JAVA开发(java的多线程开发)
先理解一下什么是进程和线程
一、进程:
进程就是正在运行中的程序。对于java项目,在操作系统中,它可以表示为一个jar包,一个服务或者一个app。
二、线程:
线程就是进程中的单个顺序控制流,也可以理解成是一条执行路径。
线程是由“进程创建”的,一个进程可以创建任意多的线程,每个线程都包含一些代码。线程中的代码会同主进程或者其他线程同时运行。
-
在java语言中:
线程A和线程B,堆内存和方法区内存共享。
但是栈内存独立,一个线程一个栈。 -
假设启动10个线程,会有10个栈空间,每个栈和每个栈之间,互不干扰,各自执行各自的,这就是多线程并发。
-
java中之所以有多线程机制,目的就是为了提高程序的处理效率。
三、线程的生命周期:

线程执行状态:
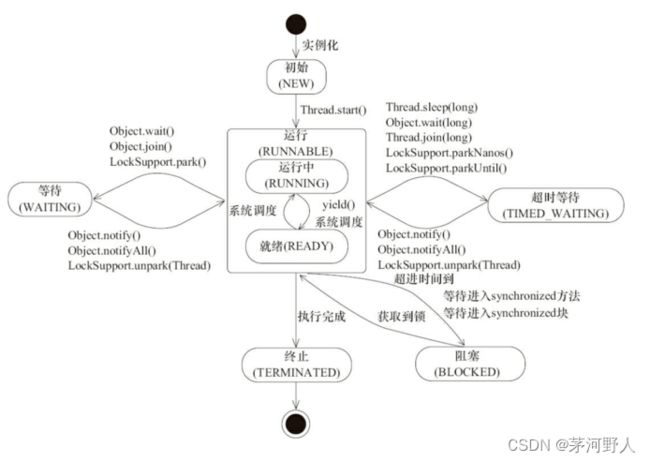
线程的控制关键词
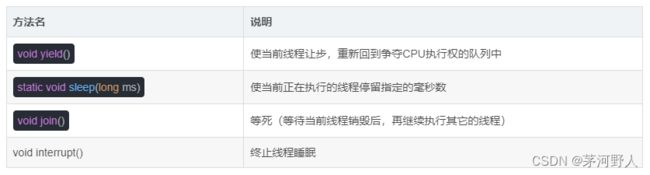
线程调用yield()方法后,线程不会回到阻塞状态,但会回到就绪状态,线程礼让不一定成功,主要看CPU调度。
每个对象都有一把锁,sleep不会释放锁!
sleep(休眠时间),当线程调用sleep()方法,线程就会进入阻塞状态,线程的sleep()方法常用于计时。
线程调用join方法即可强制执行,待该线程执行完毕后再执行其他线程,可以想象为插队,尽量少用,因为容易引起线程阻塞。
线程调用interrrupt,终止线程睡眠。
线程的优先级:
java线程的调度时通过线程调度器来按照线程的优先级来决定哪个线程优先执行,线程的优先级用数字进行表示,范围从1-10,数字越大优先级就越高。但不是优先级高的就一定会被优先执行,可能会出现性能倒置的情况,具体先执行哪个线程有CPU决定。java线程的优先级可以通过getPriority()和setPriority()方法来进行控制。
四、线程的创建方法:
1、线程创建的方式一:继承Thread类(Thread类也是实现了Runnable接口的)
(1)第一步:继承Thread类
(2)第二步:重写run()方法;run()方法的函数体即为线程体。
(3)第三步:调用start()方法;通过调用start()方法来使线程跑起来。
//线程创建的方式一:继承Thread类
//第一步:继承Thread类
public class testThread extends Thread{
//第二步:重写run()方法
@Override
public void run()
{
//线程体
for(int i=1;i<=100;i++)
{
System.out.println("我是小线程----"+i);
}
}
public static void main(String[] args){
testThread t=new testThread();
//第三步调用start()方法
t.start();
//主函数即主线程
for(int i=1;i<=200;i++)
{
System.out.println("我是主线程----"+i);
}
}
}2、实现Runnable接口
第一步:定义一个线程类实现Runnable接口。
第二步:重写run()方法,方法内部为线程执行体。
第三步:创建Thread的对象,并将Runnable接口的实现对象作为参数传入Thread的构造函数中,最后再调用start()方法进行线程的开启。
//线程创建的方式二:实现Runnable接口
//第一步:implements Runnable接口
public class testThread implements Runnable{
//第二步:重写run()方法
@Override
public void run()
{
//线程体
for(int i=1;i<=100;i++)
{
System.out.println("我是小线程----"+i);
}
}
public static void main(String[] args){
//第三步:创建Thread类,并将Runnable接口的实现类作为参数传给Thread,最后调用start()方法启动线程
testThread t=new testThread();
Thread tt=new Thread(t);
tt.start();
//主函数即主线程
for(int i=1;i<=200;i++)
{
System.out.println("我是主线程----"+i);
}
}
}
3、实现Callable接口
第一步:自定义一个MyCallable类来实现Callable接口
第二步:在MyCallable类中重写call()方法
第三步:创建FutureTask,Thread对象,并把MyCallable对象作为FutureTask类构造方法的参数传递进去,把FutureTask对象传递给Thread对象。
第四步:启动线程
这种方式的优点:可以获取到线程的执行结果。
这种方式的缺点:效率比较低,在获取t线程执行结果的时候,当前线程受阻塞,效率较低。
import java.util.concurrent.*;
//线程创建的方式三:实现Callable接口
//第一步:implements Callable接口
public class testThread implements Callable {
//第二步:重写call()方法
@Override
public Boolean call()
{
//线程体
for(int i=1;i<=100;i++)
{
System.out.println("我是小线程----"+i);
}
return true;
}
public static void main(String[] args){
testThread t1=new testThread();
//第三步:创建执行服务
ExecutorService ser = Executors.newFixedThreadPool(1);
//第四步:提交执行
Future r1=ser.submit(t1);
//主函数即主线程
for(int i=1;i<=200;i++)
{
System.out.println("我是主线程----"+i);
}
//第五步:获取结果
try {
