Protobuf 语法指南简析(proto3)
Protobuf 语法指南简析(proto3)
前言
参考官方Language Guide (proto3)文档,主要是参考了官方文档。
本文介绍如何使用 protocol buffer 语法来构造 protocol buffer 数据,包括.proto文件语法,以及如何从.proto文件生成数据访问类。
Protocol Buffers语法版本为Proto3。
定义消息类型
首先,看一个非常简单的例子。定义一个搜索请求message格式,其中每个搜索请求都有一个查询字符串、感兴趣的特定结果页和每页的结果数。
syntax = "proto3";
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
第一行指定正在使用的是proto3语法:否则编译器将使用proto2。
必须是文件非空、非注释的第一行。
SearchRequest message 定义指定了三个字段(例如: string query = 1;可以理解为一个字段),每个字段对应一个要包含在此类型message 中的数据。每个字段都有一个名称和类型。
指定字段类型
在上面的示例中,所有字段都是标量类型:两个整数(page_number和result_per_page)和一个字符串(query)。但是,还可以为字段指定复合类型,包括枚举和其他消息类型。
分配字段编号
message 定义中的每个字段都有一个唯一的数字(例如: string query = 1;中的1)。这些字段编号用于以消息二进制格式标识字段,一旦message类型被使用,就不应该更改这些字段。
请注意,范围1到15中的字段编号采用一个字节进行编码,包括字段编号和字段类型。16到2047之间的字段号采用两个字节。因此,推荐使用数字1到15。
可以指定的最小字段号是1,最大字段号是536870911。不能使用19000到19999之间的数字,这些数字是为Protocol Buffers实现而保留的,如果在.proto中使用这些保留的数字之一,编译器将报错。同样,不能使用任何 reserved 的字段编号。
指定字段规则
Message 字段可以是以下字段之一:
-
singular:可以有零个或一个字段(但不能超过一个)。这是proto3语法的默认字段规则。例子中默认为singular -
repeated:可以重复任意次数(包括零),相当于list。保留重复值的顺序。
在proto3中,标量数值类型的repeated默认使用压缩编码。
添加更多Message类型
可以在单个.proto文件中定义多个消息类型。例如:
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
message SearchResponse {
...
}
添加注释
注释使用C/C++风格 / /和/*…*/语法。
/* SearchRequest represents a search query, with pagination options to
* indicate which results to include in the response. */
message SearchRequest {
string query = 1;
int32 page_number = 2; // Which page number do we want?
int32 result_per_page = 3; // Number of results to return per page.
}
保留字段
如果通过完全删除字段或将其注释掉来更新消息类型,那么用户可以在对该类型进行自己的更新时可能会重用字段号。如果他们以后加载相同.proto的旧版本,这可能会导致严重的问题,包括数据损坏、隐私错误等。为了确保不会发生这种情况,可以指定保留已删除字段的字段编号(或是名称,这也可能导致JSON序列化问题)。用户试图使用这些字段标识符,编译器将会报错。
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
string foo = 3 // 编译报错,因为‘foo’已经被标为保留字段
}
注意,不能在同一个
reserved语句中同时使用字段名和字段号。
.proto文件生成了什么?
