Ubuntu16 服务器环境配置(Nvidia CUDA Docker 深度学习)
Ubuntu16 服务器环境配置
- 基础环境配置
-
- apt软件源配置
- SSH服务开启
- git配置
- vim配置
- 挂载硬盘
- nvdia cuda 环境配置
-
- nvdia配置
- cuda和cudnn配置
- nvidia-docker2安装
- 更改docker的默认存储位置
基础环境配置
Ubuntu的基础使用环境设计软件安装源、GPU环境、Vim等方面。用户可自定义配置常用的功能以及自己独特配置的功能。
apt软件源配置
在上一代apt使用中,apt的默认源为境外的软件源,在国内使用的时候经常出现速度较慢网络连接中断的现象,当前apt已经拥有属于中国的软件源,大部分ubuntu装机的时候会直接默认安装中国的软件源,使用命令:
sudo vi /etc/apt/sources.list
返回结果如下图所示:deb http://cn.******************, 带有cn的地址链接即为中国的软件源。
 用户也可以换用其他国内镜像源,使用之前先将sources.list备份一份,使用如下命令
用户也可以换用其他国内镜像源,使用之前先将sources.list备份一份,使用如下命令
sudo cp /etc/apt/sources.list /etc/apt/sources.list.cp
国内还有很多镜像源,比如:
阿里巴巴
网易
清华
中科大
切换镜像源时一定要注意:不同系统版本能够使用的镜像源是不一样的,用户应该首先查看自己的系统版本和代号,然后再去选择对应的版本。使用如下命令:
lsb_release -a

可以看出,作者当前使用的系统是Ubuntu 16, 代号是xenial,用户按照自己的情况去上述几个镜像源中寻找自己的配置即可。找到之后替换sources.list的内容即可,替换之后使用如下命令更新:
sudo apt-get update
SSH服务开启
新装的服务器如果想要被其他用户远程访问,要首先配置SSH服务,使用如下命令:
sudo apt-get install openssh-server -y
安装之后为其他用户添加账户(name):
sudo adduser name
执行命令之后输入密码,其他信息直接回车。
如果还要为刚刚添加的用户赋予管理员权限,则使用如下命令:
sudo usermod -aG sudo name
name之前的sudo代表的是sudo的用户组,如果是想把用户添加到其他软件的用户组中,那么可以把sudo的用户组改为其他的软件用户组,例如:把用户添加到docker的用户组:
sudo usermod -aG docker name
如果刚刚已经添加了name这个用户,若这个用户想要访问docker端口,那么可以使用ip+22端口访问。
git配置
git是比较常用的代码托管工具,有必要安装一下。
sudo apt-get install git -y
vim配置
vim是linux系统中常用的文本编辑器,重装的系统默认只能使用vi,而不能使用vim,用户需要手动安装,执行如下命令:
sudo apt-get install vim -y
上述命令的安装只是最简版的vim,用户在使用过程中会遇到很多的困难,尤其是对于python开发人员而言,用户可以对vim进行更多功能的配置。
vim基础配置都是在~/.vimrc这个文件中完成。默认是没有的需要自己新建:
vim ~/.vimrc
以下是建议的.vimrc文件的基础配置部分,双引号内为注释内容:
"去掉vi的一致性"
set nocompatible
"显示行号"
set number
" 隐藏滚动条"
set guioptions-=r
set guioptions-=L
set guioptions-=b
"隐藏顶部标签栏"
set showtabline=0
"设置字体"
set guifont=Monaco:h13
syntax on "开启语法高亮"
let g:solarized_termcolors=256 "solarized主题设置在终端下的设置"
set background=dark "设置背景色"
colorscheme solarized
set nowrap "设置不折行"
set fileformat=unix "设置以unix的格式保存文件"
set cindent "设置C样式的缩进格式"
set tabstop=4 "设置table长度"
set shiftwidth=4 "同上"
set showmatch "显示匹配的括号"
set scrolloff=5 "距离顶部和底部5行"
set laststatus=2 "命令行为两行"
set fenc=utf-8 "文件编码"
set backspace=2
set mouse=a "启用鼠标"
set selection=exclusive
set selectmode=mouse,key
set matchtime=5
set ignorecase "忽略大小写"
set incsearch
set hlsearch "高亮搜索项"
set noexpandtab "不允许扩展table"
set whichwrap+=<,>,h,l
set autoread
set cursorline "突出显示当前行"
set cursorcolumn "突出显示当前列"
配置vim插件
本文只着重介绍Vundle和YouCompleteMe两个插件因为这两个插件的安装过程比较复杂一些,而其他插件的安装几乎可以算是傻瓜式的:
插件一:Vundle
1、首先需要从github上得到项目的源码,在终端下的命令如下(请自备git):
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
2、然后需要在.vimrc文件中添加一些配置才能生效:
filetype off
set rtp+=~/.vim/bundle/Vundle.vim
call vundle#begin()
Plugin 'VundleVim/Vundle.vim'
Plugin '你的插件'
call vundle#end()
filetype plugin indent on
3、在添加完.vimrc的配置后,保存并退出vim后,执行以下命令,vim就会自动下载并安装插件了:
:PluginInstall
当命令行看到Done!就代表插件安装完成了。
挂载硬盘
用户要先确定是否有硬盘未挂载上,首先要执行如下命令查看分区:
df -h
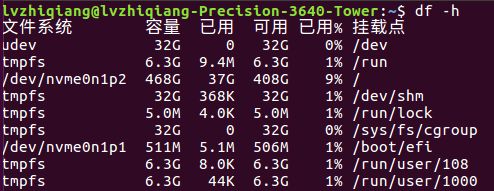
再执行以下命令查看硬盘情况:
sudo fdisk -l

