kafka Java客户端之Connect API
kafka Connect 简单介绍
Kafka Connect 是一个可扩展、可靠的在Kafka和其他系统之间流传输的数据工具。它可以通过connectors(连接器)简单、快速的将大集合数据导入和导出kafka。Kafka Connect可以接收整个数据库或收集来自所有的应用程序的消息到Kafka Topic。使这些数据可用于低延迟流处理。导出可以把topic的数据发送到secondary storage(辅助存储也叫二级存储)也可以发送到查询系统或批处理系统做离线分析。
Connect API实现一个连接器(connector),不断地从一些数据源系统拉取数据到kafka,或从kafka推送到宿系统(sink system)。
Kafka Connect功能包括:
- Kafka连接器通用框架:Kafka Connect 规范了kafka与其他数据系统集成,简化了connector的开发、部署和管理。
- 分布式和单机模式 - 扩展到大型支持整个organization(公司、组织)的集中管理服务,也可缩小到开发,测试和小规模生产部署。
- REST 接口 - 使用REST API来提交并管理Kafka Connect集群。
- 自动的offset管理 - 从connector获取少量的信息,Kafka Connect来管理offset的提交,所以connector的开发者不需要担心这个容易出错的部分。
- 分布式和默认扩展 - Kafka Connect建立在现有的组管理协议上。更多的工作可以添加扩展到Kafka Connect集群。
- 流式/批量集成 - 利用kafka现有的能力,Kafka Connect是一个桥接流和批量数据系统的理想解决方案。
Kafka Connect实际上是Kafka流式计算的一部分,区别于Kafka Stream的是,Kafka Stream在kafka内部处理数据。而Kafka Connect 是将数据导入Kafka或者将数据从Kafka导出,因此Kafka Connect主要用来与其他中间件建立流式通道
Kafka Connect的架构如下图所示:

现在常用的中间件的connect 都已经被维护好了,所以不用我们自己实现。
Kafka Connect关键词
Connectors
通过管理task来协调数据流的高级抽象
Kafka Connect中的connector定义了数据应该从哪里复制到哪里。connector实例是一种逻辑作业,负责管理Kafka与另一个系统之间的数据复制。
我们在大多数情况下都是使用一些平台提供的现成的connector。但是,也可以从头编写一个新的connector插件。在高层次上,希望编写新连接器插件的开发人员遵循以下工作流:

Task
Task是Connect数据模型中的主要处理数据的角色,也就是真正干活的。每个connector实例协调一组实际复制数据的task。通过允许connector将单个作业分解为多个task,Kafka Connect提供了内置的对并行性和可伸缩数据复制的支持,只需很少的配置。
这些任务没有存储任何状态。任务状态存储在Kafka中的特殊主题config.storage.topic和status.storage.topic中。因此,可以在任何时候启动、停止或重新启动任务,以提供弹性的、可伸缩的数据管道。

Workers
Workers是负责管理和执行connector和task的。connector和task是逻辑工作单元,并作为进程运行。
Workers有两种模式,Standalone(单机)和Distributed(分布式)。
Standalone Workers:
Standalone模式是最简单的模式,用单一进程负责执行所有connector和task。对于在本地计算机上开发和测试 Kafka Connect 非常有用。它还可用于通常使用单个代理的环境(例如,将 Web 服务器日志发送到 Kafka)。
Distributed Workers:
Distributed模式为Kafka Connect提供了可扩展性和自动容错能力。在分布式模式下,你可以使用相同的组启动许多worker进程。它们自动协调以跨所有可用的worker调度connector和task的执行。
如果你添加一个worker、关闭一个worker或某个worker意外失败,那么其余的worker将检测到这一点,并自动协调,在可用的worker集重新分发connector和task。
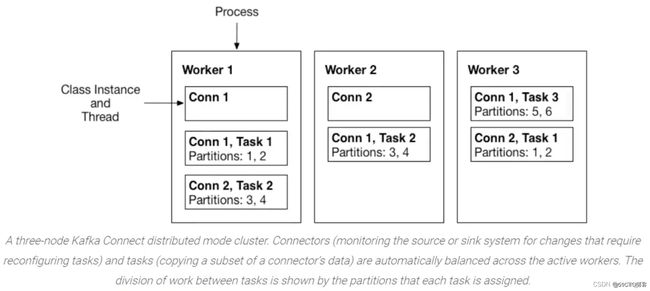
Task Rebalance
当connector首次提交到集群时,workers会重新平衡集群中的所有connector及其tasks,以便每个worker的工作量大致相同。当connector增加或减少它们所需的task数量,或者更改connector的配置时,会重新平衡。
当一个worker失败时,task在活动的worker之间重新平衡。当一个task失败时,不会触发再平衡,因为task失败被认为是一个例外情况。因此,失败的task不会被框架自动重新启动,应该通过REST API重新启动。

