Kafka详解以及集成SpringBoot的详细案例
目录
Kafka相关
kafka介绍
消息系统的分类
点对点模式 Peer-to-Peer (Queue)
发布/订阅模式 Publish/Subscribe(Topic)
Kafka特点
kafka架构简介
相关术语介绍
kafka的基本原理
kafka应用场景
kafka核心API
kafka组件详解
主题和日志
Distribution(分布)
Geo-Replication(地域复制)
Producers(生产者)
Consumers(消费者)
Consumer Group
Guarantees(担保)
kafka消息传递流程
kafka选举机制
控制器(Broker)选举Leader机制
分区副本选举Leader机制
消费组(consumer group)选举机制
zookeeper的作用
1)记录和维护broker状态
2)控制器(leader)选举
3)限额权限
4)记录 ISR(已同步的副本)
5)node 和 topic 注册
6)topic 配置
kafka结合springboot具体使用
Kafka相关
kafka介绍
Kafka是Apache旗下的一款分布式流媒体平台,Kafka是一种高吞吐量、持久性、分布式的发布订阅的消息队列系统。 它最初由LinkedIn(领英)公司发布,使用Scala语言编写,与2010年12月份开源,成为Apache的顶级子项目。 它主要用于处理消费者规模网站中的所有动作流数据。动作指(网页浏览、搜索和其它用户行动所产生的数据)。
消息系统的分类
点对点模式 Peer-to-Peer (Queue)
简称PTP队列模式,也可以理解为点到点。例如单发邮件,我发送一封邮件给小徐,我发送过之后邮件会保存在服务器的云端,当小徐打开邮件客户端并且成功连接云端服务器后,可以自动接收邮件或者手动接收邮件到本地,当服务器云端的邮件被小徐消费过之后,云端就不再存储(这根据邮件服务器的配置方式而定)。
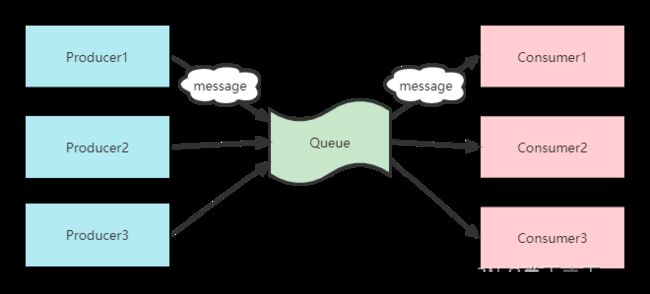
Peer-to-Peer模式工作原理:
-
消息生产者
Producer1生产消息到Queue,然后Consumer1从Queue中取出并且消费消息。 -
消息被消费后,
Queue将不再存储消息,其它所有Consumer不可能消费到已经被其它Consumer消费过的消息。 -
Queue支持存在多个Producer,但是对一条消息而言,只会有一个Consumer可以消费,其它Consumer则不能再次消费。 -
但
Consumer不存在时,消息则由Queue一直保存,直到有Consumer把它消费。
发布/订阅模式 Publish/Subscribe(Topic)
简称发布/订阅模式。例如我微博有30万粉丝,我今天更新了一条微博,那么这30万粉丝都可以接收到我的微博更新,大家都可以消费我的消息。
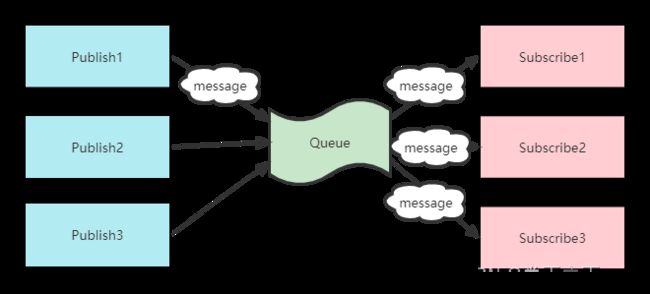
Publish/Subscribe模式工作原理:
-
消息发布者
Publisher将消息发布到主题Topic中,同时有多个消息消费者Subscriber消费该消息。 -
和PTP方式不同,发布到
Topic的消息会被所有订阅者消费。 -
当发布者发布消息,不管是否有订阅者,都不会报错信息。
-
一定要先有消息发布者,后有消息订阅者。
Kafka特点
高吞吐量:可以满足每秒百万级别消息的生产和消费。
持久性:有一套完善的消息存储机制,确保数据高效安全且持久化。
分布式:基于分布式的扩展;Kafka的数据都会复制到几台服务器上,当某台故障失效时,生产者和消费者转而使用其它的Kafka。
可扩展性: kafka集群支持热扩展
kafka架构简介

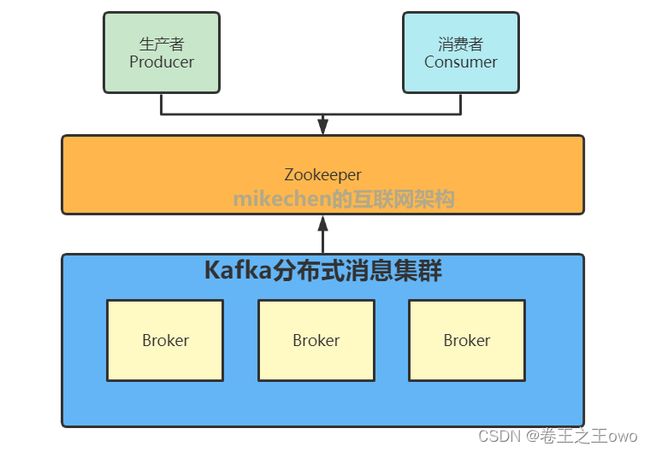
我们可以看到上图,Broker和Consumer有使用到ZooKeeper,而Producer并没有使用到ZooKeeper,因为Kafka从0.8版本开始,Producer并不需要根据ZooKeeper来获取集群状态,而是在配置中指定多个Broker节点进行发送消息,同时跟指定的Broker建立连接,来从该Broker中获取集群的状态信息,这是Producer可以知道集群中有多少个Broker是否在存活状态,每个Broker上的Topic有多少个Partition,Prodocuer会讲这些元信息存储到Producuer的内存中。如果Producoer像集群中的一台Broker节点发送信息超时等故障,Producer会主动刷新该内存中的元信息,以获取当前Broker集群中的最新状态,转而把信息发送给当前可用的Broker,当然Prodocuer也可以在配置中指定周期性的去刷新Broker的元信息以更新到内存中。 注意:只有Broker和ZooKeeper才是服务,而Producer和Consumer只是Kafka的SDK罢了
