基于Yolv5s的口罩检测
1.Yolov5算法原理和网络结构
YOLOv5按照网络深度和网络宽度的大小,可以分为YO-LOv5s、YOLOv5m、YOLOv5l、YOLOv5x。本文使用YOLOv5s,它的网络结构最为小巧,同时图像推理速度最快达0.007s。YO-LOv5的网络结构主要由四部分组成,分别是Input、Backbone、Neck、Head,其网络结构图如图所示。
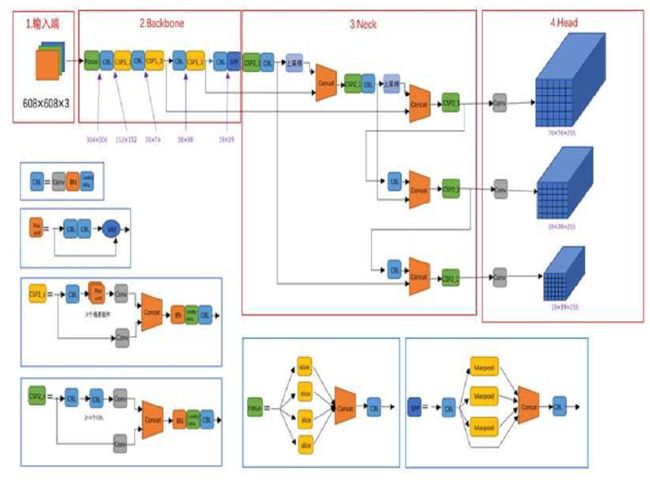
Yolov5网络结构图
1.1Input端
Input使用了Mosaic数据增强、自适应锚框计算、图片尺寸处理。Mosaic数据增强把4张图片,采用随机缩放、随机裁剪、随机排布的方式进行拼接,极大地丰富了检测数据集,尤其是增加了很多小目标,让网络结构的鲁棒性更好。在YOLOv5算法中,不同的数据集,会设定不同初始长宽的锚框,在训练数据的时候,在初始锚框的基础上得到预测框,把它和真实框比较,算出两者差距,反向更新,迭代更新网络结构参数,自适应锚框计算可以得到最佳锚框值。在目标检测算法中,要训练图片的尺寸都不相同,要把原始图片统一缩放到一个固定尺寸,再输入到网络中进行训练,本文图片的尺寸为608×608×3。
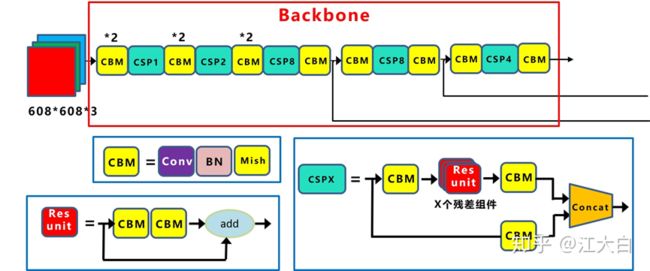
1.2Backone
Backbone包含Focus、CSP和SPP。Focus不存在于其他YOLO算法中,主要是用来进行切片操作,例如608×608×3的图像在Focus结构中进行切片操作后,变成304×304×12大小,在进行32个卷集核的卷积操作,成为304×304×32的特征图。YOLOv4中只有一种CSP结构,而YOLOv5中有两种,CSP1_x和CSP2_x,它们分别应用于Backbone和Neck中,YOLOv4的CSP结构只存在Backbone中,CSP结构如图1所示,其中CSP1_x的x表示CSP1中有x个Resunit(残差组件),CSP2_x的x表示CSP2中有2x个CBL,x影响着网络结构的深度。在Backbone中,采用SPP(空间向量金字塔池化),对特征图做最大池化,将不同尺度的特征图拼接在一起。
(1)Focus结构
