CSAPP_Lab1完成过程
文章目录
- 第一章实验基本信息
-
- 1.1 目的
- 1.2 实验环境与工具
-
- 1.2.1 硬件环境
- 1.2.2 软件环境
- 1.2.3 开发工具
-
- Windows 应用下载
- Ubuntu 应用下载
- 1.3 实验预习
- 第二章 实验环境建立
-
- 2.1 Windows下 hello程序的编辑与运行
- 2.2 Ubuntu下 程序的编辑与运行
- 第三章 Windows 软硬件系统观察分析
-
- 3.1 查看计算机基本信息
- 3.2 设备管理器查看
- 3.3 隐藏分区与虚拟内存之分页文件查看
- 3.4 任务管理与资源监视
- 3.5 CPUZ下的计算机硬件详细信息
- 第4章 Linux软硬件系统观察分析(泰山服务器)
-
- 4.0连接泰山服务器
-
- 如何提交代码到泰山服务器呢
- Linux 中的一些设备查看命令
- 4.1 计算机硬件详细信息
-
- (1)Linux查看cpu信息
- (2)Linux查看memory信息
- 4.2 任务管理与资源监视
- 4.3 磁盘任务管理与资源监视
- 4.4 Linux下网络系统信息
- 第5章 Linux下的showbyte程序
-
- 5.1 源程序提交
- 5.2 关于编码格式
- 第6章 程序的生成 Cpp、Gcc、As、ld
-
- 6.1 请提交每步生成的文件
- 第7章 计算机数据类型的本质
-
- 7.1 运行sizeof.c填表
- 第8章 程序运行分析
-
- 8.1 sum的分析
-
- 1. 运行结果与原因分析
- 2. 论述改进方法
- 8.2 float的分析
-
- 1. 运行结果与原因分析
- 2. 论述编程中浮点数比较、汇总统计等应如何正确编程。
- 8.3 利用Fibonacci求黄金比例程序优化
本文中首先给出自己的答案,然后给出一些操作细节或补充知识
第一章实验基本信息
1.1 目的
1.2 实验环境与工具
1.2.1 硬件环境
X64 CPU;2.60GHz;16G RAM;512G HD Disk
HD为Hard Disk 硬盘的缩写
如何查看本机硬件设备:
1、鼠标点击桌面左下角开始按钮,找到运行,输入dxdiag,进入DirectX诊断工具界面。
这时我们可以查看系统、显示以及声音的.硬件配置情况。
2、 除此之外,我们还可以右键点击计算机,选择管理。
然后在左侧点击设备管理器,右侧窗口就会显示本机的硬件配置情况。
3、 打开 Windows 的命令行 cmd 程序
输入 diskpart,启动磁盘 diskpart 工具
在 diskpart 磁盘工具中依次输入命令
list disk
select disk 0 # 根据实际情况选择不同磁盘编号
detail disk
使用完毕后,输入如下命令推出 diskpart 磁盘工具
exit


