读pytroch使用resnet18网络的代码
文章目录
- 前言
- 整体框架
-
- Moudule类的_call_impl()函数
- 前向传播代码
-
- 一、降采样卷积
-
- conv1(x)
- bn1(x)
- relu(x)
- 二、四个layer
-
- layer的定义
- layer的运行
- 三、结束部分
-
- 平均池化
- 一维化与全连接
- 反向传播
- 参数优化
- 一些参考文章:
前言
在学pytorch,读读调用resnet训练模型的源码。
代码随便找了个,来自 b站up主Zomin的这个视频,项目代码在评论区置顶。
整体框架

单独看其中一次训练:
核心代码:
# 遍历data loader里的数据,对每个数据进行训练 # 梯度归零-正向传递(计算输出)-计算损失-反向传递- for data, target in train_loader: data = data.to(device) target = target.to(device) # clear the gradients of all optimized variables(清除梯度) optimizer.zero_grad() # forward pass: compute predicted outputs by passing inputs to the model # (正向传递:通过向模型传递输入来计算预测输出) output = model(data).to(device) #(等价于output = model.forward(data).to(device) ) # calculate the batch loss(计算损失值) loss = criterion(output, target) # backward pass: compute gradient of the loss with respect to model parameters # (反向传递:计算损失相对于模型参数的梯度) loss.backward() # perform a single optimization step (parameter update) # 执行单个优化步骤(参数更新) optimizer.step() # update training loss(更新损失) train_loss += loss.item()*data.size(0)
Moudule类的_call_impl()函数
通过该方法调用模型中的对应函数。
def _call_impl(self, *input, **kwargs): forward_call = (self._slow_forward if torch._C._get_tracing_state() else self.forward) # If we don't have any hooks, we want to skip the rest of the logic in # this function, and just call forward. if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks or _global_forward_hooks or _global_forward_pre_hooks): return forward_call(*input, **kwargs)
前向传播代码
在ResNet类中的_forward_impl(self,x)函数中,完成了残差网络的一次完整运算,主要分为三个部分。
def _forward_impl(self, x): # See note [TorchScript super()] x = self.conv1(x) x = self.bn1(x) x = self.relu(x) #x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x
一、降采样卷积
原版resnet采用7X7降采样卷积,但是因为cifar-10图片很小因此代码中改为3X3卷积并取消了最大池化层,减小数据损失。
x = self.conv1(x) # 卷积层 x = self.bn1(x) # 归一化 x = self.relu(x) # relu
conv1(x)
通过Moudule类的_call_impl()函数调用到了conv2d函数中的forward函数,再在其中调用了_conv_forward函数,再在其中对是否需要padding操作进行区分:
def _conv_forward(self, input: Tensor, weight: Tensor, bias: Optional[Tensor]): if self.padding_mode != 'zeros': return F.conv2d(F.pad(input, self._reversed_padding_repeated_twice, mode=self.padding_mode), weight, bias, self.stride, _pair(0), self.dilation, self.groups) return F.conv2d(input, weight, bias, self.stride, self.padding, self.dilation, self.groups)
最终调用的F.conv2d(…)函数是底层封装的函数,在其中完成了卷积操作,提取特征值。
bn1(x)
调用到了_BatchNorm类中的forward函数,该函数首先会检查输入数据是否为四维(B,C,H,W),然后会配置一系列参数,包括exponential_average_factor,bn_training,同时会对参数num_batches_tracked自加一。最后同样将参数传递给封装好的batch_norm方法,进行计算。
relu(x)
在调用到Relu类的forward函数后,直接通过封装的relu函数进行计算。
def forward(self, input: Tensor) -> Tensor: return F.relu(input, inplace=self.inplace)
二、四个layer
layer的定义
在resnet的初始函数中通过调用_make_layer对四个layer进行了定义,根据resnet层数的变化,每个layer中的残差块的数量也会有变化。
定义:
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
在定义每一个layer的时候,指定了输出维度(通道数),残差块的数量,步幅等属性,其中block指的就是一个残差块,代码中直接使用的BasicBlock类,其中的部分层的定义为:
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
可以看到,一个残差块包括了两个卷积层,两个归一层,和一个relu计算,这些就是一个残差块中基础的计算层。
在定义layer的函数_make_layer,可以看到其根据需要创建了一个包含对应数量残差块的序列。
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
...