Converters
在向Kafka写入或从Kafka读取数据时,Converter是使Kafka Connect支持特定数据格式所必需的。task使用Converters将数据格式从字节转换为连接内部数据格式,反之亦然。
默认情况下,Confluent Platform 提供以下转换器:
- AvroConverter(建议):与Schema Registry一起使用
- JsonConverter:适合结构数据
- StringConverter:简单的字符串格式
- ByteArrayConverter:提供不进行转换的“传递”选项
Converters与Connectors本身分离,以允许Connectors之间自然地重复使用转换器。例如,使用相同的 Avro 转换器,JDBC 源连接器可以将 Avro 数据写入 Kafka,HDFS 接收器连接器可以从 Kafka 读取 Avro 数据。这意味着可以使用相同的转换器,即使例如,JDBC 源返回最终作为 Parquet 文件写入 HDFS 的转换器。
AvroConverter处理数据的流程图:
下图显示了在使用 JDBC 源连接器从数据库读取数据、写入 Kafka 以及最后使用 HDFS 接收器连接器写入 HDFS 时如何使用转换器。

Transforms
Connector可以配置Transforms,以便对单个消息进行简单且轻量的修改。这对于小数据的调整和事件路由十分方便,且可以在connector配置中将多个Transforms连接在一起。然而,应用于多个消息的更复杂的Transforms最好使用KSQL和Kafka Stream来实现。
Transforms是一个简单的函数,输入一条记录,并输出一条修改过的记录。Kafka Connect提供许多Transforms,它们都执行简单但有用的修改。可以使用自己的逻辑定制实现转换接口,将它们打包为Kafka Connect插件,将它们与connector一起使用。
当Transforms与Source Connector一起使用时,Kafka Connect通过第一个Transforms传递connector生成的每条源记录,第一个Transforms对其进行修改并输出一个新的源记录。将更新后的源记录传递到链中的下一个Transforms,该Transforms再生成一个新的修改后的源记录。最后更新的源记录会被转换为二进制格式写入到Kafka。Transforms也可以与Sink Connector一起使用。
Mysql 环境准备
使用mysql 来尝试kafka connect
创建Mysql数据库
使用Navicat 创建Mysql 数据库

使用DataGrip 与mysql 建立连接
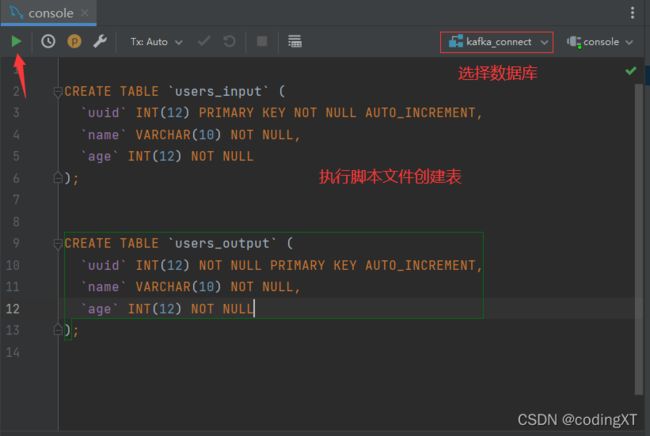
创建数据库的表
在演示Kakfa Connect的使用之前我们需要先做一些准备,因为依赖一些额外的集成。例如在本文中使用MySQL作为数据源的输入和输出,所以首先得在MySQL中创建两张表(作为Data Source和Data Sink)。建表SQL如下:
CREATE TABLE `users_input` (
`uuid` INT(12) PRIMARY KEY NOT NULL AUTO_INCREMENT,
`name` VARCHAR(10) NOT NULL,
`age` INT(12) NOT NULL
);
CREATE TABLE `users_output` (
`uuid` INT(12) NOT NULL PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(10) NOT NULL,
`age` INT(12) NOT NULL
);
Connect 准备
Kafka Connect中的connector定义了数据应该从哪里复制到哪里。connector实例是一种逻辑作业,负责管理Kafka与另一个系统之间的数据复制。
去confluent网站寻找Connector,有许多现成的可供使用

