Spring事务管理详解
文章目录
-
- 1.JdbcTemplate
-
- 1.1 概述
- 1.2 环境搭建
-
- 1.2.1 导入 jar 包
- 1.2.2 创建数据库表
- 1.2.3 创建外部配置文件
- 1.2.4 创建 Spring 配置文件
- 1.3 操作数据库
-
- 1.3.1 增删改:update
- 1.3.2 批处理增删改:batchUpdate
- 1.3.3 查询单个数值:queryForObject
- 1.3.4 查询条记录:queryForObject
- 1.3.5 查询多条记录:query
- 2.事务回顾
-
- 2.1 事务概述
-
- 2.1.1 什么是事务
- 2.1.2 事务的四个特性(ACDI)
- 2.1.3 MySQL 如何保证原子性
- 2.1.4 事务的三大行为
- 3.Spring 事务管理的两种方式
-
- 3.1 使用 Spring 事务前的准备
-
- 3.1.1 导入相关 jar 包
- 3.1.2 开启事务管理器
- 3.1.3 开启事务注解支持
- 3.2 编程式事务管理
-
- 3.2.1 基于底层 API 的编程式事务管理
- 3.2.2 基于 TransactionTemplate 的编程式事务管理
- 3.3 声明式事务管理
-
- 3.3.1 基于注解的声明式事务管理
- 3.3.2 基于XML的事务管理
- 3.4 编程式与声明式如何选择?
-
- 3.4.1 声明式事务的优点
- 3.4.2 声明式事务的粒度问题
- 3.4.3 事务被忽略会产生的问题
- 4.Spring 事务管理接口
-
- 4.1 PlatformTransactionManager:事务管理接口
- 4.2 TransactionDefinition:事务属性
- 4.3 TransactionStatus:事务状态
- 5.事务属性详解
-
- 5.1 事务传播行为
-
- 5.1.1 事务传播属性图解
-
- 5.1.1.1 REQUIRED
- 5.1.1.2 REQUIRES_NEW
- 5.1.2 正确的事务传播行为可能的值
-
- 5.1.2.1 REQUIRED
- 5.1.2.2 REQUIRES_NEW
- 5.1.2.3 NESTED
- 5.1.2.4 MANDATORY
- 5.2 事务隔离级别
-
- 5.2.1 事务并发下出现的数据读取问题
-
- 5.2.1.1 脏读
- 5.2.1.2 不可重复度
- 5.2.1.3 幻读
- 5.2.2 Isolation.DEFAULT
- 5.2.3 Isolation.READ_UNCOMMITTED
- 5.2.4 Isolation.READ_COMMITTED
- 5.2.5 Isolation.REPEATABLE_READ
- 5.2.6 Isolation.SERIALIZABLE
- 5.3 事务超时属性
- 5.4 事务只读属性
- 5.5 事务回滚规则
- 6.@Transactional注解详解
-
- 6.1 @Transactional作用范围
- 6.2 @Transactional常用配置参数
- 6.3 @Transactional事务注解原理
- 6.4 Spring AOP 自调用问题
- 6.5 @Transactional使用注意事项总结
1.JdbcTemplate
1.1 概述
为了使 JDBC 更加易于使用,Spring 在 JDBC API 上定义了一个抽象层,以此建立一个 JDBC 存取框架。
作为 Spring JDBC 框架的核心,JDBC 模版的设计目的是为不同类型的 JDBC 操作提供模版方法。通过此种方式,可以在尽可能保留灵活性的前提下,将数据库存取的工作量降到最低。
可以将 Spring 的 JdbcTemplate 看作是一个小型的轻量级持久化层框架,这与 DBUtils、MyBatis 风格非常接近。
1.2 环境搭建
1.2.1 导入 jar 包
<dependencies>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-contextartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-testartifactId>
<version>${spring.version}version>
<scope>testscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.4version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.2.8version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.28version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-jdbcartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-ormartifactId>
<version>${spring.version}version>
dependency>
dependencies>
1.2.2 创建数据库表
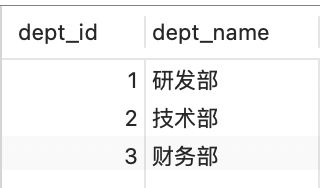
SQL:
CREATE TABLE `tbl_dept` (
`dept_id` int NOT NULL AUTO_INCREMENT,
`dept_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`dept_id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb3;
1.2.3 创建外部配置文件
Jdbc.properties:
jdbc.Driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/数据库名?characterEncoding=UTF-8&useSSL=false&useUnicode=true&serverTimezone=UTC
jdbc.username=root
jdbc.password=123456
1.2.4 创建 Spring 配置文件
applicationContext.xml:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="ink.quokka"/>
<context:property-placeholder location="jdbc.properties"/>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.Driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
bean>
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<property name="dataSource" ref="dataSource"/>
bean>
beans>
1.3 操作数据库
org.springframework.jdbc.core.JdbcTemplate 类提供了庞大的 API 用于操作数据库,下面列举一些常用 API。
- JdbcTemplate:自动提交事务
- MyBatis:默认是手动提交事务
1.3.1 增删改:update
源码如下:
public int update(String sql, @Nullable Object... args) throws DataAccessException {
return this.update(sql, this.newArgPreparedStatementSetter(args));
}
参数说明:
String sql:SQL 语句Object... args:占位符参数
测试代码:
/**
* @author smonk
* @date 2023/1/22 15:07
*/
@ContextConfiguration(locations = "classpath:applicationContext.xml")
@RunWith(SpringJUnit4ClassRunner.class)
