Hive之常见面试点
一、Hive的工作机制
1.Hive 通过给用户提供的一系列交互接口,用户提交查询等任务给Driver。
2.驱动程序将Hql发送给编译器,编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
3.编译器Compiler得到元数据信息,对任务进行编译。将Hql转换成抽象语法树AST并进行解析,然后将AST编译成逻辑执行计划,再通过逻辑执行计划进行优化的优化器,最后通过执行器将任务转换成mapreduce。
4.mapreduce提交到hadoop中执行,最后将执行返回的结果输出到用户交互接口。
二、元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
三、Hive数据库、表在HDFS上存储的路径是什么
/user/hive/warehouse
四、内部表和外部表的区别
1.未被external修饰的是内部表,被external修饰的为外部表。
2.内部表数据由Hive自身管理,外部表数据由HDFS管理;
Hive 默认情况下会将这些内部表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。
外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上 的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
3.删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
五、分区表和分桶表
(1)从表现形式上:
分区表是一个目录,分桶表是文件
(2)从创建语句上:
分区表使用partitioned by 子句指定,以指定字段为伪列(自定义),需要指定字段类型
分桶表由clustered by 子句指定,指定字段为真实字段,需要指定桶的个数
(3)从数量上:
分区表的分区个数可以增长,分桶表一旦指定,不能再增长
(4)从作用上:
1.分区避免全表扫描,根据分区列查询指定目录提高查询速度
2.对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围
划分。分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分桶的数据已经按照分桶字段进行了hash散列,分桶表数据进行抽样和JOIN时可以提高MR程序效率
六、order by、sort by、distribute by+sort by、cluster by
1.order by:对数据进行全局排序,一个MapReduce,会导致当输入规模较大时,需要较长的计算时间。
2.sort by:每个分区中进行排序,一般和distribute by使用,且distribute by写在sort by前面。当mapred.reduce.tasks=1时,效果和order by一样。
3.distribute by:类似MR的Partition,对key进行分区,结合sort by实现分区排序
4.cluster by:不能指定排序规则为 ASC 或者 DESC,只能正序排列;而 distribute by+sort by 可以定义排序规则
七、Hive数据导入与导出
导入
1.Load方式,可以从本地或HDFS上导入,本地是copy,HDFS是移动
本地:load data local inpath ‘/root/student.txt’ into table student;
HDFS:load data inpath ‘/user/hive/data/student.txt’ into table student;
2. Insert方式,往表里插入
3. As select方式,根据查询结果创建表并插入数据
4. Location方式,创建表并指定数据的路径
5. Import方式,先从hive上使用export导出在导入
导出
1.Insert方式,查询结果导出到本地或HDFS(没有local)
Insert overwrite local directory ‘/root/insert/student’ select id,name from student;
Insert overwrite directory ‘/user/ insert /student’ select id,name from student;
2.Hadoop命令导出本地
hive (default)> dfs -get /user/hive/warehouse/student/student.txt /opt/module/data/export/student3.txt;
3.hive Shell命令导出,基本语法:(hive -f/-e 执行语句或者脚本 > file)
[bym@hadoop102 hive]$ bin/hive -e ‘select * from default.student;’ >
/opt/module/hive/data/export/student4.txt;
4.Export导出到HDFS
hive> export table student to ‘/user/export/student’;
export 和 import 主要用于两个 Hadoop 平台集群之间 Hive 表迁移。
5.sqoop导出
八、Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。
Fetch抓取中
1.设置more效果:
执行某些查询语句,不会执行mapreduce程序
2.设置none效果:
执行查询语句,所有的查询都会执行mapreduce程序
九、本地模式有什么好处
在数据量较小时,提高查询效率
原因:有时 Hive 的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际 job 的执行时间要多的多。
查询数据的程序运行在提交查询语句的节点上运行(不提交到集群上运行)
十、当一个key数据过大导致数据倾斜时,如何处理
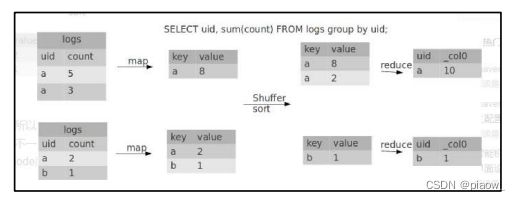
有数据倾斜的时候进行负载均衡,当配置信息参数设为true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个Reduce中),最后完成最终的聚合操作。即第一个程序进行局部聚和,第二个MR程序进行最终聚和。
十一、Hive的函数:UDF、UDAF、UDTF的区别?
UDF:单行进入,单行输出
UDAF:多行进入,单行输出
UDTF:单行输入,多行输出
十二、怎么自定义UDF、UDAF、UDTF函数?
1.自定义UDF函数
继承org.apache.hadoop.hive.ql.UDF函数;
重写evaluate方法,evaluate方法支持重载。
2.自定义UDAF函数
必须继承org.apache.hadoop.hive.ql.exec.UDAF(函数类继承)和org.apache.hadoop.hive.ql.exec.UDAFEvaluator(内部类Evaluator实现UDAFEvaluator接口);
重写Evaluator方法时需要实现 init、iterate、terminatePartial、merge、terminate这几个函数:
init():类似于构造函数,用于UDAF的初始化
iterate():接收传入的参数,并进行内部的轮转,返回boolean
terminatePartial():无参数,其为iterate函数轮转结束后,返回轮转数据,类似于hadoop的Combiner
merge():接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean
terminate():返回最终的聚集函数结果
3.自定义UDTF函数
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF函数;
重写实现initialize, process, close三个方法。
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
最后close()方法调用,对需要清理的方法进行清理。
通常使用 UDF 函数解析公共字段;用 UDTF 函数解析事件字段