当在.proto上运行protocol buffer 编译器时,编译器会根据选择的语言生成代码。你将会使用文件中描述的消息类型,获取和设置字段值、将消息序列化为输出流、解析来自输入流的消息等。
-
C++,编译器生成生成
.hand.cc -
Java,编译器生成一个生成
.java,其中包含一个类,以及一个用于创建消息类实例的特殊生成器类。 -
python有点不同:python编译器用.proto中每种消息类型的静态描述符生成一个模块,然后与metaclass一起使用,在运行时创建必要的python数据访问类。
-
go,编译器生成一个
.pb.go文件,文件中每个消息类型都有一个类型。 -
Ruby,编译器生成一个包含消息类型的Ruby模块的
.rb文件。 -
Objective-C,编译器从每个.proto生成一个
pbobjc.h和pbobjc.m文件,文件中描述的每个消息类型都有一个类。 -
C#,编译器从每个.proto生成一个
.cs文件,文件中描述的每个消息类型都有一个类。 -
DART,编译器会生成一个
.pb.dart文件,文件中的每种消息类型都有一个类。
标量值类型
int32 page_number = 2;中的int32叫做标量值类型

默认值
解析消息时,编码的消息若不包含特定的单个元素,则解析对象中的相应字段将设置为该字段的默认值。
-
string类型的默认值是空字符串
-
bytes类型的默认值是空字节
-
bool类型的默认值是false
-
数字类型的默认值是0
-
enum类型的默认值是第一个定义的枚举值
-
message类型(对象,如上文的SearchRequest就是message类型)的默认值与 语言 相关
-
repeated修饰的字段默认值是空列表
若字段的值等于默认值(如bool类型的字段设为false),那么它将不会被序列化,这样的设计是为了节省流量
枚举
在下面的示例中,添加了一个名为corpus的枚举,其中包含所有可能的值和一个corpus类型的字段:
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
enum Corpus {
UNIVERSAL = 0;
WEB = 1;
IMAGES = 2;
LOCAL = 3;
NEWS = 4;
PRODUCTS = 5;
VIDEO = 6;
}
Corpus corpus = 4;
}
corpus枚举的第一个常量映射到零:每个枚举定义必须包含一个作为其第一个元素映射到零的常量
- 必须有一个0值,以便我们可以使用0作为数值默认值
- 0需要是第一个元素,以便与proto2语义兼容,其中第一个枚举值始终是默认值。
可以通过为不同的枚举常量指定相同的值来定义别名。需要将allow_alias选项设置为true,否则将报错。
enum EnumAllowingAlias {
option allow_alias = true;
UNKNOWN = 0;
STARTED = 1;
RUNNING = 1;
}
enum EnumNotAllowingAlias {
UNKNOWN = 0;
STARTED = 1;
// RUNNING = 1; // 不注释的话会报错
}
-
枚举器常量必须在32位整数的范围内。枚举值使用变量编码,不推荐使用负值,效率很低。
-
可以在message定义内定义枚举,也可以在外部定义(可以在
.proto文件中的任何消息定义中重用)。还可以使用message中声明的枚举类型作为另一条消息中字段的类型,语法MessageType.EnumType。 -
当在使用一个枚举的
.proto上运行 protocol buffer编译器时,生成的代码在Java或C++将有一个对应的枚举,在Python中,EnumDescriptor 是Python的一个特殊的类,用于在运行时生成类中创建一组具有整数值的符号常量。
message Others {
SearchRequest.Groups groups = 1;
}
- 在反序列化过程中,消息中将保留无法识别的枚举值,具体反序列化消息时如何表示枚举值取决于语言。
使用其他消息类型
可以使用其他message 类型作为字段类型:
message SearchResponse {
repeated Result results = 1;
}
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
import导入
在上述例子中,Result message 类型与SearchResponse 在同一个文件中定义,如果要用作字段类型的message类型已经在另一个.proto文件中定义了可以通过导入其他.proto文件来使用它们的定义。在文件顶部添加导入语句:
import "myproject/other_protos.proto";
默认情况下,只能使用直接导入的.proto文件中的定义。但是,有时可能需要将.proto文件移动到新位置。现在,可以在旧位置放置一个虚拟的.proto文件,使用import public概念将所有导入转发到新位置,而不是直接移动.proto文件,并在一次更改中更新所有调用站点。任何导入包含import public语句的协议都可以传递地依赖import public依赖项。例如:
// new.proto
// All definitions are moved here
// old.proto
// This is the proto that all clients are importing.
