kafka:broker、producer、consumer常用配置
摘要
kafka参数官方文档为:https://kafka.apache.org/documentation/#producerconfigs,这里记下常用配置。
broker
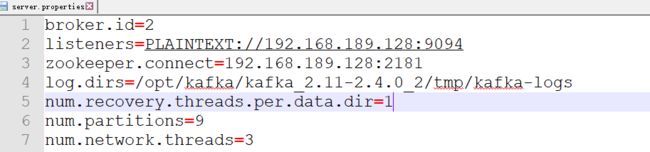
我们在kafka官网下载的文件比如kafka_2.11-2.4.0.tgz解包启动后就是就是kafka节点,主要用于接收分发消息。这些节点可以用配置成单机也可以配置集群,配置主要修改config目录下的server.properties,具体如下:
常用配置如下:
1、broker.id:每个broker的标识符,在集群中必须是唯一的,默认为0。建议可以用机器的ip尾数和端口来标识broker.id,这样无须查看字典表才能根据id找到主机。
2、port:kafka启动端口,默认为9092。kafka客户端就是通过这个端口连接kafka节点。
3、zookeeper.connect:指定连接的zookeeper地址,zookeeper主要用来保存kafka的元数据。
4、log.dir:kafka把所有消息保存到磁盘上,存放这些消息日志的目录通过这个参数指定。如果指定了多个目录,kafka会尽可能将同一分区(partition)下的消息存放到同一目录。当要新增分区时,会往分区数最少的目录加分区,而不是往占用空间最少的目录添加分区。
5、num.recovery.threads.per.data.dir:每个目录的恢复线程数量,当服务器启动、重启、关闭时,都会使用线程池对日志目录下的分区进行处理,若每个目录下分区多恢复缓慢,建议加大这个值,kafka此时用于恢复分区的线程为:log.dir的目录数量*num.recovery.threads.per.data.dir,即log.dir指定了3个目录,而num.recovery.threads.per.data.dir为5,则总共启动15个线程。
6、auto.create.topics.enable:是否启用自动创建主题,默认为true。当生产者向主题写入消息、当消费者向主题读取消息、当客户端请求获取主题元数据时,会自动创建主题。若配置为false,则需要客户端API或人工手动创建主题。
7、num.partitions:参数指定了服务器(broker)新创建的主题将包含多少分区。若客户端API或手动创建主题,则以客户端和手动指定的分区为准。一般分区只能增加不能减少。为了负载均衡,每个broker都可以存储分区的消息日志,则num.partitions的值要大于集群中broker的数量。另外,分区数量也要根据消费者和生产者速度来判断,比如每个消费者只能读取处理20MB/S的数据,而生产者的写入数据有100MB/S,则至少需要5个分区。当然,分区不是越多越好,broker对分区有限制,且分区越多,领导选举时间越长。分区数需要综合考虑。
8、log.retention.hours:消息保留时间,默认为168小时,即消息默认保留一周,一周后被删除。这个时间是判断硬盘上的文件最后修改时间来判断的,不是按每条消息的接收时间判断的。
9、log.retention.bytes:消息保修字节,通过判断每个分区的消息是否达到该限制值,来删除多出来的部分。
日志文件只要满足log.retention.hours和log.retention.bytes任意一个条件就会被删除。这两个参数参数都是针对日志片段(日志磁盘文件)的,不是针对单个消息的。
10、log.segment.bytes:日志片段大小,默认为1GB,当日志片段达到该值就会新创建文件来保存日志。
11、log.segment.ms:日志片段关闭时间,当日志片段创建时间与当前时间差值达到该值后,则日志片段会被关闭,新创建日志文件来保存消息。
12、message.max.bytes:单个消息最大值,默认1MB,若生产者发送消息的大小超过该值,则消息不会被接收,且会收到broker返回的错误信息。消费者fetch.message.max.bytes设置的值必须比message.max.bytes大,否则会出现消费者无法消费大消息的情况,会出现消息积压。
