实战:k8s之LocalDNS-2021.12.29
实战:k8s之LocalDNS-2021.12.29
目录
文章目录
-
- 实战:k8s之LocalDNS-2021.12.29
- 目录
- 实验环境
- 实验软件
- 1、DNS 优化
- 2、超时原因
-
- 2.1 内核中的 DNAT
- 2.2 问题
- 3、解决方法
- 4、性能测试
- 5、NodeLocal DNSCache
-
- 老师做的操作(了解下即可)
-
- 修改地方1:image
- 修改地方2:注意这几个参数
- 注意
-
- 注意1:go环境的安装及程序编译
- 注意2:关于镜像转存
- 注意3:老师这个镜像仓库地址是做了域名转换的吗,怎么这么短的呢?
- 关于我
- 最后
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5
实验软件
2021.12.28-实验软件-nodelocaldns
链接:https://pan.baidu.com/s/1cl474vfrXvz0hPya1EDIlQ
提取码:lpz1

1、DNS 优化
前面我们讲解了在 Kubernetes 中我们可以使用 CoreDNS 来进行集群的域名解析,但是如果在集群规模较大并发较高的情况下我们仍然需要对 DNS 进行优化,典型的就是大家比较熟悉的 **CoreDNS 会出现超时5s**的情况。
2、超时原因
⚠️ 老师说这里的超时5s故障不是很好去复现,这里解释下超时原因。
在 iptables 模式下(默认情况下,但实际在ipve下,也是解决不了这个超时问题的!),每个服务的 kube-proxy 在主机网络名称空间的 nat 表中创建一些 iptables 规则。
比如在集群中具有两个 DNS 服务器实例的 kube-dns 服务,其相关规则大致如下所示:
额,自己对iptables的知识不是很熟悉啊。。。,硬着头皮看下把。。
(1) -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
<...>
(2) -A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
<...>
(3) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-LLLB6FGXBLX6PZF7
(4) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRVEW52VMYCOUSMZ
<...>
(5) -A KUBE-SEP-LLLB6FGXBLX6PZF7 -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.6:53
<...>
(6) -A KUBE-SEP-LRVEW52VMYCOUSMZ -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.7:53
#说明:
-j代表跳转
我们知道每个 Pod 的 /etc/resolv.conf 文件中都有填充的 nameserver 10.96.0.10 这个条目。所以来自 Pod 的 DNS 查找请求将发送到 10.96.0.10,这是 kube-dns 服务的 ClusterIP 地址。
由于 (1) 请求进入 KUBE-SERVICE 链,然后匹配规则 (2),最后根据 (3) 的 random 随机模式,跳转到 (5) 或 (6) 条目,将请求 UDP 数据包的目标 IP 地址修改为 DNS 服务器的实际 IP 地址,这是通过 DNAT 完成的。其中 10.32.0.6 和 10.32.0.7 是我们集群中 CoreDNS 的两个 Pod 副本的 IP 地址。
2.1 内核中的 DNAT
DNAT 的主要职责是同时更改传出数据包的目的地,响应数据包的源,并确保对所有后续数据包进行相同的修改。后者严重依赖于连接跟踪机制,也称为 conntrack,它被实现为内核模块。conntrack 会跟踪系统中正在进行的网络连接。
conntrack(相当于一张表) 中的每个连接都由两个元组表示,一个元组用于原始请求(IP_CT_DIR_ORIGINAL),另一个元组用于答复(IP_CT_DIR_REPLY)。对于 UDP,每个元组都由源 IP 地址,源端口以及目标 IP 地址和目标端口组成,答复元组包含存储在src 字段中的目标的真实地址。
例如,如果 IP 地址为 10.40.0.17 的 Pod 向 kube-dns 的 ClusterIP 发送一个请求,该请求被转换为 10.32.0.6,则将创建以下元组:
原始:src = 10.40.0.17 dst = 10.96.0.10 sport = 53378 dport = 53
回复:src = 10.32.0.6 dst = 10.40.0.17 sport = 53 dport = 53378
通过这些条目内核可以相应地修改任何相关数据包的目的地和源地址,而无需再次遍历 DNAT 规则。此外,它将知道如何修改回复以及应将回复发送给谁。创建 conntrack 条目后,将首先对其进行确认,然后如果没有已确认的 conntrack 条目具有相同的原始元组或回复元组,则内核将尝试确认该条目。conntrack 创建和 DNAT 的简化流程如下所示:
下面这个,理解起来有些模糊