public class JdbcTemplateAPITest {
@Autowired
JdbcTemplate jdbcTemplate;
/**
* 增加记录
*/
@Test
public void TestInsert(){
String sql = "insert into tbl_dept(dept_name) values(?)";
jdbcTemplate.update(sql,"市场部");
}
/**
* 删除记录
*/
@Test
public void TestDelete(){
String sql = "delete from tbl_dept where dept_id=?";
jdbcTemplate.update(sql,4);
}
/**
* 修改记录
*/
@Test
public void TestUpdate(){
String sql = "update tbl_dept set dept_name = ? where dept_id = ?";
jdbcTemplate.update(sql,"市场部",1);
}
}
1.3.2 批处理增删改:batchUpdate
源码如下:
public int[] batchUpdate(String sql, List<Object[]> batchArgs) throws DataAccessException {
return this.batchUpdate(sql, batchArgs, new int[0]);
}
参数说明:
String sql:SQL 语句List:每个 List 集合元素代表一个占位符对象
测试代码:
/**
* @author smonk
* @date 2023/1/22 15:07
*/
@ContextConfiguration(locations = "classpath:applicationContext.xml")
@RunWith(SpringJUnit4ClassRunner.class)
public class JdbcTemplateAPITest {
@Autowired
JdbcTemplate jdbcTemplate;
// 批量增加
@Test
public void TestBatchInsert(){
String sql = "insert into tbl_dept(dept_name) values(?)";
List<Object[]> list = new ArrayList<>();
list.add(new Object[]{"人力部"});
list.add(new Object[]{"行政部"});
list.add(new Object[]{"研发部"});
list.add(new Object[]{"运营部"});
jdbcTemplate.batchUpdate(sql,list);
}
// 批量删除
@Test
public void TestBatchDelete(){
String sql = "delete from tbl_dept where dept_id = ?";
List<Object[]> list = new ArrayList<>();
list.add(new Object[]{4});
list.add(new Object[]{5});
list.add(new Object[]{6});
list.add(new Object[]{7});
jdbcTemplate.batchUpdate(sql,list);
}
// 批量修改
@Test
public void TestBatchUpdate(){
String sql = "update tbl_dept set dept_name = ? where dept_id = ?";
List<Object[]> list = new ArrayList<>();
list.add(new Object[]{"XXX",4});
list.add(new Object[]{"XXX",5});
list.add(new Object[]{"XXX",6});
list.add(new Object[]{"XXX",7});
jdbcTemplate.batchUpdate(sql,list);
}
}
1.3.3 查询单个数值:queryForObject
源码如下:
public <T> T queryForObject(String sql, Class<T> requiredType, @Nullable Object... args) throws DataAccessException {
return this.queryForObject(sql, args, this.getSingleColumnRowMapper(requiredType));
}
参数说明:
String sql:SQL 语句Class:期望返回的查询结果类型(class)requiredType Object... args:占位符参数
测试代码:
/**
* 查询单个数值
*/
@Test
public void TestQueryForObjectData(){
String sql = "select count(1) from tbl_dept";
Integer count = jdbcTemplate.queryForObject(sql,Integer.class);
System.out.println(count);
}
1.3.4 查询条记录:queryForObject
源码如下:
@Nullable
public <T> T queryForObject(String sql, RowMapper<T> rowMapper, @Nullable Object... args) throws DataAccessException {
List<T> results = (List)this.query((String)sql, (Object[])args, (ResultSetExtractor)(new RowMapperResultSetExtractor(rowMapper, 1)));
return DataAccessUtils.nullableSingleResult(results);
}
参数说明:
String sql:SQL 语句RowMapper:该对象用于指定查询结果的对象类型rowMapper Object... args:占位符参数
测试代码:
/**
* 查询单条记录
*/
@Test
public void TestQueryForObjectRecord(){
String sql = "select dept_id,dept_name from tbl_dept where dept_id = ?";
// 创建 RowMapper对象
RowMapper<Dept> rowMapper = new BeanPropertyRowMapper<>(Dept.class);
Dept dept = jdbcTemplate.queryForObject(sql, rowMapper, 1);
System.out.println(dept);
}
1.3.5 查询多条记录:query
源码如下:
public <T> List<T> query(String sql, RowMapper<T> rowMapper, @Nullable Object... args) throws DataAccessException {
return (List)result(this.query((String)sql, (Object[])args, (ResultSetExtractor)(new RowMapperResultSetExtractor(rowMapper))));
}
参数说明:
String sql:SQL 语句RowMapper:该对象用于指定查询结果的对象类型rowMapper Object... args:占位符参数
测试代码:
/**
* 查询多条记录
*/
@Test
public void TestQuery(){
String sql = "select dept_id,dept_name from tbl_dept";
// 创建 RowMapper对象
RowMapper<Dept> rowMapper = new BeanPropertyRowMapper<>(Dept.class);
