Python学习——(2)通过网络爬虫获取数据
通过网络爬虫获取数据
1. 和爬虫有关的HTTP
HTTP是网络数据通信的基础。在本节中会围绕Python网络爬虫讲述常用HTTP知识点。
1.1 基于HTTP的请求处理流程
当用户在浏览器的地址栏中输入一个URL并按回车键后,浏览器会向HTTP服务器发送HTTP请求,根据请求解析并绘制界面。
在浏览器中右击,在弹出的菜单栏中选择”检查“选项命令,打开”调试“窗口,并在其中点击”Network(网络)“标签。
在浏览器的地址栏中输入“www.coblogs.com”网址,随后在“调试”窗口中选择”Network(网络)“标签中的“Name”中,下拉列表框选择www.coblogs.com项,就可以看到发出的HTTP请求了,即Request,其中最关键的要素包括Request URL、Request Method和请求头信息Request Header。
当www.coblogs.com网址对应的HTTP请求发送到对方服务器中,对方在完成一系列验证后会根据请求包含的方法(Request Method,这里是Get)和参数(本请求不包含参数)返回相应的Response,其中包含HTTP状态码、HTML页面代码以及对应的图片和js等页面要素。
1.2 HTTP请求头包含操作系统和浏览器信息
Request请求中,处除了包含转向网站的URL,在HTTP请求头(Request Header)的user-agent里包含了操作系统和浏览器信息。
![]()
对应不同版本的操作系统和浏览器,user-agent也是不同的。一些网站会检查HTTP请求头里的user-agent信息,由于来自爬虫的请求一般不会包含user-agent信息,因此能以此来判断该请求是来自于网站还是爬虫,并会对应的采取一些反爬虫的信息。在爬虫代码中,如果有必要,也需要加入user-agent,来模拟此请求怕是来自于浏览器的。
1.3 Post和Get请求方法
从上文给出的HTTP请求中,我们看到了Request Method,也就是HTTP的请求方法是GET,此外还有POST等常见的HTTP请求方法。在HTTP协议中,通过请求方法能定义参数的传送方式。
参数在URL里以问号等形式传输,这是以GET方式传递参数的。在一些登录页面里登录后,在URL中看不到任何参数,此时用户名和密码等参数是以POST的方式放在HTTP数据包中传输给对方服务器。
相比之下,用GET方式传输参数的代价更小,但会暴露参数,而且通过Get方法能提交的参数最大是2 KB,因此这种方式一般用在不用加密且数据量较小的场景。传送密码等比较私密的参数时,建议用POST方式。
1.4 HTTP常见的状态码
常见的HTTP状态码如下所示:
| 状态码 | 含 义 |
|---|---|
| 200 | 请求成功 |
| 201 | 已成功创建,比如向服务器端发送“创建用户”,若正确创建,则会返回201 |
| 301 | 永久移动,表示该HTTP请求的资源已被永久移动到新的URL位置,浏览器会自动定向到新的URL |
| 400 | 请求包含语法错误 |
| 401 | 请求未通过身份验证,通常可能是用户名或密码不对,或未包含证书或token |
| 404 | 未找到资源 |
| 500 | 服务器内部错误 |
依上而言,爬虫程序在发出HTTP请求之后,可以首先查看返回的HTTP状态码,如果返回200等表示正确的状态,就可以进一步解析页面,如果不是,就进行对应的异常处理。
2. 通过Urllib库获取网页信息
Urllib是Python的内置库,不用额外安装,其中封装了一些基于HTTP操作URL的功能。通过调用Urllib库中的方法,我们可以更高效的实现一些爬取页面信息的功能。
2.1 通过request爬取网页
在爬虫项目中,一般是用封装在Urllib库里的request模块来发送基于HTTP的URL请求并得到对应的响应信息。
"""coding = utf-8"""
import urllib.request
url = 'http://www.cnblogs.com/'
# 发送请求
# 通过request的urlopen方法,基于HTTP协议向网址发出请求,得到包含响应结果的response对象
response = urllib.request.urlopen(url)
# 判断状态码是否为200,如果是,则说明发出的请求被正确处理,并通过utf-8的格式输出响应结果
if response.getcode() == 200:
print(response.read().decode('utf-8'))
2.2 设置超时时间
通过request模块中的urlopen方法向对方服务器发送请求时,如果长时间没有得到响应,不应继续等待,应当立即终止该请求。相反,如果再继续维持的话,不经会继续消耗本地客户端和对方服务器的资源,还会让调用程序的用户在长时间的等待中得不到响应,从而降低用户体验。
在实际项目中,在调用urlopen方法时,一般会加入timeout参数来指定超时时间,该参数的单位是秒,具体的只可以依据项目的实际需求来进行调整,一般不宜过长,如果超过这个时间,服务器端还没有返回,就会抛出异常。
"""coding = utf-8"""
import urllib.request
url = "www.cnblogs.com"