2.2 问题
o,shift,自己这一块的知识点也是盲区啊。
DNS 客户端 (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议,connect 时并不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,这时它们源 Port 相同,当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 CoreDNS 都是访问的 CLUSTER-IP,报文最终会被 DNAT 成一个具体的 Pod IP,当两个包被 DNAT 成同一个 IP,最终它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 DNS 的 Pod 副本只有一个实例的情况就很容易发生,现象就是 DNS 请求超时,客户端默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 DNS 请求有 5s 的延时。
具体原因可以参考 weave works 总结的文章 Racy conntrack and DNS lookup timeouts。
- 只有多个线程或进程,并发从同一个 socket 发送相同五元组的 UDP 报文时,才有一定概率会发生
- glibc、musl(alpine linux 的 libc 库)都使用
parallel query, 就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃 - 由于 ipvs 也使用了 conntrack, 使用 kube-proxy 的 ipvs 模式,并不能避免这个问题
3、解决方法
要彻底解决这个问题最好当然是内核上去 FIX 掉这个 BUG,除了这种方法之外我们还可以使用其他方法来进行规避,我们可以避免相同五元组 DNS请求的并发。
在 resolv.conf 中就有两个相关的参数可以进行配置:
single-request-reopen:发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突。single-request:避免并发,改为串行发送 A 类型和 AAAA 类型请求。没有了并发,从而也避免了冲突。
要给容器的 resolv.conf 加上 options 参数,有几个办法:
-
在容器的
ENTRYPOINT或者CMD脚本中,执行/bin/echo 'options single-request-reopen' >> /etc/resolv.conf(不推荐) -
在 Pod 的 postStart hook 中添加:(不推荐)
lifecycle: postStart: exec: command: - /bin/sh - -c - "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf -
使用
template.spec.dnsConfig配置:template: spec: dnsConfig: options: - name: single-request-reopen -
使用 ConfigMap 覆盖 Pod 里面的
/etc/resolv.conf:# configmap apiVersion: v1 data: resolv.conf: | nameserver 1.2.3.4 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 single-request-reopen timeout:1 kind: ConfigMap metadata: name: resolvconf --- # Pod Spec spec: volumeMounts: - name: resolv-conf mountPath: /etc/resolv.conf subPath: resolv.conf # 在某个目录下面挂载一个文件(保证不覆盖当前目录)需要使用subPath -> 不支持热更新 ... volumes: - name: resolv-conf configMap: name: resolvconf items: - key: resolv.conf path: resolv.conf
上面的方法在一定程度上可以解决 DNS 超时的问题,但更好的方式是使用本地 DNS 缓存,容器的 DNS 请求都发往本地的 DNS 缓存服务,也就不需要走 DNAT,当然也不会发生 conntrack 冲突了,而且还可以有效提升 CoreDNS 的性能瓶颈。
4、性能测试
实战开始
这里我们使用一个简单的 golang 程序来测试下使用本地 DNS 缓存的前后性能。代码如下所示:
// main.go
package main
import (
"context"
"flag"
"fmt"
"net"
"sync/atomic"
"time"
)
var host string
var connections int
var duration int64
var limit int64
var timeoutCount int64
func main() {
flag.StringVar(&host, "host", "", "Resolve host")
flag.IntVar(&connections, "c", 100, "Connections")
flag.Int64Var(&duration, "d", 0, "Duration(s)")
flag.Int64Var(&limit, "l", 0, "Limit(ms)")
flag.Parse()
var count int64 = 0
var errCount int64 = 0
pool := make(chan interface{}, connections)
exit := make(chan bool)
var (
min int64 = 0
max int64 = 0
sum int64 = 0
)
go func() {
time.Sleep(time.Second * time.Duration(duration))
exit <- true
}()
endD:
for {
select {
case pool <- nil:
go func() {
defer func() {
<-pool
}()
resolver := &net.Resolver{}
now := time.Now()
_, err := resolver.LookupIPAddr(context.Background(), host)
use := time.Since(now).Nanoseconds() / int64(time.Millisecond)
if min == 0 || use < min {
min = use
}
if use > max {
max = use
}
sum += use
if limit > 0 && use >= limit {
timeoutCount++
}
atomic.AddInt64(&count, 1)
if err != nil {
fmt.Println(err.Error())
atomic.AddInt64(&errCount, 1)
}
}()
case <-exit:
break endD
}
}
fmt.Printf("request count:%d\nerror count:%d\n", count, errCount)
fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)\n", min, max, sum/count, timeoutCount)
}
首先配置好 golang 环境,然后直接构建上面的测试应用:
go build -o testdns .
至于,如何构建自己的go环境,请查看另外一片文章:Go软件安装-已成功测试-20210413,Vscode构建Go编程环境-已成功测试-20210413
需要注意的问题,请看下文注意1:。
构建完成后生成一个 testdns 的二进制文件,然后我们将这个二进制文件拷贝到任意一个 Pod 中去进行测试:
首先这里我部署一个nginx.yaml:
[root@master1 ~]#vim nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
[root@master1 ~]#kubectl apply -f nginx.yaml
deployment.apps/nginx created
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-5d59d67564-k9m2k 1/1 Running 0 14s
nginx-5d59d67564-lbkwx 1/1 Running 0 14s
拷贝完成后进入这个测试的 Pod 中去:
[root@master1 go]#kubectl cp testdns nginx-5d59d67564-k9m2k:/root/
[root@master1 go]#kubectl exec -it nginx-5d59d67564-k9m2k -- bash
root@nginx-5d59d67564-k9m2k:/# ls -l /root/testdns
-rwxr-xr-x 1 root root 2903854 Dec 28 07:18 /root/testdns
root@nginx-5d59d67564-k9m2k:/#
我们再部署一个svc:
[root@master1 ~]#cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
ports:
- name: http
port: 5000
protocol: TCP
targetPort: 80 #相当于给上面那个nginx暴露服务
selector:
app: nginx
type: ClusterIP #默认为ClusterIP模式
[root@master1 ~]#kubectl apply -f service.yaml
service-service/nginx created
[root@master1 ~]#kubectl get svc nginx-service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-service ClusterIP 10.106.35.68 <none> 5000/TCP 58s
[root@master1 ~]#curl 10.106.35.68:5000 #可以简单来测试下
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
[root@master1 ~]#
然后我们执行 testdns 程序来进行压力测试,比如执行 200 个并发,持续 30 秒:
⚠️当然,做dns的压力测试,线上应该会有很多的程序的。,本次使用老师go写的代码来进行压测。
下面这个为老师提供的笔记里面的数据:
# 对 nginx-service.default 这个地址进行解析
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
request count:12533
error count:5
request time:min(5ms) max(16871ms) avg(425ms) timeout(475n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
request count:10058
error count:3
request time:min(4ms) max(12347ms) avg(540ms) timeout(487n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
request count:12242
error count:2
request time:min(3ms) max(12206ms) avg(478ms) timeout(644n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:11008
error count:0
request time:min(3ms) max(11110ms) avg(496ms) timeout(478n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:9141
error count:0
request time:min(4ms) max(11198ms) avg(607ms) timeout(332n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:9126
error count:0
request time:min(4ms) max(11554ms) avg(613ms) timeout(197n)
我们可以看到大部分平均耗时都是在 500ms 左右,这个性能是非常差的,而且还有部分解析失败的条目。接下来我们就来尝试使用 NodeLocal DNSCache 来提升 DNS 的性能和可靠性。
注意:自己本次测试现象数据
root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 200 -d 30 -l 5000
request count:34609
error count:0
request time:min(4ms) max(5191ms) avg(166ms) timeout(2n)
root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 200 -d 30 -l 5000
request count:31942
error count:0
request time:min(3ms) max(1252ms) avg(183ms) timeout(0n)
root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 200 -d 30 -l 5000
request count:31311
error count:0
request time:min(4ms) max(1321ms) avg(187ms) timeout(0n)
root@nginx-5d59d67564-k9m2k:~#
#我们可以看到大部分平均耗时都是在 160ms 左右,但是没有看到有看到解析失败的条目
#并发数改为1000再次测试:
root@nginx-5d59d67564-k9m2k:~# ./testdns -host nginx-service.default.svc.cluster.local -c 1000 -d 30 -l 5000
request count:24746
error count:0
request time:min(7ms) max(7273ms) avg(1138ms) timeout(52n)
root@nginx-5d59d67564-k9m2k:~#
注意:老师本次测试的现象数据