List<Dept> deptList = jdbcTemplate.query(sql, rowMapper);
for (Dept dept : deptList) {
System.out.println(dept);
}
}
2.事务回顾
2.1 事务概述
2.1.1 什么是事务
在 JavaEE 企业级开发的应用领域,为了保证数据的完整性和一致性,必须引入数据库事务的概念,所以事务管理是企业级应用程序开发中必不可少的技术。
事务就是一组由于逻辑上紧密关联而合并成一个整体(工作单元)的多个数据库操作,这些操作要么全部执行,要么都不执行。
程序是否支持事务功能,取决于数据库是否支持事务。如 MySQL 的存储引擎如果是 innodb,则支持事务;如果是 myisam 引擎,则不支持事务。
2.1.2 事务的四个特性(ACDI)
- 原子性(atomicity):一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
相关阅读:并发编程的原子性 != 事务ACID的原子性
结论:
- 并发编程的原子性不等于事务 ACDI 的原子性
- 数据库中的原子性,确实是一个不可拆分的工作单元,要么都执行,要么都不执行。因为事务可以Commit、也可以Rollback。
- 在并发编程中,一个操作是没办法 rollback 的,并且线程在执行过程中也是有可能失败的,失败了是没办法回滚的。所以,**在并发编程中,我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。**这里的原子性是通过加锁的方式来保证的,其实保证的就是一系列操作,不可以被拆分执行,即执行过程中,需要互斥排他,不能有其他线程进行执行。
2.1.3 MySQL 如何保证原子性
如果想要保证事务的原子性,就需要在异常发生时,对已经执行的操作进行回滚。
在 MySQL 中,恢复机制是通过 回滚日志(undo log) 实现的,所有事务进行的修改都会先记录到这个回滚日志中,然后再执行相关的操作。如果执行过程中遇到异常,可直接利用 回滚日志 中的信息将数据回滚到修改之前的样子即可。
并且,回滚日志会先于数据持久化到磁盘上。这样就保证了即使遇到数据库突然宕机等情况,当用户再次启动数据库的时候,数据库还能够通过查询回滚日志来回滚将之前未完成的事务。
2.1.4 事务的三大行为
- 开启事务:
connection.setAutoCommit(false) - 提交事务:
connection.commit() - 回滚事务:
connection.rollback()
3.Spring 事务管理的两种方式
Spring 支持两种方式的事务管理,分别是编程式事务管理与声明式事务管理。下面将分别对两种方式进行简单说明。
事务本是数据库中的概念位于数据访问层(dao层),但一般情况下需要将事务提升到业务层(Service层),这样做是为了能够使用事务的特性来管理具体的业务。
3.1 使用 Spring 事务前的准备
3.1.1 导入相关 jar 包
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-aspectsartifactId>
<version>${spring.version}version>
dependency>
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-ormartifactId>
<version>${spring.version}version>
dependency>
由于 Spring 事务底层实际通过 AOP 进行实现因此至少需要添加 spring-aspects 依赖,同时 Spring 的事务依赖为 spring-tx 但是由于 spring-orm 中同时包含了 spring-jdbc 与 spring-tx 故可以只添加 spring-orm。

3.1.2 开启事务管理器
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
bean>
由于 DataSourceTransactionManager 事务管理器需要装配数据源,故还需要配置数据源(以德鲁伊为例):
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.Driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
bean>
3.1.3 开启事务注解支持
<tx:annotation-driven/>
值得注意的是,该标签有一个 transaction-manager 字符串类型的属性:
- 若事务管理器 beanId 为 transactionManager:则不需要配置此属性以指定事务管理器,因为默认值就是 transactionManager。
- 若事务管理器 beanId 不为 transactionManager:则需要显示指定
transaction-manager的值以配置正确的事务管理器。
3.2 编程式事务管理
编程式事务管理就是使用传统方式,即需要在程序中显示调用 Spring 提供的事务管理 API 来开启事务、提交、回滚方法的形式管理事务。
我们可以通过 TransactionTemplate 或者 TransactionManager 手动管理事务,实际应用中很少使用,但是对于理解 Spring 事务管理原理有帮助。
3.2.1 基于底层 API 的编程式事务管理
根据 PlatformTransactionManager、TransactionDefinition 和 TransactionStatus 三个核心接口,我们完全可以通过编程的方式来进行事务管理。
示例代码:
public class xxxServiceImpl {
@Autowired
private PlatformTransactionManager platformTransactionManager;
public void testTransaction(){
// 获取事务状态对象
TransactionStatus transactionStatus = platformTransactionManager.getTransaction(new DefaultTransactionDefinition());
try{
// ......业务代码
// 提交事务
platformTransactionManager.commit(transactionStatus);
}catch (Exception e){
// 事务回滚
platformTransactionManager.rollback(transactionStatus);
}
}
}
3.2.2 基于 TransactionTemplate 的编程式事务管理
通过前面的示例可以发现,这种事务管理方式很容易理解,但令人头疼的是,事务管理的代码散落在业务逻辑代码中,破坏了原有代码的条理性,并且每一个业务方法都包含了类似的启动事务、提交、回滚事务的样板代码。
幸好 Spring 也意识到了这些,并提供了简化的方法,这就是 Spring 在数据访问层非常常见的模板回调模式。
使用 TransactionTemplate 进行编程式事务管理的示例代码如下:
public class xxxServiceImpl02 {
@Autowired
TransactionTemplate transactionTemplate;
public void testTransaction(){
transactionTemplate.execute(new TransactionCallback<Object>() {
@Override
public Object doInTransaction(TransactionStatus status) {
Object result = null;
try {
// ......业务代码
}catch (Exception e){
// 事务回滚
status.setRollbackOnly();
}
return result;
}
});
}
}
TransactionTemplate 类的 execute() 方法有一个 TransactionCallback 接口类型的参数,该接口中定义了一个 doInTransaction() 方法。通常我们以匿名内部类的方式实现 TransactionCallback 接口,并在其 doInTransaction() 方法中书写业务逻辑代码。
当然,也可以使用 Lambda 表达式进行简化:
public class xxxServiceImpl02 {
@Autowired
TransactionTemplate transactionTemplate;
public void testTransaction(){
transactionTemplate.execute(status -> {
Object result = null;
try {
// ......业务代码
}catch (Exception e){
// 事务回滚
status.setRollbackOnly();
}
return result;
});
}
}
通过这种方式可以使用默认的事务提交和回滚规则,这样在业务代码中就不需要显式调用任何事务管理的 API。doInTransaction() 方法有一个 TransactionStatus 类型的参数,我们可以在方法的任何位置调用该参数的 setRollbackOnly() 方法将事务标识为回滚的,以执行事务回滚。
根据默认规则,如果在执行回调方法的过程中抛出了未检查异常,或者显式调用了
TransacationStatus.setRollbackOnly()方法,则回滚事务;如果事务执行完成或者抛出了 checked 类型的异常,则提交事务。
另外 TransactionCallback 接口有一个实现类 TransactionCallbackWithoutResult,该类中定义了一个 doInTransactionWithoutResult() 方法,TransactionCallbackWithoutResult 接口主要用于事务过程中不需要返回值的情况。当然,对于不需要返回值的情况,我们仍然可以使用 TransactionCallback 接口,并在方法中返回任意值即可。
示例代码如下:
public class xxxServiceImpl02 {
@Autowired
TransactionTemplate transactionTemplate;
public void testTransaction() {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus status) {
try {
// ......业务代码
} catch (Exception e) {
// 事务回滚
status.setRollbackOnly();
}
}
});
}
}
3.3 声明式事务管理
Spring 官方推荐使用声明式事务管理,因为此种形式对应用程序代码的影响最小,因此最符合非侵入式轻量级容器的理想。其底层实际是通过 AOP 实现,并且基于 @Transactional 的全注解方式使用最多。
3.3.1 基于注解的声明式事务管理
开启事务注解支持:
<tx:annotation-driven/>
使用 @Transactional 注解进行事务管理的示例代码如下:
@Transactional(propagation = Propagation.REQUIRED)
public void xxxServicesImpl {
//do something
}
3.3.2 基于XML的事务管理
使用 XML 配置事务代理的方式的不足是,每个目标类都需要配置事务代理。当目标类较多,配置文件会变得非常臃肿。并且此种方式也仅在老项目中使用,因此了解即可。
使用 XML 配置方式可以自动为每个符合切入点表达式的类生成事务代理。由于底层使用 Spring AOP 实现,因此我们需要添加对应的 AspectJ 依赖:
<dependency>
<groupId>org.springframeworkgroupId>
<artifactId>spring-aspectsartifactId>
<version>5.3.23version>
dependency>
然后编写 Spring 配置文件即可:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<context:component-scan base-package="ink.quokka"/>
<aop:aspectj-autoproxy/>
<context:property-placeholder location="classpath:db.properties" ignore-unresolvable="true"/>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
bean>
<tx:advice id="transactionInterceptor" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="xxxMethod" propagation="REQUIRED" isolation="DEFAULT" read-only="false"
rollback-for="...MyException"/>
tx:attributes>
tx:advice>
<aop:config>
<aop:pointcut id="servicePt" expression="execution(* *..service..*.*(..))"/>
<aop:advisor advice-ref="transactionInterceptor" pointcut-ref="servicePt"/>
aop:config>
beans>
3.4 编程式与声明式如何选择?
先说结论:推荐优先使用编程式事务而不是声明式事务管理。
3.4.1 声明式事务的优点
声明式事务帮助我们节省了很多代码,他会自动帮我们进行事务的开启、提交以及回滚等操作,把程序员从事务管理中解放出来。
声明式事务管理使用了 AOP 实现,本质就是在目标方法执行前后进行拦截。 在目标方法执行前加入或创建一个事务,在执行方法执行后,根据实际情况选择提交或回滚事务。使用这种方式,对代码没有侵入性,方法内只需要写业务逻辑就可以了。
但是,声明式事务也并非完美!
3.4.2 声明式事务的粒度问题
首先,声明式事务有一个局限,那就是他的最小粒度要作用在方法上。 也就是说,如果想要给一部分代码块增加事务的话,那就需要把这个部分代码块单独独立出来作为一个方法。但是,正是因为这个粒度问题,所以并不建议过度的使用声明式事务。
因为声明式事务是通过注解的,有些时候还可以通过配置实现,这就会导致一个问题,那就是这个事务有可能被开发者忽略。
3.4.3 事务被忽略会产生的问题
如果开发者没有注意到一个方法是被事务嵌套的,那么就可能会在方法中加入一些如 RPC 远程调用、消息发送、缓存更新、文件写入等操作。 这些操作如果被包在事务中,有两个问题:
- 这些操作自身是无法回滚的,这就会导致数据的不一致。可能 RPC 调用成功了,但是本地事务回滚了,可是 PRC 调用无法回滚了。
- 在事务中有远程调用,就会拉长整个事务。那么久会导致本事务的数据库连接一直被占用,那么如果类似操作过多,就会导致数据库连接池耗尽。
有些时候,即使没有在事务中进行远程操作,但是有些人还是可能会不经意的进行一些内存操作,如运算。或者如果遇到分库分表的情况,有可能不经意间进行跨库操作。
但是如果是编程式事务,业务代码中就会清清楚楚看到什么地方开启事务,什么地方提交,什么时候回滚。这样有人修改这段代码的时候,就会强制他考虑要加的代码是否应该在方法事务内。
除了事务的粒度问题,还有一个问题那就是声明式事务虽然看上去帮我们简化了很多代码,但是一旦没用对,也很容易导致事务失效。
如以下几种场景就可能导致声明式事务失效:
- @Transactional 应用在非 public 修饰的方法上
- @Transactional 注解属性 propagation 设置错误
- @Transactional 注解属性 rollbackFor 设置错误
- 同一个类中方法调用,导致 @Transactional 失效
- 异常被 catch 捕获导致 @Transactional 失效
- 数据库引擎不支持事务
以上几个问题,如果使用编程式事务,则很多都是可以避免的。当然,并不要求一定要彻底不使用声明式事务,只是建议在使用事务的时候,能够更具实际情况自行选择。
原文链接:Spring官方都推荐使用的@Transactional事务,为啥我不建议使用!
4.Spring 事务管理接口
Spring 框架中,事务管理相关最重要的 3 个接口如下:
PlatformTransactionManager: (平台)事务管理器,Spring 事务策略的核心。TransactionDefinition: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)。TransactionStatus: 事务运行状态。
我们可以把 PlatformTransactionManager 接口看作事务上层的管理者,而 TransactionDefinition 和 TransactionStatus 两个接口看作事务的描述。PlatformTransactionManager 会根据 TransactionDefinition 的定义,如事务超时时间、隔离级别、传播行为等来进行事务管理 。而 TransactionStatus 接口则提供了一些方法来获取事务相应的状态比如是否新事务、是否可以回滚等等。
4.1 PlatformTransactionManager:事务管理接口
Spring 并不是直接管理事务,而是提供了多种事务管理器,Spring 事务管理器的接口是 PlatformTransactionManager。其主要用于完成事务的提交、回滚,及获取事务的状态信息。
该接口有两个常用实现类:
DataSourceTransactionManager:使用 JDBC 或 MyBatis 进行数据库操作时使用。HibernateTransactionManager:使用 Hibernate 进行持久化数据时使用。
通过此接口,Spring 便能为各个平台如:JDBC(
DataSourceTransactionManager)、Hibernate(HibernateTransactionManager)、JPA(JpaTransactionManager)等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
接口中共定义了三个方法:
public interface PlatformTransactionManager extends TransactionManager {
// 获取事务
TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException;
// 提交事务
void commit(TransactionStatus status) throws TransactionException;
// 回滚事务
void rollback(TransactionStatus status) throws TransactionException;
}
抽象出 PlatformTransactionManager 接口是为了将事务管理行为抽象出来,然后不同的平台去实现它,这样我们可以保证提供给外部的行为不变,方便我们扩展。
为什么要使用接口?
我们可以把接口理解为提供了一系列功能列表的约定,接口本身不提供功能,它只定义行为。但是谁要用,就要先实现我,遵守我的约定,然后再自己去实现我定义的要实现的功能。
4.2 TransactionDefinition:事务属性
事务管理器接口 PlatformTransactionManager 通过 TransactionStatus getTransaction(@Nullable TransactionDefinition definition) 方法来得到一个事务,这个方法里面的参数是 TransactionDefinition 类 ,这个类就定义了一些基本的事务属性。
所谓事务属性即事务的一些基本配置,描述了事务策略如何应用到方法上。事务属性一共包含如下五个方面:
- 事务隔离级别
- 事务传播行为
- 事务回滚规则
- 事务是否只读
- 事务超时
TransactionDefinition 接口中定义了 5 个方法以及一些表示事务属性的常量比如隔离级别、传播行为等等。
public interface TransactionDefinition {
// 事务传播行为 7 个常量
int PROPAGATION_REQUIRED = 0;
int PROPAGATION_SUPPORTS = 1;
int PROPAGATION_MANDATORY = 2;
int PROPAGATION_REQUIRES_NEW = 3;
int PROPAGATION_NOT_SUPPORTED = 4;
int PROPAGATION_NEVER = 5;
int PROPAGATION_NESTED = 6;
// 事务隔离级别 5 个常量
int ISOLATION_DEFAULT = -1;
int ISOLATION_READ_UNCOMMITTED = 1;
int ISOLATION_READ_COMMITTED = 2;
int ISOLATION_REPEATABLE_READ = 4;
int ISOLATION_SERIALIZABLE = 8;
// 事务超时 1 个常量
int TIMEOUT_DEFAULT = -1;
// 返回事务的传播行为,默认值为 REQUIRED
default int getPropagationBehavior() {
return 0;
}
// 返回事务的隔离级别,默认值为 DEFAULT
default int getIsolationLevel() {
return -1;
}
// 返回事务的超时时间,默认值为 -1,如果超过该时间限制但事务还没有完成,则自动回滚事务。
default int getTimeout() {
return -1;
}
// 返回是否为只读事务,默认值为 false
default boolean isReadOnly() {
return false;
}
@Nullable
default String getName() {
return null;
}
static TransactionDefinition withDefaults() {
return StaticTransactionDefinition.INSTANCE;
}
}
4.3 TransactionStatus:事务状态
TransactionStatus 接口用来记录事务的状态,该接口定义了一组方法用来获取或判断事务的相应状态信息。
PlatformTransactionManager.getTransaction(…)方法返回的就是一个 TransactionStatus 对象。通过该对象来获取相应的事务状态。
TransactionStatus 接口源码:
public interface TransactionStatus extends TransactionExecution, SavepointManager, Flushable{
// 是否有恢复点
boolean hasSavepoint();
// 刷新事务
void flush();
}
5.事务属性详解
实际业务开发中,一般都是使用
@Transactional注解来开启事务,但很多人并不清楚这个注解里面的参数是什么意思,有什么用。下面将进行一一讲解。
5.1 事务传播行为
事务传播行为是为了解决业务层方法之间互相调用的事务问题。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。如方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。事务的具体传播行为可以在 @Transaction 注解的 propagation 属性中进行定义,其属性值由 Propagation 枚举类提供。
在 TransactionDefinition 定义中包括了如下 7 个表示传播行为的常量:
public interface TransactionDefinition {
int PROPAGATION_REQUIRED = 0;
int PROPAGATION_SUPPORTS = 1;
int PROPAGATION_MANDATORY = 2;
int PROPAGATION_REQUIRES_NEW = 3;
int PROPAGATION_NOT_SUPPORTED = 4;
int PROPAGATION_NEVER = 5;
int PROPAGATION_NESTED = 6;
...