13、replica.fetch.max.bytes:副本获取消息最大值,当kafka集群的副本同步消息时,需要获取消息,该值不能小于message.max.bytes,否则会导致同步消息失败。
producer(生产者)
生产者的参数主要在构造函数的Properties里传入。spring-kafka也提供了properties传入参数的配置。主要参数如下:
1、acks:指定多少个分区副本确认消息,生产者才会认为消息是写入成功。acks=0,则无需等待服务器确认消息,生产者直接返回成功,此模式吞吐量大,但消息不可靠。acks=1,只要收到leader节点的确认消息就认为发送成功。acks=all,需要收到所有leader节点和fllower节点的确认消息就认为发送成功。后两个对消息有可靠性保证。
2、buffer.memory:生产者缓冲区大小。若应用程序发送消息速度超过客户端发送消息的速度,则会导致生产者缓冲区空间不足。
3、retries:生产者发送消息失败后的重试次数。默认每100ms重试一次,可以通过retry.backoff.ms改变这个时间间隔。
4、compression.type:压缩类型,默认下消息不压缩。这个参数可以设置为snappy、gzip等。
5、batch.size:多个消息发送到同一个分区,生产者会把它们放到同一个批次里,这个参数就是同一批次的占用内存大小(字节数)。若该值太小,会导致kafka频繁发送消息,会增加一些额外开销。
6、linger.ms:同一批次消息等待发送时间。默认情况下,即使只有一条消息,只要有可用线程,生产者也会发送掉消息,而设置该值后,消息会等待,后续有消息可以统一时间批量发送,可以增加吞吐量,因为一次性发送了更多消息,单条消息开销变小。
7、client.id:服务器用它来标识消息来源。
8、request.timeout.ms:指定了生产者在发送数据时等待服务器返回响应的时间。
9、metadata.timeout.ms:指定了生产者在获取元数据是等待服务器的响应时间。
10、max.block.ms:指定了在调用send()获取元数据的阻塞时间。
11、max.request.size:单次请求总大小。由于生产者一般是批量发送消息的,消息个数可能是1,也可能是多个,当达到该限制就会发送消息。broker对可接受消息message.max.bytes也有限制,最好都匹配得上。
consumer(消费者)
同生产者一样,参数在构造方法的Properties里传入,spring-kafka也可以直接配置文件里配置参数,主要参数如下:
1、fetch.min.bytes:消息者从服务器获取记录的最小字节数。broker获取了消费者的拉请求后,会等积压消息大小达到这个最小字节数才会将消息批量发送给消费者。
2、fetch.max.wait.ms:消费者获取数据等待时间,若broker等待时间内,消息还没有达到fetch.min.bytes,则broker不会继续等待,会直接将当前堆积的消息发送给消费者。
3、max.partition.fetch.bytes:每个分区返回给消费者最大字节数,默认1M,即KafkaConsumer.poll()方法每个分区返回的数据不超过这个参数设置的字节数。
4、session.timeout.ms:会话超时时间,默认3秒,若消费者没有在session.timeout.ms时间内发送心跳给broker,则broker会认为该消费者已死亡,会触发重平衡,将它的分区分配给其它消费者。
5、heartbeat.inerval.ms:心跳间隔时间,默认1秒,即消费者每秒向broker发送心跳。一般该值为session.timeout.ms的三分之一。
6、auto.offset.reset:指定消费者在偏移量无效情况下该如何处理,默认值是latest,即消费者只消费连上broker后产生的消息,以前积压的消息不消费。还一个值是earlist,表示消费者从起始位置开始消费。
7、enable.auto.commit:是否自动提交偏移量。默认为true。可通过auto.commit.interval.ms设置提交频率。若需要手动确认消费消息,避免重复数据或数据丢失,则建议设置为false。
8、group.id:分组id,同组下的消费者不会重复消费消息。
9、max.poll.records:用于控制单词调用call()方法能够返回的记录数量。消费者每次拉取消息的记录数量。