import public "new.proto";
import "other.proto";
// client.proto
import "old.proto";
// You use definitions from old.proto and new.proto, but not other.proto
协议编译器使用-i/–proto_路径标志在协议编译器命令行上指定的一组目录中搜索导入的文件。如果没有给出任何标志,它将在调用编译器的目录中查找。通常,您应该将–proto_路径标志设置为项目的根目录,并对所有导入使用完全限定的名称。
嵌套
可以在一个message类型中定义另一个message类型,可以多层嵌套
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}
可以使用Parent.Type来引用嵌套的message
message SomeOtherMessage {
SearchResponse.Result result = 1;
}
更新Message类型
当proto不能满足要求的情况下,需要按照要求更新message,在不破坏任何现有代码的情况下更新消息类型,记住以下规则:
-
不要更改任何现有字段的字段编号。
-
如果添加新字段,则使用“旧”消息格式的代码序列化的任何消息仍然可以由新生成的代码解析。需要确认这些元素的默认值,以便新代码可以与旧代码生成的消息正确交互。同样,由新代码创建的消息可以由旧代码解析:旧二进制文件在解析时只忽略新字段。
-
在更新的Message类型中不再使用字段编号,可以删除字段。如果需要重命名字段,可以添加前缀“OBSOLETE_”,或者
reserved字段编号,这样就不会无意中重用该编号。 -
int32、uint32、int64、uint64和bool都是兼容的,可以在不中断向前或向后兼容性的情况下将字段从这些类型中的一种更改为另一种。 -
sint32和sint64彼此兼容,但与其他整数类型不兼容。 -
只要字节是有效的UTF-8,
string和bytes就可以兼容。 -
如果字节包含消息的编码版本,则嵌入消息与
bytes兼容。 -
fixed32与sfixed32兼容,fixed64与sfixed64兼容。 -
enum与Int32、uInt32、int64和uInt64兼容(值不匹配,则会被强转)。请注意,当消息被反序列化时,客户端代码可能会对它们进行不同的处理:例如,Message中将保留无法识别的proto3枚举类型,但是当Message被反序列化时,如何表示这些枚举类型取决于语言。int字段总是保留其值。 -
将单个值更改为新的
oneof的成员是安全的,并且与二进制兼容。如果能确定一次没有设置多个代码,那么将多个字段移动到新oneof中可能是安全的。将任何字段移动到现有的oneof是不安全的。
未知字段
未知字段是格式良好的protocol buffer序列化数据用来表示解析程序无法识别的字段。例如,当一个旧的二进制文件用新字段解析新二进制文件发送的数据时,这些新字段就变成旧二进制文件中的未知字段。
最初,Proto3消息在解析过程中总是丢弃未知字段,但在3.5版中,重新引入了保留未知字段以匹配Proto2行为。在3.5及更高版本中,解析期间会保留未知字段,并包含在序列化输出中。
Any
Any允许包装任意的message类型 ,Any包含一个任意的序列化消息(以字节为单位),以及一个充当该消息类型的全局唯一标识符并解析为该消息类型的URL。为了使用Any类型,你需要导入import google/protobuf/any.proto
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}
给定消息类型的默认类型URL为type.googleapis.com/packagename.messagename。
不同语言的实现会支持动态库以线程安全的方式去帮助封装或者解封装Any值,例如在java中,Any类型会有特殊的pack()和unpack()访问器,在C++ 有 PackFrom() 和 UnpackTo() 方法:
// Storing an arbitrary message type in Any.
NetworkErrorDetails details = ...;
ErrorStatus status;
status.add_details()->PackFrom(details);
// Reading an arbitrary message from Any.
ErrorStatus status = ...;
for (const Any& detail : status.details()) {
if (detail.Is<NetworkErrorDetails>()) {
NetworkErrorDetails network_error;
detail.UnpackTo(&network_error);
... processing network_error ...
}
}
用于处理Any类型的运行库当前正在开发。
Oneof
如果有一条包含多个字段的message ,并且在同一时间最多设置一个字段,则可以使用Oneof功能强制执行此行为并保存内存。
除了Oneof共享内存中的所有字段外,Oneof字段与常规字段类似,并且最多可以同时设置一个字段。设置Oneof任何成员将自动清除所有其他成员。可以使用特殊的case()或WhichOneof()方法检查其中一个值的设置(如果有),这取决于选择的语言。
使用Oneof
message SampleMessage {
oneof test_oneof {
string name = 4;
SubMessage sub_message = 9;
}
}
在生成的代码中,oneof 字段与常规字段具有相同的getter和setter。可以得到一个特殊的方法来检查其中一个值(如果有)是设置的。
Oneof特性
- 设置一个oneof 字段将自动清除其中一个的所有其他成员。因此,如果设置了几个字段中的一个,那么只有设置的最后一个字段仍然有一个值。
SampleMessage message;
message.set_name("name");
CHECK(message.has_name());
message.mutable_sub_message(); // Will clear name field.