Focus结构中关键的是切片操作,切片操作演示过程,将4×4×3的特征图经过切片处理,变成2×2×12的特征图。将608×608×3的三通道图像输进Focus结构,经过切片操作,先变成304×304×12的特征图,之后,经过使用32个卷积核的卷积操作,最终变成304×304×32的特征图。需要注意的是,YOLOv5s网络结构中的Focus结构使用了32个卷积核,进行卷积操作,而其他三种网络结构,使用的卷积核数量有所增加。
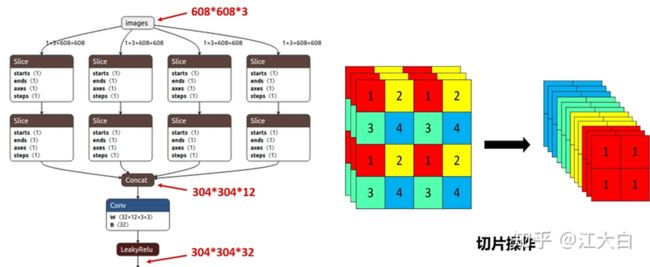
Focus结构图
(2)CSP结构
YOLOv5中有两种结构的CSP,CSP1_X结构在Backbone主干网络中,另一种CSP2_X结构在Neck中。对于Backbone的主干网络结构,CSP模块中的卷积核大小都是3*3,步进值为2,假如输入的图像尺寸是608*608,那么它的特征图变化的规律是:608*608->304*304->152*152->76*76->38*38->19*19,最终得到了一个19*19大小的特征图。
使用CSP模块的优点:1.增强网络的学习能力,使得训练出来的模型既能保持轻量化,又能有较高的准确性。2.降低计算瓶颈。3.降低内存成本。
CSP结构图
(3)SPP结构
SPP结构详细介绍:https://www.cnblogs.com/zongfa/p/9076311.html
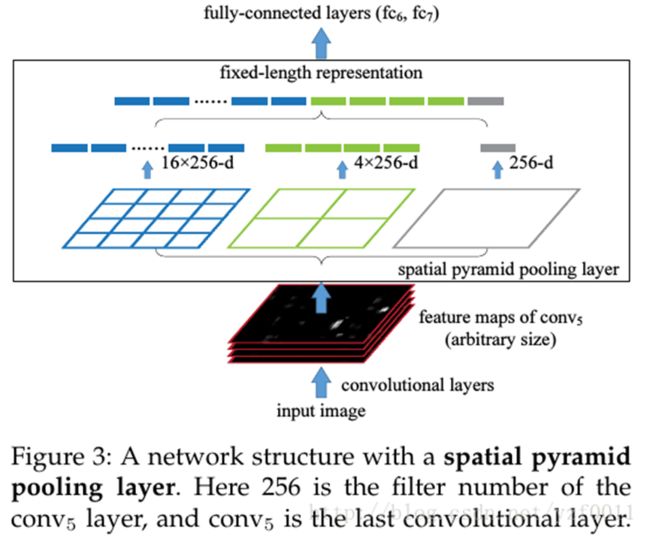
SPP结构图
1.3Neck
Neck中采用了FPN+PAN的结构,FPN是自上而下的,利用上采样的方式对信息进行传递融合,获得预测的特征图。PAN采用自底向上的特征金字塔。具体结构如图所示。
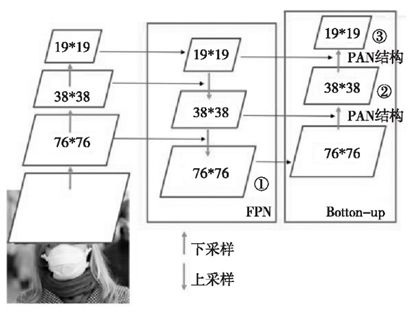
FPN+PAN结构图
1.4Prediction
Prediction包括Bounding box损失函数和非极大值抑制(NMS)。YOLOv5中使用GIOU_Loss作为损失函数,有效解决了边界框不重合时问题。在目标检测预测结果处理阶段,针对出现的众多目标框的筛选,采用加权NMS操作,获得最优目标框。
- GIOU_Loss损失函数
目标检测算法的损失函数一般由Classificition Loss(分类损失函数)以及Bounding Box Regeression Loss(回归损失函数)两大部分组成。回归损失函数在近几年的发展过程是:Smooth L1 Loss->IOU_Loss(2016)->GIOU_Loss(2019)->DIOU_Loss(2020)->CIOU_Loss(2020)。

