MySQL复制详解
目录
一、复制概述
二、复制解决的问题
1、数据分布
2、负载均衡
3、备份
4、高可用性和容灾
5、MySQL升级测试
三、复制的工作流程
1、简述工作流程
2、具体工作流程
四、复制两种方式
1、基于语句的复制(Statement-Based Replication)
2、基于行的复制(Row-Based Replication)
五、复制所用到的文件
1、二进制文件
2、中继日志文件
3、备库连接到主库的信息
4、前备库复制的二进制日志和中继日志坐标
六、发送复制事件到其它slave
七、复制过滤(Replication Filters)
八、复制的常用拓扑结构
1、一主多从
2、主-主模式(Master-Master in Active-Active Mode)
3、主动-被动模式的Master-Master(Master-Master in Active-Passive Mode)
4、带从服务器的Master-Master结构(Master-Master with Slaves)
一、复制概述
(1)复制解决的基本问题是让一台服务器的数据与其他服务器保持同步。一台主库的数据可以同步到多台备库上,备库本身也可以被配置成另外一台服务器的主库。主库和备库之间可以有多种不同的组合方式
(2)mysql支持两种复制方式:基于行的复制和基于语句的复制
(3)复制通常不会增加主库的开销,主要启用二进制日志带来的开销,但出于备份或及时从奔溃中恢复的目的,这点开销是必要的。
除此之外,每个备库也会对主库增加一些负载(例如网络I/O 开销)尤其当备库请求从主库读取旧的二进制文件时,可能会造成更高的I/O 开销。
二、复制解决的问题
1、数据分布
例如不同的数据中心,即使在不稳定的网络环境下,远程复制也可以工作。
2、负载均衡
通过mysql 复制可以将读操作分布到多个不同的服务器上,实现对读密集型应用的优化,并且实现很方便,通过简单的代码修改就能实现基本的负载均衡。对于小规模的应用,可以简单地对机器名做硬编码或使用DNS轮询。
3、备份
对于备份来说,复制是一项很有意义的技术补充,但复制既不是备份也不能够取代备份
4、高可用性和容灾
复制能够帮助应用程序避免mysql单点失败,一个包含复制的设计良好的故障切换系统能够显著地缩短宕机时间。
5、MySQL升级测试
三、复制的工作流程
1、简述工作流程
(1)在主库master上把数据更改,记录到二进制日志(Binary Log)中(这些记录被称为二进制日志事件,binary log events)
(2)备库slave将主库master的日志复制到自己的中继日志(Relay Log)中
(3)备库slave读取中继日志中的事件,将其重放到自己的数据上
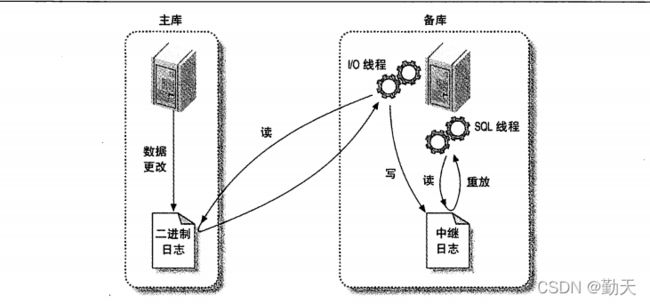
2、具体工作流程
(1) 在主库上记录二进制日志,在每个事务更新数据完成之前,master在二日志记录这些改变。
MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
(2)备库将主库的二进制日志复制到其本地的中继日志中。
- 首先备库会启动一个工作线程,称为I/O线程,I/O线程 跟主库建立一个普通的客户端连接
- 然后在主库上启动一个特殊的二进制转储线程binlog dump process,这个二进制转储线程会读取主库上二进制日志中的事件,他不会对事件进行轮询。如果该线程追赶上了主库,它将进入睡眠状态,直到主库发送信号量通知其有新的事件产生时才会被唤醒,备库I/O 线程会将接收到的事件记录到中继日志中
(3)备库的sql线程SQL slave thread执行最后一步,SQL线程从中继日志读取事件,更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。