下载JDBC Connector

去maven 仓库去下载mysql-connector的jar包
因为我的mysql 是部署的mysql 8 ,所以我下载mysql 8的连接jar包
然后将这两个包拷贝到服务器指定文件夹下面。我这里拷贝到 我部署kafka的文件路径下面
cd /usr/local/kafka
mkdir plugins
给这个文件夹赋予权限
chmod -R 777 plugins
解压kafka的connect 包
unzip confluentinc-kafka-connect-jdbc-10.3.2.zip
如果服务器磁盘空间比较紧张的话,可以删掉压缩包
rm -rf confluentinc-kafka-connect-jdbc-10.3.2.zip
将MySQL驱动包移动到kafka-connect-jdbc的lib目录下
mv mysql-connector-java-8.0.28.jar /usr/local/kafka/plugins/confluentinc-kafka-connect-jdbc-10.3.2/lib/
Connect包准备好后,我们需要修改一些kafka的配置文件
进入kafka容器
docker exec -it ${CONTAINER ID} /bin/bash
cd 到脚本文件的文件夹
cd /opt/kafka/config
这个文件夹下面的配置文件有很多,我们这里只修改分布式的connect-distributed.properties配置文件

修改如下配置项:
# 指定rest服务的端口号
rest.port=8083
# 指定Connect插件包的存放路径 引入外部依赖
plugin.path=/opt/kafka/plugins
由于rest服务监听了8083端口号,如果你的服务器开启了防火墙就需要使用以下命令开放8083端口,否则外部无法访问,但是这里我们是使用的docker 部署的kafka服务,容器的端口不用开放,但是要把容器的端口和宿主机也就是服务器的端口对应绑定上,以此访问容器的8083端口
我是用的docker 部署的kafka 服务,所以我将这个配置文件挂载了出来,方便修改
kafka的简单介绍以及docker-compose部署单主机Kafka集群
在这篇博客的docker-compose.yml文件的挂载区域添加了如下一列,将配置文件挂载到了服务器宿主机,并添加了对应端口8083的映射
- "/usr/local/kafka/kafka-1/conf/connect-distributed.properties:/opt/kafka/config/connect-distributed.properties"
完成前面的步骤后,我们就可以启动Kafka Connect了。有两种启动方式,分别是:前台启动和后台启动,前者用于开发调试,后者则通常用于正式环境。具体命令如下:
docker 部署的kafka 容器,脚本文件在/opt/kafka/bin 下面
(这里仅针对wurstmeister/kafka镜像部署的容器)
# 前台启动 会打印日志到屏幕上
./connect-distributed.sh /opt/kafka/config/connect-distributed.properties
# 后台启动
./connect-distributed.sh -daemon /opt/local/kafka/config/connect-distributed.properties
启动成功后,使用浏览器访问
http://{ip}:8084/connector-plugins 根据你的服务器IP 和设置的端口号来
正常情况下会返回一些JSON数据:

REST API
由于Kafka Connect的目的是作为一个服务运行,提供了一个用于管理connector的REST API。默认情况下,此服务的端口是8083,可以自己在上面配置文件修改。以下是当前支持的REST API:我们可以通过这些API去操作connector

使用浏览器访问查看所有的connector
http://{ip}:8084/connectors
此时返回的是一个空数组,说明没有任何的connector:

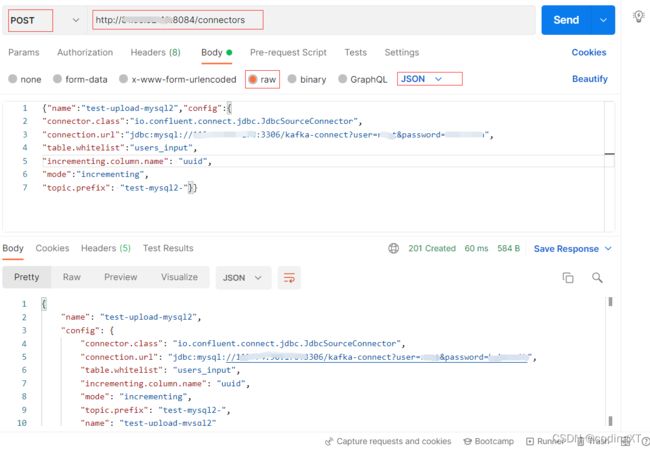
此时我们可以使用POST方式请求/connectors接口来新增一个connector,linux终端窗口curl命令调用示例如下:
curl -X POST -H 'Content-Type: application/json' -i 'http://IP:8084/connectors' \
--data \
'{"name":"test-upload-mysql","config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://IP:3306/数据库名?user=xx&password=xx",
"table.whitelist":"users_input",
"incrementing.column.name": "uuid",
"mode":"incrementing",
"topic.prefix": "test-mysql-"}}'
参数说明:
- name:指定新增的connector的名称
- config:指定该connector的配置信息
- connector.class:指定使用哪个Connector类
- connection.url:指定MySQL的连接url
- table.whitelist:指定需要加载哪些数据表
- incrementing.column.name:指定表中自增列的名称
- mode:指定connector的模式,这里为增量模式
- topic.prefix:Kafka会创建一个Topic,该配置项就是用于指定Topic名称的前缀,后缀为数据表的名称。例如在本例中将生成的Topic名称为:test-mysql-users_input
使用postmen提交POST 请求也是一样的,将上面的json部分copy到下面

