Linux中python、C++和C语言的多线程用法整理(_thread、threading、thread和pthread)
目录
- python3
-
- 开始学习Python线程
-
- _thread
-
- 常量和函数:
- 锁对象
- 试用基本功能
- 试用线程同步
- threading
-
- 函数
- 常量
- 类
-
- 线程本地数据
- 线程对象
- 锁对象
- 递归锁对象
- 条件对象
- 信号量对象
- Semaphore 例子
- 事件对象
- 定时器对象
- 栅栏对象
- 在 with 语句中使用锁、条件和信号量
- 测试
- C++
-
- std::thread
-
- std::thread 构造函数
- std::thread 赋值操作
- 其他成员函数
-
- get_id
- joinable
- join
- detach
- swap
- native_handle
- hardware_concurrency [static]
- std::this_thread 命名空间中相关辅助函数介绍
-
- get_id
- yield
- sleep_until
- sleep_for
- std::mutex
-
- Mutex 系列类(四种)
- Lock 类(两种)
- 其他类型
- 函数
- std::mutex 的成员函数
- std::recursive_mutex 介绍
- std::time_mutex 介绍
- std::recursive_timed_mutex 介绍
- std::lock_guard 介绍
- std::unique_lock 介绍
- std::try_lock
- std::lock
- std::call_once
- 测试
- C语言
-
- 头文件
- 线程
-
- 创建线程
- 取消线程
- 终止线程
- 连接和分离线程
- 互斥锁
- 自旋锁
-
- 自旋锁与互斥量的区别
- 自旋锁初始化
- 自旋锁操作
- 自旋锁销毁
- 读写锁
-
- 初始化读写锁
- 获取读写锁中的读锁
- 读取非阻塞读写锁中的锁
- 写入读写锁中的锁
- 写入非阻塞读写锁中的锁
- 解除锁定读写锁
- 销毁读写锁
- 条件变量
- 测试
平台:华硕 Thinker Edge R 瑞芯微 RK3399Pro
固件版本:Tinker_Edge_R-Debian-Stretch-V1.0.4-20200615
python3
参考资料:Python3 多线程 | 菜鸟教程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
使用线程可以把占据长时间的程序中的任务放到后台去处理。
用户界面可以更加吸引人,比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
程序的运行速度可能加快。
在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
线程可以被抢占(中断)。
在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) – 这就是线程的退让。
线程可以分为:
内核线程:由操作系统内核创建和撤销。
用户线程:不需要内核支持而在用户程序中实现的线程。
Python3 线程中常用的两个模块为:
_thread
threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 “_thread”。
开始学习Python线程
_thread
参考资料:
_thread — 低级线程 API
python _thread模块使用
Python中使用线程有两种方式:函数或者用类来包装线程对象。
_thread模块提供了操作多个线程(也被称为 轻量级进程 或 任务)的底层原语 —— 多个控制线程共享全局数据空间。为了处理同步问题,也提供了简单的锁机制(也称为 互斥锁 或 二进制信号)。threading 模块基于该模块提供了更易用的高级多线程 API。
在 3.7 版更改: 这个模块曾经为可选项,但现在总是可用。
常量和函数:
exception _thread.error
发生线程相关错误时抛出。
在 3.3 版更改: 现在是内建异常
RuntimeError的别名。
_thread.LockType
锁对象的类型。
_thread.start_new_thread(function, args[, kwargs])
开启一个新线程并返回其标识。 线程执行函数
function并附带参数列表args(必须是元组)。 可选的kwargs参数指定一个关键字参数字典。
当函数返回时,线程会静默地退出。
当函数因某个未处理异常而终结时,sys.unraisablehook()会被调用以处理异常。 钩子参数的object属性为function。 在默认情况下,会打印堆栈回溯然后该线程将退出(但其他线程会继续运行)。
当函数引发SystemExit异常时,它会被静默地忽略。
在 3.8 版更改: 现在会使用
sys.unraisablehook()来处理未处理的异常。
函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程。语法如下:
_thread.start_new_thread ( function, args[, kwargs] )
参数说明:
function- 线程函数。
args- 传递给线程函数的参数,他必须是个tuple类型。
kwargs- 可选参数。
_thread.interrupt_main(signum=signal.SIGINT, /)
模拟一个信号到达主线程的效果。 线程可使用此函数来打断主线程,虽然并不保证打断将立即发生。
如果给出signum,则表示要模拟的信号的编号。
如果未给出signum,则将模拟signal.SIGINT。 如果 Python没有处理给定的信号 (它被设为signal.SIG_DFL或signal.SIG_IGN),此函数将不做任何操作。
在 3.10版更改: 添加了
signum参数来定制信号的编号。
注解 这并不会发出对应的信号而是将一个调用排入关联处理句柄的计划任务(如果句柄存在的话)。 如果你想要真的发出信号,请使用
signal.raise_signal()。
_thread.exit()
抛出
SystemExit异常。如果没有捕获的话,这个异常会使线程退出。
_thread.allocate_lock()
返回一个新的锁对象。锁中的方法在后面描述。初始情况下锁处于解锁状态。
_thread.get_ident()
返回当前线程的 “线程标识符”。它是一个非零的整数。它的值没有直接含义,主要是用作
magic cookie,比如作为含有线程相关数据的字典的索引。线程标识符可能会在线程退出,新线程创建时被复用。
_thread.get_native_id()
返回内核分配给当前线程的原生集成线程 ID。 这是一个非负整数。它的值可被用来在整个系统中唯一地标识这个特定线程(直到线程终结,在那之后该值可能会被 OS 回收再利用)。
可用性: Windows, FreeBSD, Linux, macOS, OpenBSD, NetBSD, AIX。
3.8 新版功能.
_thread.stack_size([size])
返回创建线程时使用的堆栈大小。可选参数 size 指定之后新建的线程的堆栈大小,而且一定要是0(根据平台或者默认配置)或者最小是32,768(32KiB)的一个正整数。如果 size 没有指定,默认是0。如果不支持改变线程堆栈大小,会抛出
RuntimeError错误。如果指定的堆栈大小不合法,会抛出ValueError错误并且不会修改堆栈大小。32KiB是当前最小的能保证解释器有足够堆栈空间的堆栈大小。需要注意的是部分平台对于堆栈大小会有特定的限制,例如要求大于32KiB的堆栈大小或者需要根据系统内存页面的整数倍进行分配
- 应当查阅平台文档有关详细信息(4KiB页面比较普遍,在没有更具体信息的情况下,建议的方法是使用4096的倍数作为堆栈大小)。
适用于: Windows,具有 POSIX 线程的系统。
_thread.TIMEOUT_MAX
Lock.acquire()方法中timeout参数允许的最大值。传入超过这个值的timeout会抛出OverflowError异常。
3.2 新版功能.
锁对象
lock.acquire(waitflag=1, timeout=- 1)
没有任何可选参数时,该方法无条件申请获得锁,有必要的话会等待其他线程释放锁(同时只有一个线程能获得锁 —— 这正是锁存在的原因)。
如果传入了整型参数waitflag,具体的行为取决于传入的值:如果是 0 的话,只会在能够立刻获取到锁时才获取,不会等待,如果是非零的话,会像之前提到的一样,无条件获取锁。
如果传入正浮点数参数timeout,相当于指定了返回之前等待得最大秒数。如果传入负的timeout,相当于无限期等待。如果waitflag是 0 的话,不能指定timeout。
如果成功获取到所会返回True,否则返回False。
在 3.2 版更改: 新的
timeout形参。
在 3.2 版更改: 现在获取锁的操作可以被POSIX信号中断。
lock.release()
释放锁。锁必须已经被获取过,但不一定是同一个线程获取的。
lock.locked()
返回锁的状态:如果已被某个线程获取,返回
True,否则返回False。
除了这些方法之外,锁对象也可以通过
with语句使用,例如:
import _thread
a_lock = _thread.allocate_lock()
with a_lock:
print("a_lock is locked while this executes")
注意事项:
线程与中断奇怪地交互:KeyboardInterrupt 异常可能会被任意一个线程捕获。(如果 signal 模块可用的话,中断总是会进入主线程。)
调用 sys.exit() 或是抛出 SystemExit 异常等效于调用 _thread.exit()。
不可能中断锁的 acquire() 方法 —— KeyboardInterrupt 一场会在锁获取到之后发生。
当主线程退出时,由系统决定其他线程是否存活。在大多数系统中,这些线程会直接被杀掉,不会执行 try ... finally 语句,也不会执行对象析构函数。
当主线程退出时,不会进行正常的清理工作(除非使用了 try ... finally 语句),标准 I/O 文件也不会刷新。
试用基本功能
在合适的地方编写测试代码:
nano thread_test.py
#!/usr/bin/python3
import _thread
import time
# 为线程定义一个函数
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 无法启动线程")
time.sleep(25)
exit()

python3 ./thread_test.py

试用线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
示例:
引自线程互斥锁——周瑞英
创建多个线程模拟火车票售票系统;三个线程在有票时进行买票,并打印输出每次剩余的票数。

nano tickets.py
#!/usr/bin/python3
import _thread
import time
M = 3
tickets = 20
locks = []
for _ in range(M): # 每个线程分配一个锁
lock_temp = _thread.allocate_lock()
lock_temp.acquire()
locks.append(lock_temp)
def fun(ID):
global tickets
global locks
while True:
if tickets > 0:
time.sleep((ID + 1)/10)
tickets -= 1
print("(Thread %d)the remaining tickets:%d" %(ID + 1, tickets))
else:
locks[ID].release()
return
for _ in range(M):
_thread.start_new_thread(fun, (_,))
for _ in range(M): # 等待所有线程结束(等待对应的锁解锁)
while(locks[_].locked()):
pass
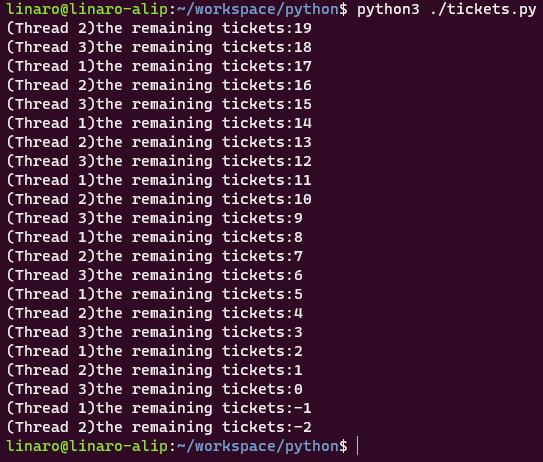
python3 ./tickets.py
如图所示,买票过程中出现了错误的票数:
利用互斥锁修改程序:
#!/usr/bin/python3
import _thread
import time
M = 3
tickets = 20
locks = []
lock = _thread.allocate_lock()
