################################
# 12 #
######################################
##前边的函数,方便查看,搬到这里了
#def group_data(data,filed_name):
# group_data = defaultdict(list)
# for data_piont in data:
# account_key = data_piont[filed_name]
#group_data[account_key].append(data_piont)
#return group_data
#def total_sth(group_data,filed_name):
# total_sth = {}
#for key,data_piont in group_data.items():
# total = 0
# for data_record in data_piont:
# total += data_record[filed_name]
# total_sth[key] = total
# return total_sth
#total_minutes = list(total_minutes_by_account.values())
#def describe_data(data):
# print('Mean:', np.mean(data))
# print('Standard deviation:', np.std(data))
#print('Minimum:', np.min(data))
# print('Maximum:', np.max(data))
pass_student_by_account = group_data(passing_engagement,"account_key")
##访问总时间数据
pass_student_total_minutes = total_sth(pass_student_by_account,"total_minutes_visited")
total_minutes = list(pass_student_total_minutes.values())
print("通过学生访问课程总时间数据:")
describe_data(total_minutes)
##访问总时间数据
non_pass_student_total_minutes = total_sth(non_pass_student_by_account,"total_minutes_visited")
total_minutes = list(non_pass_student_total_minutes.values())
print("未通过学生访问课程总时间数据:")
describe_data(total_minutes)
通过学生访问课程总时间数据:
Mean: 394.58604648350865
Standard deviation: 448.4995193265521
Minimum: 0.0
Maximum: 3564.7332644989997
未通过学生访问课程总时间数据:
Mean: 143.32647426675584
Standard deviation: 269.5386190114951
Minimum: 0.0
Maximum: 1768.5227493319999

##课程完成数
pass_student_courses = total_sth(pass_student_by_account,"lessons_completed")
total_courses = list(pass_student_courses.values())
print("通过学生课程完成数量数据:")
describe_data(total_courses)
print("\n")
non_pass_student_courses = total_sth(non_pass_student_by_account,"lessons_completed")
total_courses = list(non_pass_student_courses.values())
print("未通过学生课程完成数量数据:")
describe_data(total_courses)
print("\n")通过学生课程完成数量数据:
Mean: 2.052550231839258
Standard deviation: 3.1422270555779344
Minimum: 0
Maximum: 36
未通过学生课程完成数量数据:
Mean: 0.8620689655172413
Standard deviation: 2.5491599418312028
Minimum: 0
Maximum: 27

##访问天数
pass_student_days = total_sth(pass_student_by_account,"has_visited")
total_days = list(pass_student_days.values())
print("通过学生访问天数数据:\n")
describe_data(total_days)
print("\n")
## 计算你所感兴趣的数据指标,并分析通过项目和没有通过项目的两组学生有何异同。
## 你可以从我们之前使用过的数据指标开始(教室的访问时间、课程完成数、访问天数)。
non_pass_student_days = total_sth(non_pass_student_by_account,"has_visited")
total_days = list(non_pass_student_days.values())
print("未通过学生访问天数数据:/n")
describe_data(total_days)通过学生访问天数数据:
Mean: 3.384853168469861
Standard deviation: 2.2588214709184595
Minimum: 0
Maximum: 7
未通过学生访问天数数据:/n
Mean: 1.9051724137931034
Standard deviation: 1.9057314413619046
Minimum: 0
Maximum: 7

如果从以上选一个最有趣的差异,我可能会选上课的总分钟数,因为一个是第一周6.5各小时,一个是2.5小时,我认为两者差距最大,但是这个还是比较主观的
制作直方图
######################################
13 #
######################################
针对通过项目和没有通过项目的两组学生,为我们之前研究的三个数据指标制作直方图。
你也可以为其它你所检验的数据指标来制作直方图。
data = [1, 2, 1, 3, 3, 1, 4, 2]
%matplotlib inline
import matplotlib.pyplot as plt
plt.hist(data)
%matplotlib inline 这行代码专门用于 IPython 笔记本,可使图形呈现在你的笔记本而非新窗口中。
如果你没有使用 IPython 笔记本,你无需包含这行代码,而是应该在底部添加 plt.show() 这行代码,以便图形能够呈现在新窗口中。
直方图----数据的分布情况
x轴是上课时间总数或者访问课程总数及上课总天数区间,y轴是在这些区间中有多少学生
得出结论,进行预测#
我们已经解决了优达学成学生数据中的一些问题,同时,发现了变量之间的一些关系,现在,轮到我们得出结论,或者进行预测,你可能已经得出了一些初步结论,例如,通过地铁项目的学生在第一周中上课的分钟数要大于未通过的学生,但是,即便通过和未通过项目的学生之间不存在任何实际差异,两组的平均值也不会是相等的,那么,应该如何判断数据差异是真正的差异,还是数据中的噪音所导致的,我们看到的差异很大,这不太可能是由噪音造成的,但在这些情况中,直觉往往是不可靠的,你需要利用统计学来严格检查,偶然得出这些结果的可能性。----查看统计学课程
但是记住,我们得出的结论是未经证实的试验性结论
自己小结:通过对数据的统计,我们发现了变量间的一些关系,针对差异比较明显的关系,我们初步下了结论。但是这种差异是否是真正的差异,还是说很偶然,碰巧出现了这种差异,凭感觉是无法确定的,感觉不靠谱。这时候,需要用到统计学来严格检查,碰巧偶然得出这种可能性有多大。–统计学课程。
相关性,不表明因果关系#
你需要得出另一种结论是,如果改变某一数据,另一个数据也会随之变化
比如,你发现通过首个项目的学生,更愿意在第一周内多次上课,这就是相关性,通过首个项目,与多次上课相关,这能说明在第一周中多次上课,能使学生通过项目吗?这是一种因果关系的表述。例如,假设优达学城在学生注册第一周内向其发电邮,提醒他们回来上课,这使得更多学生的上课次数增多,但这会促使完成项目的学生数目增加吗?这听起来很有道理,但根据这个数据,我们还无法确定,为了解释这个问题,我们来看一下这个图

