论文阅读VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
文章目录
-
- VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
-
- 研究动机:
- Abstract
- 本文提出方法:
- 具体流程
-
- 1. Masked Autoencoders Are Scalable Vision Learners
- 2. Characteristics of Video Data
- 3. VideoMAE
- Experiments
-
- Datasets
- Ablation Studies
- Conclusion
研究动机:
目前视频模型都依赖图像数据集的预训练权重,如何在不使用任何预训练的模型和的额外图像数据情况下,在视频数据集本身上有效高效地训练一个VIT
把MAE扩展到视频领域,相比于原来的MAE区别主要在于更高的mask率(90%、95%)、每帧的mask一样(即沿时间维度同一位置patch都被mask掉),mask一些patch,通过encoder-decoder根据这些少量数据来重建出原始图像,整个过程不需要label和其他数据集是一个自监督过程
Abstract
为了在相对较小的数据集上实现最佳性能,通常需要对超大规模数据集上的video transformers进行预训练。在本文中,我们展示了video masked autoencoders(VideoMAE)是用于自监督视频预训练(SSVP)的数据高效学习者。我们受到最近ImageMAE[31]的启发,提出了特定的video tube masking带有极高的比例。这种简单的设计使video reconstruction 成为更具挑战性和有意义的自我监督任务,从而鼓励在预训练过程中提取更有效的video representations 。我们用VideoMAE得到了三个重要的发现:(1)极高的掩蔽比比例(即90%-95%)仍然为VideoMAE提供了良好的性能。视频内容具有时间冗余性,比图像具有更高的掩蔽比。(2) VideoMAE在非常小的数据集(即大约3k-4k视频)上取得了令人印象深刻的结果,而不使用任何额外的数据。这部分归因于视频重建的挑战性任务,以加强高水平的结构学习。(3) VideoMAE显示,对于SSVP,数据质量比数据数量更重要。预训练数据集和目标数据集之间的域转移是一个重要因素。 值得注意的是,在不使用任何额外数据的情况下,我们的具有vanilla ViT主干的VideoMAE可以在kinect -400上达到87.4%,在SomethingSomething V2上达到75.4%,在UCF101上达到91.3%,在HMDB51上达到62.6%。
本文提出方法:
本文提出了一个自监督视频预训练方法(SSVP) ——video masked autoencoders(VideoMAE),VideoMAE继承了 masking random cubes和reconstructing the missing ones的简单pipeline,但视频的时间维度使他们不同于图像中的遮挡,原因如下:
- 时间冗余会造成更多地关注静态或局部变化缓慢的运动特征
- 时间相关会使模型仅仅学习低语义的时间对应关系特征,而不能高级推理
具体做法:
1.为解决视频的时间冗余,我们使用极高遮掩比从下采样片段中删除cubes