for _ in range(M): # 每个线程分配一个锁
lock_temp = _thread.allocate_lock()
lock_temp.acquire()
locks.append(lock_temp)
def fun(ID):
global tickets
global lock
global locks
while True:
lock.acquire() # 上锁
if tickets > 0:
time.sleep((ID + 1)/10)
tickets -= 1
print("(Thread %d)the remaining tickets:%d" %(ID + 1, tickets))
lock.release() # 解锁
if not tickets > 0:
locks[ID].release()
return
for _ in range(M):
_thread.start_new_thread(fun, (_,))
for _ in range(M): # 等待所有线程结束(等待对应的锁解锁)
while(locks[_].locked()):
pass
如图所示,票数不再出现错误

threading
来源:threading — 基于线程的并行
这个模块在较低级的模块 _thread 基础上建立较高级的线程接口。参见: queue 模块。
在 3.7 版更改: 这个模块曾经为可选项,但现在总是可用。
注解 在 Python 2.x 系列中,此模块包含有某些方法和函数
camelCase形式的名称。 它们在 Python 3.10 中已弃用,但为了与 Python 2.5 及更旧版本的兼容性而仍受到支持。
CPython implementation detail: 在 CPython 中,由于存在 全局解释器锁,同一时刻只有一个线程可以执行 Python 代码(虽然某些性能导向的库可能会去除此限制)。 如果你想让你的应用更好地利用多核心计算机的计算资源,推荐你使用 multiprocessing 或 concurrent.futures.ProcessPoolExecutor。 但是,如果你想要同时运行多个 I/O 密集型任务,则多线程仍然是一个合适的模型。
函数
threading.active_count()
返回当前存活的
Thread对象的数量。 返回值与enumerate()所返回的列表长度一致。函数
activeCount是此函数的已弃用别名。
threading.current_thread()
返回当前对应调用者的控制线程的
Thread对象。如果调用者的控制线程不是利用threading创建,会返回一个功能受限的虚拟线程对象。函数
currentThread是此函数的已弃用别名。
threading.excepthook(args, /)
处理由
Thread.run()引发的未捕获异常。
args参数具有以下属性:
exc_type: 异常类型
exc_value: 异常值,可以是None.
exc_traceback: 异常回溯,可以是None.
thread: 引发异常的线程,可以为None。
如果
exc_type为SystemExit,则异常会被静默地忽略。 在其他情况下,异常将被打印到sys.stderr。
如果此函数引发了异常,则会调用sys.excepthook()来处理它。
threading.excepthook()可以被重载以控制由Thread.run()引发的未捕获异常的处理方式。
使用定制钩子存放exc_value可能会创建引用循环。 它应当在不再需要异常时被显式地清空以打破引用循环。
如果一个对象正在被销毁,那么使用自定义的钩子储存thread可能会将其复活。请在自定义钩子生效后避免储存thread,以避免对象的复活。
参见
sys.excepthook()处理未捕获的异常。
3.8 新版功能.
threading.__excepthook__
保存
threading.excepthook()的原始值。 它被保存以便在原始值碰巧被已损坏或替代对象所替换的情况下可被恢复。
3.10 新版功能.
threading.get_ident()
返回当前线程的 “线程标识符”。它是一个非零的整数。它的值没有直接含义,主要是用作
magic cookie,比如作为含有线程相关数据的字典的索引。线程标识符可能会在线程退出,新线程创建时被复用。
3.3 新版功能.
threading.get_native_id()
返回内核分配给当前线程的原生集成线程 ID。 这是一个非负整数。 它的值可被用来在整个系统中唯一地标识这个特定线程(直到线程终结,在那之后该值可能会被 OS 回收再利用)。
可用性: Windows, FreeBSD, Linux, macOS, OpenBSD, NetBSD, AIX。
3.8 新版功能.
threading.enumerate()
返回当前所有存活的
Thread对象的列表。 该列表包括守护线程以及current_thread()创建的空线程。 它不包括已终结的和尚未开始的线程。 但是,主线程将总是结果的一部分,即使是在已终结的时候。
threading.main_thread()
返回主
Thread对象。一般情况下,主线程是Python解释器开始时创建的线程。
3.4 新版功能.
threading.settrace(func)
为所有
threading模块开始的线程设置追踪函数。在每个线程的run()方法被调用前,func会被传递给sys.settrace()。
threading.gettrace()
返回由
settrace()设置的跟踪函数。
3.10 新版功能.
threading.setprofile(func)
为所有
threading模块开始的线程设置性能测试函数。在每个线程的run()方法被调用前,func会被传递给sys.setprofile()。
threading.getprofile()
返回由
setprofile()设置的性能分析函数。
3.10 新版功能.
threading.stack_size([size])
返回创建线程时使用的堆栈大小。可选参数 size 指定之后新建的线程的堆栈大小,而且一定要是0(根据平台或者默认配置)或者最小是32,768(32KiB)的一个正整数。如果 size 没有指定,默认是0。如果不支持改变线程堆栈大小,会抛出
RuntimeError错误。如果指定的堆栈大小不合法,会抛出ValueError错误并且不会修改堆栈大小。32KiB是当前最小的能保证解释器有足够堆栈空间的堆栈大小。需要注意的是部分平台对于堆栈大小会有特定的限制,例如要求大于32KiB的堆栈大小或者需要根据系统内存页面的整数倍进行分配 - 应当查阅平台文档有关详细信息(4KiB页面比较普遍,在没有更具体信息的情况下,建议的方法是使用4096的倍数作为堆栈大小)。
适用于: Windows,具有 POSIX 线程的系统。
常量
threading.TIMEOUT_MAX
阻塞函数(
Lock.acquire(), RLock.acquire(), Condition.wait(), ...)中形参timeout允许的最大值。传入超过这个值的timeout会抛出OverflowError异常。
3.2 新版功能.
类
该模块的设计基于 Java的线程模型。 但是,在Java里面,锁和条件变量是每个对象的基础特性,而在Python里面,这些被独立成了单独的对象。 Python 的 Thread 类只是 Java 的 Thread 类的一个子集;目前还没有优先级,没有线程组,线程还不能被销毁、停止、暂停、恢复或中断。 Java 的 Thread 类的静态方法在实现时会映射为模块级函数。
下述方法的执行都是原子性的。
线程本地数据
线程本地数据是特定线程的数据。管理线程本地数据,只需要创建一个 local (或者一个子类型)的实例并在实例中储存属性:
mydata = threading.local()
mydata.x = 1
在不同的线程中,实例的值会不同。
class threading.local
一个代表线程本地数据的类。
更多相关细节和大量示例,参见
_threading_local模块的文档。
线程对象
(机翻)Thread类表示一个在独立的控制线程中运行的活动。有两种方法可以指定活动:通过向构造函数传递一个可调用的对象,或者通过在子类中重写run()方法。其他方法(除了构造函数)不应该在子类中被覆盖。换句话说,只覆盖这个类的 __init__() 和 run() 方法。
当线程对象一但被创建,其活动一定会因调用线程的 start() 方法开始。这会在独立的控制线程调用 run() 方法。
一旦线程活动开始,该线程会被认为是 ‘存活的’ 。当它的 run() 方法终结了(不管是正常的还是抛出未被处理的异常),就不是’存活的’。 is_alive() 方法用于检查线程是否存活。
其他线程可以调用一个线程的 join() 方法。这会阻塞调用该方法的线程,直到被调用 join() 方法的线程终结。
线程有名字。名字可以传递给构造函数,也可以通过 name 属性读取或者修改。
如果 run() 方法引发了异常,则会调用 threading.excepthook() 来处理它。 在默认情况下,threading.excepthook() 会静默地忽略 SystemExit。
一个线程可以被标记成一个“守护线程”。 这个标识的意义是,当剩下的线程都是守护线程时,整个 Python 程序将会退出。 初始值继承于创建线程。 这个标识可以通过 daemon 特征属性或者 daemon 构造器参数来设置。
注解 守护线程在程序关闭时会突然关闭。他们的资源(例如已经打开的文档,数据库事务等等)可能没有被正确释放。如果你想你的线程正常停止,设置他们成为非守护模式并且使用合适的信号机制,例如:
Event。
有个 “主线程” 对象;这对应Python程序里面初始的控制线程。它不是一个守护线程。
“虚拟线程对象” 是可以被创建的。这些是对应于“外部线程”的线程对象,它们是在线程模块外部启动的控制线程,例如直接来自C代码。虚拟线程对象功能受限;他们总是被认为是存活的和守护模式,不能被 join() 。因为无法检测外来线程的终结,它们永远不会被删除。
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
调用这个构造函数时,必需带有关键字参数。参数如下:
group应该为None;为了日后扩展ThreadGroup类实现而保留。
target是用于run()方法调用的可调用对象。默认是None,表示不需要调用任何方法。
name是线程名称。 在默认情况下,会以 “Thread-N” 的形式构造唯一名称,其中 N 为一个较小的十进制数值,或是 “Thread-N (target)” 的形式,其中 “target” 为target.__name__,如果指定了target参数的话。
args是用于调用目标函数的参数元组。默认是()。
kwargs是用于调用目标函数的关键字参数字典。默认是{}。如果不是
None,daemon参数将显式地设置该线程是否为守护模式。 如果是None(默认值),线程将继承当前线程的守护模式属性。如果子类型重载了构造函数,它一定要确保在做任何事前,先发起调用基类构造器(
Thread.__init__())。
在 3.10 版更改: 使用
target名称,如果name参数被省略的话。在 3.3 版更改: 加入
daemon参数。
start()
开始线程活动。
它在一个线程里最多只能被调用一次。它安排对象的
run()方法在一个独立的控制进程中调用。如果同一个线程对象中调用这个方法的次数大于一次,会抛出
RuntimeError。
run()
代表线程活动的方法。
你可以在子类型里重载这个方法。 标准的
run()方法会对作为target参数传递给该对象构造器的可调用对象(如果存在)发起调用,并附带从args和kwargs参数分别获取的位置和关键字参数。
join(timeout=None)
等待,直到线程终结。这会阻塞调用这个方法的线程,直到被调用
join()的线程终结 – 不管是正常终结还是抛出未处理异常 – 或者直到发生超时,超时选项是可选的。
当timeout参数存在而且不是None时,它应该是一个用于指定操作超时的以秒为单位的浮点数或者分数。因为join()总是返回None,所以你一定要在join()后调用is_alive()才能判断是否发生超时 – 如果线程仍然存活,则join()超时。
当timeout参数不存在或者是None,这个操作会阻塞直到线程终结。
一个线程可以被join()很多次。
如果尝试加入当前线程会导致死锁,join()会引起RuntimeError异常。如果尝试join()一个尚未开始的线程,也会抛出相同的异常。
name
只用于识别的字符串。它没有语义。多个线程可以赋予相同的名称。 初始名称由构造函数设置。
getName()
setName()
已被弃用的
name的取值/设值 API;请改为直接以特征属性方式使用它。
3.10 版后已移除.