CHECK(!message.has_name());
-
如果解析器在解析中有一个oneof 的多个成员,则在解析的消息中只使用看到的最后一个成员。
-
oneof 不能
repeated。 -
反射API适用于其中一个字段。
-
如果将oneof字段设置为默认值(例如,将int32 oneof字段设置为0,则将设置该oneof字段的“case”,并将序列化该值。
-
如果使用C++,请确保代码不会导致内存崩溃。以下示例代码将崩溃,因为已通过调用
set_name()方法删除了sub_消息。
SampleMessage message;
SubMessage* sub_message = message.mutable_sub_message();
message.set_name("name"); // Will delete sub_message
sub_message->set_... // Crashes here
- 同样,在C++中,如果
Swap()来交换两个oneof,每个消息将以另一个oneof情况结束:在下面的示例中,msg1将有sub_message,msg2将有name。
SampleMessage msg1;
msg1.set_name("name");
SampleMessage msg2;
msg2.mutable_sub_message();
msg1.swap(&msg2);
CHECK(msg1.has_sub_message());
CHECK(msg2.has_name());
向后兼容性问题
添加或删除其中一个字段时要小心。如果检查oneof的值返回None/NOT_SET,则可能意味着oneof尚未设置,或者已设置为oneof的其他版本中的字段。没有办法区别,因为没有办法知道未知字段是否是其中一个的成员。
标签重用问题
-
将字段移入或移出某个字段:在消息序列化和分析之后,可能会丢失某些信息(某些字段将被清除)。但是,您可以安全地将单个字段移动到的新字段中,并且如果知道只设置了一个字段,则可以移动多个字段。
-
删除oneof字段并将其添加返回:这可能会在序列化和分析消息后清除当前设置的oneof字段。
-
拆分或合并其中一个:这与移动常规字段有类似的问题。
Maps
创建关联映射作为数据定义的一部分,protocol buffers提供了一种方便的快捷方式语法:
map<key_type, value_type> map_field = N;
key_type可以是任何整数或字符串类型(除浮点类型和字节之外的任何标量类型)。请注意,枚举不是有效的key_type。value_type 可以是除另一个映射之外的任何类型。
因此,例如,如果要创建一个项目映射,其中每个Project message都与一个字符串键相关联,可以这样定义它:
map<string, Project> projects = 3;
-
Map 字段不能
repeated。 -
顺序不确定。
-
为.proto生成文本格式时,map按键排序。数字键按数字顺序排列。
-
如果存在重复的keys ,则使用最后的keys。当从文本格式分析映射时,如果有重复的keys ,解析可能会失败。
-
提供键但没有值,则字段序列化时的行为取决于语言。在C++、Java和Python中,该类型的默认值被序列化,而在其他语言中没有任何序列化。
向后兼容
map语法在等价于以下内容,在不支持映射的protocol buffers仍然可以处理数据:
message MapFieldEntry {
key_type key = 1;
value_type value = 2;
}
repeated MapFieldEntry map_field = N;
任何支持map的protocol buffer实现必须同时生成和接受上述定义可以接受的数据。
包
可以向.proto文件添加可选的包说明符,以防止协议消息类型之间的名称冲突。
package foo.bar;
message Open { ... }
在定义message 类型的字段时,可以使用包说明符:
message Foo {
...
foo.bar.Open open = 1;
...