Boolean rs1=r1.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
System.out.println("get方法出错!!!");
}
//第六步:关闭服务
ser.shutdownNow();
}
} 五使用线程池:
提前创建好多个线程,放入线程池,使用时直接获取,使用完返回池中,可以避免频繁创建和销毁,实现重复利用。
例子:
查询大量数据做一个合并。将各个查询数据的线程提交至线程池,这里使用的线程是带有返回结果的异步线程。
controller层
@Resource
private IBlogService blogService;@GetMapping("/testThredData")
public List testThredData(){
return blogService.getAllResult();
}
service层
public interface IBlogService extends IService {
//每个线程分页查询
public List getQueryData(Integer start,Integer end);
//合并线程结果
public List getAllResult();
}
serviceImpl层
@Service
public class BlogServiceImpl extends ServiceImpl implements IBlogService {
@Resource
private BlogMapper blogMapper;
@Autowired
private MultiThreadQueryUtil multiThreadQueryUtil;
//每个线程分页查询
@Override
public List getQueryData(Integer start, Integer end) {
return this.blogMapper.getQueryData(start,end);
}
//合并线程结果
@Override
public List getAllResult() {
return multiThreadQueryUtil.getMultiCombineResult();
}
}
线程池工具类
@Service
public class MultiThreadQueryUtil {
/**
* 获取多线程结果并进行结果合并
* @return
*/
public List getMultiCombineResult() {
//开始时间
long start = System.currentTimeMillis();
//返回结果
List result = new ArrayList<>();
//查询数据库总数量
// int count = workflowTaskMapper.selectCountAll();
// Map splitMap = ExcelLocalUtils.getSplitMap(count,5);
//假定总数据4条
//Callable用于产生结果
List> tasks = new ArrayList<>();
for (int i = 1; i <= 4; i++) {
//不同的线程用户处理不同分段的数据量,这样就达到了平均分摊查询数据的压力
//这里让每个线程每次查询一条数据
int startNum =i-1;//对应的数据要和i挂钩 ,否则数据不变
int endNum =i;
Callable qfe = new ThredQuery(startNum, endNum);
tasks.add(qfe);
}
try{
//定义固定长度的线程池 防止线程过多,5就够用了
// ExecutorService executorService = Executors.newFixedThreadPool(5);
//4条数据,分成4个线程来查询
ExecutorService executorService = Executors.newFixedThreadPool(4);
//Future用于获取结果
List> futures=executorService.invokeAll(tasks);
//处理线程返回结果
if(futures!=null&&futures.size() > 0){
for (Future future:futures){
result.addAll(future.get());
}
}
//关闭线程池,一定不能忘记
executorService.shutdown();
}catch (Exception e){
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("线程查询数据用时:"+(end-start)+"ms");
return result;
}
}
ThredQuery线程执行方法类
public class ThredQuery implements Callable {
public static SpringContextUtil springContextUtil = new SpringContextUtil();
private int start;
private int end;
//每个线程查询出来的数据集合
private List datas;
public ThredQuery(int start,int end) {
this.start=start;
this.end=end;
//每个线程查询出来的数据集合
// QueryService queryService= springContextUtil.getBean("queryService");
//上面获取bean实例的方法可能会失效
IBlogService blogService = springContextUtil.getBean(IBlogService.class);
List count = blogService.getQueryData(start,end);
datas = count;
}
//返回数据给Future
@Override
public List call() throws Exception {
return datas;
}
}