ident
这个线程的 ‘线程标识符’,如果线程尚未开始则为 None 。这是个非零整数。参见 get_ident() 函数。当一个线程退出而另外一个线程被创建,线程标识符会被复用。即使线程退出后,仍可得到标识符。
native_id
此线程的线程 ID (TID),由 OS (内核) 分配。 这是一个非负整数,或者如果线程还未启动则为
None。 请参阅get_native_id()函数。 这个值可被用来在全系统范围内唯一地标识这个特定线程 (直到线程终结,在那之后该值可能会被 OS 回收再利用)。
注解 类似于进程 ID,线程 ID 的有效期(全系统范围内保证唯一)将从线程被创建开始直到线程被终结。
可用性: 需要
get_native_id()函数。
3.8 新版功能.
is_alive()
返回线程是否存活。
当 run() 方法刚开始直到run()方法刚结束,这个方法返回True。模块函数enumerate()返回包含所有存活线程的列表。
daemon
(机翻)一个布尔值,表示该线程是否是守护线程(
True)或不是(False)。这个值必须在start()被调用之前设置,否则会引发RuntimeError。它的初始值继承自创建线程;主线程不是守护线程,因此在主线程中创建的所有线程都默认为daemon = False。
当没有存活的非守护线程时,整个Python程序才会退出。
isDaemon()
setDaemon()
已被弃用的
daemon的取值/设值 API;请改为直接以特征属性方式使用它。
3.10 版后已移除.
锁对象
原始锁是一个在锁定时不属于特定线程的同步基元组件。在Python中,它是能用的最低级的同步基元组件,由 _thread 扩展模块直接实现。
原始锁处于 “锁定” 或者 “非锁定” 两种状态之一。它被创建时为非锁定状态。它有两个基本方法, acquire() 和 release() 。当状态为非锁定时, acquire() 将状态改为 锁定 并立即返回。当状态是锁定时, acquire() 将阻塞至其他线程调用 release() 将其改为非锁定状态,然后 acquire() 调用重置其为锁定状态并返回。 release() 只在锁定状态下调用; 它将状态改为非锁定并立即返回。如果尝试释放一个非锁定的锁,则会引发 RuntimeError 异常。
锁同样支持 上下文管理协议。
当多个线程在 acquire() 等待状态转变为未锁定被阻塞,然后 release() 重置状态为未锁定时,只有一个线程能继续执行;至于哪个等待线程继续执行没有定义,并且会根据实现而不同。
所有方法的执行都是原子性的。
class threading.Lock
实现原始锁对象的类。一旦一个线程获得一个锁,会阻塞随后尝试获得锁的线程,直到它被释放;任何线程都可以释放它。
需要注意的是 Lock 其实是一个工厂函数,返回平台支持的具体锁类中最有效的版本的实例。
acquire(blocking=True, timeout=- 1)
可以阻塞或非阻塞地获得锁。
当调用时参数blocking设置为True(缺省值),阻塞直到锁被释放,然后将锁锁定并返回True。
在参数blocking被设置为False的情况下调用,将不会发生阻塞。如果调用时blocking设为True会阻塞,并立即返回False;否则,将锁锁定并返回True。
(机翻)当调用浮点timeout参数设置为正值时,最多阻断由timeout指定的秒数,只要锁不能被获取就可以。如果timeout参数为-1,则指定一个无限制的等待。严禁在blocking为假时指定timeout。
如果成功获得锁,则返回True,否则返回False(例如发生 超时 的时候)。
在 3.2 版更改: 新的
timeout形参。
在 3.2 版更改: 现在如果底层线程实现支持,则可以通过POSIX上的信号中断锁的获取。
release()
释放一个锁。这个方法可以在任何线程中调用,不单指获得锁的线程。
当锁被锁定,将它重置为未锁定,并返回。如果其他线程正在等待这个锁解锁而被阻塞,只允许其中一个允许。
当在未锁定的锁上发起调用时,会引发RuntimeError。
没有返回值。
locked()
如果获得了锁,返回
True。
递归锁对象
重入锁是一个可以被同一个线程多次获取的同步基元组件。在内部,它在基元锁的锁定/非锁定状态上附加了 “所属线程” 和 “递归等级” 的概念。在锁定状态下,某些线程拥有锁 ; 在非锁定状态下, 没有线程拥有它。
若要锁定锁,线程调用其 acquire() 方法;一旦线程拥有了锁,方法将返回。若要解锁,线程调用 release() 方法。 acquire()/release() 对可以嵌套;只有最终 release() (最外面一对的 release() ) 将锁解开,才能让其他线程继续处理 acquire() 阻塞。
递归锁也支持 上下文管理协议。
class threading.RLock
此类实现了重入锁对象。重入锁必须由获取它的线程释放。一旦线程获得了重入锁,同一个线程再次获取它将不阻塞;线程必须在每次获取它时释放一次。
需要注意的是RLock其实是一个工厂函数,返回平台支持的具体递归锁类中最有效的版本的实例。
acquire(blocking=True, timeout=- 1)
可以阻塞或非阻塞地获得锁。
当无参数调用时: 如果这个线程已经拥有锁,递归级别增加一,并立即返回。否则,如果其他线程拥有该锁,则阻塞至该锁解锁。一旦锁被解锁(不属于任何线程),则抢夺所有权,设置递归等级为一,并返回。如果多个线程被阻塞,等待锁被解锁,一次只有一个线程能抢到锁的所有权。在这种情况下,没有返回值。
(机翻)当调用
blocking参数设置为 "True"时,与调用无参数时做同样的事情,并返回 “True”。
当调用时将blocking参数设置为False时,不阻塞。如果没有参数的调用会阻塞,立即返回False;否则,做与没有参数的调用一样的事情,并返回True。
当调用浮点timeout参数设置为正值时,最多阻塞时间为timeout指定的秒数,只要锁不能被获取。如果锁已经被获取,返回True;如果timeout已过,返回False。
在 3.2 版更改: 新的
timeout形参。
release()
释放锁,自减递归等级。如果减到零,则将锁重置为非锁定状态(不被任何线程拥有),并且,如果其他线程正被阻塞着等待锁被解锁,则仅允许其中一个线程继续。如果自减后,递归等级仍然不是零,则锁保持锁定,仍由调用线程拥有。
只有当前线程拥有锁才能调用这个方法。如果锁被释放后调用这个方法,会引起RuntimeError异常。
没有返回值。
条件对象
条件变量总是与某种类型的锁对象相关联,锁对象可以通过传入获得,或者在缺省的情况下自动创建。当多个条件变量需要共享同一个锁时,传入一个锁很有用。锁是条件对象的一部分,你不必单独地跟踪它。
条件变量遵循 上下文管理协议 :使用 with 语句会在它包围的代码块内获取关联的锁。 acquire() 和 release() 方法也能调用关联锁的相关方法。
其它方法必须在持有关联的锁的情况下调用。 wait() 方法释放锁,然后阻塞直到其它线程调用 notify() 方法或 notify_all() 方法唤醒它。一旦被唤醒, wait() 方法重新获取锁并返回。它也可以指定超时时间。
(机翻)notify()方法唤醒了等待条件变量的线程之一,如果有任何线程在等待的话。notify_all()方法唤醒了所有等待条件变量的线程。
注意: notify() 方法和 notify_all() 方法并不会释放锁,这意味着被唤醒的线程不会立即从它们的 wait() 方法调用中返回,而是会在调用了 notify() 方法或 notify_all() 方法的线程最终放弃了锁的所有权后返回。
使用条件变量的典型编程风格是将锁用于同步某些共享状态的权限,那些对状态的某些特定改变感兴趣的线程,它们重复调用 wait() 方法,直到看到所期望的改变发生;而对于修改状态的线程,它们将当前状态改变为可能是等待者所期待的新状态后,调用 notify() 方法或者 notify_all() 方法。例如,下面的代码是一个通用的无限缓冲区容量的生产者-消费者情形:
# Consume one item
with cv:
while not an_item_is_available():
cv.wait()
get_an_available_item()
# Produce one item
with cv:
make_an_item_available()
cv.notify()
使用 while 循环检查所要求的条件成立与否是有必要的,因为 wait() 方法可能要经过不确定长度的时间后才会返回,而此时导致 notify() 方法调用的那个条件可能已经不再成立。这是多线程编程所固有的问题。 wait_for() 方法可自动化条件检查,并简化超时计算。
# Consume an item
with cv:
cv.wait_for(an_item_is_available)
get_an_available_item()
选择 notify() 还是 notify_all() ,取决于一次状态改变是只能被一个还是能被多个等待线程所用。例如在一个典型的生产者-消费者情形中,添加一个项目到缓冲区只需唤醒一个消费者线程。
class threading.Condition(lock=None)
实现条件变量对象的类。一个条件变量对象允许一个或多个线程在被其它线程所通知之前进行等待。