复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
备注:I/O线程 和sql线程 都是备库 生成,I/O线程 读取主库二进制日志到自身的中继日志,sql线程读取中继日志写入到自身的数据库中
四、复制两种方式
1、基于语句的复制(Statement-Based Replication)
在mysql 5.0之前的版本中只支持基于语句的复制,此模式下 主库会记录那些造成数据更改的查询,当备库读取并重放这些事件时,实际上是把主库上执行过的SQL再执行一遍
优点:
实现简单,理论上讲,简单地记录和执行这些语句,能够让主备保持同步;二进制日志里的事件更加紧凑,一个更新GB的数据的查询仅需要几十个字节的二进制日志。而mysqlbinlog对于基于语句的日志处理十分方便。
缺点:
有些主库上的数据更新除了执行的语句外,可能还依赖其他因素,例如同一条SQL在主备执行时间可能稍微或很不相同,因此在传输的二进制日志中,除了查询语句,还包括了一些元数据信息,如当前的时间戳;另外存储过程和触发器在使用基于语句的复制模式时也可能存在问题
另外一个问题就是基于语句的复制必须是串行化的。这要求大量特殊的代码,配置。如InnoDB的next-key锁等。并不是所有的存储引擎都支持基于语句的复制。
2、基于行的复制(Row-Based Replication)
mysql5.1 开始支持基于行的复制,这种方式会将实际数据记录在二进制日志中,跟其他数据库的实现比较相像
优点:可以正确地复制每一行,任何语句都能正确工作,一些语句的效率更高
坏处:
udpate table set name = 'hello world'由于这条语句做了全表更新,使用基于行的复制开销会很大,因为每一行的数据都会被记录到二进制日志中,这使得二进制日志事件非常庞大。并且会给主库上记录日志和复制增加额外的负载,更慢的日志记录则会降低并发度
五、复制所用到的文件
1、二进制文件
mysql-bin.index当在服务器上开启二进制日志时,同时会生成一个和二进制日志同名的但以.index 作为后缀的文件,该文件用于记录磁盘上的二进制日志位置。这里的 index 并不是指表的索引,而是每一行包含了二进制文件的文件名(该文件不能被删除,否则mysql 识别不了二进制日志文件)
#例如我机器上的二进制文件
-rw-rw---- 1 mysql mysql 372 Jul 3 03:55 mysql-bin.000001
-rw-rw---- 1 mysql mysql 192 Jul 3 19:41 mysql-bin.0000022、中继日志文件
mysql-relay-bin-index这个文件是中继日志的索引文件,和mysql-bin.index 的作用类似
3、备库连接到主库的信息
master.info这个文件用于保存备库连接到主库所需要的信息,不要删除它,否则,slave重启后不能连接master。一般在备库的mysql data目录下
-rw-rw----. 1 mysql mysql 91 5月 12 02:02 master.info
-rw-rw----. 1 mysql mysql 38 5月 11 23:46 mysql-bin.index
-rw-rw----. 1 mysql mysql 351 5月 12 01:32 mysql-relay-bin.000005
-rw-rw----. 1 mysql mysql 76 5月 11 23:46 mysql-relay-bin.index
-rw-rw----. 1 mysql mysql 71 5月 12 01:32 relay-log.info4、前备库复制的二进制日志和中继日志坐标
relay-log.info这个文件包含了当前备库复制的二进制日志和中继日志坐标(同样不能删除该文件,否则重启后将无法获知从哪个位置开始复制,可能会导致重放已经执行过的语句)
六、发送复制事件到其它slave
