每天学一点之Stream流相关操作
StreamAPI
一、Stream特点
Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,负责存储数据,Stream流讲的是计算,负责处理数据!”
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。每次处理都会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
二、Stream操作的步骤
1- 创建 Stream:通过一个数据源(如:集合、数组),获取一个流
2- 中间操作:每次处理都会返回一个持有结果的新Stream,即中间操作的方法返回值仍然是Stream类型的对象,因此中间操作可以是个操作链(返回值类型是Stream类型的可以一直使用.方法操作),可对数据源的数据进行n次处理,但是在终结操作前,并不会真正执行。
3- 终止操作:终止操作的方法返回值类型就不再是Stream了,因此一旦执行终止操作,就结束整个Stream操作了。一旦执行终止操作,就执行中间操作链,最终产生结果并结束Stream。

案例分析:
@Test
public void test1(){
//1、创建Stream,指定数据源来创建Stream
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("hi");
list.add("heihei");
Stream<String> stream = list.stream();
//2、加工处理
//假设我要处理的要求:把里面所有的e字母,修改为a
//Function 的抽象方法 R apply(T t)
stream = stream.map(s-> s.replace('e','a'));
//假设我要处理的要求:筛选出包含a字母的单词
//Predicate接口 boolean test(T t)
stream = stream.filter(s -> s.contains("a"));
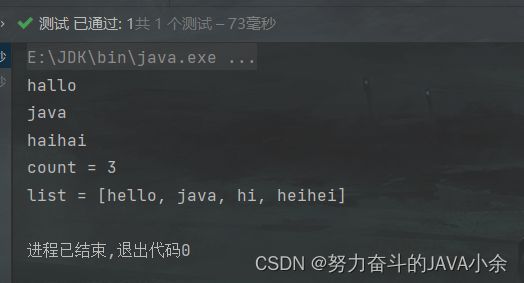
//处理,打印所有包含"a"字母的单词
//Consumer 的抽象方法 void accept(T t)
stream = stream.peek( s -> System.out.println(s));
//3、结束处理
//统计满足条件的单词的个数
// long count = stream.count();//没有这一步,前面的加工处理不执行
// System.out.println("count = " + count);
System.out.println("list = " + list);//不会修改数据源
}
没有开启3、结束处理步骤时的运行结果:
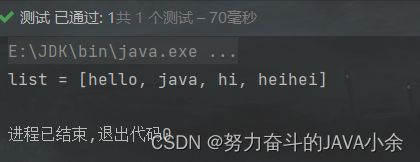
开启之后的运行结果:
三、创建StreamAPI
1、创建 Stream方式一:通过集合
Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
-
public default Stream stream() : 返回一个顺序流
-
public default Stream parallelStream() : 返回一个并行流
Stream stream = list.stream();
2、创建 Stream方式二:通过数组
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
- public static Stream stream(T[] array): 返回一个流
String[] arr = {“hello”,“world”,“java”};
Stream stream = Arrays.stream(arr);
3、创建 Stream方式三:通过Stream的of()
可以调用Stream类静态方法 of(), 通过显示值创建一个流。它可以接收任意数量的参数。
- public static Stream of(T… values) : 返回一个顺序流
Stream stringStream = Stream.of(“hello”, “world”, “java”);
4、创建 Stream方式四:创建无限流
可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
- public static Stream iterate(final T seed, final UnaryOperator f):返回一个无限流
- public static Stream generate(Supplier s) :返回一个无限流
@Test
public void test4(){
//Supplier 的抽象方法 T get()
Stream<Double> stream = Stream.generate(() -> Math.random());
//结束Stream
//Consumer 的抽象方法 void accept(T t)
stream.forEach(t-> System.out.println(t));
}
@Test
public void test5(){
//Stream iterate(final T seed, final UnaryOperator f)
//seed:种子
//UnaryOperator: T apply(T t)
// Stream stream = Stream.iterate(1, t -> t+2);
Stream<Integer> stream = Stream.iterate(1, t -> {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
return t+2;});
//结束Stream
//Consumer 的抽象方法 void accept(T t)
stream.forEach(System.out::println);
}
}
四、中间操作API
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
| 序号 | 方 法 | 描 述 |
|---|---|---|
| 1 | Stream filter(Predicate p) | 接收 Lambda , 从流中排除某些元素 |
| 2 | Stream distinct() | 筛选,通过流所生成元素的equals() 去除重复元素 |
| 3 | Stream limit(long maxSize) | 截断流,使其元素不超过给定数量 |
| 4 | Stream skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补 |
| 5 | Stream peek(Consumer action) | 接收Lambda,对流中的每个数据执行Lambda体操作 |
| 6 | Stream sorted() | 产生一个新流,其中按自然顺序排序 |
| 7 | Stream sorted(Comparator com) | 产生一个新流,其中按比较器顺序排序 |
| 8 | Stream map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| 9 | Stream mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| 10 | Stream mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| 11 | Stream mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| 12 | Stream flatMap(Function f) | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 |
/*
需求:给你一组单词,统计里面使用了几个字母,并找出这些字母
*/
/*
Stream map(Function mapper);
T类型->R类型对象
Stream flatMap(Function> mapper);
T类型->Stream流
*/
Set<String> set = Stream.of("hello", "java", "world", "xiaoyu") //把所有单词的每一个字母取出来
.flatMap(s -> Arrays.stream(s.split("|")))
.collect(Collectors.toSet());
System.out.println("字母有:"+set);
System.out.println("个数:" + set.size());
/*
字母有:[a, d, e, h, i, j, l, o, r, u, v, w, x, y]
个数:14
*/
案例:
@Test
public void test10(){
//找出最老的3个员工,年龄最大的3个员工
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee(1,"张三",23,15000));
list.add(new Employee(2,"李四",24,14000));
list.add(new Employee(3,"王五",25,18000));
list.add(new Employee(4,"赵六",22,12000));
list.add(new Employee(5,"陈前",29,12000));
list.add(new Employee(6,"林上清",27,12000));
list.add(new Employee(7,"昆昆",27,12000));
//年龄第3名的员工,年龄值不能重复
//思路:先找出年龄值是第3的值,然后再找员工
//Stream mapToInt(ToIntFunction f)
//ToIntFunction int applyAsInt(T value);
OptionalInt ageOption = list.stream()
.sorted((t1,t2)->t2.getAge()-t1.getAge())
.mapToInt(emp -> emp.getAge())
.distinct()
.skip(2)
.findFirst();
System.out.println("age = " + ageOption);
list.stream()
.filter(emp -> emp.getAge() == ageOption.getAsInt())
.forEach(t-> System.out.println(t));
}
五、终结操作API
终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void。流进行了终止操作后,不能再次使用。
| 序号 | 方法的返回值类型 | 方法 | 描述 |
|---|---|---|---|
| 1 | boolean | allMatch(Predicate p) | 检查是否匹配所有元素 |
| 2 | boolean | anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| 3 | boolean | noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| 4 | Optional | findFirst() | 返回第一个元素 |
| 5 | Optional | findAny() | 返回当前流中的任意元素 |
| 6 | long | count() | 返回流中元素总数 |
| 7 | Optional | max(Comparator c) | 返回流中最大值 |
| 8 | Optional | min(Comparator c) | 返回流中最小值 |
| 9 | void | forEach(Consumer c) | 迭代 |
| 10 | T | reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| 11 | U | reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional |
| 12 | R | collect(Collector c) | 将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法 |
Stream<Integer> stream = Stream.of(1, 2, 3, 5, 7, 9);
//判断stream中的所有数据,是否都满足 偶数的要求
//allMatch(Predicate predicate)
//Predicate boolean test(T t)
boolean result = stream.allMatch(num -> num % 2 == 0);
//判断stream中的所有数据,是否有数字满足 偶数的要求
//anyMatch(Predicate predicate)
//Predicate boolean test(T t)
boolean result = stream.anyMatch(num -> num % 2 == 0);
}
//判断stream中的所有数据,是否都不满足 偶数的要求
//noneMatch(Predicate predicate)
//Predicate boolean test(T t)
boolean result = stream.noneMatch(num -> num % 2 == 0);
//获取流中第一个元素
Optional<Integer> first = stream.findFirst();
//加工处理一下,筛选出所有的偶数
//Stream filter(Predicate predicate);
//Predicate boolean test(T t)
stream = stream.filter(num -> num%2==0);
//统计流中的元素个数
long count = stream.count();
//找出流中的最大值和最小值
//Comparator int compare(T t1 ,T t2)
Optional<Integer> max = stream.max((t1, t2) -> t1-t2);
Optional<Integer> min = stream.min((t1, t2) -> t1 - t2);
//遍历流中的数据
// void forEach(Consumer action);
//Consumer 的抽象方法 void accept(T t)
stream.forEach(t-> System.out.println(t));
//使用reduce方法找出最大值,不用max方法
//Optional reduce(BinaryOperator accumulator);
//BinaryOperator T apply(T t1, T t2)
Optional<Integer> max = stream.reduce((t1, t2) -> t1 > t2 ? t1 : t2);
//把流中的元素值累加起来
//Optional reduce(BinaryOperator accumulator);
//BinaryOperator T apply(T t1, T t2)
final Optional<Integer> sum = stream.reduce((t1, t2) -> t1 + t2);
//筛选出所有的偶数,放到一个List集合中
//中间处理
//Stream filter(Predicate predicate);
//Predicate boolean test(T t)
stream = stream.filter(t->t%2==0);
//收集这些元素到List中
List<Integer> list = stream.collect(Collectors.toList());
//筛选出所有的偶数,放到一个Set集合中
//中间处理
//Stream filter(Predicate predicate);
//Predicate boolean test(T t)
stream = stream.filter(t->t%2==0);
Set<Integer> set = stream.collect(Collectors.toSet());