相关术语介绍
| 名词 | 解释 |
|---|---|
| Producer | 消息和数据的生产者,主要负责生产Push消息到指定Broker的Topic中。 |
| Broker | Kafka节点就是被称为Broker,Broker主要负责创建Topic,存储Producer所发布的消息,记录消息处理的过程,现是将消息保存到内存中,然后持久化到磁盘。 |
| Topic | 同一个Topic的消息可以分布在一个或多个Broker上,一个Topic包含一个或者多个Partition分区,数据被存储在多个Partition中。 |
| replication-factor | 复制因子;这个名词在上图中从未出现,在我们下一章节创建Topic时会指定该选项,意思为创建当前的Topic是否需要副本,如果在创建Topic时将此值设置为1的话,代表整个Topic在Kafka中只有一份,该复制因子数量建议与Broker节点数量一致。 |
| Partition | 分区;在这里被称为Topic物理上的分组,一个Topic在Broker中被分为1个或者多个Partition,也可以说为每个Topic包含一个或多个Partition,(一般为kafka节. 点数CPU的总核心数量)分区在创建Topic的时候可以指定。分区才是真正存储数据的单元。 |
| Consumer | 消息和数据的消费者,主要负责主动到已订阅的Topic中拉取消息并消费,为什么Consumer不能像Producer一样的由Broker去push数据呢?因为Broker不知道Consumer能够消费多少,如果push消息数据量过多,会造成消息阻塞,而由Consumer去主动pull数据的话,Consumer可以根据自己的处理情况去pull消息数据,消费完多少消息再次去取。这样就不会造成Consumer本身已经拿到的数据成为阻塞状态。 |
| ZooKeeper | ZooKeeper负责维护整个Kafka集群的状态,存储Kafka各个节点的信息及状态,实现Kafka集群的高可用,协调Kafka的工作内容。 |
kafka的基本原理
我们将消息的发布(publish)称作 producer,将消息的订阅(subscribe)表述为 consumer,将中间的存储阵列称作 broker(代理),这样就可以大致描绘出这样一个场面:
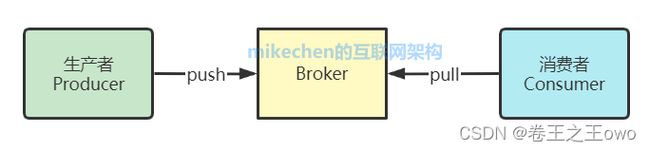
生产者将数据生产出来,交给 broker 进行存储,消费者需要消费数据了,就从broker中去拿出数据来,然后完成一系列对数据的处理操作。

多个 broker 协同合作,producer 和 consumer 部署在各个业务逻辑中被频繁的调用,三者通过 zookeeper管理协调请求和转发,这样一个高性能的分布式消息发布订阅系统就完成了。
图上有个细节需要注意,producer 到 broker 的过程是 push,也就是有数据就推送到 broker,而 consumer 到 broker 的过程是 pull,是通过 consumer 主动去拉数据的。
kafka应用场景
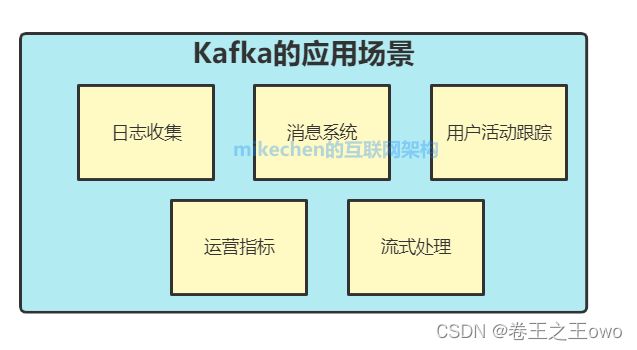
1.日志收集
一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
2.消息系统
解耦和生产者和消费者、缓存消息等。
3.用户活动跟踪
Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
4.运营指标
Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
5.流式处理
比如spark streaming和storm
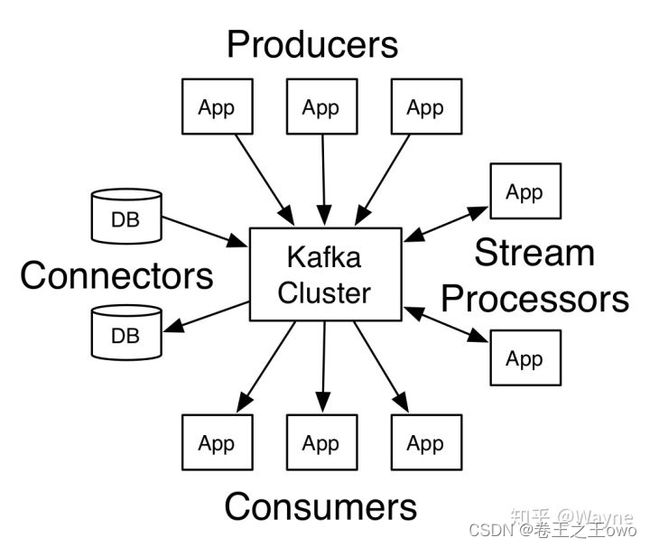
kafka核心API
-
Producer API:生产者API允许应用程序将一组记录发布到一个或多个Kafka Topic中。
-
Consumer API:消费者API允许应用程序订阅一个或多个Topic,并处理向他们传输的记录流。
-
Streams API:流API允许应用程序充当流处理器,从一个或者多个Topic中消费输入流,并将输出流生成为一个或多个输出主题,从而将输入流有效地转换为输出流。
-