如果给出了非None的lock参数,则它必须为Lock或者RLock对象,并且它将被用作底层锁。否则,将会创建新的RLock对象,并将其用作底层锁。
在 3.3 版更改: 从工厂函数变为类。
acquire(*args)
请求底层锁。此方法调用底层锁的相应方法,返回值是底层锁相应方法的返回值。
release()
释放底层锁。此方法调用底层锁的相应方法。没有返回值。
wait(timeout=None)
等待直到被通知或发生超时。如果线程在调用此方法时没有获得锁,将会引发
RuntimeError异常。
这个方法释放底层锁,然后阻塞,直到在另外一个线程中调用同一个条件变量的notify()或notify_all()唤醒它,或者直到可选的超时发生。一旦被唤醒或者超时,它重新获得锁并返回。
当提供了timeout参数且不是None时,它应该是一个浮点数,代表操作的超时时间,以秒为单位(可以为小数)。
当底层锁是个RLock,不会使用它的release()方法释放锁,因为当它被递归多次获取时,实际上可能无法解锁。相反,使用了RLock类的内部接口,即使多次递归获取它也能解锁它。 然后,在重新获取锁时,使用另一个内部接口来恢复递归级别。
返回True,除非提供的timeout过期,这种情况下返回False。
在 3.2 版更改: 很明显,方法总是返回 None。
wait_for(predicate, timeout=None)
等待,直到条件计算为真。
predicate应该是一个可调用对象而且它的返回值可被解释为一个布尔值。可以提供timeout参数给出最大等待时间。
这个实用方法会重复地调用wait()直到满足判断式或者发生超时。返回值是判断式最后一个返回值,而且如果方法发生超时会返回False。
忽略超时功能,调用此方法大致相当于编写:
while not predicate():
cv.wait()
因此,规则同样适用于
wait():锁必须在被调用时保持获取,并在返回时重新获取。 随着锁定执行判断式。
3.2 新版功能.
notify(n=1)
默认唤醒一个等待这个条件的线程。如果调用线程在没有获得锁的情况下调用这个方法,会引发
RuntimeError异常。
这个方法唤醒最多 n 个正在等待这个条件变量的线程;如果没有线程在等待,这是一个空操作。
当前实现中,如果至少有 n 个线程正在等待,准确唤醒 n 个线程。但是依赖这个行为并不安全。未来,优化的实现有时会唤醒超过 n 个线程。
注意:被唤醒的线程并没有真正恢复到它调用的
wait(),直到它可以重新获得锁。 因为notify()不释放锁,其调用者才应该这样做。
notify_all()
唤醒所有正在等待这个条件的线程。这个方法行为与
notify()相似,但并不只唤醒单一线程,而是唤醒所有等待线程。如果调用线程在调用这个方法时没有获得锁,会引发RuntimeError异常。
notifyAll方法是此方法的已弃用别名。
信号量对象
这是计算机科学史上最古老的同步原语之一,早期的荷兰科学家 Edsger W. Dijkstra 发明了它。(他使用名称 P() 和 V() 而不是 acquire() 和 release() )。
一个信号量管理一个内部计数器,该计数器因 acquire() 方法的调用而递减,因 release() 方法的调用而递增。 计数器的值永远不会小于零;当 acquire() 方法发现计数器为零时,将会阻塞,直到其它线程调用 release() 方法。
信号量对象也支持 上下文管理协议 。
class threading.Semaphore(value=1)
该类实现信号量对象。信号量对象管理一个原子性的计数器,代表
release()方法的调用次数减去acquire()的调用次数再加上一个初始值。如果需要,acquire()方法将会阻塞直到可以返回而不会使得计数器变成负数。在没有显式给出value的值时,默认为1。
可选参数value赋予内部计数器初始值,默认值为 1 。如果value被赋予小于0的值,将会引发ValueError异常。
在 3.3 版更改: 从工厂函数变为类。
acquire(blocking=True, timeout=None)
获取一个信号量。
在不带参数的情况下调用时:
如果在进入时内部计数器的值大于零,则将其减一并立即返回True。
如果在进入时内部计数器的值为零,则将会阻塞直到被对release()的调用唤醒。 一旦被唤醒(并且计数器的值大于 0),则将计数器减 1 并返回True。 每次对release()的调用将只唤醒一个线程。 线程被唤醒的次序是不可确定的。
(机翻)当调用时将blocking设置为False,不阻塞。如果没有参数的调用会阻塞,立即返回False;否则,做与没有参数的调用相同的事情,并返回True。
当发起调用时如果timeout不为None,则它将阻塞最多timeout秒。 请求在此时段时未能成功完成获取则将返回False。 在其他情况下返回True。
在 3.2 版更改: 新的 timeout 形参。
release(n=1)
释放一个信号量,将内部计数器的值增加 n。 当进入时值为零且有其他线程正在等待它再次变为大于零时,则唤醒那 n 个线程。
在 3.9 版更改: 增加了 n 形参以一次性释放多个等待线程。
class threading.BoundedSemaphore(value=1)
该类实现有界信号量。有界信号量通过检查以确保它当前的值不会超过初始值。如果超过了初始值,将会引发
ValueError异常。在大多情况下,信号量用于保护数量有限的资源。如果信号量被释放的次数过多,则表明出现了错误。没有指定时,value的值默认为1。
在 3.3 版更改: 从工厂函数变为类。
Semaphore 例子
信号量通常用于保护数量有限的资源,例如数据库服务器。在资源数量固定的任何情况下,都应该使用有界信号量。在生成任何工作线程前,应该在主线程中初始化信号量。
maxconnections = 5
# ...
pool_sema = BoundedSemaphore(value=maxconnections)
工作线程生成后,当需要连接服务器时,这些线程将调用信号量的 acquire 和 release 方法:
with pool_sema:
conn = connectdb()
try:
# ... use connection ...
finally:
conn.close()
使用有界信号量能减少这种编程错误:信号量的释放次数多于其请求次数。
事件对象
这是线程之间通信的最简单机制之一:一个线程发出事件信号,而其他线程等待该信号。
一个事件对象管理一个内部标识,调用 set() 方法可将其设置为 true ,调用 clear() 方法可将其设置为 false ,调用 wait() 方法将进入阻塞直到标识为 true 。
class threading.Event
实现事件对象的类。事件对象管理一个内部标识,调用
set()方法可将其设置为true。调用clear()方法可将其设置为false。调用wait()方法将进入阻塞直到标识为true。这个标识初始时为false。
在 3.3 版更改: 从工厂函数变为类。
is_set()
当且仅当内部标识为
true时返回True。
isSet方法是此方法的已弃用别名。
set()
将内部标识设置为
true。所有正在等待这个事件的线程将被唤醒。当标识为true时,调用wait()方法的线程不会被被阻塞。
clear()
将内部标识设置为
false。之后调用wait()方法的线程将会被阻塞,直到调用set()方法将内部标识再次设置为true。
wait(timeout=None)
阻塞线程直到内部变量为
true。如果调用时内部标识为true,将立即返回。否则将阻塞线程,直到调用set()方法将标识设置为true或者发生可选的超时。
当提供了timeout参数且不是None时,它应该是一个浮点数,代表操作的超时时间,以秒为单位(可以为小数)。
当且仅当内部旗标在等待调用之前或者等待开始之后被设为真值时此方法将返回True,也就是说,它将总是返回True除非设定了超时且操作发生了超时。
在 3.1 版更改: 很明显,方法总是返回
None。
定时器对象
此类表示一个操作应该在等待一定的时间之后运行 — 相当于一个定时器。 Timer 类是 Thread 类的子类,因此可以像一个自定义线程一样工作。
与线程一样,通过调用 start() 方法启动定时器。而 cancel() 方法可以停止计时器(在计时结束前), 定时器在执行其操作之前等待的时间间隔可能与用户指定的时间间隔不完全相同。
例如:
def hello():
print("hello, world")
t = Timer(30.0, hello)
t.start() # after 30 seconds, "hello, world" will be printed
class threading.Timer(interval, function, args=None, kwargs=None)
创建一个定时器,在经过
interval秒的间隔事件后,将会用参数args和关键字参数kwargs调用function。如果args为None(默认值),则会使用一个空列表。如果kwargs为None(默认值),则会使用一个空字典。
在 3.3 版更改: 从工厂函数变为类。
cancel()
停止定时器并取消执行计时器将要执行的操作。仅当计时器仍处于等待状态时有效。
栅栏对象
3.2 新版功能.