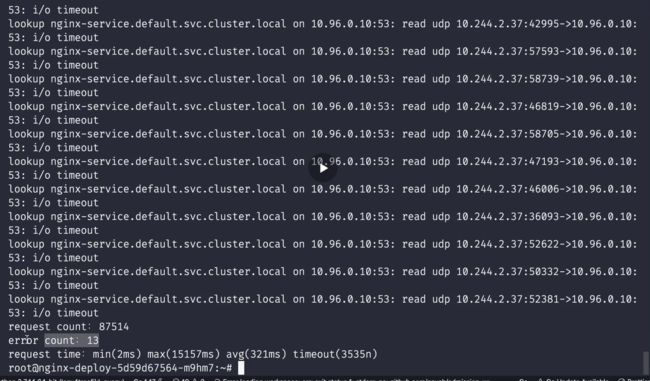
这个i/o timeout 可能在你的线上环境出现,因为你线上的业务并发可能都是很高的。
-
注意:dns压力测试不一定能测试成功,主要还和你的环境有关系。
-
注意:-l参数含义,应该是超过5s的话,有点模糊不清。。。
5、NodeLocal DNSCache
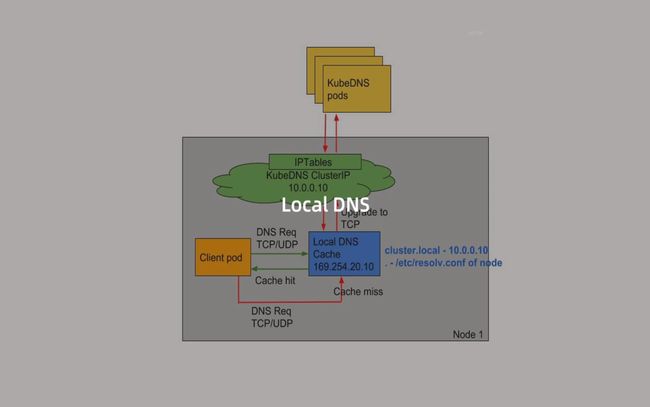
**NodeLocal DNSCache 通过在集群节点上运行一个 DaemonSet 来提高集群 DNS 性能和可靠性。**处于 ClusterFirst 的 DNS 模式下的 Pod 可以连接到 kube-dns 的 serviceIP 进行 DNS 查询,通过 kube-proxy 组件添加的 iptables 规则将其转换为 CoreDNS 端点。通过在每个集群节点上运行 DNS 缓存,NodeLocal DNSCache 可以缩短 DNS 查找的延迟时间、使 DNS 查找时间更加一致,以及减少发送到 kube-dns 的 DNS 查询次数。
在集群中运行 NodeLocal DNSCache 有如下几个好处:
- 如果本地没有 CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须到另一个节点进行解析,使用
NodeLocal DNSCache后,拥有本地缓存将有助于改善延迟。 - 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表(上面提到的5s超时问题就是这个原因造成的)
注意:这里改成TCP的话,也是可以有效果的 - 从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP,TCP conntrack 条目将在连接关闭时被删除,而 UDP 条目必须超时过后(默认
nfconntrackudp_timeout是 30 秒) - 将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)
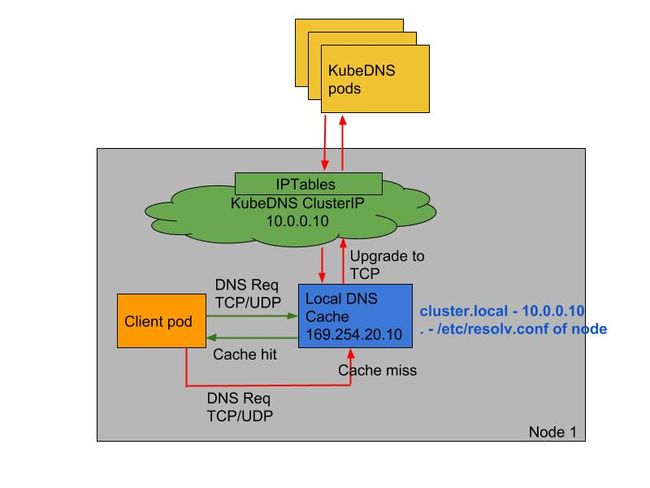
要安装 NodeLocal DNSCache 也非常简单,直接获取官方的资源清单即可:
wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
[root@master1 ~]#wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
--2021-12-28 16:38:36-- https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
Resolving github.com (github.com)... 20.205.243.166
Connecting to github.com (github.com)|20.205.243.166|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml [following]
--2021-12-28 16:38:36-- https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.111.133, 185.199.109.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 5334 (5.2K) [text/plain]
Saving to: ‘nodelocaldns.yaml’
100%[===================================================================>] 5,334 --.-K/s in 0.1s
2021-12-28 16:38:37 (51.4 KB/s) - ‘nodelocaldns.yaml’ saved [5334/5334]
[root@master1 ~]#ll nodelocaldns.yaml
-rw-r--r-- 1 root root 5334 Dec 28 16:38 nodelocaldns.yaml
[root@master1 ~]#
有可能因为网络问题下载失败,这里可以稍微等待下再次尝试。
该资源清单文件中包含几个变量值得注意,其中:
__PILLAR__DNS__SERVER__:表示 kube-dns 这个 Service 的 ClusterIP,可以通过命令kubectl get svc -n kube-system | grep kube-dns | awk'{ print $3 }'获取(我们这里就是10.96.0.10)__PILLAR__LOCAL__DNS__:表示 DNSCache 本地的 IP,默认为169.254.20.10__PILLAR__DNS__DOMAIN__:表示集群域,默认就是cluster.local
另外还有两个参数 __PILLAR__CLUSTER__DNS__ 和 __PILLAR__UPSTREAM__SERVERS__,这两个参数会通过镜像 1.21.1 版本去进行自动配置,对应的值来源于 kube-dns 的 ConfigMap 和定制的 Upstream Server 配置。直接执行如下所示的命令即可安装:
$ sed 's/k8s.gcr.io\/dns/cnych/g
s/__PILLAR__DNS__SERVER__/10.96.0.10/g
s/__PILLAR__LOCAL__DNS__/169.254.20.10/g
s/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml |
kubectl apply -f -
#注意:这个使用的是老师的镜像中转地址cnych。
可以通过如下命令来查看对应的 Pod 是否已经启动成功:
[root@master1 ~]#kubectl get po -nkube-system -l k8s-app=node-local-dns -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-local-dns-2tbfz 1/1 Running 0 100s 172.29.9.51 master1 <none> <none>
node-local-dns-7xv6x 1/1 Running 0 100s 172.29.9.53 node2 <none> <none>
node-local-dns-rxhww 1/1 Running 0 100s 172.29.9.52 node1 <none> <none>
我们导出来一个pod看下情况:
[root@master1 ~]#kubectl get po node-local-dns-2tbfz -nkube-system -oyaml
可以看到镜像地址被修改过来了:

这里可以看到显示从169.254.20.10解析地址,如果没有再去找10.96.0.10的。

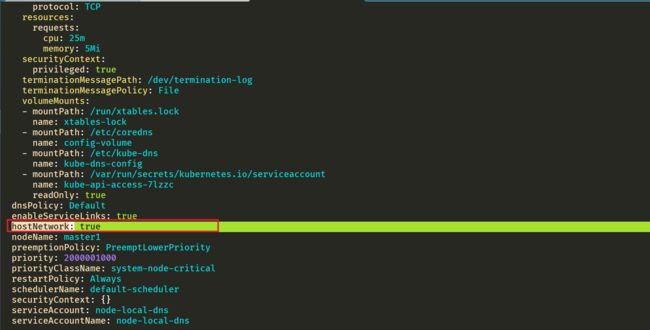
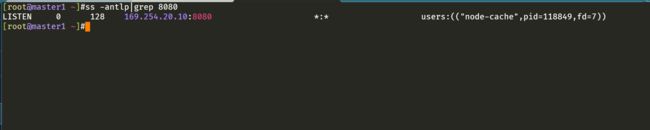
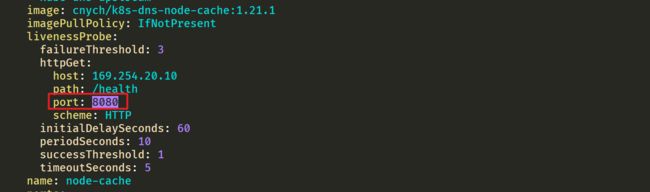
⚠️ 需要注意的是这里使用 DaemonSet 部署 node-local-dns 使用了 hostNetwork=true,会占用宿主机的 8080 端口,所以需要保证该端口未被占用。
但是到这里还没有完,如果 kube-proxy 组件使用的是 ipvs 模式的话我们还需要修改 kubelet 的 --cluster-dns 参数,将其指向 169.254.20.10,Daemonset 会在每个节点创建一个网卡来绑这个 IP,Pod 向本节点这个 IP 发 DNS 请求,缓存没有命中的时候才会再代理到上游集群 DNS 进行查询。iptables 模式下 Pod 还是向原来的集群 DNS 请求,节点上有这个 IP 监听,会被本机拦截,再请求集群上游 DNS,所以不需要更改 --cluster-dns 参数。
⚠️如果担心线上环境修改
--cluster-dns参数会产生影响,我们也可以直接在新部署的 Pod 中通过 dnsConfig 配置使用新的 localdns 的地址来进行解析。
由于我这里使用的是 kubeadm 安装的 1.22 版本的集群,所以我们只需要替换节点上 /var/lib/kubelet/config.yaml 文件中的 clusterDNS 这个参数值,然后重启即可:
sed -i 's/10.96.0.10/169.254.20.10/g' /var/lib/kubelet/config.yaml
systemctl daemon-reload && systemctl restart kubelet
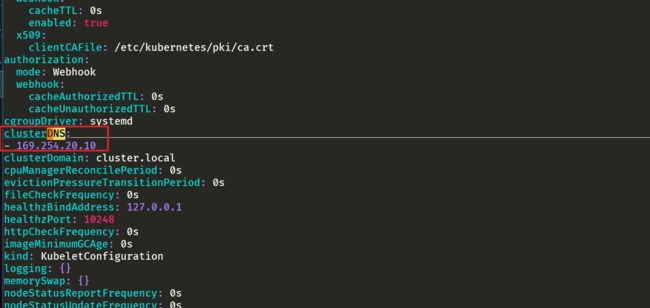
注意:all节点均要配置:
待 node-local-dns 安装配置完成后,我们可以部署一个新的 Pod 来验证下:
[root@master1 ~]#vim test-node-local-dns.yaml
# test-node-local-dns.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-node-local-dns
spec:
containers:
- name: local-dns
image: busybox
command: ["/bin/sh", "-c", "sleep 60m"]
直接部署:
[root@master1 ~]#vim test-node-local-dns.yaml
[root@master1 ~]#kubectl apply -f test-node-local-dns.yaml
pod/test-node-local-dns created
[root@master1 ~]#kubectl exec -it test-node-local-dns -- sh
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
options ndots:5
/ #
我们可以看到 nameserver 已经变成 169.254.20.10 了,当然对于之前的历史 Pod 要想使用 node-local-dns 则需要重建。
接下来我们重建前面压力测试 DNS 的 Pod,重新将 testdns 二进制文件拷贝到 Pod 中去:
[root@master1 ~]#kubectl delete -f nginx.yaml
deployment.apps "nginx" deleted
[root@master1 ~]#kubectl apply -f nginx.yaml
deployment.apps/nginx created
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-5d59d67564-kgd4q 1/1 Running 0 22s
nginx-5d59d67564-lxnt2 1/1 Running 0 22s
test-node-local-dns 1/1 Running 0 5m50s
[root@master1 ~]#kubectl cp go/testdns nginx-5d59d67564-kgd4q:/root
[root@master1 ~]#kubectl exec -it nginx-5d59d67564-kgd4q -- bash
root@nginx-5d59d67564-kgd4q:/# cd /root/
root@nginx-5d59d67564-kgd4q:~# ls
testdns
root@nginx-5d59d67564-kgd4q:~# cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
options ndots:5
root@nginx-5d59d67564-kgd4q:~#
