【ChatBot开发笔记】聊天机器人准备工作——初识NLTK库、语料与词汇资源
目录
- 简述
-
- 一、NLTK
-
- 1、安装
- 2、搜索
- 3、词统计
- 二、语料与词汇资源
-
- 1、举例
- 2、类似的语料库还有:
- 3、语料库的通用接口:
- 4、其他词典资源:
- 5、加载自己的语料库
- 结语
简述
2021.3.8——3.28,该段时间我们的目标进度是实现聊天机器人的提问处理模块内容。时间紧任务重,所以今天我做了一些项目开始前的基本准备工作,为接下来的项目做一些小小的铺垫。
一、NLTK
NLTK(Natural Language Toolkit)是一个比较优秀的自然语言处理工具包,是我们实现聊天机器人需要的比较重要的一个工具。在后续的程序实现中,我们需要通过他里面的数据来进行学习和练习。
1、安装
直接
pip install nltk
安装即可,但是因为是外网的原因,CMD下载速度极慢,建议科学上网(后面下载book的时候最好还是用梯子,不然那几kb/s的速度下载100多兆着实让人暴躁),或者采用清华大学的镜像服务器安装:
pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
nltk下好之后,运行
nltk.download()
在出现的界面中选择book下载即可。
接下来执行:
from nltk.book import *
将会得到如下结果
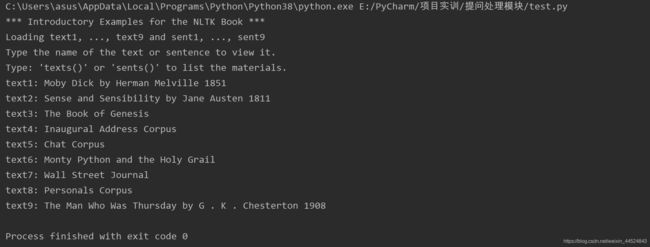
里面的text*都是书籍节点,后面输出的为书籍名,可以使用print(text1)返回书籍节点1的书籍名。
2、搜索
使用 concordance 函数搜索包含某词的上下文
print(text1.concordance("love"))
输出结果为:

使用 similar 函数可以搜索相关词
print(text1.similar("ship"))
返回
![]()
使用 common_contexts 获得两个或两个以上的词的共同的上下文
print(text2.common_contexts(['monstrous','very']))
使用 dispersion_plot 可以判断词在文本中的位置;竖线代表单词,行代表文本;可以用来研究随时间推移语言使用上的变化
print(text4.dispersion_plot(['citizens','democracy','freedom','duties','America']))
输出图片
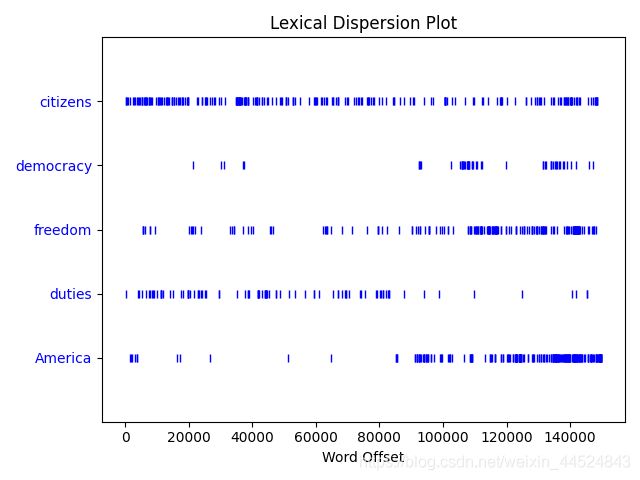
3、词统计
len(text1):返回总字数
set(text1):返回文本的所有词集合len(set(text4)):返回文本总词数
text4.count(“is”):返回“is”这个词出现的总次数
FreqDist(text1):统计文章的词频并按从大到小排序存到一个列表里
fdist1.hapaxes():返回只出现一次的词
text4.collocations():频繁的双联词
fdist1 = FreqDist(text1); 统计词频
fdist1.plot(50, cumulative=True):输出累计图像
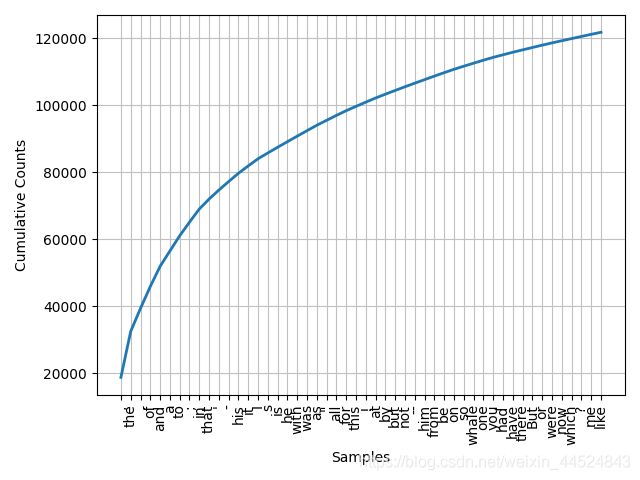 纵轴表示累加了横轴里的词之后总词数是多少,这样看来,这些词加起来几乎达到了文章的总词数。