栅栏类提供一个简单的同步原语,用于应对固定数量的线程需要彼此相互等待的情况。线程调用 wait() 方法后将阻塞,直到所有线程都调用了 wait() 方法。此时所有线程将被同时释放。
栅栏对象可以被多次使用,但进程的数量不能改变。
这是一个使用简便的方法实现客户端进程与服务端进程同步的例子:
b = Barrier(2, timeout=5)
def server():
start_server()
b.wait()
while True:
connection = accept_connection()
process_server_connection(connection)
def client():
b.wait()
while True:
connection = make_connection()
process_client_connection(connection)
class threading.Barrier(parties, action=None, timeout=None)
创建一个需要
parties个线程的栅栏对象。如果提供了可调用的action参数,它会在所有线程被释放时在其中一个线程中自动调用。timeout是默认的超时时间,如果没有在wait()方法中指定超时时间的话。
wait(timeout=None)
冲出栅栏。当栅栏中所有线程都已经调用了这个函数,它们将同时被释放。如果提供了
timeout参数,这里的timeout参数优先于创建栅栏对象时提供的timeout参数。
函数返回值是一个整数,取值范围在0到parties– 1,在每个线程中的返回值不相同。可用于从所有线程中选择唯一的一个线程执行一些特别的工作。例如:
i = barrier.wait()
if i == 0:
# Only one thread needs to print this
print("passed the barrier")
如果创建栅栏对象时在构造函数中提供了
action参数,它将在其中一个线程释放前被调用。如果此调用引发了异常,栅栏对象将进入损坏态。
如果发生了超时,栅栏对象将进入破损态。
如果栅栏对象进入破损态,或重置栅栏时仍有线程等待释放,将会引发BrokenBarrierError异常。
reset()
重置栅栏为默认的初始态。如果栅栏中仍有线程等待释放,这些线程将会收到
BrokenBarrierError异常。
请注意使用此函数时,如果存在状态未知的其他线程,则可能需要执行外部同步。 如果栅栏已损坏则最好将其废弃并新建一个。
abort()
使栅栏处于损坏状态。 这将导致任何现有和未来对 wait() 的调用失败并引发
BrokenBarrierError。 例如可以在需要中止某个线程时使用此方法,以避免应用程序的死锁。
更好的方式是:创建栅栏时提供一个合理的超时时间,来自动避免某个线程出错。
parties
冲出栅栏所需要的线程数量。
n_waiting
当前时刻正在栅栏中阻塞的线程数量。
broken
一个布尔值,值为
True表明栅栏为破损态。
exception threading.BrokenBarrierError
异常类,是
RuntimeError异常的子类,在Barrier对象重置时仍有线程阻塞时和对象进入破损态时被引发。
在 with 语句中使用锁、条件和信号量
这个模块提供的带有 acquire() 和 release() 方法的对象,可以被用作 with 语句的上下文管理器。当进入语句块时 acquire() 方法会被调用,退出语句块时 release() 会被调用。因此,以下片段:
with some_lock:
# do something...
相当于:
some_lock.acquire()
try:
# do something...
finally:
some_lock.release()
现在 Lock 、 RLock 、 Condition 、 Semaphore 和 BoundedSemaphore 对象可以用作 with 语句的上下文管理器。
测试
将_thread的例子修改为threading的版本:
nano threading_test.py
#!/usr/bin/python3
import threading
import time
M = 3
tickets = 20
lock = threading.Lock()
def fun(ID):
global tickets
global lock
while True:
lock.acquire() # 上锁
if tickets > 0:
time.sleep((ID + 1)/10)
tickets -= 1
print("(Thread %d)the remaining tickets:%d" %(ID + 1, tickets))
lock.release() # 解锁
if not tickets > 0:
return
for _ in range(M):
threading.Thread(target=fun, args=(_,), daemon = True).start()
while threading.active_count() > 1:
pass
python3 ./threading_test.py

其它部分的示例见Python3多线程threading介绍(转载)
以下部分内容摘自C++ 多线程 | 菜鸟教程
g++ -std=c++11 test.cpp
C++
参考资料:C++ std::thread | 菜鸟教程
C++ 11 之后添加了新的标准线程库 std::thread,std::thread 在 std::thread 时需要包含 在
之前一些编译器使用 C++ 11 的编译参数是 -std=c++11:
std::thread
std::thread 构造函数
/* 默认构造函数 */
thread() noexcept;
/* 初始化构造函数 */
template <class Fn, class... Args>
explicit thread(Fn&& fn, Args&&... args);
/* 拷贝构造函数 [deleted] */
thread(const thread&) = delete;
/* Move 构造函数 */
thread(thread&& x) noexcept;
默认构造函数,创建一个空的 std::thread 执行对象。
初始化构造函数,创建一个 std::thread 对象,该 std::thread 对象可被 joinable,新产生的线程会调用 fn 函数,该函数的参数由 args 给出。
拷贝构造函数(被禁用),意味着 std::thread 对象不可拷贝构造。
Move 构造函数,move 构造函数(move 语义是 C++11 新出现的概念),调用成功之后 x 不代表任何 std::thread 执行对象。
std::thread 各种构造函数例子如下:
#include std::thread 赋值操作
/* Move 赋值操作 */
thread& operator=(thread&& rhs) noexcept;
/* 拷贝赋值操作 [deleted] */
thread& operator=(const thread&) = delete;
(1) Move 赋值操作,如果当前对象不可 joinable,需要传递一个右值引用(rhs)给 move 赋值操作;如果当前对象可被 joinable,则会调用 terminate() 报错。
(2) 拷贝赋值操作,被禁用,因此 std::thread 对象不可拷贝赋值。
请看下面的例子:
#include 其他成员函数
get_id
获取线程 ID,返回一个类型为 std::thread::id 的对象。请看下面例子:
#include joinable
检查线程是否可被 join。检查当前的线程对象是否表示了一个活动的执行线程,由默认构造函数创建的线程是不能被join的。另外,如果某个线程已经执行完任务,但是没有被join的话,该线程依然会被认为是一个活动的执行线程,因此也是可以被join的。
#include join
join 线程,调用该函数会阻塞当前线程,直到由 *this 所标示的线程执行完毕 join 才返回。
#include detach
detach 线程。 将当前线程对象所代表的执行实例与该线程对象分离,使得线程的执行可以单独进行。一旦线程执行完毕,它所分配的资源将会被释放。
调用 detach 函数之后:
*this 不再代表任何的线程执行实例。
joinable() == false
get_id() == std::thread::id()
另外,如果出错或者 joinable() == false,则会抛出 std::system_error。
#include swap
swap 线程,交换两个线程对象所代表的底层句柄(underlying handles)。
#include 执行结果如下:

native_handle
返回 native handle(由于 std::thread 的实现和操作系统相关,因此该函数返回与 std::thread 具体实现相关的线程句柄,例如在符合 Posix 标准的平台下(如 Unix/Linux)是 Pthread 库)。
#include 执行结果:
菜鸟教程说的结果为
Thread 2 is executing at priority 0
Thread 1 is executing at priority 20
在wsl2 ubuntu 18.04 LTS中实测的结果为

在RK3399 Pro的Debian系统上实测的结果为

遗憾。
hardware_concurrency [static]
检测硬件并发特性,返回当前平台的线程实现所支持的线程并发数目,但返回值仅仅只作为系统提示(hint)。
#include std::this_thread 命名空间中相关辅助函数介绍
get_id
获取线程 ID。
#include yield
当前线程放弃执行,操作系统调度另一线程继续执行。
#include sleep_until
线程休眠至某个指定的时刻(time point),该线程才被重新唤醒。
template< class Clock, class Duration >
void sleep_until( const std::chrono::time_point<Clock,Duration>& sleep_time );
sleep_for
线程休眠某个指定的时间片(time span),该线程才被重新唤醒,不过由于线程调度等原因,实际休眠时间可能比 sleep_duration 所表示的时间片更长。
#include 执行结果如下:

std::mutex
参考资料:C++11 并发指南三(std::mutex 详解) —— Haippy
Mutex 又称互斥量,C++ 11中与 Mutex 相关的类(包括锁类型)和函数都声明在 std::mutex,就必须包含
std::mutex 是C++11 中最基本的互斥量,std::mutex 对象提供了独占所有权的特性——即不支持递归地对 std::mutex 对象上锁,而 std::recursive_lock 则可以递归地对互斥量对象上锁。
Mutex 系列类(四种)
std::mutex,最基本的 Mutex 类。
std::recursive_mutex,递归 Mutex 类。
std::time_mutex,定时 Mutex 类。
std::recursive_timed_mutex,定时递归 Mutex 类。
Lock 类(两种)
std::lock_guard,与 Mutex RAII 相关,方便线程对互斥量上锁。
std::unique_lock,与 Mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制。
其他类型
std::once_flag
std::adopt_lock_t
std::defer_lock_t
std::try_to_lock_t
函数
std::try_lock,尝试同时对多个互斥量上锁。
std::lock,可以同时对多个互斥量上锁。
std::call_once,如果多个线程需要同时调用某个函数,call_once 可以保证多个线程对该函数只调用一次。
std::mutex 的成员函数
构造函数,std::mutex不允许拷贝构造,也不允许 move 拷贝,最初产生的 mutex 对象是处于 unlocked 状态的。
lock(),调用线程将锁住该互斥量。线程调用该函数会发生下面 3 种情况:
(1). 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁。
(2). 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。
(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
unlock(), 解锁,释放对互斥量的所有权。
try_lock(),尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。线程调用该函数也会出现下面 3 种情况,
(1). 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量。
(2). 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉。
(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
下面给出一个与 std::mutex 的小例子:
#include std::recursive_mutex 介绍
std::recursive_mutex 与 std::mutex 一样,也是一种可以被上锁的对象,但是和 std::mutex 不同的是,std::recursive_mutex 允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,std::recursive_mutex 释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),可理解为 lock() 次数和 unlock() 次数相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
std::time_mutex 介绍
std::time_mutex 比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until()。
try_lock_for 函数接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex 的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
try_lock_until 函数则接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
下面的小例子说明了 std::time_mutex 的用法:
#include std::recursive_timed_mutex 介绍
和 std:recursive_mutex 与 std::mutex 的关系一样,std::recursive_timed_mutex 的特性也可以从 std::timed_mutex 推导出来。
std::lock_guard 介绍
与 Mutex RAII 相关,方便线程对互斥量上锁。
例子:
#include std::unique_lock 介绍
与 Mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制。
例子:
#include std::try_lock
template <class Mutex1, class Mutex2, class... Mutexes>
int try_lock (Mutex1& a, Mutex2& b, Mutexes&... cde);
尝试锁定多个互斥对象(机翻)
尝试使用try_lock成员函数锁定所有作为参数传递的对象(非阻塞)。
该函数为每个参数调用try_lock成员函数(首先是a,然后是b,最后是cde中的其他参数,顺序相同),直到所有调用都成功,或者一旦其中一个调用失败(要么返回false,要么抛出一个异常)。
如果函数因调用失败而结束,则对所有调用try_lock成功的对象调用unlock,并且该函数返回锁定失败的对象的参数顺序号。对于参数列表中的其余对象,不再进行进一步的调用。
参数
a, b, cde
要尝试锁定的对象。
Mutex1、Mutex2和Mutexes应是可锁类型。
返回值
如果该函数成功地锁定了所有的对象,它返回-1。
否则,该函数返回未能被锁定的对象的索引(0代表a,1代表b,…)。
例子
// std::lock example
#include 可能的结果
task a
[task b failed: mutex foo locked]
(机翻)互斥对象可能被锁定在task_b上,或者两个任务都可以按照其中一种顺序成功(文本可能在失败时出现混合)。

std::lock
template <class Mutex1, class Mutex2, class... Mutexes>
void lock (Mutex1& a, Mutex2& b, Mutexes&... cde);
锁定多个互斥对象(机翻)
锁定所有作为参数传递的对象,必要时阻塞调用线程。
该函数通过对其成员lock、try_lock和unlock的非指定序列的调用来锁定这些对象,确保所有参数在返回时被锁定(不产生任何死锁)。
如果函数不能锁定所有的对象(比如因为它的一个内部调用抛出了一个异常),在失败之前,函数首先解锁它成功锁定的所有对象(如果有的话)。
参数
a, b, cde
要锁定的对象。
Mutex1、Mutex2和Mutexes应是可锁定的类型。
例子
// std::lock example
#include (机翻)请注意,在通过调用std::lock替换单个锁之前,如果task_a锁定了foo,而task_b锁定了bar,两者都无法获得第二个锁,导致死锁。
可能的输出(行的顺序可能不同)。
task a
task b
std::call_once
template <class Fn, class... Args>
void call_once (once_flag& flag, Fn&& fn, Args&&... args);
调用一次函数(机翻)
调用参数为args的fn,除非另一个线程已经执行了(或正在执行)具有相同标志的对call_once的调用。
如果另一个线程已经在主动执行一个具有相同标志的对call_once的调用,则会导致被动执行。被动执行不调用fn,但不返回,直到主动执行本身返回,并且所有可见的副作用在这一点上在所有并发调用这个具有相同标志的函数中是同步的。
如果对call_once的主动调用以抛出异常结束(该异常会被传播到其调用线程),并且存在被动执行,则会在这些被动执行中选择一个,并调用其作为新的主动调用。
请注意,一旦一个主动执行返回,所有当前的被动执行和未来对call_once的调用(具有相同的标志)也会返回,而不会成为主动执行。
主动执行使用fn和args的lvalue或rvalue引用的衰减拷贝,忽略fn返回的值。
参数
flag
函数用来跟踪调用状态的对象。
在不同的线程中使用相同的对象进行调用,如果同时调用,则会产生一个单一的调用。
(C++11)如果flag有一个无效的状态,函数会抛出一个带有invalid_argument错误条件的system_error异常。
call_once是在头文件
fn
指向函数的指针,指向成员的指针,或者任何一种可移动的函数对象(即其类别定义了operator()的对象,包括闭包和函数对象)。
返回值(如果有的话)被忽略。
args...
传递给调用fn的参数。它们的类型应是可移动的结构。
如果fn是一个成员指针,第一个参数应是一个定义了该成员的对象(或一个引用,或一个指向它的指针)。
例子
// call_once example
#include 可能的输出(winner可能会有所不同)

测试
将之前的实验修改为C++版本:
nano main.cpp
#include nano Makefile
main: main.o
g++ -o main main.o -lpthread -std=c++11
main.o: main.cpp
g++ -c main.cpp
.PHONY:clear
clear:
rm *.o
rm main
make
./main

C语言
参考资料:
pthread库的使用 —— sherlock_lin
【C++】【pthread】C++ POSIX Thread 线程同步常用API讲解 —— 命运之手
线程以及pthread库的使用 —— 椛茶
pthread学习笔记(二)–pthread常用API及简单介绍 —— hitrose27
pthread学习笔记(三)–跋涉之旅之Posix线程编程指南(1) —— hitrose27
帮助手册的安装:
sudo apt-get install manpages-posix-dev
头文件
使用 pthread 需要添加头文件,并链接库 -lpthread
#include 一些常用函数如下:
线程
创建线程
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void*), void *restrict arg);
参数
thread :thread 是一个指向线程标识符的指针,线程调用后,该值被设置为线程ID
typedef unsigned long int pthread_t;
attr :一个不透明的属性对象,可以被用来设置线程属性。您可以指定线程属性对象,也可以使用默认值 NULL。
start_routine: 是线程函数的其实地址,即线程函数体,线程创建成功后,thread 指向的内存单元从该地址开始运行
arg :运行函数的参数。它必须通过把引用作为指针强制转换为 void 类型进行传递。如果没有传递参数,则使用 NULL。
返回值:若线程创建成功,则返回0,失败则返回错误码,并且 thread 内容是未定义的。
pthread_t pthread_self(void);
获取当前线程的id
参数
thread 是线程表示符
int pthread_equal(pthread_t t1, pthread_t t2);
参数
thread 是线程表示符
比较两个线程 ID 是否相等,在 Linux 系统中 pthread_t 都设计为 unsigned long 类型,所以可以直接用 == 判别是否相等,但是如果某些系统设计为结构体类型,那么就可以通过 pthread_equal 函数判别是否相等了。
取消线程
一般情况下,线程在其主体函数退出的时候会自动终止 ,但同时也可以因为接收到另一个线程发来的终止(取消)请求而强制终止 。
线程取消的方法是向目标线程发Cancel信号,但如何处理Cancel信号则由目标线程自己决定 ,或者忽略、或者立即终止、或者继续运行至Cancelation-point(取消点) ,由不同的Cancelation状态决定 。
线程接收到CANCEL信号的缺省处理 (即pthread_create()创建线程的缺省状态)是继续运行至取消点 ,也就是说设置一个CANCELED状态,线程继续运行,只有运行至Cancelation-point的时候才会退出。
取消点
根据POSIX标准,pthread_join()、pthread_testcancel()、 pthread_cond_wait()、pthread_cond_timedwait()、sem_wait()、sigwait()等函数以及 read()、write()等会引起阻塞的系统调用都是Cancelation-point,而其他pthread函数都不会引起Cancelation动作。但是pthread_cancel的手册页声称,由于Linux Thread库与C库结合得不好,因而目前C库函数都不是Cancelation-point;但CANCEL信号会使线程从阻塞的系统调用中退出,并置EINTR错误码 ,因此可以在需要作为Cancelation-point的系统调用前后调用pthread_testcancel(),从而达到POSIX标准所要求的目标 ,即如下代码段:
pthread_testcancel();
retcode = read(fd, buffer, length);
pthread_testcancel();
pthread_testcancel的函数声明如下:
//terminate the thread as per pthread_exit(PTHREAD_CANCELED) if
//it has been canceled
extern void pthread_testcancel(void);
从上面的代码说明当中可以看出当达到了取消点的时候,为了解决和c库函数结合不好的问题,使用pthread_testcancel()可以执行退出的操作(当PTHREAD_CANCELED置位时,会调用pthread_exit函数)。