由上图可知有一个3.7T的硬盘没有挂载上,需执行以下操作:
1、新建硬盘挂载的目录,执行以下代码:
sudo mkdir /data
2、初始化并格式化硬盘
sudo parted /dev/sdb mklabel gpt
sudo mkfs.ext4 /dev/sdb
 复制图中的UUID
复制图中的UUID
3、修改/etc/fstab文件,执行如下命令:
sudo vim /etc/fstab
 添加如图最后一行,UUID按照用户自己的复制内容修改。
添加如图最后一行,UUID按照用户自己的复制内容修改。
4、挂载,执行如下命令:
sudo mount -a
df -h
 如果硬盘没有在分区之中出现的话,重启系统。
如果硬盘没有在分区之中出现的话,重启系统。
nvdia cuda 环境配置
nvdia配置
无论手动安装还是自动安装,都建议先禁用Nouveau驱动,禁用方式如下:
sudo vim /etc/modprobe.d/blacklist.conf
在文本的最后两行添加如下内容:
blacklist nouveau
options nouveau modeset=0
再执行如下命令:
sudo update-initramfs -u
重启之后,执行以下命令,若没有输出则代表禁用生效:
lsmod | grep nouveau
开始安装,首先执行如下命令:
sudo ubuntu-drivers devices
如果有输出,则可以使用自动安装,再执行如下命令即可:
sudo ubuntu-drivers autoinstall
完成后重启就可以完成驱动安装。
如果没有输出,则需手动安装,操作如下:
1、首先去nvidia官网下载对应的驱动,然后保存到用户根目录(~/)
2、首先查看GPU是否支持CUDA,执行如下命令:
lspci | grep -i nvidia
3、查看linux版本
uname -m && cat /etc/*release
4、卸载原有nvidia驱动,执行如下命令:
sudo apt-get remove --purse nvidia*
5、 赋予下载的nvidia驱动可执行权限,并使用这个程序删除之前的安装信息:
sudo chmod +x ./*.run
sudo ./NVIDIA-Linux-x86_64-384.59.run --uninstall
6、禁用X-Wimdow服务,执行如下命令:
sudo service lightdm stop
关闭图形界面之后,按Ctrl+Alt+F1进入命令行界面,输入用户名和密码登录
7、使用命令行安装驱动,执行如下命令:
sudo ~/NVIDIA-Linux-x86_64-384.59.run -no-opengl-files
8、测试驱动是否安装成功,执行如下代码:
nvidia-smi
若列出GPU的信息列表,表示驱动安装成功。
cuda和cudnn配置
cuda安装
1、首先在官网上下载驱动对应的cuda文件
2、将cuda文件放在根目录(~/)下,赋予执行权限
3、执行如下命令开始安装cuda
sudo sh cuda_11.4.2_470.57.02_linux.run

输入accept,并注意不要安装driver(如下图),选择install进行安装。

5、弹出下图说明文件安装成功。
6、配置环境,在.bashrc文件中添加如下代码(注意提前检验路径是否存在!):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.4/lib64
export PATH=$PATH:/usr/local/cuda-11.4/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-11.4
7、终端运行。保存并退出文件后,执行以下代码:
source ~/.bashrc
8、执行如下代码进行检查,如果弹出下图则安装成功:
nvcc --version
 cudnn安装
cudnn安装
1、首先去官网下载对应cudnn安装包,并复制到根目录(~/)下
2、使用如下命令解压安装包:
tar -xvzf cudnn-11.4-linux-x64-v8.2.2.26.tgz
3、安装cudnn
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
nvidia-docker2安装
docker安装
安装nvidia-docker之前需要安装docker
1、下载依赖的安装包:
sudo apt install apt-transport-https ca-certificates software-properties-common curl
2、安装GPG证书:
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
3、写入软件源信息
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
4、更新并安装docker-ce
sudo apt-get -y update
sudo apt-get -y install docker-ce
nvidia-docker安装
1、添加仓库包:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
2、安装nvidia-docker2
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
3、测试容器是否能调用外层的nvidia
先下载支持cuda的镜像,执行如下命令:
sudo docker pull nvidia/cuda:11.4.2-devel-ubuntu18.04
等待安装
 安装成功
安装成功
先查看镜像及镜像id,执行如下命令:
sudo docker images
 使用下载的镜像启动容器,执行如下命令:
使用下载的镜像启动容器,执行如下命令:
sudo nvidia-docker run -it --name test f17 /bin/bash
(f17 是上图中的镜像id)
进入容器之后,执行以下命令:
nvidia-smi
 出现上图结果代表安装成功。
出现上图结果代表安装成功。
更改docker的默认存储位置
默认的docker是安装在系统分区上,正常使用的过程中,应该放置在存储容量更大的硬盘分区上。
参考教程进行更改
docker镜像与容器在linux环境下的迁移