红色表示奶酪的人口消费,黑色表示因被床单缠住,而死亡的人数,可以看到,两个变量的相关度极高,随着其中一个变量的增加,另一个也会随之升高,但你认为食用奶酪是导致人们被床单缠住的原因吗?应该不是吧,这可能是巧合,或者,可能存在导致两者升高的第三个因素,在这里,奶酪消费和被床单缠住的情况,都在随时间的增加而增加。如果真是这样,即便你禁止了奶酪的食用,因被床单缠死而死亡的人数也可能会继续增长。
那么导致上课和通过项目之间关联的第三个因素可能有哪些呢?
我认为,其中一个可能是感兴趣的程度,也许,对数据分析不感兴趣的人也很少访问这个网站。而由于他们不想进行相关学习,他们也无法通过项目。如果你说服这些学生更频繁的访问网站,他们仍然可能因缺乏兴趣而不完成项目。对于这些学生而言,更好的方法可能是尝试学习其他他们感兴趣的东西。
另一个因素可能是背景知识,很多人没有学习数据分析的相关编程知识,因此,他们在陷入困境后就不再回来上课了。如果你说服这些学生回来继续学习,他们可能仍然无法走出困境,也无法取得任何进展。在这种情况下,学生可以 学习编程课程,以补习背景知识。
另一方面,这个相关性可能就是因果关系造成的,我觉得这个解释很合理。但根据目前的数据,我无法证实这一结论。
你需要进行相关实验,来验证两者是否是因果关系。
这个实验就是我们经常提到的A/B测试—了解这些实验的相关知识,以及实验中可能出现的问题,
自己小结:
上边我们得出了通过项目的学生与未通过项目学生总的学习时间上有明显差异,这个差异是否是真正的差异,需要统计学知识来检查。
这里又得出一个结论,学生上课时间增加,通过项目的数量也增加,两者是否是因果关系。
1.可能不是因果关系,只是具有相关性,就像吃奶酪与被床单缠死的例子,如果是相关性,那么肯定是存在第三个因素导致两者都上升,第三个因素是什么:老师给了两种情况,其一;兴趣决定了,其二:背景知识
2.如果真是因果关系,那么需要进行相关实验来验证,这个实验就是A/B测试----具体如何验证及实验过程中存在的问题,要看A/B测试那节课
基于众多特征进行预测#
你现在需要尝试预测哪些学生更可能通过首个项目,而那些不会通过,你可以先根据你的研究,利用启发式方法,处理这个问题。
例如,你可以预测,第一周上课时间较长的学生,最后更可能通过第一个项目,但这样做出的预测往往不够准确。
首先,我们可能需要,考虑更多。你至少要考虑之前已经研究过的东西。比如,完成课程数量,上课分钟数和上课天数,除此之外,你可能还要考虑,一些其他的信息或特征。这本身并不难。但是这些特征之间有着复杂的相互作用。
比如,在单独观察上课分钟数的数据时,它可能是一个很重要的特征,但当你同时考虑它和课程完成数量时,你可能会发现,在知道学生完成课程的数量后,他们上课的分钟数,就无法提供任何其他信息了。
在此类情况中,你可以利用机器学习,自动进行较为准确的预测,这通常比你手动进行的预测更准确。有些机器学习算法还会根据特征对预测的重要性,为你提供一系列特征,
自己小结:
预测是根据特征来的:
可以根据研究数据中的一些特征手动进行预测,以某一个特征进行预测时候(这个特征比较重要),但是某一个特征预测,其准确度不够。
如果多个特征进行预测,各个特征之间又有着复杂的相互作用:比如当同时考虑其他特征时,另一个特征可能就变得无法提供任何其他信息了,
可以通过机器学习进行预测。
沟通----可视化#
在得出结论和做出预测后,程序的最后一步是分享你的研究成果。
即使你的结论没有统计学和机器学习作为支撑,你也可以考虑如何就你的研究成果与他人进行交流。
此时,你需要找出你认为最有趣或最值得分享的研究成果。并决定如何分享这些成果。—可视化
例如,我感兴趣的是,通过和未通过首个项目的学生,在上课总分钟数上的区别,我认为最清楚的呈现该结果的方法是展现两组的平均值;
此外,我还觉得,第一周上课的天数很有趣。对此,我认为,直方图能更好的展示数据,如果你想采用可视化手段,最好要花时间对其进行优化。你要让它看起来更美观。使其能够传达你要表现的趋势。你虽然知道图表表达的意思,但你的读者不一定能看懂。
改进图表及分享发现
######################################
# 14 #
######################################
## 至少改进一幅之前的可视化图表,尝试导入 seaborn 库使你的图表看起来更美观。
## 加入轴标签及表头,并修改一个或多个 hist() 内的变量。