IOU_Loss图
图是IOU_Loss,可以看出黄色框是预测框,蓝色框是真实框。假设预测框和真实框的交集为A,并集为B,IOU定义为交集A除以并集B,IOU的Loss为:
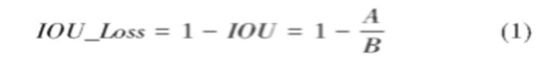
IOU的Loss比较简单,但存在两个问题。
问题1:预测框和真实框不相交的情况,如图(a)状态1所示,此时IOU为0,无法反应出预测框和真实框距离的远近,此时损失函数不能求导,IOU_Loss损失函数无法优化预测框和真实框不相交的情况

特殊状态的IOU_Loss图
问题2:当预测框和真实框大小相同,IOU也可能会相同,如上图(b)(c)的状态2和状态3的情况所示,此时IOU_Loss损失函数也不能区分这两种情况的不同。因此使用GIOU_Loss来进行改进。

GIOU_Loss图
如上图是GIOU_Loss,黄色框是预测框,蓝色框是真实框,令预测框和真实框的最小外接矩形为集合C,差集定义为集合C和并集B的差,则GIOU_Loss为:
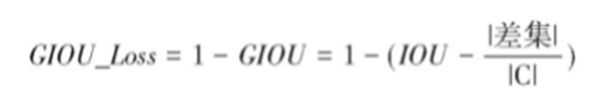
GIOU_Loss损失函数提高了衡量相交尺度的方式,减少了单纯IOU_Loss时的不足。
2.实验及结果
2.1实验数据集及实验环境
2.1.1数据集
数据集采用Kaggle上的Face Mask Detection,数据集一共853张图片,划分为三个类,一种是戴口罩的,一种是不戴口罩的,还有一种是没有戴好口罩的。数据集链接:https://www.kaggle.com/andrewmvd/face-mask-detection
数据集展示:
下载下来后,这些数据集还不能直接使用。因为yolov5不支持xml文件处理,而是支持txt文件。所以首先将这些数据按照下图这样的目录格式整理好:
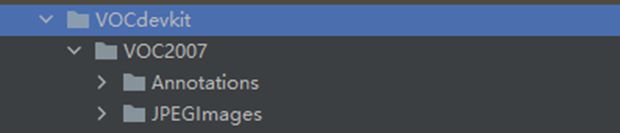
然后运行下面的代码,将该数据集转换成Yolov5能够使用的数据集:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["with_mask", "without_mask","mask_weared_incorrect"]
# classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
运行完上面的代码后,会生成下面的目录格式:
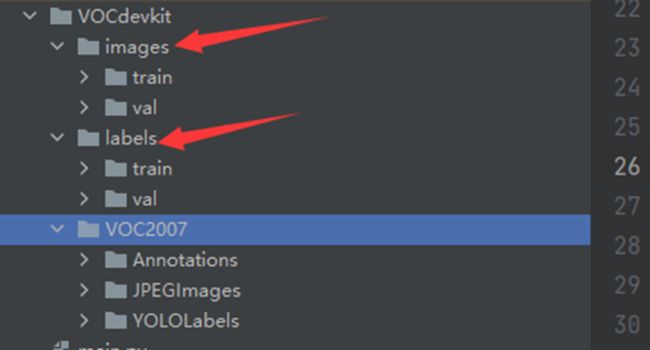
可以看到通过运行上面的代码,在VOCdevkit目录下生成了images和lables文件夹,这两个文件夹下又有train和val文件夹,这个就是需要的数据集了。其中train对应的就是训练集,val对应的就是测试集。
2.2.2数据集标注
因为数据集中已经给定了标注好的xml文件,这里就不再进行标注。数据集标注主要是通过labelimg进行标注。
2.2.3实验环境
实验环境采用Ubuntu 20.04.2+双路Intel 4110CPU+64G内存+RTX2080Ti显卡+Anaconda3进行实验。
2.2Yolov5网络训练
一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而yolov5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过这个网址进行下载,本次训练自己的数据集用的预训练权重为yolov5s.pt。