}
为了方便使用,Spring 相应地定义了一个枚举类 Propagation 来使用这些常量:
public enum Propagation {
REQUIRED(0),
SUPPORTS(1),
MANDATORY(2),
REQUIRES_NEW(3),
NOT_SUPPORTED(4),
NEVER(5),
NESTED(6);
private final int value;
private Propagation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
Spring 支持7种传播行为:
| 传播属性 | 描述 |
|---|---|
| REQUIRED | 【默认值】如果有事务在运行,当前的方法就在这个事务内运行;否则就启动一个新的事务,并在自己的事务内运行。 |
| REQUIRES_NEW | 当前的方法必须启动一个新事务,并在自己的事务内运行;如果有事务正在运行,应该将它挂起。 |
| SUPPORTS | 如果有事务正在运行,当前的方法就在这个事务内运行;否则,可以不运行在事务中。 |
| NOT_SUPPORTED | 当前的方法不应该运行在事务中,如果有运行的事务则将它挂起。 |
| MANDATORY | 当前的方法必须运行在事务中,如果没有正在运行的事务就抛出异常。 |
| NEVER | 当前的方法不应该运行在事务中,如果有正在运行的事务就抛出异常。 |
| NESTED | 如果有事务正在运行,当前的方法就应该在这个事务的嵌套事务内运行;否则就启动一个新的事务,并在它自己的事务内运行。 |
5.1.1 事务传播属性图解
我们在 B 类的 method02() 方法中调用了 A 类的 method01() 方法,这个时候就涉及到业务层方法之间互相调用的事务问题。如果 method02() 如果发生异常需要回滚,如何配置事务传播行为才能让 method01() 也跟着回滚呢?这个时候就需要事务传播行为的知识了。
@Service
Class A {
@Transactional(propagation = Propagation.xxx)
public void method01 {
//do something
}
}
@Service
Class B {
@Autowired
A a;
@Transactional(propagation = Propagation.xxx)
public void method02 {
a.method01();
//do something
a.method01();
}
}
5.1.1.1 REQUIRED
图解:⬇️

当 method02() 开始运行时启动了事务 Tx1 ,方法体中调用了两次 method02() ,由于已经有 method02() 方法的事务 Tx1 正在运行,故 method01() 方法直接在 Tx1 事务内运行。
当出现异常时,此种方式会进行正在执行事务 Tx1 的全部方法的回滚。
5.1.1.2 REQUIRES_NEW
图解:⬇️
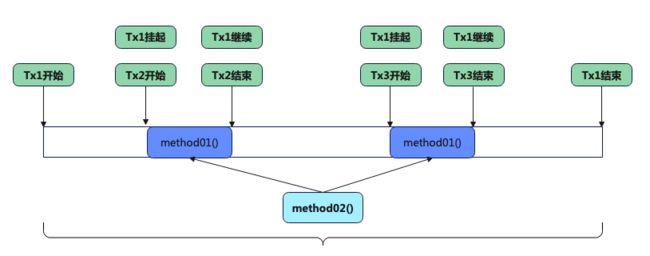
当 method02() 开始运行时启动了事务 Tx1 ,在方法执行过程中第一次调用了 method()01,则将事务 Tx1 挂起,为 method()01 开启一个新事务 Tx2,然后 method()01 在 Tx2 内运行,Tx2 结束继续运行 Tx1 。在方法执行过程中又第二次调用了 method()01,则将事务 Tx1 挂起,为 method()01 开启一个新事务 Tx3,然后 method()01 在 Tx3 内运行,Tx3 结束继续运行 Tx1,直至 Tx1 结束。
当出现异常时,只会回滚对应事务内执行的操作。
5.1.2 正确的事务传播行为可能的值
5.1.2.1 REQUIRED
Propagation.REQUIRED 是使用的最多的一个事务传播行为,我们平时经常使用的 @Transactional 注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。也就是说:
- 如果外部方法没有开启事务的话,
Propagation.REQUIRED修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。 - 如果外部方法开启事务并且被
Propagation.REQUIRED的话,所有Propagation.REQUIRED修饰的内部方法和外部方法均属于同一事务 ,只要一个方法回滚,整个事务均回滚。
5.1.2.2 REQUIRES_NEW
Propagation.REQUIRES_NEW 总是会创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW 修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
5.1.2.3 NESTED
Propagation.NESTED 如果当前存在事务,就在嵌套事务内执行;如果当前没有事务,就执行与 Propagation.REQUIRED 类似的操作。也就是说:
- 在外部方法开启事务的情况下,在内部开启一个新的事务,作为嵌套事务存在。
- 如果外部方法无事务,则单独开启一个事务,与
PROPAGATION_REQUIRED类似。
5.1.2.4 MANDATORY
Propagation.MANDATORY (mandatory:强制性)如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。 (使用较少,了解即可)
若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚:
Propagation.SUPPORTS:如果当前存在事务,则加入该事务;如果当前没>有事务,则以非事务的方式继续运行。Propagation.NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,>则把当前事务挂起。Propagation.NEVER:以非事务方式运行,如果当前存在事务,则抛出异>>常。
5.2 事务隔离级别
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
public interface TransactionDefinition {
......
int ISOLATION_DEFAULT = -1;
int ISOLATION_READ_UNCOMMITTED = 1;
int ISOLATION_READ_COMMITTED = 2;
int ISOLATION_REPEATABLE_READ = 4;
int ISOLATION_SERIALIZABLE = 8;
......