此时我们就能看到各种参数,选择需要的即可
1.2.2 软件环境
Windows10 64位; Vmware 15;Ubuntu 20.04 LTS 64位;
优麒麟是中国国产操作系统Ubuntu Kylin的Ubuntu Kylin 14.04 LTS版本。正式发布并确定中文名为“优麒麟”。
1.2.3 开发工具
Visual Studio 2019 64位;CodeBlocks 64位;vi/vim/gedit+gcc
Windows 应用下载
WindowsCode Blocks下载教程
Ubuntu 应用下载
Ubuntu Code Blocks 下载:
sudo apt install codeblocks
了解Ubuntu PPA
LINUX常用编辑器:(Vim,Emacs,gedit,gcc,g++)
编译器配置参见
Ubuntu VScode 不能运行 C/C++ 代码解决办法:
将代码所在文件夹在 VScode 打开,即可运行(类似打开一个工程)
1.3 实验预习
上实验课前,认真预习了实验指导PPT
了解实验的目的、实验环境与软硬件工具、实验操作步骤,复习与实验有关的理论知识。
初步使用计算机管理、设备管理器、磁盘管理器、任务管理器、资源监视器、性能监视器、系统信息、系统配置、组件服务查看计算机的软硬件信息。
在Windows、Linux下分别编写 hello.c,显示“Hello 5201314-菜菜”(可换成学生自己信息)
试着编写了 showbyte.c 显示hello.c的内容:如书P2页,每行16个字符,上一行为字符,下一行为其对应的10进制形式。
试着编写了sizeof.c打印输出C语言每一个数据类型(含指针)占用空间,并在Windows、Linux的32/64模式分别运行,并比较运行结果。
第二章 实验环境建立
2.1 Windows下 hello程序的编辑与运行
easy
2.2 Ubuntu下 程序的编辑与运行
在 ubuntu 中创建并运行 C 语言文件
// 创建
touch love.c
// 用 vim 或者 gedit (有GUI界面,小白推荐)编写代码
vim love.c
// 或
gedit love.c
# include // 运行 C 文件
gcc love.c
// 此时当前文件夹下产生了一个 a.out 文件,直接运行即可
./a.out
第三章 Windows 软硬件系统观察分析
3.1 查看计算机基本信息
运行Windows管理工具中的“系统信息”程序,查看CPU、物理内存、系统目录、启动设备、页面文件等信息
3.2 设备管理器查看
3.3 隐藏分区与虚拟内存之分页文件查看
在Windows运行中搜索磁盘管理器,在磁盘管理器中能看到的,没有在计算机里显示的磁盘分区为隐藏分区,例如C盘显示了,它不是隐藏分区
在磁盘管理其中没有磁盘名为空的盘为隐藏分区
查看方法1
查看所有分区的方法
关于pagefile.sys
查看pagefile.sys大小
在桌面鼠标右击“我的电脑”–“属性”–“高级”“性能”“设置”“高级”“虚拟内存”
3.4 任务管理与资源监视
PID(进程控制符)英文全称为Process Identifier,它也属于电工电子类技术术语。
PID就是各进程的身份标识,程序一运行系统就会自动分配给进程一个独一无二的PID。进程中止后PID被系统回收,可能会被继续分配给新运行的程序。
PID一列代表了各进程的进程ID,也就是说,PID就是各进程的身份标识。
任务管理器中即可查看
3.5 CPUZ下的计算机硬件详细信息
方法一: 运行任务管理器
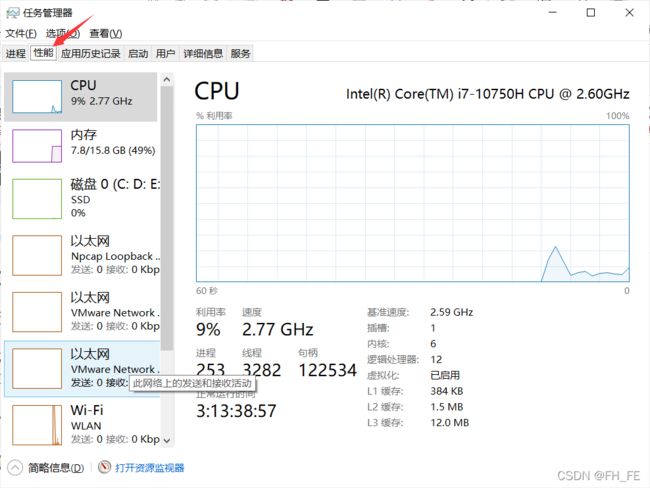
方法二:下载CPUZ查看即可
CPUZ的部分说明
第4章 Linux软硬件系统观察分析(泰山服务器)
4.0连接泰山服务器
< > 不可或缺,但是不用输入<>
[ ] 可有可无
打开Xshell7

连接服务器
ssh <用户名>@ddns.hitsplab1.xyz 22210
输入密码连接即可
如何提交代码到泰山服务器呢
上传文件
scp -P 22210 文件所在地址 用户名@ddns.hitsplab1.xyz:~/文件目录(LAB1)
// 或者为了方便,在需要提交的文件所在的文件夹,打开终端
scp -P 22210 需要提交的文件名称 用户名@ddns.hitsplab1.xyz:~/文件目录(LAB1)
下载文件
scp -P 22210 用户名@ddns.hitsplab1.xyz:/文件全名 d:/本地目录名
例子
scp -P 22210 stu_7203610000@ddns.hitsplab1.xyz:~/LAB1/LAB1.zip e:/CSAPP/
Linux 中的一些设备查看命令
参考命令
4.1 计算机硬件详细信息
(1)Linux查看cpu信息
cat /proc/cpuinfo
查看cpu型号
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看物理cpu个数
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
查看每个CPU中core(核)的个数
cat /proc/cpuinfo | grep "cpu cores" | uniq
查看逻辑CPU个数
cat /proc/cpuinfo | grep "processor" | wc -l
(2)Linux查看memory信息
运行指令参考
查看内存信息
cat /proc/meminfo
以MB为单位查看
free -m
以GB为单位查看
free -h
4.2 任务管理与资源监视
查看进程PID
ps laf
4.3 磁盘任务管理与资源监视
Ubuntu磁盘查看命令
linux下查看磁盘分区的文件系统格式
查看系统磁盘空间
df
带单位(如GB,MB等)的系统磁盘空间查看
df -h
sda表示的是你的第一块sata硬盘,sda1表示的是你的第一块sata硬盘的第一个分区。
/dev/sda是指接在SATA、SCSI第一个接口上的硬盘。
查看dev/sda 的类型,扇区等信息
sudo fdisk -l
// 可以显示出所有挂载和未挂载的分区,但不显示文件系统类型
df -T
// 只可以查看已经挂载的分区和文件系统类型。
4.4 Linux下网络系统信息
查看mac地址的方法或 ifconfig 中各参数对应的意义
ifconfig命令查看网卡MAC地址
有些Linux发行版本的MAC地址字段为HWaddr,有些Linux发行版本的MAC地址字段为ether。根据实际情况选择命令。
ether 或 HWaddr 对应mac地址
inet 对应 IPv4
inet6 对应 IPv6
/sbin/ifconfig | grep HWaddr
//或
/sbin/ifconfig | grep ether
第5章 Linux下的showbyte程序
5.1 源程序提交
# include 
吐槽一下,这虚拟机有BUG,终端框稍微缩放一下,一行就没了,¥#%#(这合理吗)

