基于Vision Transformer的视频哈希检索识别虚假视频
©作者 | Doreen
01 介绍
深度学习的飞速发展为图像处理带来技术突破的同时,也为虚假图像和视频的泛滥创造了条件。
利用深度学习算法伪造的图像和视频很难用肉眼区分出来,若这些图像和视频被不良分子利用,将对社会和个人造成一定的损失。
因此,寻找一个有效的算法识别伪造的图像和视频显得尤为重要。
传统的虚假视频的检测方法是利用哈希算法进行图像检索,由于相似视频的哈希编码相互联系紧密,很难区分出细节部分,这给识别工作造成了较大的困难。
针对这个问题,研究人员提出了利用基于vision Transformer模型的视频哈希检索方法有效地识别了视频中的可疑部分。
02 相关工作
目前,鉴定深度学习伪造视频的方式主要有两类,一类是通过伪造内容和源内容在视觉上的不一致性来区分出可疑部分,另一类是借助两者不同的数据特征来区分出伪造目标。
前一种方法用人眼就能清楚地识别伪造内容,但对于伪造技巧高超的目标,仅凭视觉难以准确地区分出可疑部分。
第二种方法虽不依赖视觉特征,仅利用数据特征就能识别高质量的伪造视频,但在一些特殊的情况下很难提供有效的证据证明视频的可疑部分。
因此,将视觉特性和数据结合起来成为研究人员关注的焦点。
基于深度学习模型的图像哈希网络已经在识别伪造图像中取得了较好的成果,但在视频方面的应用比较少。
因此,作者提出将Vision Transformer模型与视频哈希检索法结合起来用于标注视频中的可疑部分。
03 方法
1、训练视频的哈希中心
将高维度的数据在汉明空间中转换成紧凑的二进制哈希编码后可以高效地进行数据存储和检索。因此,有效地对视频进行哈希编码是视频鉴别的首要条件。
作者首先将1个源视频和一组伪视频送入vision Transformer模型令其生成哈希中心集。
vision Transformer的结构如图1(a)所示,包括2个Transformer编码模块和2个相似的注意力模块分支(即哈希分支和鉴别器)。
第一个Transformer编码器主要是对视频的空间信息进行编码,第二个模块则是对视频的时间信息进行编码。
编码后的数据通过其中一个分支的tanh函数生成了一个哈希编码集并将其二值化为哈希中心集,如公式(1)所示,z是哈希编码的长度,x是哈希编码。
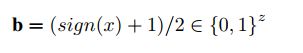
相比静态的图像,视频在随机加载的过程中生成哈希中心集比较困难。
为了解决这个问题,作者将模型的输入调整为1个源视频和2个伪视频。
为了评价哈希中心集的准确性,作者在另一个分支的鉴别器模块中借用K-means算法中的损失函数(如公式(2))来衡量每轮训练后的损失。
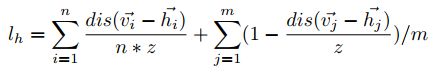
其中n是标记为不同标签的不同种类的样本数量,m是标记为同种标签的同一类别的样本数量,v是哈希中心,h是哈希编码。
该损失函数的设计思想是尽可能扩大不同类别的哈希编码差异,同时减小同一类别的哈希编码差异。
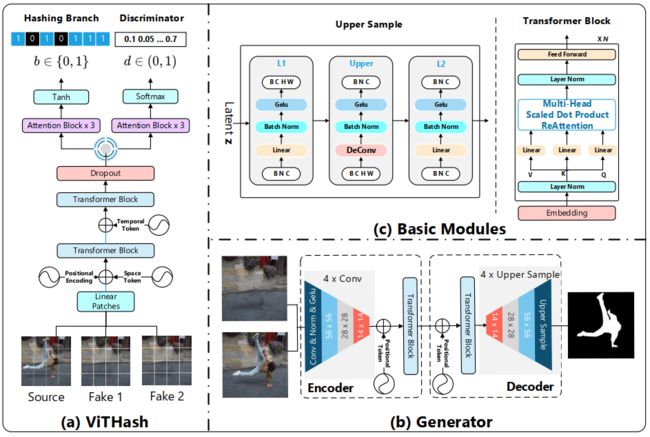
图1 ViHash与Generator模块的结构图(图片来自论文:Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake videos. https://arxiv.org/abs/2112.08117)
2、利用生成器标记视频的可疑部分
使用vision Transformer训练视频的哈希中心虽然可以识别出伪造的视频,但哈希中心缺乏视频的空间信息,难以标记伪造视频的可疑部分。
因此,作者提出使用Generator模块对伪造部分进行精确定位(即标记可疑部分)。
Generator模块包括一个Encoder和一个Decoder(如图1(b)所示),两者分别由4个卷积层组成。
为了进一步强化空间信息,在这两者之间加入了两个Transformer block(结构如图1(c)所示)。在Decoder模块中,作者使用了上采样使被标记的可疑部分的细节更丰富。
文中,作者使用了公式(3)描述了被标记的部分。
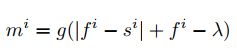
其中,i是视频的帧数,f是伪造视频,s是源视频,g(x)是一个将每帧图像的像素映射到0至255之间的函数,λ是一个与视频相关的常量(不同视频的λ不同)。
04 实验
由于伪造视频的数量有限,作者采用DeepFace-Lab,Faceswap,Faceswap-GAN,Recycle-GAN和ALAE这5种方法生成了一个包含200个视频(一共5558774帧)的DFTL(Deepfake Tracing and Localization)数据集,然后对比ViTHash模型与CSQ方法在检索相似视频方面的准确率。