删除指定的connector

查看指定connector的运行状态

新增connector完成后,我们尝试往数据表里添加一些数据,具体的sql如下:
insert into users_input(`name`, `age`) values('xt', 23);
insert into users_input(`name`, `age`) values('xt2', 24);
insert into users_input(`name`, `age`) values('xt3', 25);
使用DataGrip 来执行脚本文件
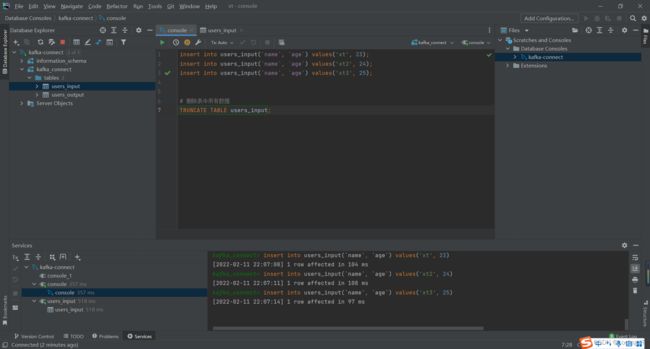
使用kafka-console-consumer.sh脚本命令去拉取test-mysql-users_input中的数据:
kafka-1是我的容器名
./kafka-console-consumer.sh --bootstrap-server kafka-1:9092 --topic test-mysql-users_input --from-beginning
拉取出来的数据是JSON结构的,其中的payload就是数据表中的数据

能拉取到这样的数据就代表已经成功将MySQL数据表中的数据传输到Kafka Connect Source里了,也就是完成输入端的工作了。
现在我们已经能够通过Kafka Connect将MySQL中的数据写入到Kafka中了,接下来就是完成输出端的工作,将Kafka里的数据输出到MySQL中。
首先,我们需要调用Rest API新增一个Sink类型的connector。具体请求如下:
{"name":"test-download-mysql","config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://IP:3306/kafka_connect?user=root&password=XXX",
"topics":"test-mysql-users_input",
"auto.create":"false",
"insert.mode": "upsert",
"pk.mode":"record_value",
"pk.fields":"uuid",
"table.name.format": "users_output"}}
参数说明:
- name:指定新增的connector的名称
- config:指定该connector的配置信息
- connector.class:指定使用哪个Connector类
- connection.url:指定MySQL的连接url
- topics:指定从哪个Topic中读取数据
- auto.create:是否自动创建数据表
- insert.mode:指定写入模式,upsert表示可以更新及写入
- pk.mode:指定主键模式,record_value表示从消息的value中获取数据
- pk.fields:指定主键字段的名称
- table.name.format:指定将数据输出到哪张数据表上

部署完毕之后可以看见users_output上面已经有了和users_input一样的数据
可以直观的看到Kafka Connect实际上就做了两件事情:使用Source Connector从数据源(MySQL)中读取数据写入到Kafka Topic中,然后再通过Sink Connector读取Kafka Topic中的数据输出到另一端(MySQL)。
虽然本例中的Source端和Sink端都是MySQL,但是不要被此局限了,因为Source端和Sink端可以是不一样的,这也是Kafka Connect的作用所在。它就像一个倒卖数据的中间商,将Source端的数据读取出来写到自己的Topic,这就像进货一样,然后再将数据输出给Sink端。至此,就完成了一个端到端的数据同步,其实会发现与ETL过程十分类似,这也是为啥Kafka Connect可以作为实现ETL方案的原因。
References:
- https://blog.csdn.net/wjandy0211/article/details/93642257
- https://docs.confluent.io/3.0.0/connect/
- https://www.orchome.com/455
- https://docs.confluent.io/platform/current/connect/index.html
- https://blog.51cto.com/zero01/2498682
(写博客主要是对自己学习的归纳整理,资料大部分来源于书籍、网络资料、官方文档和自己的实践,整理的不足和错误之处,请大家评论区批评指正。同时感谢广大博主和广大作者辛苦整理出来的资源和分享的知识。)