#自己本次的测试数据
#再次压测
#先来个200个并发,测试三次
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:47344
error count:0
request time:min(1ms) max(976ms) avg(125ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:49744
error count:0
request time:min(1ms) max(540ms) avg(118ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:55929
error count:0
request time:min(2ms) max(463ms) avg(105ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~#
root@nginx-5d59d67564-kgd4q:~#
#再来个1000个并发,测试三次
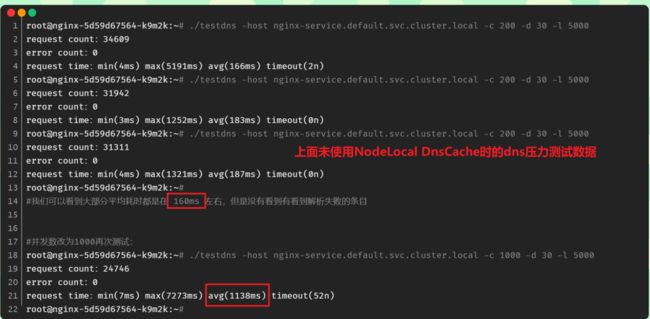
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000
request count:42177
error count:0
request time:min(16ms) max(2627ms) avg(690ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000
request count:45456
error count:0
request time:min(29ms) max(2484ms) avg(650ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000
request count:45713
error count:0
request time:min(3ms) max(1698ms) avg(647ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~#
#注意:这个1000并发测试效果就很明显了
老师笔记的测试数据:
# 拷贝到重建的 Pod 中
$ kubectl cp testdns svc-demo-546b7bcdcf-b5mkt:/root
$ kubectl exec -it svc-demo-546b7bcdcf-b5mkt -- /bin/bash
root@svc-demo-546b7bcdcf-b5mkt:/# cat /etc/resolv.conf
nameserver 169.254.20.10 # 可以看到 nameserver 已经更改
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
root@svc-demo-546b7bcdcf-b5mkt:/# cd /root
root@svc-demo-546b7bcdcf-b5mkt:~# ls
testdns
# 重新执行压力测试
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:16297
error count:0
request time:min(2ms) max(5270ms) avg(357ms) timeout(8n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:15982
error count:0
request time:min(2ms) max(5360ms) avg(373ms) timeout(54n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:25631
error count:0
request time:min(3ms) max(958ms) avg(232ms) timeout(0n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:23388
error count:0
request time:min(6ms) max(1130ms) avg(253ms) timeout(0n)
从上面的结果可以看到无论是最大解析时间还是平均解析时间都比之前默认的 CoreDNS 提示了不少的效率,所以我们还是非常推荐在线上环境部署 NodeLocal DNSCache 来提升 DNS 的性能和可靠性的。唯一的缺点就是由于 LocalDNS 使用的是 DaemonSet 模式部署,所以如果需要更新镜像则可能会中断服务(不过可以使用一些第三方的增强组件来实现原地升级解决这个问题,比如 openkruise-阿里云开源的一个增强套件。)。
阿里云也是比较推荐线上去部署这个的。
老师做的操作(了解下即可)
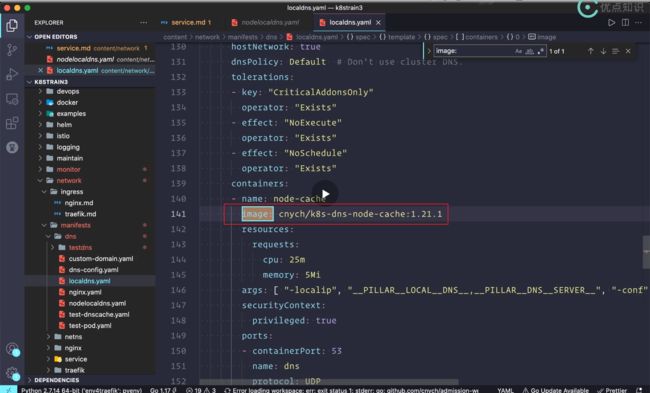
修改地方1:image
修改image地址:
默认的镜像地址:

老师做了镜像转存后自己的地址:
修改地方2:注意这几个参数
__PILLAR__DNS__DOMAIN__
__PILLAR__DNS__SERVER__ :表示 kube-dns 这个 Service 的 ClusterIP,可以通过命令 kubectl get svc -n kube-system | grep kube-dns | awk'{ print $3 }' 获取(我们这里就是 10.96.0.10)

[root@master1 ~]#kubectl get svc -nkube-system |grep kube-dns
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 58d
[root@master1 ~]#kubectl get svc -nkube-system |grep kube-dns |awk '{print $3}'
10.96.0.10
[root@master1 ~]#
__PILLAR__LOCAL__DNS__:表示 DNSCache 本地的 IP,默认为169.254.20.10
__PILLAR__LOCAL__DNS__:表示 DNSCache 本地的 IP,默认为 169.254.20.10
这个相当于一个虚拟ip,后面会做一个中转的。

__PILLAR__DNS__DOMAIN__:表示集群域,默认就是cluster.local
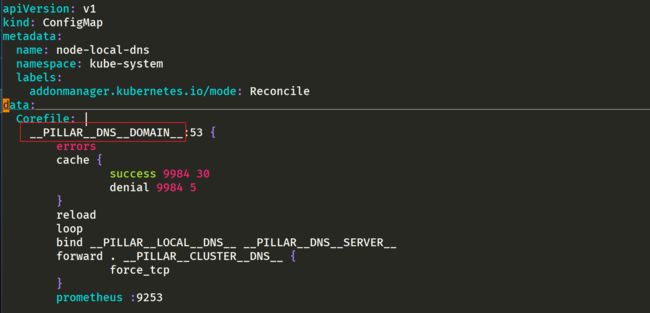
- 注意
另外还有两个参数 __PILLAR__CLUSTER__DNS__ 和 __PILLAR__UPSTREAM__SERVERS__,这两个参数会通过镜像 1.15.16 版本去进行自动配置,对应的值来源于 kube-dns 的 ConfigMap 和定制的 Upstream Server 配置。