Connector API:连接器API允许构建和运行可重用的生产者或消费者,这些生产者或消费者将Kafka Topic连接到现有的应用程序或数据系统。例如:连接到关系数据库的连接器可能会捕获对表的每次更改。
kafka组件详解
主题和日志
主题和日志官方被称为是Topic and log。 Topic是记录发布到的类别或者订阅源的名称,Kafka的Topic总是多用户的;也就是说,一个Topic可以有零个、一个或者多个消费者订阅写入它的数据。 每个Topic Kafka集群都为一个Partition分区日志,如下图所示:
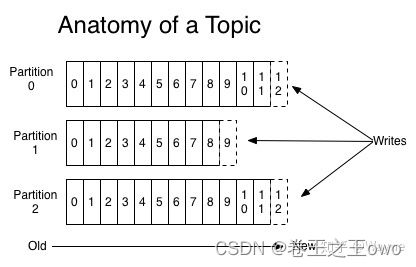
每个Partition分区都是一个有序的记录序列(不可变),如果有新的日志会按顺序结构化添加到末尾,分区中的记录每个都按顺序的分配一个ID号,称之为偏移量,在整个Partition中具有唯一性。如上图所示,有Partition、Partition1、Partition2,其中日志写入的顺序从Old到New,ID号从0-12等。
Kafka集群发布过的消息记录会被持久化到硬盘中,无论该消息是否被消费,发布记录都会被Kafka保留到硬盘当中,我们可以设置保留期限。例如,如果保留策略我们设置为两天,则在发布记录的两天内,该消息可供使用,之后则被Kafka丢弃以释放空间,Kafka的性能在数据大小方面是非常出色的,可以长时间保留数据不成问题。

实际上,以消费者为单位地保留的唯一元数据是消费者在日志中的偏移或位置。这个偏移量由消费者控制的:消费者通常会在读取记录时线性地推进偏移量,但事实上,由于消费者的位置时由消费者控制的,所以它可以按照自己喜欢的任何顺序进行消费记录。例如,消费者可以重置之前的偏移量来处理之前的数据,或者直接从最新的偏移量开始消费。 这些功能的组合意味着Kafka消费者非常的不值一提,他们可以很随便,即使这样,对集群或者其他消费者没有太大影响。例如:可以使用命令工具来“tail”任何Topic的内容,而不会更改任何现有使用者所使用的内容。
日志中分区有几个用途。首先,他们允许日志的大小超出适合单台服务器的大小,每个单独的分区必须适合托管它的服务器,但是一个主题可能有许多分区,因此它可以处理任意数量的数据,其次,他们作为并行的单位-更多的是在一点上。
Distribution(分布)
日志Partition分区分布在Kafka集群中的服务器上,每台服务器都处理数据并请求共享分区。为了实现容错,每个Partition分区被复制到多个可配置的Kafka集群中的服务器上。
名词介绍:
leader:领导者
followers:追随者
每个Partition分区都有一个leader(领导者)服务器,是每个Partition分区,假如我们的Partition1分区分别被复制到了三台服务器上,其中第二台为这个Partition分区的领导者,其它两台服务器都会成为这个Partition的followers(追随者)。其中Partition分片的leader(领导者)处理该Partition分区的所有读和写请求,而follower(追随者)被动地复制leader(领导者)所发生的改变,如果该Partition分片的领导者发生了故障等,两个follower(追随者)中的其中一台服务器将自动成为新的leader领导者。每台服务器都充当一些分区的leader(领导者)和一些分区的follower(追随者),因此集群内的负载非常平衡。
注意:上面讲的
leader和follower仅仅是每个Partition分区的领导者和追随者,并不是我们之前学习到的整个集群的主节点和备节点,希望大家不要混淆。
Geo-Replication(地域复制)
Kafka Mirrormaker为集群提供地域复制支持,使用MirrorMaker,可以跨多个机房或云端来复制数据,可以在主动/被动方案中使用它进行备份和恢复;在主动方案中,可以使数据更接近用户,或支持数据位置要求。
Producers(生产者)
生产者将数据发布到他们选择的Topic,生产者负责选择分配给Topic中的哪个分区的记录。这可以通过循环方式来完成,只是为了负载均衡,或者可以根据一些语义分区函数(比如基于记录中的某个键)来完成。
Consumers(消费者)

名词介绍
Consumers:消费者
Consumers Group:消费者组
Consumers Group name:消费者组名
Consumers使用Consumers Group name标记自己,并且发布到Topic的每个记录被传递到每个订阅Consumers Group中的一个Consumers实例,Consumers实例可以在单独的进程中,也可以在不同的机器,如果所有Consumers实例具有相同的Consumers Group,则记录将有效地在Consumers上进行负载均衡。