为了进一步定位伪造视频的可疑区域,作者采用FGVC、DFGVI、STTN、OPN、CPNET和DVI这6种方法扩展了公开数据集DAVIS2016,生成了200个训练集和100个测试集的伪造视频(一共33550帧),并将Generator模型与DMAC方法进行了对比。
1、哈希编码的长度与鉴别准确率的关系
准确的哈希编码是识别伪造视频的前提,为了说明哈希编码的长度与实验结果的关系,作者将几种伪造的视频进行64bit至1024bit的哈希编码,并对比了哈希编码长度与鉴别结果之间的关系,如表1所示。
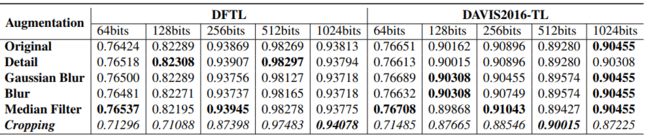
表1 哈希编码长度与鉴别准确率的关系(表格来自论文:Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake videos.https://arxiv.org/abs/2112.08117)
从表1可以清楚地看出,在相同长度的哈希编码下,鉴别各类伪造视频的准确率变化不大。
随着哈希编码的长度增加,鉴别准确率也随之提高。但到了1024bit时,准确率有所下降。
由此可以得出512bit的哈希编码是比较合适的选择。
2、与现有的其他方法的对比
与作者提出的VTL(Video Tracing and Tampering Localization)方法类似,CSQ (Central Similarity Quantization)是通过生成哈希中心对图像、视频进行检索。
从表2的结果来看,CSQ在DFTL数据集上对相似视频的鉴别率小于10%,VTL通过对哈希中心的训练则能达到98.2%。
在IOU这个指标上,VTL与DMAC方法在DFTL和DAVIS2016-TL两个数据集上都表现不佳,尤其是在DFTL数据集上,DMAC仅有0.06。
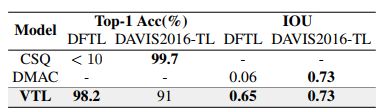
表2 VTL与现有方法的结果对比(表格来自论文:Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake videos.https://arxiv.org/abs/2112.08117)
为了进一步可视化结果,作者展示了DMAC和VTL方法对视频可疑部分的标记图像,如图2所示。
从图2中可以清楚地看出两者在DFTL数据集上都不能有效地提取出可疑目标;在DAVIS2016-TL数据集上,VTL提取的目标比DMAC有更丰富的细节。
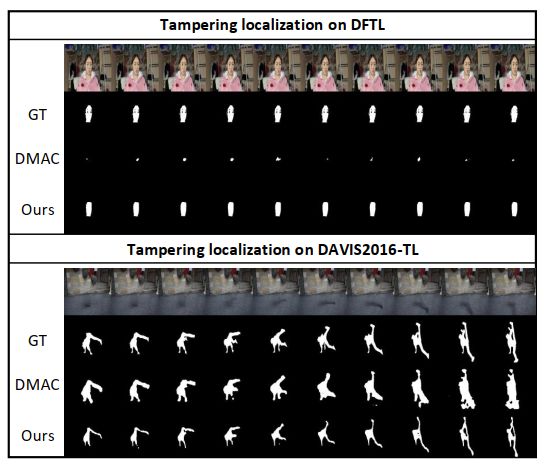
图2 标记几帧图像的可疑区域(图片来自论文:Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake videos.https://arxiv.org/abs/2112.08117)05
05 结论
在传统鉴伪的基础上,作者提出了将基于视觉特性和基于数据特性的方式结合起来的VTL方法定位视频的可疑部分。
首先通过ViTHash模型生成视频的哈希中心,并与源视频的哈希中心进行对比,鉴别是否为伪造视频。
然后利用Generator模型的卷积模块和Transformer模块进一步强化像素的空间信息,将源视频与伪造视频进行精确对比从而找到两者不同的部分。
通过实验发现,利用ViTHash+Generator的VTL方法虽然能准确地鉴定出虚假视频,但在标记其可疑部分方面则效果不佳。
为了解决这个问题,可以考虑根据源视频的内容提取特定的特征对其进行数据增广,并将其与伪造视频的类似内容进行对比,进而更精准地标记出伪造部分。
参考文献
1. Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake videos. https://arxiv.org/abs/2112.08117
2. L. Yuan et al., "Central Similarity Quantization for Efficient Image and Video Retrieval," 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3080-3089
3. P. Zhuang, H. Li, S. Tan, B. Li and J. Huang, "Image Tampering Localization Using a Dense Fully Convolutional Network," in IEEE Transactions on Information Forensics and Security, vol. 16, pp. 2986-2999, 2021
私信我领取目标检测与R-CNN/数据分析的应用/电商数据分析/数据分析在医疗领域的应用/NLP学员项目展示/中文NLP的介绍与实际应用/NLP系列直播课/NLP前沿模型训练营等干货学习资源。