注意
注意1:go环境的安装及程序编译

自己学了一点go基础。在master01上安装好go环境后,把代码copy进去并运行发现报错了,如下:
缺少go.mod文件,自己现在用的是新版本:go version go1.16.2 linux/amd64

解决办法:完美解决。
在代码所在父目录下创建go.mod文件
[root@master1 go]#pwd
/root/go
[root@master1 go]#ls
main.go
[root@master1 go]#cd /root
[root@master1 ~]#go mod init module #在代码所在父目录下创建go.mod文件
go: creating new go.mod: module module
go: to add module requirements and sums:
go mod tidy
[root@master1 ~]#ll go.mod
-rw-r--r-- 1 root root 23 Dec 28 13:17 go.mod
[root@master1 ~]#cd go/
[root@master1 go]#go build -o testdns .
[root@master1 go]#ll -h testdns
-rwxr-xr-x 1 root root 2.8M Dec 28 13:17 testdns
[root@master1 go]#
这个是在linux下构建的代码,当然在windows下也是可以构建的。
或者在winodws go环境下编译也是可以的:
不管是在linux环境下吗,还是windows环境下,还是旧版本或新版本go环境,代码只需要写一份就可以。
⚠️ 注意:老师有说过,当时他在mac下如果直接编译代码的吗,生成的二进制文件只适合mac。
因为我们的pod是在linux下跑的,因此这里要指定下linux再编译代码。

那么问题来了,我在winodws下构建的代码,要不要也指定这个参数呢??
本次直接使用老师的命令在linux下直接编译即可:
[root@master1 go]#pwd
/root/go
[root@master1 go]#ls
main.go
[root@master1 go]#GOOS=linux GOARCH=amd64 go build -o testdns .
[root@master1 go]#ll
total 2840
-rw-r--r-- 1 root root 1904 Dec 27 15:58 main.go
-rwxr-xr-x 1 root root 2903854 Dec 28 15:13 testdns
[root@master1 go]#
这里,这个压测软件testdns已经给你准备好了,可以直接使用。

⚠️还有个问题:就是关于linux下go环境不生效问题,需要再次source下,记得之前是没问题的啊,这次配置就有问题,奇怪……后面再排查下。
注意2:关于镜像转存
[root@master1 ~]#vim nodelocaldns.yaml
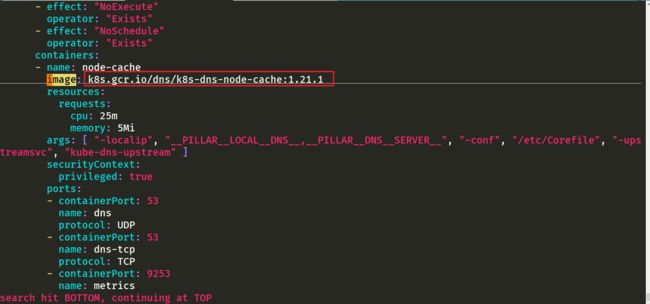
我们要把这个地址替换下,我们要做个镜像中转。
来到如下这个网址:
https://katacoda.com/
katacoda.com也是一个比较好的学习网站。
使用github账号登录网站即可:


这个是外国网站,还是比较慢的:

这里使用科学上网:
这里它可能也是起了一个pod或者容器。
我们把k8s.gcr.io/dns/k8s-dns-node-cache:1.21.1镜像给它拉取下来:
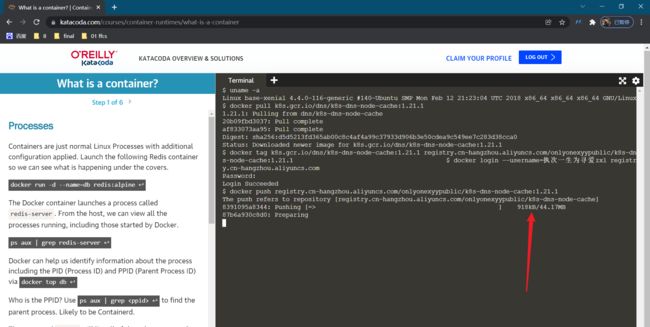
这个推的速度太慢了。。。。但是老师的为啥这么快呢?难道是因为老师的那个镜像仓库地址是全球可达的,做了域名转换的吗(cdn加速的吗)?
- 如何转存镜像?
[root@xyy admin]#docker pull k8s.gcr.io/dns/k8s-dns-node-cache:1.21.1
Error response from daemon: Get "https://k8s.gcr.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
[root@xyy admin]#
注意,这个镜像地址k8s-dns-node-cache:1.21.1没在dockerhub仓库源,也没在阿里的镜像仓库源。
- 感觉push的速度好慢啊:。。。