# 发送请求
# 和上一段程序不同,我们这里添加了timeout,设置时间为0.1秒,此时会出现报错
# 倘若我们将timeout设置为10,报错将会消失
response = urllib.request.urlopen(url, timeout = 0.1)
if response.getcode() == 200:
print(response.read().decode('utf-8'))
这里给出代码,自行运行。运行之后的结果会提示:
urllib.error.URLError:<urlopen error timed out>
也就是说,请求发送出去之后,就过0.1秒后没有返回,就会抛出上述异常。
2.3 用URLError处理网络异常
如果出现了timeout异常,就会直接退出,根据异常处理原则,出现网络异常后,我们首先要输出异常信息,让我们了解问题出想的原因;之后才是保证程序的流程不会中断,据此,我们可以使用Urllib库中的URLError方法进行处理。
"""coding= utf-8"""
from urllib import request, error
url = "http://www.cnblogs.com"
# 向服务器发送请求
try:
response = request.urlopen(url, timeout = 0.1)
except error.URLError as e:
print(e.reason)
print("continue")
运行结果如下:

2.4 设置header属性来模拟浏览器发送请求
我们之前的例子都是通过urlopen的方法来发送HTTP请求的,在某些场景中,我们也需要向浏览器这样发送HTTP的头信息,我们把这种请求方式称之为“浏览器请求”,这样我们就可以获得预期的信息了。
"""coding = utf-8"""
import urllib.request
# 指定网页信息
url = "http://www.cnblogs.com"
# 创建一个Request类型的req对象,代表一个HTTP请求
req = urllib.request.Request(url)
# 我们加入头部信息,在HTTP请求中主要包含的是操作系统和浏览器的信息,我们可以通过User-agent获取
req.add_header("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:97.0) Gecko/20100101 Firefox/97.0")
# 我们得到网页的返回结果
data = urllib.request.urlopen(req).read()
# 打印返回的网页信息
print(data.decode("utf-8"))
具体运行结果,自行验证。
3. 通过BeautifulSoup提取页面信息
3.1 安装BeautifulSoup库
和网页页面信息提取相关的Python库有两个:一个是re库,这个库是Python的内置库,主要功能是用来封装正则表达式,不用我们额外安装;还有一个是beautifulsoup4库,这个库不是内置库,主要的功能是用来解析HTML的标签,需要我们额外安装,安装方式是在Python的终端界面(Terminal)中键入“pip install beautifulsoup4“ 或 pip3 install beautifulsoup4”。安装完成之后,我们通过“pip list” 或 “pip3 list”查看是否已经安装。
在此不再概述。
3.2 用Tag提取HTML元素和属性
了解过前端的人都知道,在HTML页面中,有非常多的标签,我们也可以称它们为元素,比如最常见的和。而元素中牙可以定义很多的属性或者是元素的值。
因此我们需要创建Tag对象提取HTML中的元素,Tag对象有两个非常重要的元素:name和attrs,name表示元素的名字,而attrs表示属性的列表。
""" coding = utf-8"""
from bs4 import BeautifulSoup
# 定义HTML的文本数据
htmlContent = """
HTML Title
Hello
"""
# 把解析好的对象放入soup
soup = BeautifulSoup(htmlContent, "html.parser")
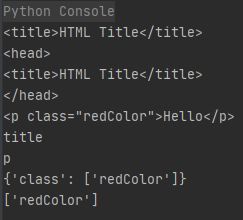
# 输出HTML Title
print(soup.title)
# 输出HTML Title
print(soup.head)
# 输出Hello
print(soup.p)
# 输出title,表示元素的名字
print(soup.title.name)
# 如下输出p,表示元素的名字
print(soup.p.name)
# 用键值对的形式输出{'class' : ['redColor']}
print(soup.p.attrs)
# 输出['redColor'],表示属性值
print(soup.p.attrs['class'])
输出结果如下:
3.3 用NavigableString提取元素值
如果想进一步获取HTML元素中的值,我们就可以调用tag.string方法,这返回的是NavigableString类型对象。
"""ciding = utf-8"""