纵轴表示累加了横轴里的词之后总词数是多少,这样看来,这些词加起来几乎达到了文章的总词数。
二、语料与词汇资源
1、举例
nltk下有多个语料库,以Gutenberg语料库为例,执行
print(nltk.corpus.gutenberg.fileids())
返回Gutenberg语料库的文件标识符
![]()
nltk.corpus.gutenberg就是gutenberg语料库的阅读器,它有很多实用的方法,比如:
nltk.corpus.gutenberg.raw(‘chesterton-brown.txt’):输出chesterton-brown.txt文章的原始内容
nltk.corpus.gutenberg.words(‘chesterton-brown.txt’):输出chesterton-brown.txt文章的单词列表
nltk.corpus.gutenberg.sents(‘chesterton-brown.txt’):输出chesterton-brown.txt文章的句子列表
2、类似的语料库还有:
from nltk.corpus import webtext:网络文本语料库,网络和聊天文本
from nltk.corpus import brown:布朗语料库,按照文本分类好的500个不同来源的文本
from nltk.corpus import reuters:路透社语料库,1万多个新闻文档
from nltk.corpus import inaugural:就职演说语料库,55个总统的演说
3、语料库的通用接口:
fileids():返回语料库中的文件
categories():返回语料库中的分类
raw():返回语料库的原始内容
words():返回语料库中的词汇
sents():返回语料库句子
abspath():指定文件在磁盘上的位置
open():打开语料库的文件流
4、其他词典资源:
有一些仅是词或短语以及一些相关信息的集合,叫做词典资源。
词汇列表语料库:nltk.corpus.words.words(),所有英文单词,这个可以用来识别语法错误
停用词语料库:nltk.corpus.stopwords.words,用来识别那些最频繁出现的没有意义的词
发音词典:nltk.corpus.cmudict.dict(),用来输出每个英文单词的发音
比较词表:nltk.corpus.swadesh,多种语言核心200多个词的对照,可以作为语言翻译的基础
同义词集:WordNet,面向语义的英语词典,由同义词集组成,并组织成一个网络
5、加载自己的语料库
收集自己的语料文件(文本文件)到某路径下(比如/lym),然后执行:
from nltk.corpus import PlaintextCorpusReader
corpus_root = '/lym'
wordlists = PlaintextCorpusReader(corpus_root, '.*')
wordlists.fileids()
就可以列出自己语料库的各个文件了,也可以使用如wordlists.sents(‘a.txt’)和wordlists.words(‘a.txt’)等方法来获取句子和词信息
结语
明天项目实训就要正式开始了,就用我这第一篇博客揭开项目实训的序章,也希望能够在日后的博客中记录项目的进度和我的成长。