2.考虑到时间相关性,设计了tube masking为提高在重建时有无motion的cubes信息丢失的风险
本文所使用数据集: Something-Something ;UCF101 ;HMDB51
本文贡献:
-
提出一个极高比例的tube masking带来性能上的提升
-
在不需要额外数据情况下,可以在小规模视频数据集上实现很好的结果
-
当源数据集和目标数据集之间存在域转移时,VideoMAE表明数据质量比数据数量更重要
视频发展流程:
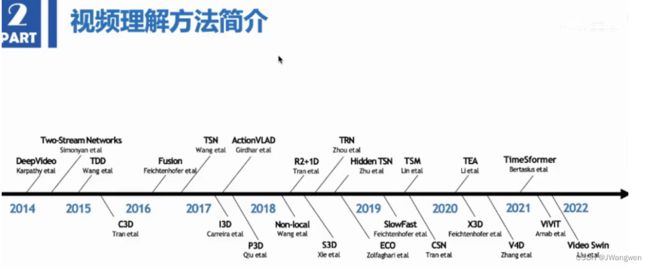
具体流程
1. Masked Autoencoders Are Scalable Vision Learners
masked: masked来源于BERT,每次挖掉一些东西然后去预测被挖掉的东西
Autoencoder: 这里的auto不是自动的意思,而是“自”的意思,标号和样本(y和x)来自于同一个东西。 在NLP中,大家都是可以理解的,但是在计算机视觉中,图片的标号很少来自图片本身,所以作者在这里加上了auto,意在指出和计算机视觉中其他的encoder相比,这里的标号也就是图片本身,这样能跟之前的很多工作区分开来
MAE模型结构:随机mask输入图片的部分patches,然后重构这些缺失的像素。
两个核心设计:
-
非对称的Encoder-Decoder
Encoder只作用在可见的patch中,Decoder重构被mask的patch
-
遮盖大量的块(比如75%)
迫使模型去学习一些更好的特征,从而得到一个较好的自监督训练效果

一张 224x224的输入图像首先被分成大小为 16 ×16 的非重叠的块(token)------>每个像素块(token)会经过块嵌入(token embedding)的操作被转化为高维特征------>MAE采用较高的掩码比率 (75%) 随机遮盖掉一部分的像素块(token),将剩余的像素块送到编码器(encoder)中进行特征提取------>将Encoder提取出来的特征块与另一部分预设的可学习的像素块(learnable mask token)进行拼接,构成和原始输入图像尺寸一样大的特征送入decoder----->最终输出原图像,loss计算在masked patches上进行
2. Characteristics of Video Data

Temporal redundancy
时间冗余会造成更多地关注静态或局部变化缓慢的运动特征,encoder backbone不能有效地捕获运动表示
如果采用原始视频的密集帧率(例如 30 FPS)进行预训练,则训练效率会非常低,因为这将使我们更多地关注静态或局部变化缓慢的运动特征。
Temporal correlation
时间相关性会影响推理能力,仅仅学习低语义的时间对应关系特征,而不是高层抽象语义信息提取
3. VideoMAE
Our VideoMAE takes the downsampled frames as inputs and uses the cube embedding to obtain video tokens.

对原始视频片段进行时序下采样-----> 采用时空块嵌入将原始视频数据转为视觉像素块----->对视觉像素块进行极高比例(90-95%)的tube masking------> 采用带有时空联合注意力机制的自编码器重建视频像素块