from bs4 import BeautifulSoup
htmlcontent = """
HTML Title
"""
# 把解析好的对象放入soup中
soup = BeautifulSoup(htmlcontent, "html.parser")
# 通过soup.title.string的形式解析title元素中的值,输出HTML Title
print(soup.title.string)
# 用type得到soup.title.string的类型,输出 输出结果如下:

3.4 用Comment提取注释
当然,每一种编程语言都会说明注释方式,在HTML文本中,是通过** **的方式进行注释。在BeautifulSoup对象中,我们可以通过使用Comment对应的的进行读取注释信息。
"""coding = utf-8"""
from bs4 import BeautifulSoup
htmlContent = ''
# 将解析好的对象放入soup
soup = BeautifulSoup(htmlContent, "html.parser")
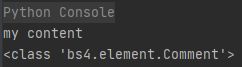
# 通过soup.元素名.string来获得元素值,也可能得到注释
comment = soup.b.string
# 如下输出my.comment
print(comment)
# 如下输出 输出结果如下:
因为在解析HTML页面时,不用关注注释,因此我们首先判断是否是NavigableString类型还是Comment类型。若是NavigableString,我们继续进行解析,若是Comment类型,则直丢弃。
4. 通过正则表达式截取信息
在实际项目中,我们一般会使用正则表达式来查找和替换某个模式的文本。在爬虫场景中,我们就会使用正规则表达式按照一定的规则来获取HTML文本中查找和截取所需的数据。
正则表达式的方法是封印在Python的re库中,我们将使用re库中提供的方法解析BeautifulSoup提取到的信息,来从中得到预期结果。
4.1 查找指定字符串
正则表达式的主要功能还是查找和替换。
"""coding = utf-8"""
# 引入所需的正则表达式re库
import re
# 定义要查找的内容(查找目标),也就是“Python”字符串
pattern = "Python"
# 定义待查找的目标字符串
val = "Now I am learning Python"
# 通过re.search方法实现查找功能,实现方式为re.search(查找目标,目标字符串)
position = re.search(pattern, val)
# 结果输出()
# 查找时要注意匹配字母大小写,大写与小写是不同的表达
print(position)
输出结果如下:
![]()
4.2 用通用字符来模糊匹配
通常情况下,精确查找(匹配)我们并不常用,更加常用的是模糊匹配。模糊匹配时我们就要使用一些通配符来实现我们的匹配效果。
| 通配符 | 含 义 |
|---|---|
| w | 用来匹配任何一个字母、数字或下划线。 |
| \W | 用来匹配除了字母、数字或下划线以外的其他任意一个字符。 |
| \d | 用来匹配任意一个十进制数字。 |
| \D | 用来匹配除了十进制数字以外的其他任意一个字符。 |
| \s | 用来匹配任意一个空白字符。 |
| \S | 用来匹配除了空白字符外的其他任意一个字符。 |
这些通配符是用来匹配一个字符的,而且小写表示”能匹配上“、大写表示”匹配除此之外的任一字符“。
"""coding = utf-8"""
# 导入正则表达式re库
import re
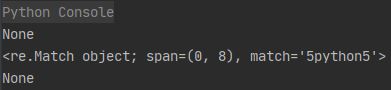
pattern = '\wpython\W'
val = '5python_'
# 输出结果:None
# 因为最后一个字符是下划线
print(re.search(pattern, val))
pattern = '\wpython\d'
val = '5python5'
# 输出结果: 输出结果如下:
4.3 通过原子表来定义匹配规则
我们还可以使用原子表来定义更加灵活的匹配规则,原子表是用**[]**来定义的,下面会给出在原子表中经常出现的元字符以及它的含义。
| 原子表 | 含 义 |
|---|---|
| ^ | 匹配字符串的开始位置 |
| $ | 匹配字符串的结束位置 |
| ? | 匹配0或1次前面的原子 |
| + | 匹配一次或多次前面的原子 |
| {n} | 前面的原子至少出现n次 |
| {n, m} | 前面的原子至少出现n次,至多出现m次 |
"""coding = utf-8"""
import re
# 匹配深沪A股和创业板股票的规则
# ^表示开始的位置,$表示结束的位置
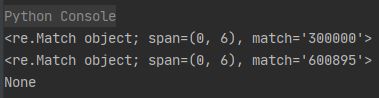
# 用[6|3|0]表示第一位需要是6或3或0,用[0-9]{5}表示之后的0到9的数字出现5次
# 综合起来,我们要寻找的是以6、3或0为开头的六位数字
stockPattern = '^[6|3|0][0-9]{5}$'
# 符合我们的显示规则,然后输出
# 输出结果: 输出结果如下: