机器学习--KNN(K- Nearest Neighbor)
1、KNN(K- Nearest Neighbor)法-----K最邻近法
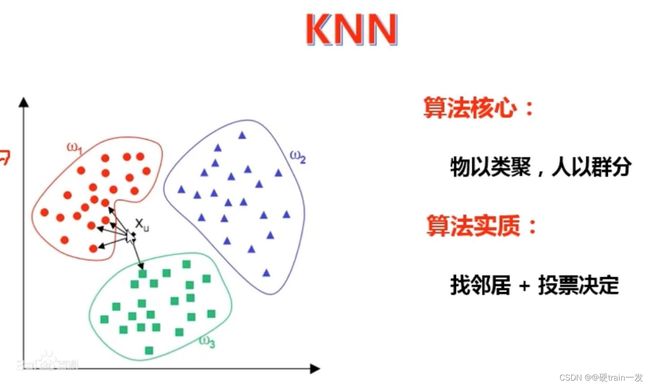
KNN算法的核心思想是:如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN方法在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
2、代码实现
KNN.py
import numpy as np
from math import sqrt
from collections import Counter
from .metrics import accuracy_score
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
"""下划线_开头,为私有变量"""
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], "the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], "the size of X_train must be at least k"
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None,\
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1],\
"the feature number of X_predict must be equal to X_train" # 特征的个数必须与训练集上的一样
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测值x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1],\
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x - x_train) ** 2)) for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def score(self, X_test, y_test):
"""根据测试集 X_test,y_test确定当前模型的准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self):
return "KNN(k=%d)" % self.k
main.py
import KNN
import numpy as np
#使用模拟数据
raw_data_x = [[3.393533211,2.331273381],
[3.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.422088941],
[7.939820817,0.791637231]
]
raw_data_y=[0,0,0,0,0,1,1,1,1,1]
#将x、y转化成np识别的数列
X_train=np.array(raw_data_x)
y_train=np.array(raw_data_y)
x = np.array([8.093607318,3.365731514])
X_predict = x.reshape(1,-1)
if __name__ == '__main__':
knn_clf=KNN.KNNClassifier(6)
knn_clf.fit(X_train,y_train)
y_predict=knn_clf.predict(X_predict)
print(y_predict[0])
Time:2023.3.12
如果上面代码对您有帮助,欢迎点个赞!!!