}
包说明符影响生成代码的方式取决于所选语言:
-
在C++中,生成的类被封装在C++命名空间内。例如,
Open将位于命名空间foo::bar中。 -
在Java中,包被用作Java包,除非在.proto 文件中明确地提供了一个
option java_package包选项。 -
在python中,package指令被忽略,因为python模块是根据它们在文件系统中的位置组织的。
-
在go中,包被用作go包的名称,除非在.proto文件中显式地提供一个
option go_package。 -
在Ruby中,生成的类被封装在嵌套的Ruby名称空间中,转换为所需的Ruby大写样式(第一个字母大写;如果第一个字符不是字母,则PB_是预先准备好的)。例如,
Open将位于命名空间foo::bar中。 -
在C#中,除非在.proto文件中显式提供
option csharp_namespace,否则包在转换为PascalCase后将用作命名空间。例如,Open将位于命名空间Foo.Bar中。
包和名称解析
protocol buffer中的类型名称解析像C++一样工作:首先搜索innermost 范围,然后搜索next-innermost,等等,每个包都被认为是它的父包的“inner”。“.”(例如,.foo.bar.baz)表示从最外面的作用域开始。
protocol buffer 编译器通过分析导入的.proto文件解析所有类型名。每种语言的代码生成器都知道如何引用该语言中的每种类型,即使它有不同的作用域规则。
定义服务
如果要将消息类型与RPC(远程过程调用)系统一起使用,可以在.proto文件中定义一个RPC服务接口,protocol buffer 编译器将以所选语言生成服务接口代码和stubs。因此,例如,如果要使用接收SearchRequest并返回SearchResponse的方法定义RPC服务,可以在.proto文件中定义它,如下所示:
service SearchService {
rpc Search (SearchRequest) returns (SearchResponse);
}
JSON映射
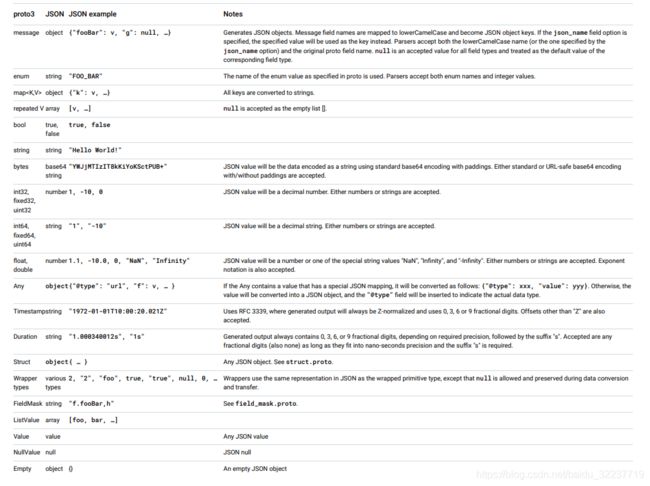
Proto3支持JSON中的规范化编码,使得在系统之间共享数据更加容易。下表按类型描述了编码。
如果JSON编码的数据中缺少一个值,或者它的值为空,那么在解析到protocol buffer.时,它将被解释为适当的默认值。如果一个字段在protocol buffer中有默认值,那么默认情况下,它将在JSON编码的数据中被省略,以节省空间。
JSON选项
Proto3 JSON实现可以提供以下选项:
-
使用默认值发出字段:在Proto3 JSON输出中,默认情况下省略具有默认值的字段。实现可以提供一个选项,用其默认值覆盖此行为和输出字段。
-
忽略未知字段:Proto3 JSON解析器默认情况下应拒绝未知字段,但提供选择在解析时忽略未知字段。
-
使用proto字段名而不是lowerCamelCase名称:默认情况下,proto3 JSON 输出器将字段名转换为lowerCamelCase,并将其用作JSON 名称。可以使用一个选项来使用proto字段名作为JSON名称。Proto3 JSON解析器需要接受转换后的lowerCamelCase名称和Proto字段名称。
-
将枚举值作为整数而不是字符串发出:默认情况下,在JSON输出中使用枚举值的名称。可以提供一个选项来使用枚举值的数值。
Options
在定义.proto文件时能够标注一系列的options。Options不会改变声明的整体含义,但可能影响在特定上下文中处理声明的方式。可用选项的完整列表在google/protobuf/descriptor.proto中定义。
有些选项是文件级选项,它们在顶级范围内写入,而不是在任何消息、枚举或服务定义内写入。有些选项是消息级选项,这意味着它们应该写在消息定义中。有些选项是字段级选项,这意味着它们应该写在字段定义中。还可以在枚举类型、枚举值、服务类型和服务方法上编写选项;但是,目前没有任何有用的选项可用于这些类型。
java_package:文件选项,即指定包名
option java_package = "com.example.foo";
java_multiple_files: 文件选项,使最外部消息、枚举和服务在包级别定义,而不是在以.proto文件命名的外部类中定义。