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
layer的运行
以其中layer1的运行为例观察layer的运行过程:
首先在上个部分可以发现layer1其实是一个包含了复数个残差块的序列,在运行到该序列的forward函数后,会便利其中的每一个残差块并将输入数据作为参数并将其输出作为下一个残差块的输入数据:
def forward(self, input):
for module in self:
input = module(input)
return input
随后程序就会进入到BasicBlock的forward方法,其中就是一个残差块的所有计算内容。
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
可以看到核心计算部分就是两个卷积+归一化的结构,以及两者之间的一个relu计算, 然后将运算结果out加上了identity也就是开始的时候保存的输入数据,并且对x的映射是否有参数(是否进行运算)。这个部分既是resnet论文中下图里F(x)+x部分的实现:
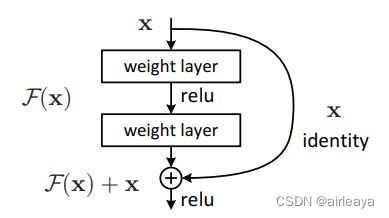
在最后对数据进行一次relu计算,这样就是一个完整的残差块的运算。
规定数量的残差块构成一个layer,几个layer组成了resnet的主要运算部分。
三、结束部分
在完成所有残差块的运算后,网络将会进行一次平均池化、一维化以及一次全连接层的运算。
平均池化
平均池化直接调用函数:
def forward(self, input: Tensor) -> Tensor:
return F.adaptive_avg_pool2d(input, self.output_size)
其中output_size就是一个元组(1,1),意味着输出每个通道都是1X1即一个像素点的特征图。在adaptive_avg_pool2d函数中再调用torch提供的函数计算。
_output_size = _list_with_default(output_size, input.size())
return torch._C._nn.adaptive_avg_pool2d(input, _output_size)
一维化与全连接
一维化的运算直接调用torch.flatten函数。
全连接层fc则通过torch提供的linear函数完成:
return torch._C._nn.linear(input, weight, bias)
如此就是正向传递的全过程。
反向传播
在对前向传播结果计算完损失值后,就进入反向传播的运算,反向传播通过求导的链式法则基于损失值反向求导来获得梯度,以辅助之后的参数优化的过程。
反向传播借助pytorch的autograd机制实现,程序会进入backward函数,进行一些参数的运算后调用_make_grads函数,将grad_tensor重新组织成对应的格式tuple(list(Tensor,…))
完成一系列参数调整后会调用Variable._execution_engine.run_backward函数进行梯度计算。
完成反向传播。
参数优化
代码中设置的是SGD优化器:
optimizer = optim.SGD(...)
然后会在优化器的param_groups中遍历‘param’的元素并将其对应的值和梯度分别加入到列表中,同时也会读取其他参数,然后回调用sgd函数,并将之前准备的参数传入:
F.sgd(params_with_grad, # 参数列表
d_p_list, # 梯度列表
momentum_buffer_list, # buffer列表
weight_decay=weight_decay,
momentum=momentum,
lr=lr,
dampening=dampening,
nesterov=nesterov)
核心代码如下:
for i, param in enumerate(params):
d_p = d_p_list[i]
if weight_decay != 0:
# grad=param+param*weight_decay
d_p = d_p.add(param, alpha=weight_decay)
if momentum != 0:
# 提取动量
buf = momentum_buffer_list[i]
if buf is None: # 分离一个新tensor确保原数据不被改动
buf = torch.clone(d_p).detach()
momentum_buffer_list[i] = buf
else:
buf.mul_(momentum).add_(d_p, alpha=1 - dampening)
if nesterov:
d_p = d_p.add(buf, alpha=momentum)
else:
d_p = buf
param.add_(d_p, alpha=-lr)# 调整参数为param+d_p*-lr
完成参数优化后更新损失,即完成了一次resnet18网络的计算。
一些参考文章:
Pytorch torch.Tensor.detach()方法的用法及修改指定模块权重的方法
训练中动态调整学习率lr,optimizer.param_groups
PyTorch】聊聊 backward 背后的代码
关于pytorch中的AdaptiveAvgPool2d
pytorch BatchNorm参数详解,计算过程
深度学习 | 反向传播详解
TORCH.TENSOR.ADD