Datawhale集成学习笔记:投票法的原理和案例分析
学习内容来源自:Datawhale
投票法的思路
投票法是集成学习中常用的技巧,可以帮助我们提高模型的泛化能力,减少模型的错误率。举个例子,在航空航天领域,每个零件发出的电信号都对航空器的成功发射起到重要作用。如果我们有一个二进制形式的信号:
11101100100111001011011011011
在传输过程中第二位发生了翻转
10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
下面我们使用一个例子说明硬投票:
对于某个样本:
模型 1 的预测结果是 类别 A
模型 2 的预测结果是 类别 B
模型 3 的预测结果是 类别 B
有2/3的模型预测结果是B,因此硬投票法的预测结果是B
同样的例子说明软投票:
对于某个样本:
模型 1 的预测结果是 类别 A 的概率为 99%
模型 2 的预测结果是 类别 A 的概率为 49%
模型 3 的预测结果是 类别 A 的概率为 49%
最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,因此软投票法的预测结果是A。
从这个例子我们可以看出,软投票法与硬投票法可以得出完全不同的结论。相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。当投票集合中使用的模型能预测类别的概率时,适合使用软投票。软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。
sklearn.ensemble.VotingRegressor参数说明
estimators:
list of (str, estimator) tuples
在VotingRegressor调用fit方法将你和存储在类属性self.estimators_中的原始估计器的克隆体。可以使用set_params将评估器设置为“drop”。
版本0.21中的更改:“drop”收录进该版本。
自版本0.22以来已弃用: 使用None删除评估器在0.22中已弃用,在0.24中删除了该功能并使用字符串’drop’代替。
weights:
array-like of shape (n_classifiers,), default=None
权重序列(float或int),用于在平均(soft voting)之前对预测的类标签(hard voting)或类概率的出现进行加权。如果没有,使用统一的权重。
n_jobs:
int, default=None
所有并行estimators fit作业数量。
除非在joblib.parallel_backend中,否则None表示是1。-1表示使用所有处理器。参见Glossary了解更多细节。
verbose:
bool, default=False
如果为True,拟合时经过的时间将在拟合完成时打印出来。
sklearn.ensemble.VotingClassifier 参数说明
voting = ‘hard’:使用 Hard Voting 做决策
voting = ‘soft’:使用 Soft Voting 做决策
这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)
有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)
模型还提供了voting参数让我们选择软投票或者硬投票:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')
下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
print(X.shape, y.shape)
运行给结果
(1000, 20) (1000,)
make_classification参数说明
n_samples:样本数量.
n_features:总的特征数量,是从有信息的数据点,冗余数据点,重复数据点,和特征点-有信息的点-冗余的点-重复点中随机选择的。
n_informative:多信息特征的个数
n_redundant:冗余信息,informative特征的随机线性组合
n_repeated:重复信息,随机提取n_informative和n_redundant 特征
n_classes:分类类别
n_clusters_per_class:某一个类别是由几个cluster构成的
weights :列表类型,权重比
flip_y:随机交换样本的一段
class_sep:乘以超立方体大小的因子。 较大的值分散了簇/类,并使分类任务更容易。默认为1
hypercube:If True the clusters are put on the vertices of a hypercube. If False,the clusters are put on the vertices of a random polytope.
shift:Shift features by the specified value. If None,then features are shifted by a random value drawn in [-class_sep,class_sep].
scale:Multiply features by the specified value. If None,then features are scaled by a random value drawn in [1,100]. Note that scaling happens after shifting.
shuffle:Shuffle the samples and the features.
random_state:如果是int,random_state是随机数发生器使用的种子; 如果RandomState实例,random_state是随机数生成器; 如果没有,则随机数生成器是np.random使用的RandomState实例。
我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
# evaluate a give model using cross-validation
from sklearn.model_selection import cross_val_score #Added by ljq
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
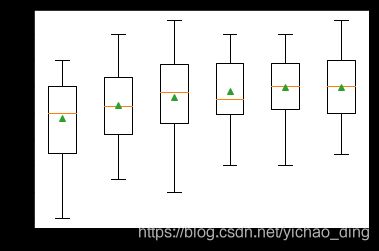
然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RepeatedStratifiedKFold
from matplotlib import pyplot
import numpy as np
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, np.mean(scores), np.std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
我们得到的结果如下:
硬投票结果:
knn1 0.876 (0.033)
knn3 0.886 (0.026)
knn5 0.892 (0.033)
knn7 0.896 (0.027)
knn9 0.900 (0.025)
hard_voting 0.902 (0.029)
显然投票的效果略大于任何一个基模型。
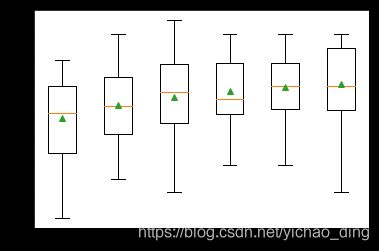
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
如果需要使用软投票的话只需要把voting设置为 soft 即可,看一下软投票的结果
软投票结果:
knn1 0.876 (0.033)
knn3 0.886 (0.026)
knn5 0.892 (0.033)
knn7 0.896 (0.027)
knn9 0.900 (0.025)
soft_voting 0.900 (0.027)