Temporal downsampling —— use the strided temporal sampling
首先从原始视频 V V V中随机采样一个由 T T T 个连续帧组成的视频片段,然后使用带有时序间隔采样将视频片段压缩为帧,每个帧包含HxWx3个像素。实验中采样间隔 τ τ τ 设为4和2
Cube embedding —— the joint space-time cube embedding
将 T X H X W T X H X W TXHXW的视频片段中每个大小为2×16×16的cube视为一个token embedding,因此,采样得到的视频片段经过时空块嵌入(cube embedding)层后可以得到个视觉像素块。在这个过程中,同时会将视觉像素块的通道维度映射为 D D D。这种设计可以减少输入数据的时空维度大小,一定程度上也有助于缓解视频数据的时空冗余性。

Tube masking with extremely high ratios
tube maskinig是为了解决信息泄露问题,具体来说,管道式掩码策略可以表示为 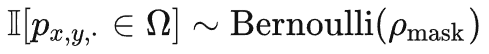 。不同的时间t共享相同的值,相同空间位置的token将总是会被掩码。所以对于一些视觉像素块(例如,不同掩码策略的示例图第 4 行的包含手指的像素块),网络将无法在其他帧中找到其对应的部分。这种设计这有助于减轻重建过程中出现「信息泄露」的风险,可以让VideoMAE通过提取原始视频片段中的高层语义信息,来重建被掩码的token。
。不同的时间t共享相同的值,相同空间位置的token将总是会被掩码。所以对于一些视觉像素块(例如,不同掩码策略的示例图第 4 行的包含手指的像素块),网络将无法在其他帧中找到其对应的部分。这种设计这有助于减轻重建过程中出现「信息泄露」的风险,可以让VideoMAE通过提取原始视频片段中的高层语义信息,来重建被掩码的token。
joint space-time attention
前文中提到了VideoMAE采用了极高的掩码率,只保留了极少的token作为编码器的输入。为了更好地提取这部分保留token的高级时空特征,VideoMAE选择使用原始的ViT作为Backbone,同时在注意力层中采用时空联合自注意力(即不改变原始ViT的模型结构)。因此所有保留token都可以在自注意层中相互交互。时空联合自注意力机制的![]() 级别的计算复杂度是网络的计算瓶颈,而前文中针对VideoMAE使用了极高掩码比率策略,仅将未被遮蔽的token(例如10%)输入到编码器中。这种设计一定程度上可以有效地缓
级别的计算复杂度是网络的计算瓶颈,而前文中针对VideoMAE使用了极高掩码比率策略,仅将未被遮蔽的token(例如10%)输入到编码器中。这种设计一定程度上可以有效地缓![]() 级别的计算复杂度的问题。
级别的计算复杂度的问题。
框架设计:
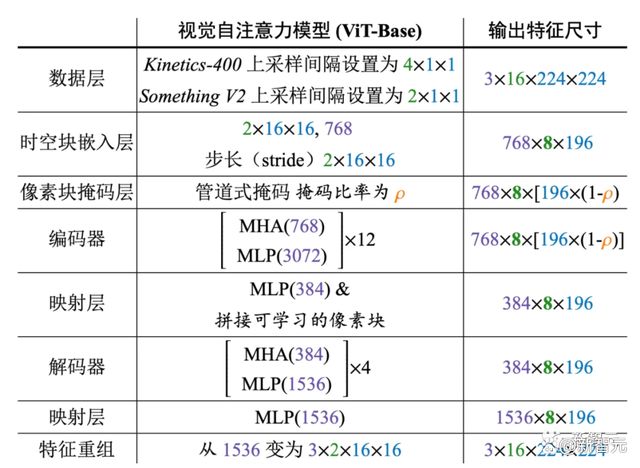
Experiments
Datasets
K-400: 240k training videos and 20k validation videos of 10s from 400 classes
Something-Something V2 : having around 169k videos for training and 20k videos for
validation,与K400不同的是这个数据集包含174个以动作为中心的动作类。
UCF101: 9.5k/3.5k train/val videos
HMDB51: 3.5k/1.5k train/val videos
AVA: 一个具有211k训练和57k验证视频片段的人类动作时空定位数据集。
Ablation Studies
默认选项是灰色 16帧 ViT-B backbone 在SSV2和K400
16-frame vanilla ViT-B mask ratio ρ=90% for 800 epochs 在微调后进行评估时,在 Something-Something V2 上选择2个视频片段和3次裁剪进行测试,在Kinetics-400上选择5个视频片段和3次裁剪进行测试。
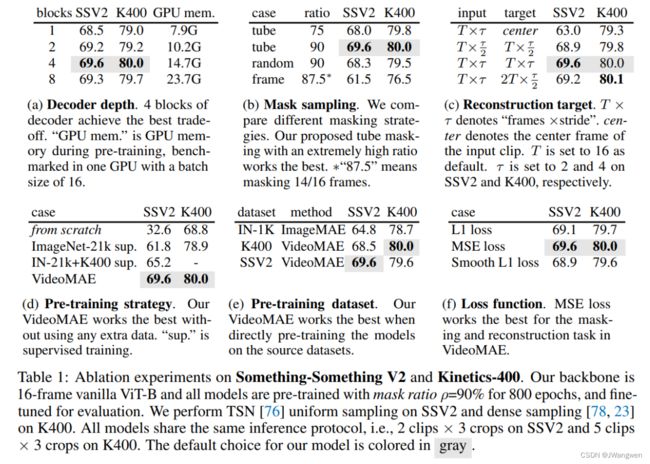
Decoder design :
VideoMAE关键部分,VideoMAE中更深的解码器可以取得更好的性能,而深度较浅的解码器可以有效地降低 GPU 的显存占用。默认为4blocks,解码器宽度设置为编码器的半通道(例如,384-d为ViT-B)
Masking strategy :
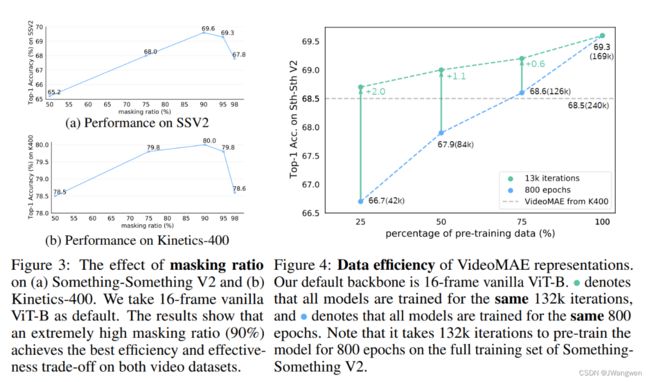
全局随机掩码和随机掩码图像帧的性能劣于tube masking策略,将掩码比率增加到 90% 性能有所提升
Reconstruction target :
如果只使用视频片段中的中心帧作为重建目标,VideoMAE在下游任务中的性能会大大降低。默认重建目标为下采样clip
Pre-training strategy :
利用VideoMAE从视频数据集本身预训练得到的ViT,在不使用任何额外的数据的条件下,最终能达到 69.6% 的最佳性能。Kinetics-400 上也有相似的结论。
Pre-training dataset :
首先按照MAE的设置,在 ImageNet-1K 上对ViT自监督预训练 1600 epoch。然后利用I3D中的策略,将 2D 块嵌入层膨胀为3D 时空块嵌入层,并在视频数据集上微调模型。这种训练范式可以超过从头有监督训练的模型。紧接着,将MAE预训练的模型与在 Kinetics-400 上VideoMAE预训练的ViT模型的性能进行了比较。可以发现VideoMAE可以实现比MAE更好的性能。然而这两种预训练模型均未能取得比仅在Something-Something V2 数据集上进行自监督预训练的VideoMAE更好的性能。由此可以分析,预训练数据集和目标数据集之间的领域差异可能是一个重要问题。
**masking ratio :**90% best
AVA上结果:
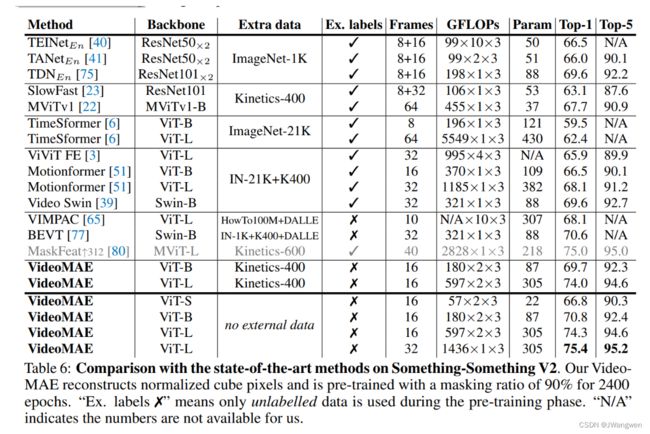
SSV2:
Conclusion
本文的方法主要在high masking ratio 和 tube masking strategy 上进行设计
Future work: VideoMAE仅利用RGB video stream,未来希望声音和文本数据能提供更多信息。
多模态对比学习用于从噪声文本监督中学习视频表示
some multimodal contrastive learning methods [37, 43, 63] have been developed
to learn video representation from noisy text supervision.