option java_multiple_files = true;
java_outer_classname:文件选项,即指定最外部类类名,如果不指定,那么默认的类名是以proto文件的名字作为类名的
option java_outer_classname = "Peoples"; //然后编译完成后就是生成的Peoples的类名,而不是以proto文件名作为类名了
-
optimize_for:文件选项,可以被设置为 SPEED, CODE_SIZE,或者LITE_RUNTIME,这些值将影响代码的生成-
SPEED:默认protocol buffer编译器将通过在消息类型上执行序列化、语法分析及其他通用的操作.这种代码是最优的
. -
CODE_SIZE:protocol buffer编译器将会产生最少量的类,通过共享或基于反射的代码来实现序列化、语法分析及各种其它操作.采用该方式产生的代码将比SPEED要少得多, 但是操作要相对慢些,但是生成的代码的访问方式和SPEED是一样的 -
LITE_RUNTIME:protocol buffer编译器依赖于运行时核心类库来生成代码(即采用libprotobuf-lite 替代libprotobuf).这种核心类库由于忽略了一 些描述符及反射,要比全类库小得多。
-
option optimize_for = CODE_SIZE;
-
cc_enable_arenas:文件选项,为C++生成代码使用 arena allocation -
objc_class_prefix:文件选项,设置Objective-C类前缀,该前缀前置于从该.proto生成的所有Objective-C类和枚举。没有默认的。应该使用Apple推荐的3-5个大写字符的前缀。请注意,所有2个字母的前缀都由Apple保留。 -
deprecated:文件选项,如果设置为true,则表示该字段已弃用,不应被新代码使用。在大多数语言中,这没有实际效果。在Java,这变成了@Deprecated注释。将来,其他语言特定的代码生成器可能会在字段的访问器上生成废弃的注释,访问该字段时反过来会导致警告。如果该字段未被任何人使用,并希望阻止新用户使用它 ,建议用reserved语句替换该字段声明。
int32 old_field = 6 [deprecated=true];
生成类
若要生成Java、Python、C++、Go、Ruby、ObjuleC或C代码,需要在.proto文件中定义的消息类型,需要在.proto上运行protocol buffer编译器protoc 。如果尚未安装编译器,请下载该包并按照自述文件中的说明进行操作。对于go,您还需要为编译器安装一个特殊的代码生成器插件。
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR --go_out=DST_DIR --ruby_out=DST_DIR --objc_out=DST_DIR --csharp_out=DST_DIR path/to/file.proto
IMPORT_PATH指定解析导入指令时要在其中查找.proto文件的目录。如果省略,则使用当前目录。可以通过多次传递--proto_path来指定多个目录;它们将按顺序进行搜索。-I=IMPORT_PATH可用作--proto_path的简短形式。- 可以提供一个或多个输出指令:
-
--cpp_out在DST_DIR中生成C++代码。 -
--java_out在DST_DIR中生成Java代码。 -
--python_out在DST_DIR中生成python代码。 -
--go_out在DST_DIR中生成go代码。 -
--ruby_out在DST_DIR中生成ruby代码。 -
--objc_out在DST_DIR中生成objective-c代码。 -
--csharp_out在DST_DIR中生成C代码。 -
--php_out在DST_DIR中生成php代码。
-
另外,如果DST_DIR 以.zip或.jar结尾,编译器将把输出写入给定名称的zip格式存档文件。JAVA JAR规范要求.jar输出也将得到清单文件。请注意,如果输出文件已经存在,它将被覆盖,无法将文件添加到现有文件中。
- 必须提供一个或多个
.proto文件作为输入。可以一次指定多个.proto文件。尽管文件是相对于当前目录命名的,但每个文件必须位于IMPORT_PATH之一,以便编译器可以确定其规范名称。
欢迎关注我的公众号,持续分析优质技术文章