注意:现在的时间 2021年12月29日05:22:35这个push的速度会快些的,f**k,但是后面还是推送失败了。。。

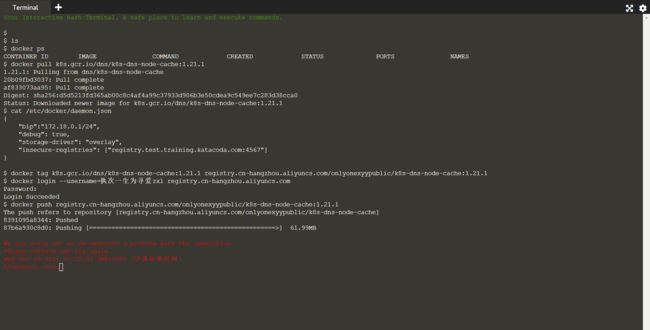
- 老师这里已经做好了镜像转存,我这里再推送到自己仓库下。
查看之前从老师做好的镜像转存那里下载好的镜像:

[root@master1 ~]#ctr -n k8s.io i ls -q|grep k8s-dns-node-cache
docker.io/cnych/k8s-dns-node-cache:1.21.1
docker.io/cnych/k8s-dns-node-cache@sha256:04c4f6b1f2f2f72441dadcea1c8eec611af4d963315187ceb04b939d1956782f
nerdctl -n k8s.io images|grep k8s-dns-node-cache
#注意:ctr命令和nerdctl命令在k8s里使用都是需要加上,-n k8s.io命名空间的。

开始转存:
#登录自己的阿里云仓库
[root@master1 ~]#nerdctl login --username=执次一生为寻爱zxl registry.cn-hangzhou.aliyuncs.com
Enter Password: Login Succeeded
#重新打tag
[root@master1 ~]#nerdctl -n k8s.io tag cnych/k8s-dns-node-cache:1.21.1 registry.cn-hangzhou.aliyuncs.com/onlyonexyypublic/k8s-dns-node-cache:1.21.1
#注意:打好的tag也是在-n k8s.io下的。
[root@master1 ~]#nerdctl -n k8s.io images|grep k8s-dns-node-cache
……
cnych/k8s-dns-node-cache 1.21.1 04c4f6b1f2f2 10 hours ago 104.3 MiB
registry.cn-hangzhou.aliyuncs.com/onlyonexyypublic/k8s-dns-node-cache 1.21.1 04c4f6b1f2f2 About a minute ago 104.3 MiB
[root@master1 ~]#
#开始push
[root@master1 ~]#nerdctl -n k8s.io push registry.cn-hangzhou.aliyuncs.com/onlyonexyypublic/k8s-dns-node-cache:1.21.1
INFO[0000] pushing as a single-platform image (application/vnd.docker.distribution.manifest.v2+json, sha256:04c4f6b1f2f2f72441dadcea1c8eec611af4d963315187ceb04b939d1956782f)
manifest-sha256:04c4f6b1f2f2f72441dadcea1c8eec611af4d963315187ceb04b939d1956782f: waiting |--------------------------------------|
layer-sha256:af833073aa9559031531fca731390d329e083cccc0b824c236e7efc5742ae666: waiting |--------------------------------------|
config-sha256:5bae806f8f123c54ca6a754c567e8408393740792ba8b89ee3bb6c5f95e6fbe1: waiting |--------------------------------------|
layer-sha256:20b09fbd30377e1315a8bc9e15b5f8393a1090a7ec3f714ba5fce0c9b82a42f2: waiting |--------------------------------------|
elapsed: 0.8 s total: 0.0 B (0.0 B/s)
[root@master1 ~]#
发现已经成功推送了:
docker pull registry.cn-hangzhou.aliyuncs.com/onlyonexyypublic/k8s-dns-node-cache:1.21.1

自己下去拉取测试下吧:
我这里在云虚机上拉取测试下:

注意3:老师这个镜像仓库地址是做了域名转换的吗,怎么这么短的呢?
自己阿里云镜像服务地址:
docker pull registry.cn-hangzhou.aliyuncs.com/onlyonexyypublic/k8s-dns-node-cache:[镜像版本号]
老师自己的镜像地址:
哦,原来在这里,包括前面那个中转速度慢的原因。这个后面再看把!!!

关于我
我的博客主旨:我希望每一个人拿着我的博客都可以做出实验现象,先把实验做出来,然后再结合理论知识更深层次去理解技术点,这样学习起来才有乐趣和动力。并且,我的博客内容步骤是很完整的,也分享源码和实验用到的软件,希望能和大家一起共同进步!
各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人免费帮您解决问题:
-
个人微信二维码:x2675263825 (舍得), qq:2675263825。

-
个人博客地址:www.onlyonexl.cn

-
个人微信公众号:云原生架构师实战

-
个人csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
-
个人github主页:https://github.com/OnlyOnexl

最后
好了,关于LocalDNS实验就到这里了,感谢大家阅读,最后贴上我女神的photo,祝大家生活快乐,每天都过的有意义哦,我们下期见!