如果所有Consumers实例在不同的Consumers Group中,则每个记录将广播到所有Consumers进程中。
两个Kafka Cluster,托管了四个Partition(分区),从P0-P3,包含两个Consumers Group分别是Consumer Group A和Consumer Group B,Consumners Group A有两个Consumers实例,B有四个Consumers实例。也就是消费者A组有两个消费者,B组有四个消费者。 然后,更常见的是,我们发现Topic有少量的Consumers Group,每个消费者对应一个用户组,每个组有许多消费者实例组成,用于可伸缩和容错,这只不过是发布/订阅语义,其中订阅者是一组消费者,而不是单个进程。
在Kfaka中实现消费者的方式是通过在消费者实例上划分日志中的Partition分区,以便每个实例在任何时间点都是分配的“相同份额”,维护消费者组成功资格的过程由Kafka动态协议实现,如果新的消费者实例加入该消费者组,新消费者实例将从该组的其它成员手里接管一些分区;如果消费者实例故障,其分区将分发给其余消费者实例。
Kafka仅提供分区内记录的总顺序,而不是Topic中不同分区之间的记录。对于大多数应用程序而言,按分区排序和按键分许数据的能力已经足够,但是如果你需要记录总顺序,则可以使用只有一个分区的Topic来实现,尽管这意味着每个消费者组只有一个消费者进程。
Consumer Group
我们开始处有讲到消息系统分类:P-T-P模式和发布/订阅模式,也有说到我们的Kafka采用的就是发布订阅模式,即一个消息产生者产生消息到Topic中,所有的消费者都可以消费到该条消息,采用异步模型;而P-T-P则是一个消息生产者生产的消息发不到Queue中,只能被一个消息消费者所消费,采用同步模型 其实发布订阅模式也可以实现P-T-P的模式,即将多个消费者加入一个消费者组中,例如有三个消费者组,每个组中有3个消息消费者实例,也就是共有9个消费者实例,如果当Topic中有消息要接收的时候,三个消费者组都会去接收消息,但是每个人都接收一条消息,然后消费者组再将这条消息发送给本组内的一个消费者实例,而不是所有消费者实例,到最后也就是只有三个消费者实例得到了这条消息,当然我们也可以将这些消费者只加入一个消费者组,这样就只有一个消费者能够获得到消息了。
Guarantees(担保)
在高级别的Kafka中提供了以下保证:
-
生产者发送到特定Topic分区的消息将按照其发送顺序附加。也就是说,如果一个Producers生产者发送了M1和M2,一般根据顺序来讲,肯定是先发送的M1,随后发送的M2,如果是这样,假如M1的编号为1,M2的编号为2,那么在日志中就会现有M1,随后有M2。
-
消费者实例按照他们存储在日志中的顺序查看记录。
-
对于具有复制因子N的Topic,Kafka最多容忍N-1个服务器故障,则不会丢失任何提交到日志的记录。
kafka消息传递流程
Producer在发布消息到某个Partition时,先通过Zookeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW(即offset)并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。Consumer读消息也是从Leader读取,只有被commit过的消息(offset低于HW的消息)才会暴露给Consumer。
具体步骤总结下来如下:
-
producer 先从 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 leader
-
producer 将消息发送给该 leader
-
leader 将消息写入本地 log
-
followers 从 leader pull 消息,写入本地 log 后向leader 发送 ACK
-
leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset)并向 producer 发送 ACK
kafka选举机制
控制器(Broker)选举Leader机制
所谓控制器就是一个Borker,在一个kafka集群中,有多个broker节点,但是它们之间需要选举出一个leader,其他的broker充当follower角色。集群中第一个启动的broker会通过在zookeeper中创建临时节点/controller来让自己成为控制器,其他broker启动时也会在zookeeper中创建临时节点,但是发现节点已经存在,所以它们会收到一个异常,意识到控制器已经存在,那么就会在zookeeper中创建watch对象,便于它们收到控制器变更的通知。
-
那么如果控制器由于网络原因与zookeeper断开连接或者异常退出,那么其他broker通过watch收到控制器变更的通知,就会去尝试创建临时节点/controller,如果有一个broker创建成功,那么其他broker就会收到创建异常通知,也就意味着集群中已经有了控制器,其他broker只需创建watch对象即可。
-
如果集群中有一个broker发生异常退出了,那么控制器就会检查这个broker是否有分区的副本leader,如果有那么这个分区就需要一个新的leader,此时控制器就会去遍历其他副本,决定哪一个成为新的leader,同时更新分区的ISR集合。
-
如果有一个broker加入集群中,那么控制器就会通过Broker ID去判断新加入的broker中是否含有现有分区的副本,如果有,就会从分区副本中去同步数据。
-
集群中每选举一次控制器,就会通过zookeeper创建一个controller epoch,每一个选举都会创建一个更大,包含最新信息的epoch,如果有broker收到比这个epoch旧的数据,就会忽略它们,kafka也通过这个epoch来防止集群产生“脑裂”。
分区副本选举Leader机制
在kafka的集群中,会存在着多个主题topic,在每一个topic中,又被划分为多个partition,为了防止数据不丢失,每一个partition又有多个副本,在整个集群中,总共有三种副本角色:
-
leader副本:也就是leader主副本,每个分区都有一个leader副本,为了保证数据一致性,所有的生产者与消费者的请求都会经过该副本来处理。
-
follower副本:除了首领副本外的其他所有副本都是follower副本,follower副本不处理来自客户端的任何请求,只负责从leader副本同步数据,保证与首领保持一致。如果leader副本发生崩溃,就会从这其中选举出一个leader。
-
优先副本:创建分区时指定的优先leader。如果不指定,则为分区的第一个副本。
默认的,如果follower与leader之间超过10s内没有发送请求,或者说没有收到请求数据,此时该follower就会被认为“不同步副本”。而持续请求的副本就是“同步副本”,当leader发生故障时,只有“同步副本”才可以被选举为leader。其中的请求超时时间可以通过参数replica.lag.time.max.ms参数来配置。
我们希望每个分区的leader可以分布到不同的broker中,尽可能的达到负载均衡,所以会有一个优先leader,如果我们设置参数auto.leader.rebalance.enable为true,那么它会检查优先leader是否是真正的leader,如果不是,则会触发选举,让优先leader成为leader。
消费组(consumer group)选举机制
组协调器会为消费组(consumer group)内的所有消费者选举出一个leader,这个选举的算法也很简单,第一个加入consumer group的consumer即为leader,如果某一时刻leader消费者退出了消费组,那么会重新 随机 选举一个新的leader。
zookeeper的作用
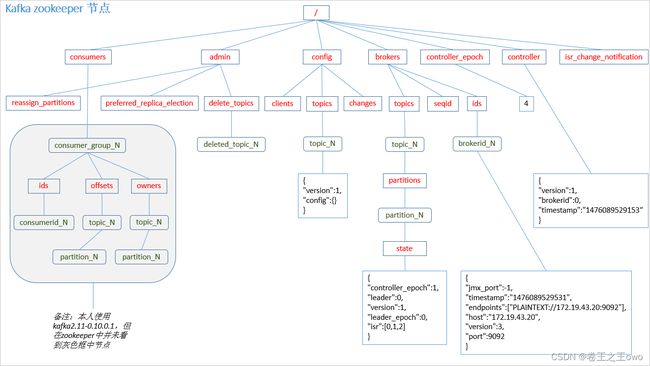
Zookeeper具体使用:
1、broker启动时在/brokers/ids下创建一个临时节点znode,把broker id写进去,broker宕机或没响应该节点就会被删除。
2、每个Broker会把自己存储和维护的partition信息注册到/broker/topics/…路径下。
3、consumers也会在zookeeper上注册临时节点,用以保持消费负载平衡和offset记录。
4、每个consumer在/consumers/[group_id]/ids下创建一个临时consumer_id,用来描述当前group下哪些consumer是alive的。
5、group id相同的多个consumer构成一个消费组,共同消费一个topic,并尽量消费均衡。
1)记录和维护broker状态
zookeeper 记录了所有 broker 的存活状态,broker 会向 zookeeper 发送心跳请求来上报自己的状态。
zookeeper 维护了一个正在运行并且属于集群的 broker 列表。
2)控制器(leader)选举