如果线程处于无限循环中,且循环体内没有执行至取消点的必然路径 ,则线程无法由外部其他线程的取消请求而终止。因此在这样的循环体的必经路径上应该加入pthread_testcancel()调用 (杜绝无法跳出的情况)。
与线程取消相关的pthread函数
取消线程的执行
int pthread_cancel(pthread_t thread);
pthread_cancel()函数将请求取消该线程。目标线程的取消状态和类型决定了取消何时生效。当执行取消操作时,将调用线程的取消清理处理程序。当最后一个取消清理处理程序返回时,线程特定的数据析构函数将被调用。当最后一个析构函数返回时,线程将被终止。
对于从pthread_cancel()返回的调用线程来说,目标线程中的取消处理应以异步方式运行。
设置本线程对Cancel信号的反应
int pthread_setcancelstate(int state, int *oldstate);
state有两种值:PTHREAD_CANCEL_ENABLE(缺省)和 PTHREAD_CANCEL_DISABLE,分别表示收到信号后设为CANCLED状态和忽略CANCEL信号继续运行 ;old_state如果不为 NULL则存入原来的Cancel状态以便恢复 。
(一般的函数设计原则——返回值表示函数执行的状态,输入输出的结果均由参数列表传入)
设置本线程取消动作的执行时机
int pthread_setcanceltype(int type, int *oldtype);
type由两种取值:PTHREAD_CANCEL_DEFFERED和 PTHREAD_CANCEL_ASYCHRONOUS,仅当Cancel状态为Enable时有效 ,分别表示收到信号后继续运行至下一个取消点再退出和 立即执行取消动作(退出) ;oldtype如果不为NULL则存入运来的取消动作类型值。
检查本线程是否处于Canceled状态
void pthread_testcancel(void)
如果是,则进行取消动作 ,否则直接返回。
终止线程
void pthread_exit(void *value_ptr);
参数
value_ptr: 是线程的退出码,传递给创建线程的地方
中止线程可以有三种方式:
- 线程函数体执行结束;
- 调用
pthread_exit方法退出线程; - 被同一进程中的另外的线程Cancel掉
pthread_exit 用于显式地退出一个线程。通常情况下,pthread_exit() 函数是在线程完成工作后无需继续存在时被调用。
如果 main() 是在它所创建的线程之前结束,并通过 pthread_exit() 退出,那么其他线程将继续执行。否则,它们将在 main() 结束时自动被终止。
即用于提前结束当前线程,如果是父线程,子线程也会立刻结束。
如果是main线程的话,则特殊对待,只结束主线程,其它子线程等其自然结束,最后进程才退出。
通过pthread_exit退出的线程,不会释放线程资源,还是需要通过pthread_detach或pthread_join来释放。
连接和分离线程
int pthread_join(pthread_t thread, void **value_ptr);
参数
thread 是线程表示符
value_ptr 用来获取线程的返回值,一般是 pthread_join 方法传递出来的值
pthread_join() 是一个线程阻塞函数,调用该函数则等到线程结束才继续运行。当创建一个线程时,它的某个属性会定义它是否是可连接的(joinable)或可分离的(detached)。只有创建时定义为可连接的线程才可以被连接。如果线程创建时被定义为可分离的,则它永远也不能被连接。 对同一个线程只能使用一次,并且必须是Joinable状态的线程,否则都将立刻返回错误码,不等待线程执行完毕。
int pthread_detach(pthread_t thread);
参数
thread 是线程表示符
将当前线程与pid解绑。通过pthread_create创建的线程,默认是会保存return值的,直到有人调用了pthread_join来获取return值。
我们把这种状态的线程叫做Joinable Thread,如果没有人调用pthread_join,即便线程代码执行完毕了,return值还会一直保存,比较浪费内存资源。
通过pthread_detach,我们可以让线程切换到Detached状态,即线程代码执行完,立刻销毁return值。
pthread_detach可以在线程中对自己使用,也可以在创建子线程的父线程中,对子线程使用。
互斥锁
互斥锁用于在多线程情况下,禁止多个线程同时访问资源,以避免多线程同时操作同一变量可能引发的冲突。
互斥锁通过pthread_mutex_t类型来表示,只有获得了mutex的线程,才能继续执行代码,mutex被释放后,其它线程才能重新获得mutex。
销毁并初始化一个互斥对象
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
可以通过函数动态初始化:
pthread_mutex_t mutex;
pthread_mutex_init(&mutex, nullptr);
也可以通过预定义的宏静态初始化:
pthread_mutex_t mutex;
mutex = PTHREAD_MUTEX_INITIALIZER;
获得mutex锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
并继续执行后面的代码,如果mutex锁已被其它线程占有,则一直持续等待。
释放mutex锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);
需要保证同步的代码执行完毕,释放已经获得的mutex锁。
尝试获得mutex锁
int pthread_mutex_trylock(pthread_mutex_t *mutex);
如果已被其它线程占有,则立刻返回错误码。
和pthread_mutex_lock的区别在于,pthread_mutex_lock必须拿到mutex,拿不到就一直等待。
而pthread_mutex_trylock只是尝试一下,拿不到就立刻停止等待,不会阻塞代码。
超时版本的lock
#include 如果到达了指定时间,还没有得到mutex锁,则返回错误码。
注意,这里的时间不是指1秒,2秒这种超时间隔,而是年月日时分秒这种具体的等待截止时间。
struct timespec time;
clock_gettime(CLOCK_REALTIME, &time); //当前系统时间
time.tv_sec += 10; //10秒后的系统时间
pthread_mutex_timedlock(&mutex, &time);
销毁mutex锁
int pthread_mutex_destroy(pthread_mutex_t *mutex);
已经被lock的mutex,再destroy会返回EBUSY错误。
已经被destroy的mutex,再lock程序会崩溃,抛出pthread_mutex_lock called on a destroyed mutex的错误。
已经被lock的mutex,再lock会死锁(互斥锁有很多种,这里指的是默认类型)。
pthread_mutex_destroy使用不正确,轻则造成销毁失败,内存资源浪费,重则造成程序崩溃
所以pthread_mutex_destroy的使用一定要注意两点:
-
在
pthread_mutex_destroy调用之后,要保证包含mutex的方法,不再被调用,可通过pthread_join,等待和mutex相关的其它线程都结束后,再调用pthread_mutex_destroy。 -
用到
mutex的方法,一定要设计成可退出的,不能在某些条件下就进入死循环,通过pthread_join也无法正常退出,必要时要配合pthread_cond使用,才能达到随时退出循环的效果。
自旋锁
参考资料:pthread的互斥量和自旋锁 —— zhaopengnju
自旋锁与互斥量的区别
在多处理器环境中,自旋锁最多只能被一个可执行线程持有。如果一个可执行线程试图获得一个被争用(已经被持有的)自旋锁,那么该线程就会一直进行忙等待,自旋,也就是空转,等待锁重新可用。如果锁未被争用,请求锁的执行线程便立刻得到它,继续执行。一个被争用的自旋锁使得请求它的线程在等待锁重新可用时自旋,特别的浪费CPU时间,所以自旋锁不应该被长时间的持有。实际上,这就是自旋锁的设计初衷,在短时间内进行轻量级加锁。
信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用而不能在中断上下文使用,因为中断的上下文不允许休眠(trylock可以),因此在中断上下文只能使用自旋锁。
自旋锁保持期间是抢占失效的(内核不允许被抢占) ,而信号量和读写信号量保持期间是可以被抢占的。
自旋锁保护的临界区默认是可以相应中断的,但是如果在中断处理程序中请求相同的自旋锁,那么会发生死锁(内核自旋锁可以关闭中断)。
(摘自noticeable的博客:25、线程同步及消息队列)自旋锁与互斥锁功能一样,唯一一点不同的就是互斥量阻塞后休眠让出CPU,而自旋锁阻塞后不会让出CPU,会一直忙等待,直到得到锁!
自旋锁在用户态使用的比较少,在内核使用的比较多!自旋锁的使用场景:锁的持有时间比较短,或者说小于2次上下文切换的时间。
自旋锁在用户态的函数接口和互斥量一样,把pthread_mutex_xxx()中mutex换成spin,如:pthread_spin_init()。
自旋锁初始化
int pthread_spin_init(pthread_spinlock_t *lock, int pshared);
自旋锁操作
int pthread_spin_lock(pthread_spinlock_t *lock);
int pthread_spin_trylock(pthread_spinlock_t *lock);
int pthread_spin_unlock(pthread_spinlock_t *lock);
自旋锁销毁
int pthread_spin_destroy(pthread_spinlock_t *lock);
读写锁
参考资料:linux使用读写锁pthread_rwlock_t
很多时候,对共享变量的访问有以下特点:大多数情况下线程只是读取共享变量的值,并不修改,只有极少数情况下,线程才会真正地修改共享变量的值。对于这种情况,读请求之间之间是无需同步的,他们之间的并发访问是安全的。但是必须互斥写请求和其他读请求。
这种情况在实际中是存在的,比如配置项。大多数时间内,配置是不会发生变化的,偶尔会出现修改配置的情况。如果使用互斥量,完全阻止读请求并发,则会造成性能的损失。处于这种考虑,POSIX引入了读写锁。
多个线程可以同时获得读锁(Reader-Writer lock in read mode),但是只有一个线程能够获得写锁(Reader-writer lock in write mode)
读写锁有三种状态:
- 一个或者多个线程获得读锁,其他线程无法获得写锁
- 一个线程获得写锁,其他线程无法获得读锁
- 没有线程获得此读写锁
初始化读写锁
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock,
const pthread_rwlockattr_t *restrict attr);
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;
如果 attr 为 NULL,则使用缺省的读写锁属性,其作用与传递缺省读写锁属性对象的地址相同。初始化读写锁之后,该锁可以使用任意次数,而无需重新初始化。成功初始化之后,读写锁的状态会变为已初始化和未锁定。如果调用 pthread_rwlock_init() 来指定已初始化的读写锁,则结果是不确定的。如果读写锁在使用之前未初始化,则结果是不确定的。
如果缺省的读写锁属性适用,则 PTHREAD_RWLOCK_INITIALIZER 宏可初始化以静态方式分配的读写锁,其作用与通过调用 pthread_rwlock_init() 并将参数attr 指定为 NULL 进行动态初始化等效,区别在于不会执行错误检查。
返回值
如果成功,pthread_rwlock_init() 会返回零。否则,将返回用于指明错误的错误号。
如果 pthread_rwlock_init() 失败,将不会初始化 rwlock,并且 rwlock 的内容是不确定的。