5.2 关于编码格式
本来写的代码一显示中文就乱码,想糊弄过去,但是!!!
在漂亮小姐姐的追问下,我当然得努力一下,于是乎了解了一下各种编码方式,以下是对ANSI、Unicode和UTF-8的理解
ANSI 只能标识英文字符,每个字符使用一个字节(8位)
Unicode 可以适用于所有语言,但是每个字符都要使用两个字节(16位)占用空间大
UTF-8 对于英文使用一个字节存储,对于中文使用三个字节存储
参考文章,为了避免链接失效,我就扒下来了,详情如下
UNICODE是万能编码,包含了所有符号的编码,它规定了所有符号在计算机底层的二进制的表示顺序。有关Unicode为什么会出现就不叙述了,Unicode是针对所有计算机的使用者定义一套统一的编码规范,这样计算机使用者就避免了编码转换的问题。Unicode定义了所有符号的二进制形式,也就是符号如何在计算机内部存储的,而且每个符号规定都必须使用两个字节来表示,也就是用16位二进制去代表一个符号,这样就导致了一个问题,英文编码的空间浪费,因为在ANSI中的符号都是一个字节来表示的,而使用了UNICODE编码就白白浪费了一个字节。也就代表着Unicode需要使用两倍的空间去存储相应的ANSI编码下的符号。虽然现在硬盘或者内存都很廉价,但是在网络传输中,这个问题就凸显出来了,你可以这样想想,本来1M的带宽在ANSI下可以代表10241024个字符,但是在Unicode下却只能代表10241024/2个字符。也就是1MB/s的带宽只能等价于512KB/s,这个很可怕啊。
所以为了解决符号在网络中传输的浪费问题,就出现了UTF-8编码,Unicode transfer format -8 ,后面的8代表是以8位二进制为单位来传输符号的,但是这样又导致了一个问题,虽然UTF-8可以使用一个字节来表示ANSI下的符号,但是对于其它类似汉语的符号,得需要两个字节来表示,所以计算机不知道如何去截取一个符号,也就是一个符号对应的二进制的截取开始位置和截取结束位置。所以为了解决Unicode下的ANSI符号的空间浪费和网络传输下如何截取字符的问题,UTF规定:如果一个符号只占一个字节,那么这个8位字节的第一位就为0。如果为两个字节,那么规定第一个字节的前两位都为1,然后第一个字节的第三位为0,第二个字节的前两位为10,然后如果是三个字节的话,那么第一个字节的前三位为111,第四位为0,剩余的两个字节的前两位都为10。按照这样的算法去思考一个中文字符的UTF-8是怎么表示的:一个中文字符需要两个字节来表示,两个字节一共是16位,那么UTF-8下,两个字节是不够的,因为两个字节下,第一个字节已经占据了三位:110,然后剩余的一个字节占据了两位:10,现在就只剩下11位,与Unicode下的两个字节,16位去表示任意一个字符是相悖的。所以就使用三个字节去表示非ANSI字符:三个字节下,一共是24位,第一个字节头四位是:1110,后两个字节的前两位都是:10,那么24位-8位=16位,刚好两个字节去表示Unicode下的任意一个非ANSI字符。这也就是为什么UTF-8需要使用三个字节去表示一个非ANSI字符的原因了!
大佬举例细讲