当设置log_slave_updates时,你可以让slave扮演其它slave的master。此时,slave把SQL线程执行的事件写进行自己的二进制日志(binary log),然后,其它的slave可以获取这些事件并执行它。如下:

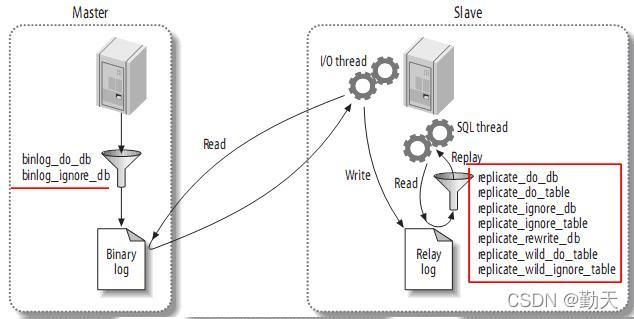
七、复制过滤(Replication Filters)
复制过滤可以让你只复制服务器中的一部分数据,有两种复制过滤:
1)在master上过滤二进制日志中的事件;
2)在slave上过滤中继日志中的事件。如下:
八、复制的常用拓扑结构
复制的体系结构有以下一些基本原则:
(1) 每个slave只能有一个master;
(2) 每个slave只能有一个唯一的服务器ID;
(3) 每个master可以有很多slave;
(4) 如果你设置log_slave_updates,slave可以是其它slave的master,从而扩散master的更新。
MySQL不支持多主服务器复制(Multimaster Replication)——即一个slave可以有多个master。但是,通过一些简单的组合,我们却可以建立灵活而强大的复制体系结构。
1、一主多从
由一个master和一个slave组成复制系统是最简单的情况。Slave之间并不相互通信,只能与master进行通信。如下:
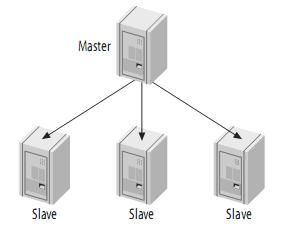
如果写操作较少,而读操作很多时,可以采取这种结构。你可以将读操作分布到其它的slave,从而减小master的压力。但是,当slave增加到一定数量时,slave对master的负载以及网络带宽都会成为一个严重的问题。 这种结构虽然简单,但是,它却非常灵活,足够满足大多数应用需求。一些建议:
(1) 不同的slave扮演不同的作用 (例如使用不同的索引,或者不同的存储引擎);
(2) 用一个slave作为备用master,只进行复制;
(3) 用一个远程的slave,用于灾难恢复;
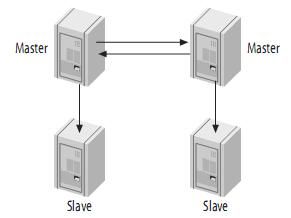
2、主-主模式(Master-Master in Active-Active Mode)
Master-Master复制的两台服务器,既是master,又是另一台服务器的slave。如图:

在第一个服务器上执行:
mysql> UPDATE tbl SET col=col + 1;在第二个服务器上执行:
mysql> UPDATE tbl SET col=col * 2;那么结果是多少呢?一台服务器是4,另一个服务器是3,但是,这并不会产生错误。
实际上,MySQL并不支持其它一些DBMS支持的多主服务器复制(Multimaster Replication),这是MySQL的复制功能很大的一个限制(多主服务器的难点在于解决更新冲突),但是,如果你实在有这种需求,你可以采用MySQL Cluster,以及将Cluster和Replication结合起来,可以建立强大的高性能的数据库平台。 但是,可以通过其它一些方式来模拟这种多主服务器的复制。
3、主动-被动模式的Master-Master(Master-Master in Active-Passive Mode)
这是master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中一个服务只能进行只读操作。如图:
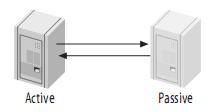
好处: 如果供写入的服务器出了故障,能迅速的切换到从服务器,
4、带从服务器的Master-Master结构(Master-Master with Slaves)
这种结构的优点就是提供了冗余。在地理上分布的复制结构,它不存在单一节点故障问题,而且还可以将读密集型的请求放到slave上。