kafka 集群中有多个 broker,其中有一个会被选举为控制器。控制器负责管理整个集群所有分区和副本的状态,例如某个分区的 leader 故障了,控制器会选举新的 leader。从多个 broker 中选出控制器,这个工作就是 zookeeper 负责的。
3)限额权限
kafka 允许一些 client 有不同的生产和消费的限额,这些限额配置信息是保存在 zookeeper 里面的。
4)记录 ISR(已同步的副本)
Kafka会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,该集合中是一些分区的副本。只有当这些副本都跟Leader中的副本同步了之后,kafka才会认为消息已提交,并反馈给消息的生产者。如果这个集合有增减,kafka会更新zookeeper上的记录。zookeeper 发现其中有成员不正常,马上移除。
5)node 和 topic 注册
zookeeper 保存了所有 node 和 topic 的注册信息,可以方便的找到每个 broker 持有哪些 topic。
node 和 topic 在 zookeeper 中是以临时节点的形式存在的,只要与 zookeeper 的 session 一关闭,他们的信息就没有了。
6)topic 配置
zookeeper 保存了 topic 相关配置,例如 topic 列表、每个 topic 的 partition 数量、副本的位置等等。
kafka结合springboot具体使用
依赖导入
org.springframework.kafka
spring-kafka
配置文件
spring:
kafka:
bootstrap-servers: fairytail.ltd:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
#auto-commit-interval: 50
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: latest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 8
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
profiles:
active: dev
server:
port: 3435配置类
@Configuration
public class KafkaConfig {
@Bean
public NewTopic batchTopic() {
return new NewTopic("sinosun", 2, (short) 1);
}
}生产者
@Component
public class KafkaProduce {
@Autowired
private KafkaTemplate kafkaTemplate;
//自定义topic
public static final String TOPIC_TEST = "sinosun";
public static final String TOPIC_GROUP1 = "topic.group1";
public void send(Object obj) {
kafkaTemplate.send(TOPIC_TEST, 0,""+ System.currentTimeMillis(),obj);
}
} 消费者
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = KafkaProduce.TOPIC_TEST,groupId = KafkaProduce.TOPIC_GROUP1)
public void topicTest(ConsumerRecord record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional message = Optional.ofNullable(record.value());
message.ifPresent((Object msg) ->{
msg=message.orElse(null);
log.info("Topic:" + topic + ",Message:" + msg+" partition"+record.partition()+" class"+msg.getClass());
String task = JSONUtil.toJsonStr(msg);
List integers = JSONArray.parseArray(task, Integer.class);
integers.forEach(param->{