我们先将Yolov5通过git将代码pull到本地,可以看到如下的目录格式:
然后我们将下载好的Yolov5.pt模型文件放在Yolov5的根目录下。将数据集文件也放在Yolov5根目录下:
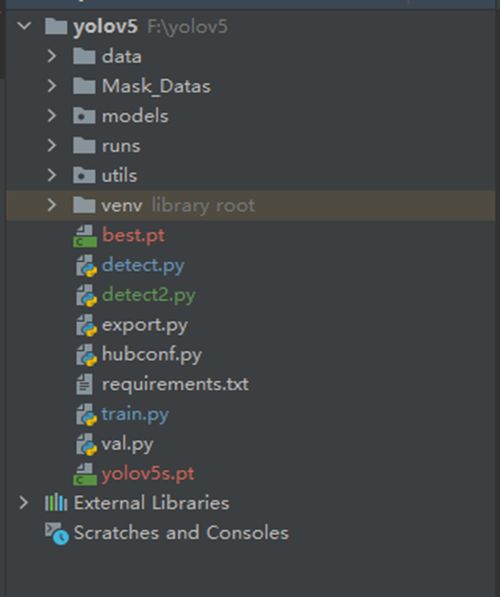
现在来对代码的整体目录做一个介绍:
├── data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);还有一些官方提供测试的图片。如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。但是自己的数据集不建议放在这个路径下面,而是建议把数据集放到yolov5项目的同级目录下面。
├── models:里面主要是一些网络构建的配置文件和函数,其中包含了该项目的四个不同的版本,分别为是s、m、l、x。从名字就可以看出,这几个版本的大小。他们的检测测度分别都是从快到慢,但是精确度分别是从低到高。这就是所谓的鱼和熊掌不可兼得。如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
├── utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
├── weights:放置训练好的权重参数。
├── detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
├── train.py:训练自己的数据集的函数。
├── test.py:测试训练的结果的函数。
├──requirements.txt:这是一个文本文件,里面写着使用yolov5项目的环境依赖包的一些版本,可以利用该文本导入相应版本的包。
然后我们修改models/yolov5s.yaml文件将nc改成3,因为我们是个3分类问题。并且在data目录下创建一个biaoqing.yaml文件,其内容为:
train: Mask_Datas/images/train # train images (relative to 'path') 128 images
val: Mask_Datas/images/val # val images (relative to 'path') 128 images
# Classes
nc: 3 # number of classes
names: ['with_mask', 'without_mask', 'mask_weared_incorrect'] # class names
里面指定了训练集和测试集的路径,以及分类的内容。
然后我们修改Yolov5根目录下的train.py文件,修改超参数如下图。其中—weights指定了预训练权重,--cfg指定预训练权重的配置文件,--data指定数据集的配置文件。还有一些参数比如—epochs指定了训练的轮数,默认是300轮,可以根据需要进行修改。还有--batch-size指定一次读取多少张照片,一般都是指定8的倍数张。根据自己的电脑性能进行修改。

修改完上面的参数后,我们将代码上传到了运行环境如下:

通过requirements.txt安装了所需要的库。直接运行python train.py即可开始进行训练,下面是训练图

经过200轮训练后,我们生成了一个best.pt,也就是在这200轮训练得出来的最后的权重文件。
2.3实验结果与分析
我们查看results.png文件如下图:

训练过程中随着迭代次数增加,各种数值变化,如上图所示,图中各个数值的含义如下:
GIo U:数值越接近0,目标框画的越准确。
Objectness:数值越接近0,对目标检测得越准确。
Classification:数值越接近0,目标分类越准确。
Precision:准确率,即标出的正确目标个数除以标出的目标总个数,越接近1,准确率越高。
Recall:召回率,即标出的正确目标个数除以需要标出的目标总个数,越接近1,准确率越高。
m [email protected]和m [email protected]:0.95:AP是用Precision和Recall作为两坐标轴作图后围成的面积,越接近1,准确率越高。
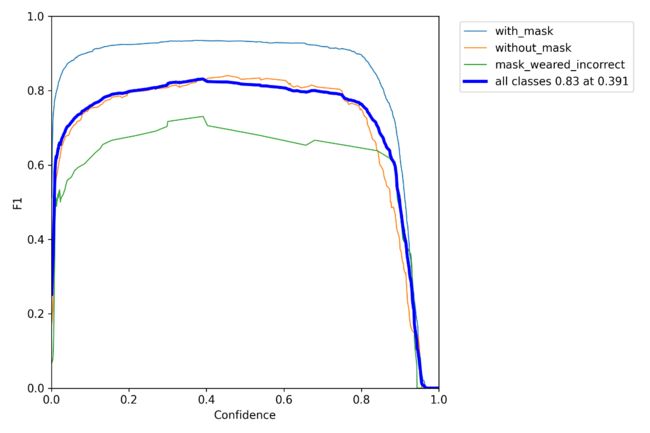
置信度图

P-R图
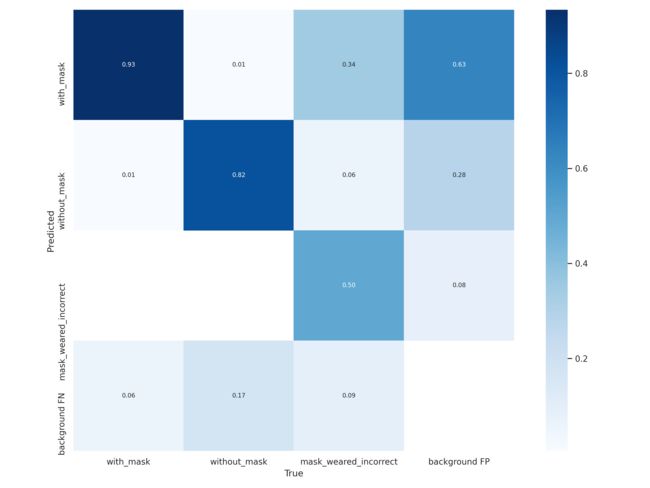
混淆矩阵
实验效果:
