【2022】小伙用爬虫整理了自己十年的动态(爬虫保姆级教程)
前言
中学时期,自己就已经是一名合格的网民,有事没事都会发说说,还会拉着同学朋友帮忙点赞。近期寒假,自己点开空间想回忆过往“青春”…



无奈1页只能显示20条数据,自己看完就必须要点击下一页才能继续接着看,太麻烦! 嗯?用爬虫能试试吗,咱说干就干。
关于爬虫的那些事
- 什么是爬虫?
百度百科定义:网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
如果百度说的太高大上,大家有看不大明白的地方的话,我按我的理解翻译一下:爬虫可以模拟用户的浏览行为,向对方的服务器发送请求,并接收服务器返回的相应信息(可以简单理解为HTML代码),只是爬虫没有把返回的信息同浏览器一样渲染出来。所以我们可以把浏览器当作成一个高效地、可以按我们想法操作的特殊浏览器来使用。 - 爬虫违法吗?
技术是不违法的,但使用爬虫技术有如下行为都是违法:
(1)爬虫爬取涉及个人隐私的东西。
例如:如果爬虫程序采集到公民的姓名、身份证件号码、通信通讯联系方式、住址、账号密码、财产状况、行踪轨迹等个人信息,并将之用于非法途径的,则肯定构成非法获取公民个人信息的违法行为。
(2)因为爬虫造成对方服务器瘫痪,违法。
(3)爬虫非法获利。
例如:你用爬虫把CSDN里的教程资料爬取一大部分复制到你的网站里边,并把你爬取到的教程打包拿出去售卖,毫无疑问,违法了。
爬虫第一步(分析网页,确定爬取思路)
学会分析网页是做网络爬虫的第一步,自己之前在学习爬虫时看了很多博主说什么有万能的爬取方法,所谓的万能方法都是luan的,因为只有自己学会如何分析网页、了解了其爬虫的方法、原理、解析数据的技术,爬取自己想要的数据时才会如鱼得水。在这里推荐使用谷歌浏览器,原因嘛,很简单,分析网络时谷歌浏览器的开发者工具使用起来简单快捷而且高效。这里自己就用谷歌浏览器做一下示范吧。
-
进入空间-我的说说

-
在网页加载完毕之后,打开开发者工具(F12),或者在页面点击鼠标右键-检查。

-
选择开发者工具里的Network进行抓包。

-
这个抓包工具是什么呢?为什么要抓包?
我们在浏览空间页面时,有时候会发现自己在向下滑动页面的时候,自己信息会慢慢加载出来,但自己的页面却没有刷新跳转,这个时候就要怀疑网页是不是使用了动态刷新(AJAX),如果使用了网页使用了动态刷新使用普通的get,post方法访问网址(url)时是无法成功爬取的。
抓包工具可以把浏览器发送的所有请求的记录以及把服务器返回的所有信息都截取下来,我们分析浏览器发送的请求和响应数据就可以“对症下药”!
打开抓包工具后再次刷新页面。
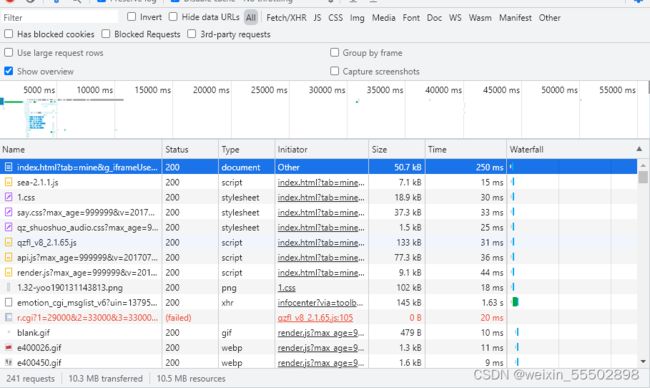
241个请求也不能一个一个的点开看,使用搜索功能进行搜索,安排ctrl+F可以打开全局搜索功能,搜索的内容就属入一条自己的页面上能看见的动态文案,例如我这里就输入:“每一段都很温暖,”

令人欣喜的是能够搜索到有记录(有些网站会把信息加密,不会让用户直接搜索出来,这里直接一搜就出结果了少了不少的事情,欣喜)。
我们点击这一条搜索出来的信息,查看详情信息。

**通常我们在详情信息里会查看或者使用前4个功能。
点击第一个:Headers。

点击第二个。

点击第三个。

我们通常在Preview里边查看Json数据。
我看此刻可以找找,看自己的说说文案被“藏”到了什么地方?

Nice!在json数据的mesglist里可以找到文案,但看到信息长度只有20条。为什么是20条呢?

难道是最开始传值传的20影响的吗?还好这个访问的方式是GET我们可以在浏览器里直接访问地址更改我们我的值。

把这里的20改成21,再试试访问。
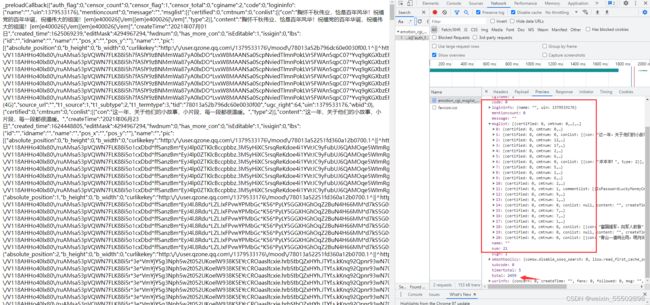
访问成功,果然我们接收到的数据条数跟之前发送的数量有关,此时我们又观察到Json数据里边有一项数据total:2459,猜一猜有可能是我空间说说的总条数。后来在空间主页面确实也证实了我们这一猜想。
既然我们有能力改变取值的数量,我们直接把num改为2459不就把全部数据截取到了吗?这是一个好的办法,我们再试一试
把num改为2459后:

截取到的信息数目降到了10。
看来后台可能做了判断处理,当这个数值在大于了某个数值以后就默认改为10条返回。不过还好,经过几轮的测试,最终发现这个数值为40,一次性最多可以获取40条数据。那么我们只需要多重复执行几次程序爬取就好啦。
既然要多次获取数据,那总要判断数据获取到哪儿了,获取数据也应该会有一个区间,
再看看传过去的数值,sort和pos都比较可疑,试一试。可以得到结果,pos可以返回包括该数值之后的包括它本身的num条信息。
我们的爬取思路基本确定下来了,我们可以把爬取到的信息放入词云分析,或者生成excel文件查看!
爬虫第二步(爬取数据)
- 为了更容易成功的获取数据,我们要设置一下爬虫的headers。
- 我们暂时把获取的数据打印显示出来就可以了。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36',
'Cookie': '复制你的cookie',
}
- headers里边只设置U-A和Cookie就好,这两项数据均可以在自己的浏览器里找到。

有些小伙伴就要问啦,为什么要设置headers呢?直接用request.get/post不好吗?
我们根据字面意思,可以把headers理解成为一个头部信息,我们的浏览器在访问目标服务器时会携带头部信息,所携带的信息都在上方的图片中,我们这里只截取了其中的User-Agent和Cookie*两个数据作为头信息。*
User-Agent这个参数会告诉目标服务器我用的是什么浏览器在访问你,比如这里我就告诉它了我使用的是谷歌浏览器,不同浏览器的User-Agent都是不一样的,大家可以使用不同浏览器去访问同一个页面,看看User-Agent有什么不一样。
有些网页有反爬措施,比如它识别到有一个不是浏览器的“东西”在向我发出请求要访问我,我就会把他拒绝掉来达到反爬的目的。那么我在这里给我的爬虫穿上了一件浏览器的“外衣”,服务器就会把我当作成正常的浏览器。这个操作我们可以称为UA伪装,这也是最基础的反反爬措施之一。
Cookie:
先来简单说说这东西是啥?不用cookie行不行?
我们先来想象一下这样一个场景:你开了一家奶茶店,这家奶茶店只为你的会员服务,要想喝到你们家的奶茶就必须注册你家的会员,那么问题来了。顾客在我这里办理了会员我是不是要登记一下呀,如果我的会员越来越多我只凭脑子记也容易忘掉,那我就用本子把顾客的电话号码记一下吧,顾客来消费时先说自己的电话号码,如果我的本子上有它的电话,那就说明是我家的会员;随着我的会员人数越来越多,每次来我都要查号码,那我就再升级一下,我给我的会员定制一张卡片,卡片上的信息跟我本子上的信息基本相同,以后顾客只需要出示我给的卡片,我就知道它是我的会员,可以卖奶茶给它。
一般谈Cookie都会涉及到另一个名词——Session。
session就好像是上个场景中我手中的本子,Cookie就好比我给到顾客手中卡片。session是保存在服务端的数据信息,这些信息大多跟用户有关系,Cookie是服务器返回在浏览器里的信息,可以把它当作成为一把钥匙,session当作成一把锁。当我们的钥匙能打开对应的锁时,才会有访问的权限。当一个我们爬取的网站涉及到有登陆操作才会有访问权限时就要考虑使用cookie。
- 我们在headers里直接加入Cookie信息就好比如将我们把浏览器的钥匙复制了一把给了爬虫,让爬虫去解锁服务器的锁,而在基础的爬虫里不用加入Cookie信息,例如爬取百度百科信息不用加。因为百度并没有验证我的用户身份,并没有要求我必须登陆账号才能搜索,所以我可以不用加。但这里访问的是自己的空间,TX公司有必须登陆才能访问的验证操作,所以要加Cookie信息。但如果一定要问有没有不加Cookie还能够获取到数据的方法,答案肯定是有的,可以考虑使用selenium(处理动态加载信息一流工具,爬虫的万精油,但缺点就是获取数据的速度较慢)
- 开始爬取
import requests
start=0
url = f'https://user.qzone.xx.com/proxy/domain/taotao.xx.com/cgi-bin/emotion_cgi_msglist_v6?uin=000000000&ftype=0&sort=0&pos={start}&num=40&replynum=100&g_tk=273268310&callback=_preloadCallback&code_version=1&format=jsonp&need_private_comment=1&g_tk=273268310'
res = requests.get(url=url, headers=headers)
res.encoding = 'utf-8'
html = res.text
- 使用爬虫的基本方式是用request库里的get或者post方法 ,访问一个页面到底是使用post还是get我们可以参考浏览器访问服务器的方式。因为这里浏览器采用的是Get方式访问的服务器,那我们也使用get方式。
- requests.get(url,headers)方法:
url:这里的参数填写要访问的目标网址,建议填写时从浏览器复制,避免输入错误。例如我们要爬取百度的首页,我们的url就可以写成"https://www.baidu.com"
headers:就是设置爬虫的头部信息,上面我们讲了为什么要设置,这里就不再赘述。
在执行了get方法之后会生成一个对象,我们暂且把这个对象赋值命名为res
3.网页编码规则
因为互联网这个“网”非常的大,不同的网页可能会采用不同的编码方式,我们之前看到了浏览器返回的信息中告诉了我们编码方式是‘utf-8’,所以我们这里把编码方式手动设定成为‘utf-8’,保证自己的编码方式跟服务器的相同才能保证拿到“看得懂”的数据。
4.获取网页信息
前面我们已经设置了要访问的地址以及头部信息,也告诉爬虫了我们的编码方式,那么下一步我们就要获取服务器返回的数据了。那么我们应该用什么方式来获取呢?在这里我介绍text和json这两种最常见的方法,这两种方法基本可以获取市面上98%的网页数据。 - .text方法
返回页面的原HTML代码,使用率(80%),从前面我们看到服务器响应回来的信息格式是html,那么我们就使用text接收。
- .json方法
返回页面的数据类型是json,使用率(20%),json是一种轻量级的数据格式。随着前后端分离技术的发展,json格式越来越受欢迎。当我们提取到的数据类型是Json时,我们就要提高“警惕”,因为返回类型时json格式时往往前端采用了AJAX动态刷新技术,使我们的爬取过程更为复杂。不过也有好处,动态加载出来的网页信息基本上就是我们想要的信息,换而言之,我们想要的数据就是Json数据里,我们只用解析Json数据就可以获取信息。
获取到的页面信息如下:

不方便查看我们可以去浏览器看看格式。

注意:我们此刻爬取到的信息还不能直接解析
为啥不能解析呢?因为我们拿到的字符串格式的数据,python还没有办法像字典那样读取信息。那我拿着一堆字符串干嘛,我要自己一点一点的去里边复制粘贴吗?当然不是,我们一般解析网页数据的方式有三种:1、xpath解析 2、re正则表达式 3.beautifulSoup,但第1和第3种方法是解析html标签时用的方法,对于json格式的字符串玩意还真搞不定。那正则表达式试试?
我又看了一下解析的数据,算了,评论区的大佬用正则试试吧(),我在这里使用另一种方法(字符串转字典格式)。
我们需要引入json库,使用json库中的loads方法,此方法可以把字符串解析为字典格式,使用方式也很简单,只需要把str数据直接传入里边就可以了,赶紧试试。
import json
myjson = json.loads(html)

恩?报错? 我们看看原因 ,原来是我们传入的Json格式错了,我们把html打印出来看看,找找原因。![]()
![]()
果然有错,数据的头部和尾部多了点多余的信息,我们要保证传入的字符串格式要和字典的格式是一样的,那么必须要把多余的东西给去掉,最高端的操作往往采用最朴素的方式——切片处理一下。
myjson = json.loads(html[17:-2])
重新执行一下,没有报错,说明转字典成功。那么接下来就更好办了,直接在字典里边取我们想取出来的数据。方便查看数据结构,我们可以在浏览器的开发者工具里查看。

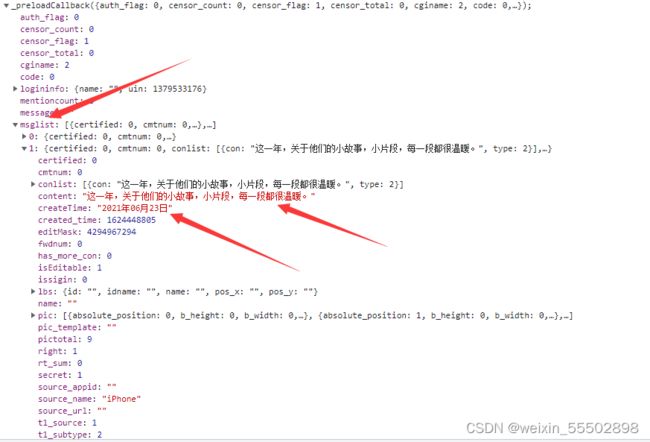
可以看出,所有的说说内容都在“msglist”中,而其中又有20个列表,每个列表中的“”代表内容,“”代表所发布的时间,在这里我只选择内容和时间进行保存,有兴趣的伙伴可以试试把评论信息一块保存下来。直接上解析代码:
mydata=[]
for i in myjson['msglist']:
mesage=[]
parrent = "[em](.*?)[/em]"
content = str(i['content']).replace(' ', '').replace('\n', '')
qu = re.findall(parrent, content, re.S)
if qu:
for j in qu:
if j != '':
target = j
content = content.replace(f'{target}', '').replace('[em]', '').replace('e/em]', '').replace(
'[/em]', '').replace(' ', '').replace('\n', '')
createTime = i['createTime']
mesage.append(content)
mesage.append(createTime)
mydata.append(mesage)
print(mydata)
打印结果:

爬虫第三部(数据存储)
我们目前已经成功拿到了数据,但每次都在控制台里查看信息显然不科学,我们需要把我们爬取到的数据永久化的存储到我们的电脑里,存储的方式也是可以按照用户的方式来选择,比如你可以选择把他存入为.txt文件、word文件、excle文件等等,因为这里的数据涉及到了分类(说说内容、发布时间)显然把他们保存成为excle文件更好查看一点。
我们此次使用csv包,也可以使用pandas生成xls文件,为了方便这里就用csv生成csv格式的文件。
import csv
title=['说说内容','发布时间']
with open('my.csv','w',encoding='utf-8-sig',newline='')as pf:
writer = csv.writer(pf)
writer.writerow(title)
writer.writerows(mydata)
- 我们在涉及到IO操作的时候推荐使用With open的方式,因为此方式可以自动的申请资源和释放资源,避免了因为忘记释放掉资源而浪费资源。
- 在open中我们传入了4个参数:
·文件路径:这里我们就把他保存在跟python文件的同一个路径下,我们直接写上文件名即可,注意要加上文件后缀。
·打开方式:这里选择’w‘模式写入。
·编码方式:设置为’utf-8-sig‘
·newline=‘’ 设置此项可以不用换行将数据写入,大家可以试试要这句代码和不要这句代码有何区别。
结果展示


我们可以用词云来分析一下,10多年来自己动态的内容
全文代码
持续更新中。。。。。
在这里插入代码片