ThreadPoolManager.addExecuteTask("java", param);
});
ack.acknowledge();
});
}
} 测试类
@RestController
@RequestMapping("/kafka")
@Slf4j
public class Controller {
@Autowired
private KafkaProduce kafkaProduce;
@GetMapping("/test")
public String test() throws InterruptedException {
for (Integer i = 0; i < 100; i++) {
List integers = Arrays.asList(1, 2, 3, 4, 5, 6);
String parse = JSONObject.toJSONString(integers);
kafkaProduce.send(parse);
}
ThreadPoolManager.COUNT.await();
log.info(">>>>>>.进入缓冲队列的次数[{}]", ThreadPoolManager.number);
ThreadPoolManager.number.set(0);
return "success";
} 线程池
/**
* @author lijianwei
* 线程池管理类
*/
@Slf4j
public class ThreadPoolManager {
public static Map> consumerMap = new HashMap<>();
//最小线程数(核心线程数)
private static int SIZE_CORE_POOL = 20;
//最大线程数
private static int SIZE_MAX_POOL = 20;
//线程空闲存活时间
private static int TIME_KEEP_ALIVE = 5000;
//缓冲队列大小
private static int SIZE_WORK_QUEUE = 1;
//原子类进行拒绝策略计数
public static AtomicInteger number = new AtomicInteger();
//计数器,给main线程判断线程池是否执行完
public static final CountDownLatch COUNT = new CountDownLatch(600);
/**
* 自定义拒绝策略,将超过线程数量的任务放入缓冲队列
*/
private static final RejectedExecutionHandler mHandler = new RejectedExecutionHandler() {
@SneakyThrows
@Override
public void rejectedExecution(Runnable task, ThreadPoolExecutor executor) {
number.incrementAndGet();
mThreadPool.getQueue().put(task);
log.error("进入缓冲队列");
}
};
private static ThreadPoolExecutor mThreadPool;
/**
* 线程池初始化
*/
public static void init() {
log.info(">>>>>>>>>线程池初始化");
mThreadPool = new ThreadPoolExecutor
(SIZE_CORE_POOL,
SIZE_MAX_POOL,
TIME_KEEP_ALIVE,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(SIZE_WORK_QUEUE),
Executors.defaultThreadFactory(),
mHandler);
}
/**
* 根据不同的type进行不同的方法,利用Java的consumer类型
* @param type
* @param data
*/
public static void addExecuteTask(String type, Object data) {
try {
mThreadPool.execute(() -> {
try {
//根据类型执行不同的任务
consumerMap.get(type).accept(data);
} catch (Exception e) {
log.error("线程池执行任务失败");
}
});
} finally {
COUNT.countDown();
}
}
}