}
和事务传播行为那块一样,为了方便使用,Spring 也相应地定义了一个枚举类:Isolation
public enum Isolation {
DEFAULT(-1), // 默认使用后端数据库默认的隔离级别
READ_UNCOMMITTED(1), // 读未提交
READ_COMMITTED(2), // 读已提交
REPEATABLE_READ(4), // 可重复读
SERIALIZABLE(8); // 串行化
private final int value;
private Isolation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
5.2.1 事务并发下出现的数据读取问题
5.2.1.1 脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据,但未提交的事务被回滚后便会读取到脏数据。(MySQL 不支持脏读)
5.2.1.2 不可重复度
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
不可重复读和脏读的区别是:脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如同一个事物前后两次查询同一个数据,期望两次读的内容是一样的,但是因为读的过程中,因为令一个程序写了该数据,导致不可重复读。
5.2.1.3 幻读
幻读(虚读)是事务非独立执行时发生的一种现象。幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据,而幻读针对的是一批数据整体(比如数据的个数)。
例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。 同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
5.2.2 Isolation.DEFAULT
- 级别:-1【默认】
- 描述:使用后端数据库默认的隔离级别。
- MySQL 默认采用
REPEATABLE_READ隔离级别 - Oracle 默认采用
READ_COMMITTED隔离级别
- MySQL 默认采用
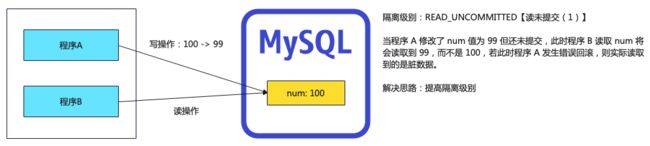
5.2.3 Isolation.READ_UNCOMMITTED
- 级别:1【读未提交】
- 描述:最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更。
- 不足:可能会引起脏读、幻读、不可重复读
- 图解:
5.2.4 Isolation.READ_COMMITTED
- 级别:2【读已提交】
- 级别:2【读已提交】
- 描述:允许读取并发事务已经提交的数据。
- 不足:可以阻止脏读,但是可能会导致幻读或不可重复读。
- 图解:

5.2.5 Isolation.REPEATABLE_READ
- 级别:4【可重复读】
- 描述:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改。
- 不足:可以阻止脏读和不可重复读,但幻读仍有可能发生。
5.2.6 Isolation.SERIALIZABLE
- 级别:8
- 描述:最高的隔离级别,完全服从 ACID(原子性、一致性、隔离性、持久性) 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰。
- 不足:该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能,通常情况下也不会用到该级别。
相关文章:深入分析事务的隔离级别
5.3 事务超时属性
所谓事务超时,就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。在 TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒,默认值为 -1,这表示事务的超时时间取决于底层事务系统或者没有超时时间。
事务的超时时限起作用的条件比较多,且超时的时间计算点较复杂。所以,该值一般就使用默认值即可。
5.4 事务只读属性
public interface TransactionDefinition {
......
// 返回是否为只读事务,默认值为 false
boolean isReadOnly();
}
对于只有读取数据查询的事务,可以指定事务类型为 readonly,即只读事务。只读事务不涉及数据的修改,数据库会提供一些优化手段,适合用在有多条数据库查询操作的方法中。
- 如果一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持 SQL 执行期间的读一致性;
- 如果一次执行多条查询语句,例如统计查询,报表查询。在这种场景下,多条查询 SQL 必须保证整体的读一致性,否则,在前条 SQL 查询之后,后条 SQL 查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态,此时,应该启用事务支持。
MySQL 默认对每一个新建立的连接都启用了
autocommit模式。在该模式下,每一个发送到 MySQL 服务器的sql语句都会在一个单独的事务中进行处理,执行结束后会自动提交事务,并开启一个新的事务。但是,如果你给方法加上了
Transactional注解,这个方法执行的所有sql> 会被放在一个事务中。如果声明了只读事务的话,数据库就会去优化它的执行,并不会带来其他的什么收益。如果不加
Transactional注解,每条sql会开启一个单独的事务,中间被其它事务改了数据,都会实时读取到最新值。
5.5 事务回滚规则
事务回滚规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行时异常(RuntimeException 的子类)时才会回滚,Error 也会导致事务回滚,但是,在遇到检查型(Checked)异常时不会回滚。
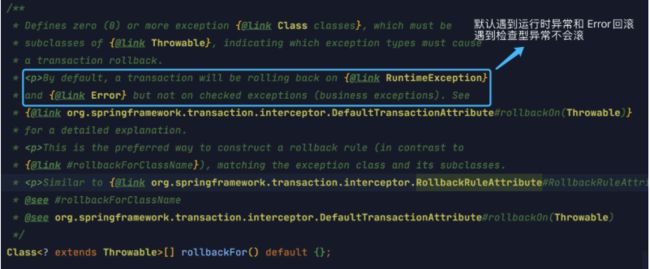
如果想要回滚自定义的特定的异常类型或者受检异常,可以在 Transactional 注解中使用 rollbackFor 属性显示指定需要进行回滚的异常类型:
@Transactional(rollbackFor = MyException.class)
下面简单回顾一下异常:
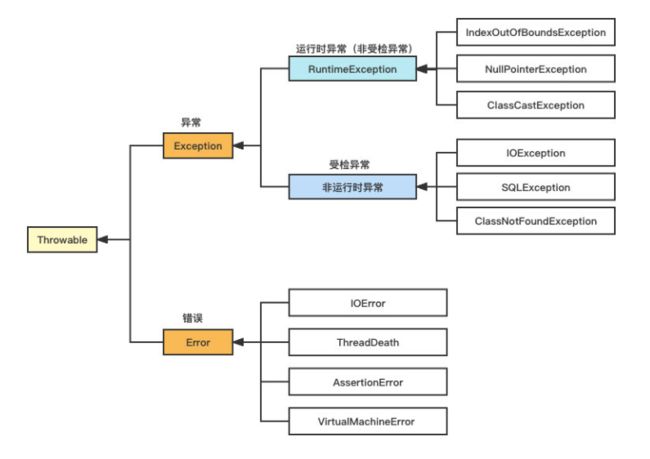
-
Throwable:Java 语言中所有错误或异常的超类,只有当对象是此类或其子类之一的实例时,才能通过 JVM 虚拟机或者 Java 的 throw 语句抛出。 -
Exception:会在程序编译和运行时出现,用于通知程序员已经或可能出现的错误,并要求对其进行处理。- 运行时异常:是
RuntimeException类或其子类,即只有在运行时才出现的异常。这些异常由 JVM 抛出,在编译时不要求必须处理(捕获或抛出),但只要代码编写足够仔细,程序足够健壮,运行时异常是可以避免的。 - 受检异常:也叫编译时异常,即在代码编写时要求必须捕获或抛出的异常,若不处理则无法通过编译。
- 运行时异常:是
-
Error:指程序在运行过程中出现的无法处理的错误。当这些错误发生时,程序无法处理(捕获或抛出),因此 JVM 一般会终止线程。
6.@Transactional注解详解
6.1 @Transactional作用范围
@Transactional 部分源码:
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {}
从 @Target 可以看到 @Transactional 注解可以作用在如下三个位置:
- 方法:【推荐】该注解只能应用到 public 方法上,对于其他非 public 方法,如果加上了注解
@Transactional,虽然 Spring 不会报错,但不会将指定事务织入到该方法中。因为 Spring 会忽略掉所有非 public 方法上的@Transaction注解。 - 类:则表示该类上所有的 public 方法均将在执行时织入事务。
- 接口:不推荐在接口上使用。
6.2 @Transactional常用配置参数