EINVAL:attr 或 rwlock 指定的值无效。
获取读写锁中的读锁
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
可用来向 rwlock 所引用的读写锁应用读锁。
如果写入器未持有读锁,并且没有任何写入器基于该锁阻塞,则调用线程会获取读锁。如果写入器未持有读锁,但有多个写入器正在等待该锁时,调用线程是否能获取该锁是不确定的。如果某个写入器持有读锁,则调用线程无法获取该锁。如果调用线程未获取读锁,则它将阻塞。调用线程必须获取该锁之后,才能从 pthread_rwlock_rdlock() 返回。如果在进行调用时,调用线程持有 rwlock 中的写锁,则结果是不确定的。
为避免写入器资源匮乏,允许在多个实现中使写入器的优先级高于读取器。
一个线程可以在 rwlock 中持有多个并发的读锁,该线程可以成功调用 pthread_rwlock_rdlock() n 次。该线程必须调用 pthread_rwlock_unlock() n 次才能执行匹配的解除锁定操作。
如果针对未初始化的读写锁调用 pthread_rwlock_rdlock(),则结果是不确定的。
线程信号处理程序可以处理传送给等待读写锁的线程的信号。从信号处理程序返回后,线程将继续等待读写锁以执行读取,就好像线程未中断一样。
返回值
如果成功,pthread_rwlock_rdlock() 会返回零。否则,将返回用于指明错误的错误号。
EINVAL:attr 或 rwlock 指定的值无效。
读取非阻塞读写锁中的锁
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
应用读锁的方式与 pthread_rwlock_rdlock() 类似,区别在于如果任何线程持有 rwlock 中的写锁或者写入器基于 rwlock 阻塞,则 pthread_rwlock_tryrdlock() 函数会失败。
返回值
如果获取了用于在 rwlock 所引用的读写锁对象中执行读取的锁,则 pthread_rwlock_tryrdlock() 将返回零。如果没有获取该锁,则返回用于指明错误的错误号。
EBUSY:无法获取读写锁以执行读取,因为写入器持有该锁或者基于该锁已阻塞。
写入读写锁中的锁
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
可用来向 rwlock 所引用的读写锁应用写锁。
如果没有其他读取器线程或写入器线程持有读写锁 rwlock,则调用线程将获取写锁。否则,调用线程将阻塞。调用线程必须获取该锁之后,才能从pthread_rwlock_wrlock() 调用返回。如果在进行调用时,调用线程持有读写锁(读锁或写锁),则结果是不确定的。
为避免写入器资源匮乏,允许在多个实现中使写入器的优先级高于读取器。
如果针对未初始化的读写锁调用 pthread_rwlock_wrlock(),则结果是不确定的。
线程信号处理程序可以处理传送给等待读写锁以执行写入的线程的信号。从信号处理程序返回后,线程将继续等待读写锁以执行写入,就好像线程未中断一样。
返回值
如果获取了用于在 rwlock 所引用的读写锁对象中执行写入的锁,则 pthread_rwlock_rwlock() 将返回零。如果没有获取该锁,则返回用于指明错误的错误号。
写入非阻塞读写锁中的锁
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
应用写锁的方式与 pthread_rwlock_wrlock() 类似,区别在于如果任何线程当前持有用于读取和写入的 rwlock,则pthread_rwlock_trywrlock() 函数会失败。
如果针对未初始化的读写锁调用 pthread_rwlock_trywrlock(),则结果是不确定的。
线程信号处理程序可以处理传送给等待读写锁以执行写入的线程的信号。从信号处理程序返回后,线程将继续等待读写锁以执行写入,就好像线程未中断一样。
返回值
如果获取了用于在 rwlock 引用的读写锁对象中执行写入的锁,则 pthread_rwlock_trywrlock() 将返回零。否则,将返回用于指明错误的错误号。
EBUSY:无法为写入获取读写锁,因为已为读取或写入锁定该读写锁。
解除锁定读写锁
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
可用来释放在 rwlock 引用的读写锁对象中持有的锁。
如果调用线程未持有读写锁 rwlock,则结果是不确定的。
如果通过调用 pthread_rwlock_unlock() 来释放读写锁对象中的读锁,并且其他读锁当前由该锁对象持有,则该对象会保持读取锁定状态。如果pthread_rwlock_unlock() 释放了调用线程在该读写锁对象中的最后一个读锁,则调用线程不再是该对象的属主。如果 pthread_rwlock_unlock() 释放了该读写锁对象的最后一个读锁,则该读写锁对象将处于无属主、解除锁定状态。
如果通过调用 pthread_rwlock_unlock() 释放了该读写锁对象的最后一个写锁,则该读写锁对象将处于无属主、解除锁定状态。
如果 pthread_rwlock_unlock() 解除锁定该读写锁对象,并且多个线程正在等待获取该对象以执行写入,则通过调度策略可确定获取该对象以执行写入的线程。如果多个线程正在等待获取读写锁对象以执行读取,则通过调度策略可确定等待线程获取该对象以执行写入的顺序。如果多个线程基于 rwlock 中的读锁和写锁阻塞,则无法确定读取器和写入器谁先获得该锁。
如果针对未初始化的读写锁调用 pthread_rwlock_unlock(),则结果是不确定的。
返回值
如果成功,pthread_rwlock_unlock() 会返回零。否则,将返回用于指明错误的错误号。
销毁读写锁
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
可用来销毁 rwlock 引用的读写锁对象并释放该锁使用的任何资源。
在再次调用 pthread_rwlock_init() 重新初始化该锁之前,使用该锁所产生的影响是不确定的。实现可能会导致pthread_rwlock_destroy() 将 rwlock 所引用的对象设置为无效值。如果在任意线程持有 rwlock 时调用pthread_rwlock_destroy(),则结果是不确定的。尝试销毁未初始化的读写锁会产生不确定的行为。已销毁的读写锁对象可以使用 pthread_rwlock_init() 来重新初始化。销毁读写锁对象之后,如果以其他方式引用该对象,则结果是不确定的。
返回值
如果成功,pthread_rwlock_destroy() 会返回零。否则,将返回用于指明错误的错误号。
EINVAL:attr 或 rwlock 指定的值无效。
条件变量
条件变量通过pthread_cond_t类型来表示,它的工作原理很简单,线程A阻塞在某行代码,一直wait一个cond,线程B发出一个cond,那么线程A收到cond后,代码就会被打破,可以继续往下执行。
这是个非常实用的功能,我们用传统的while(bool flag)去控制线程流程时,必须执行完整块循环体后,才能回到flag判断,这种方式控制线程停止是不灵活的,也不能实时生效,而pthread_cond_t则具备实时和灵活的特点。
初始化一个cond变量
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);
cond的初始化和mutex一样,可以动态初始化,也可以通过静态宏来初始化。
//静态初始化
static pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
//动态初始化
static pthread_cond_t cond;
pthread_cond_init(&cond, nullptr);
等待一个cond信号到来
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);
pthread_cond_wait实际包含了三个子行为:
首先释放了mutex,这样在等待cond期间,其它线程也是可以使用被mutex保护的资源的。
然后进入wait_cond阻塞阶段,一直等待cond的到来,直到其它线程通过signal发出了一个cond。
拿到cond后,线程会重新尝试锁定mutex,锁定成功后pthread_cond_wait方法才return。
超时版本的wait
int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime);
和pthread_mutex_timedlock使用方法基本一致。
发出一个cond信号
int pthread_cond_signal(pthread_cond_t *cond);
唤醒一个处于wait_cond状态的线程,如果有多个wait的线程,按等待顺序,唤醒最先开始等待的。
//wait线程,消费信号的线程
pthread_mutex_lock(&mutex);
pthread_cond_wait(&cond, &mutex);
//do something ...
pthread_mutex_unlock(&mutex);
//signal线程,生成信号的线程
pthread_mutex_lock(&mutex);
//do something ...
pthread_cond_signal(&cond);
//do something ...
pthread_mutex_unlock(&mutex);
cond变量必须配合mutex变量来使用。
cond和mutex都是为了控制对临界资源的访问,cond负责通知,mutex负责锁定。
仅有通知功能,当然不能保证多线程同步,mutex可以保证关键操作的原子性和有序性。
我们以生产者-消费者模型来举例,这和单独使用mutex时的原理是一模一样的。
//临界资源
static int count = 0;
//消费者线程,不断消耗资源
while(count == 0) //1
pthread_cond_wait(&cond); //2
count = count - 1; //5
//生产者线程,不断生产资源
count = count + 1; //3
pthread_cond_signal(&cond); //4
我们理想的情况可能是,1-2-3-4-5(没食物-等食物-生产食物-有食物-吃食物)。
而在多线程情景下,所有语句的执行顺序都是不可预测的,什么情况都可能发生。
比如1-3-4-2(没食物-生产食物-等食物),由于signal比wait执行得早,即使有食物,也不能实时收到通知。
也可能是3-4-1-1-5-5(只生产了一个食物,但两个线程同时去吃食物,count会变为负数)。
我们希望的情况是,12一起执行,不能拆散,34一起执行,不能拆散,5执行期间count不能被其它线程访问。
加上mutex之后,就能实现我们想要的目标,正确代码如下:
//临界资源
static int count = 0;
//消费者线程,不断消耗资源
pthread_mutex_lock(&mutex);
while(count == 0)
pthread_cond_wait(&cond, &mutex);
count = count - 1;
pthread_mutex_unlock(&mutex);
//生产者线程,不断生产资源
pthread_mutex_lock(&mutex);
count = count + 1;
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
给所有处于wait状态的线程发出一个cond信号
int pthread_cond_broadcast(pthread_cond_t *cond);
所有处于wait状态的线程都会获得cond,但是仍然要去竞争mutex,才能继续执行。
销毁cond变量
int pthread_cond_destroy(pthread_cond_t *cond);
和pthread_mutex_destroy使用方法基本一致
测试
将之前的实验修改为C语言版本:
nano main.c
#include nano Makefile
main: main.o
cc -o main main.o -lpthread
main.o: main.c
cc -c main.c
.PHONY:clear
clear:
rm *.o
rm main
make
./main