注意默认情况下Windows的编码方式不是UTF-8,读取的时候应该一次读取两个字节
附上CodeBlocks的编码方式配置
文件编码:
setting -> editor ->general setting ->encoding settings此处默认Windows-936即gbk
编译编码:
setting -> compiler -> global compiler settings -> other compiler options在框中输入:
-finput-charset=GBK
-fexec-charset=GBK
Dev只能编译各种ANSI格式的文件,所以外面导入的文件总是乱码,没有很好的解决方法,只能通过文本保存的方式申明其编码方式操作参考
华为的服务器数据溢出让我裂开 ,调了好久,呜呜呜
处理后可以输出中文及其十进制数的代码如下
# include 注意读取字符的时候,在CRLF格式下,回车是 \r\n
不读 \r 的话会会出现奇怪的换行现象,因为光标会跳转到行首
\r 会让光标到行行首

第6章 程序的生成 Cpp、Gcc、As、ld
6.1 请提交每步生成的文件
生成 hello.i 文件
gcc -E hello.c -o hello.i
// 或
cpp hello.c > hello.i
生成 hello.s 文件
gcc -S hello.c -o hello.s
// 或
cc1 hello.i -o hello.s
// cc1 很可能不在path中,用一下代码
/usr/lib/gcc/x86_64-linux-gnu/8/cc1 hello.i -o hello.s
生成 hello.o 文件
gcc -c hello.s -o hello.o
// 或
as hello.s -o hello.o
生成 hello.out文件
gcc hello.o -o hello.out
// 或
ld hello.o -lc -o hello.out
// ld 使用可能会出错
看文本文件的内容 File 文件名 看文件类型等,有一下多种方式
nano hello.c
more hello.c
cat hello.c
gedit hello.c
第7章 计算机数据类型的本质
7.1 运行sizeof.c填表
Windows中用VS可以轻易切换 X86/X64
Linux中
// 32位
gcc hello.c -m32
// 64位
gcc hello.c -m64
如果报错了

错误原因是:
系统中的gcc没有安装multilib 库;使用这个库可以在64位的机器上产生32位的程序
运行一下命令安装即可
sudo apt-get install gcc-multilib
sudo apt-get install g++-multilib
注意:sizeof()返回值为无符号整型
printf("%u", sizeof(int)); // M32
printf("%lu", sizeof(int)); // M64
第8章 程序运行分析
8.1 sum的分析
1. 运行结果与原因分析

运行结果:异常退出。
原因分析:无符号数 (len)0-1 = 4294967295;造成数组访问越界,程序异常结束。

设置访问限制,防止下标越界
运行结果:则输出整个数组所有数字之和。
原因分析:无符号数 (len)0-1 = 4294967295;程序访问了整个数组空间
2. 论述改进方法
方法一:把 i <= len – 1; 改为 i < len;
方法二:unsigned len 改为 int len
8.2 float的分析
大家都知道,在二进制世界中,浮点数是不精确的,因此直接用 < > == !=比较浮点数大小是很危险的,而且结果也是不确定的。
不考虑精度来比较浮点数大小是耍流氓。我之前的做法是基于精度对浮点数进行比较,比如,精度为2,如果 abs(a-b)<0.01,就说明 a==b。否则就是 a>b。
1. 运行结果与原因分析


产生原因分析:
第一组输入在表示为二进制时是无线循环的,而float只能表示到小数点后23位,所以要进行截断和舍入,被舍入为偶数。
第二组输入在表示为二进制时是有限的,所以表示为精确值不需要舍入,或者小数点6位之后的舍入值刚好是本身。
2. 论述编程中浮点数比较、汇总统计等应如何正确编程。
浮点数的表示是近似值,所以要尽量避免利用浮点数进行比较。
最好使用浮点数插值加精度限制来比较大小,例如
(a - b) < 1e-6
8.3 利用Fibonacci求黄金比例程序优化
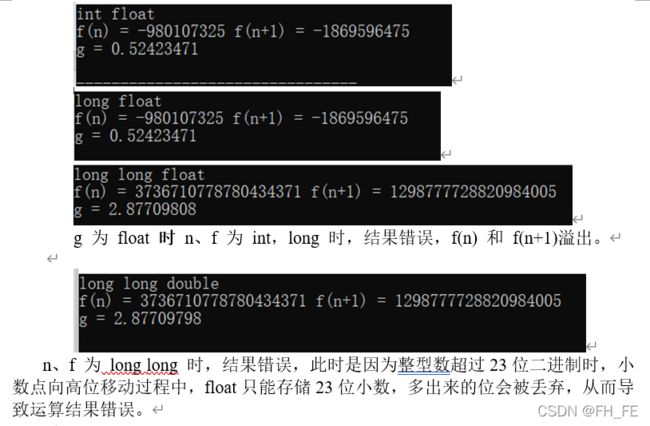
也可以将求Fibonacci的整型数改为double类型,由于浮点数的存储机制,默认去掉低位无法存储的数据,产生的结果接近真实值 0.618