@Transactional 注解源码如下,里面包含了基本事务属性的配置:
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {
@AliasFor("transactionManager")
String value() default "";
@AliasFor("value")
String transactionManager() default "";
String[] label() default {};
// 事务传播行为,默认值 Propagation.REQUIRED
Propagation propagation() default Propagation.REQUIRED;
// 事务隔离级别,默认值 Isolation.DEFAULT
Isolation isolation() default Isolation.DEFAULT;
// 事务超时属性,默认值 -1
int timeout() default -1;
String timeoutString() default "";
// 用于设置该方法对数据库的操作是否是只读的,默认值 false
boolean readOnly() default false;
// 事务回滚规则,默认 RuntimeException(运行时异常)、Error(错误)
Class<? extends Throwable>[] rollbackFor() default {};
// 指定需要回滚的异常类类名。类型为 String[],默认值为空数组。若只有一个异常类时,可以不使用数组。
String[] rollbackForClassName() default {};
// 指定不需要回滚的异常类。类型为 Class[],默认值为空数组。若只有一个异常类时,可以不使用数组。
Class<? extends Throwable>[] noRollbackFor() default {};
// 指定不需要回滚的异常类类名。类型为 String[],默认值为空数组。若只有一个异常类时,可以不使用数组。
String[] noRollbackForClassName() default {};
}
其中有 5 个比较常用的参数:
| 属性名 | 说明 |
|---|---|
| propagation | 事务的传播行为,默认值为 REQUIRED。 |
| isolation | 事务的隔离级别,默认值采用 DEFAULT。 |
| timeout | 事务的超时时间,默认值为-1(不会超时)。如果超过该时间限制但事务还没有完成,则自动回滚事务。 |
| readOnly | 指定事务是否为只读事务,默认值为 false。 |
| rollbackFor | 指定需要回滚的异常类。类型为 Class[],默认值为空数组。若只有一个异常类时,可以不使用数组。 |
6.3 @Transactional事务注解原理
@Transactional 的工作机制是基于 AOP 实现的,AOP 又是使用动态代理实现的。如果目标对象实现了接口,默认情况下会采用 JDK 的动态代理,如果目标对象没有实现了接口,则会使用 CGLIB 动态代理。
源码中提供有一个 createAopProxy() 方法决定了是使用 JDK 还是 Cglib 来做动态代理,源码如下:
public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {
@Override
public AopProxy createAopProxy(AdvisedSupport config) throws AopConfigException {
if (config.isOptimize() || config.isProxyTargetClass() || hasNoUserSuppliedProxyInterfaces(config)) {
Class<?> targetClass = config.getTargetClass();
if (targetClass == null) {
throw new AopConfigException("TargetSource cannot determine target class: " +
"Either an interface or a target is required for proxy creation.");
}
if (targetClass.isInterface() || Proxy.isProxyClass(targetClass)) {
return new JdkDynamicAopProxy(config);
}
return new ObjenesisCglibAopProxy(config);
}
else {
return new JdkDynamicAopProxy(config);
}
}
.......
}
如果一个类或者一个类中的 public 方法上被标注 @Transactional 注解,Spring 容器就会在启动的时候为其创建一个代理类,在调用被 @Transactional 注解的 public 方法的时候,实际调用的是 TransactionInterceptor 类中的 invoke() 方法。这个方法的作用就是在目标方法之前开启事务,方法执行过程中如果遇到异常的时候回滚事务,方法调用完成之后提交事务。
6.4 Spring AOP 自调用问题
若同一类中的其他没有 @Transactional 注解的方法内部调用有 @Transactional 注解的方法,那么有 @Transactional 注解的方法的事务会失效。这是由于 Spring AOP 代理的原因造成的,因为只有当 @Transactional 注解的方法在类以外被调用的时候,Spring 事务管理才生效。
如下 MyService 类中的 method1()调用 method2()就会导致 method2()的事务失效:
@Service
public class MyService {
private void method1() {
method2();
//......
}
@Transactional
public void method2() {
//......
}
}
解决办法就是避免同一类中自调用或者使用 AspectJ 取代 Spring AOP 代理。
6.5 @Transactional使用注意事项总结
@Transactional注解只有作用到 public 方法上事务才生效,不推荐在接口上使用;- 避免同一个类中调用
@Transactional注解的方法,这样会导致事务失效; - 正确的设置
@Transactional的rollbackFor和propagation属性,否则事务可能会回滚失败; - 被
@Transactional注解的方法所在的类必须被 Spring 管理,否则不生效; - 底层使用的数据库必须支持事务机制,否则不生效;
参考文章:
- https://javaguide.cn/system-design/framework/spring/spring-transaction.html
- https://docs.spring.io/spring/docs/4.2.x/spring-framework-reference/html/transaction.html
- https://www.ibm.com/developerworks/cn/java/j-master-spring-transactional-use/index.html
- http://www.mobabel.net/spring 事务管理中 transactional 的参数/
- https://segmentfault.com/a/1190000013341344
- https://www.ibm.com/developerworks/cn/education/opensource/os-cn-spring-trans/index.html
- https://www.cnblogs.com/Vieat/p/11176231.html#:~:text=幻读和不可重复读,如数据的个数)%E3%80%82
- https://www.cnblogs.com/aliger/p/3898869.html
- https://www.hollischuang.com/archives/5608