hadoop+zookeeper+hbase+hive
hadoop安装配置
-
hadoop安装文档:https://blog.csdn.net/pucao_cug/article/details/71698903
-
zookeeper安装文档:https://blog.csdn.net/pucao_cug/article/details/72228973
-
hbase安装文档:https://blog.csdn.net/pucao_cug/article/details/72229223
-
hive安装文档:https://blog.csdn.net/pucao_cug/article/details/71773665
一、集群部署介绍
1.1 Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任 务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
hadoop生态圈:
1.1.1 HDFS(Hadoop分布式文件系统)
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。
HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
1.1.2 Mapreduce(分布式计算框架)
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种分布式计算模型,用以进行大数据量的计算。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分,
其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
1.1.3 HBASE(分布式列存数据库)
源自Google的Bigtable论文,发表于2006年11月,HBase是Google Bigtable克隆版
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
1.1.4 Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
1.1.5 HIVE(数据仓库)
由facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务
1.1.6 Pig(ad-hoc脚本)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具
Pig定义了一种数据流语言—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
其编译器将Pig Latin翻译成MapReduce程序序列将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
1.1.7 Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
1.1.8 Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。当然也可以用于收集其他类型数据
1.1.9 Mahout(数据挖掘算法库)
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。
Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。
除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
1.1.10 Oozie(工作流调度器)
Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。
Oozie使用hPDL(一种XML流程定义语言)来描述这个图。
1.1.11 Yarn(分布式资源管理器)
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。 Yarn是下一代 Hadoop 计算平台,yarn是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行。 用于自己编写的框架作为客户端的一个lib,在运用提交作业时打包即可。该框架为提供了以下几个组件:
-
资源管理:包括应用程序管理和机器资源管理
-
资源双层调度
-
容错性:各个组件均有考虑容错性
-
扩展性:可扩展到上万个节点
- Mesos(分布式资源管理器)
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache项目,当前有一些公司使用Mesos管理集群资源,比如Twitter。
与yarn类似,Mesos是一个资源统一管理和调度的平台,同样支持比如MR、steaming等多种运算框架。
1.1.12 Tachyon(分布式内存文件系统)
Tachyon(/'tæki:ˌɒn/ 意为超光速粒子)是以内存为中心的分布式文件系统,拥有高性能和容错能力,
能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。
Tachyon诞生于UC Berkeley的AMPLab。
1.1.13 Tez(DAG计算模型)
Tez是Apache最新开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,
即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,
这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
目前hive支持mr、tez计算模型,tez能完美二进制mr程序,提升运算性能。
1.1.14 Spark(内存DAG计算模型)
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。
最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。
Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍
1.1.15 Giraph(图计算模型)
Apache Giraph是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
最早出自雅虎。雅虎在开发Giraph时采用了Google工程师2010年发表的论文《Pregel:大规模图表处理系统》中的原理。后来,雅虎将Giraph捐赠给Apache软件基金会。
目前所有人都可以下载Giraph,它已经成为Apache软件基金会的开源项目,并得到Facebook的支持,获得多方面的改进。
1.1.16 GraphX(图计算模型)
Spark GraphX最先是伯克利AMPLAB的一个分布式图计算框架项目,目前整合在spark运行框架中,为其提供BSP大规模并行图计算能力。
1.1.17 MLib(机器学习库)
Spark MLlib是一个机器学习库,它提供了各种各样的算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等。
1.1.18 Streaming(流计算模型)
Spark Streaming支持对流数据的实时处理,以微批的方式对实时数据进行计算
1.1.19 Kafka(分布式消息队列)
Kafka是Linkedin于2010年12月份开源的消息系统,它主要用于处理活跃的流式数据。
活跃的流式数据在web网站应用中非常常见,这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。
这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
1.1.20 Phoenix(hbase sql接口)
Apache Phoenix 是HBase的SQL驱动,Phoenix 使得Hbase 支持通过JDBC的方式进行访问,并将你的SQL查询转换成Hbase的扫描和相应的动作。
1.1.21 ranger(安全管理工具)
Apache ranger是一个hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的hadoop生态圈的所有数据权限。
1.1.22 knox(hadoop安全网关)
Apache knox是一个访问hadoop集群的restapi网关,它为所有rest访问提供了一个简单的访问接口点,能完成3A认证(Authentication,Authorization,Auditing)和SSO(单点登录)等
1.1.23 falcon(数据生命周期管理工具)
Apache Falcon 是一个面向Hadoop的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。它使终端用户可以快速地将他们的数据及其相关的处理和管理任务“上载(onboard)”到Hadoop集群。
1.1.24 Ambari(安装部署配置管理工具)
Apache Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具。
1.2 环境说明
我的环境是在虚拟机中配置的,Hadoop集群中包括3个节点:1个Master,2个Salve,节点之间局域网连接,可以相互ping通,节点IP地址分布如下:
| 系统版本 | 主机名 | ip | 角色 |
|---|---|---|---|
| centos7.0 | nodea | 192.168.47.136 | 主机 |
| centos7.0 | nodeb | 192.168.47.137 | 从机 |
| centos7.0 | nodec | 192.168.47.138 | 从机 |
大数据平台版本
| 名称 | 版本 | 下载地址 | 说明 |
|---|---|---|---|
| hadoop | 2.8.0 | https://archive.apache.org/dist/hadoop/core/ | 大数据 |
| zookeeper | 3.4.10 | http://mirror.bit.edu.cn/apache/zookeeper/ | 分布式协调组件 |
| hbase | 1.2.6 | http://mirror.bit.edu.cn/apache/hbase/ | 基于hdfs的数据库 |
| hive | 2.3.3 | http://mirrors.hust.edu.cn/apache/hive/stable-2/ | 数据仓库 |
1.2.1 资源下载
所需资源hadoop、hbase、zookeeper、jdk
1、JKD下载地址:http://pan.baidu.com/s/1i5NpImx
2、hadoop下载:https://archive.apache.org/dist/hadoop/core/
3、hbase下载:http://mirror.bit.edu.cn/apache/hbase/
4、zookeeper下载:http://mirror.bit.edu.cn/apache/zookeeper/
5、hive下载:http://mirrors.hust.edu.cn/apache/hive/stable-2/
1.3 环境配置
1.3.1 修改主机名
[root@nodea hadoop]# vi /etc/hostname
-------------------------------------------------------------------
文本内容修改为:
nodea
-------------------------------------------------------------------
[root@nodea hadoop]# vi /etc/sysconfig/network
-------------------------------------------------------------------
HOSTNAME=nodea
-------------------------------------------------------------------
[root@nodea hadoop]# vi /etc/hosts
-------------------------------------------------------------------
新增
192.168.47.129 nodeb
192.168.47.131 nodec
192.168.47.130 nodea
移除
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
-------------------------------------------------------------------
这里如果不移除127.0.0.1,启动hadoop,hdfs上传文件会报错
报错信息如下:
2018-06-11 10:43:33,970 WARNorg.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server:nodea/192.168.47.130:8020
2018-06-11 10:43:55,009 INFOorg.apache.hadoop.ipc.Client: Retrying connect to server:nodea/192.168.47.130:8020. Already tried 0 time(s); retry policy isRetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2018-06-11 10:43:56,012 INFOorg.apache.hadoop.ipc.Client: Retrying connect to server:nodea/192.168.47.130:8020. Already tried 1 time(s); retry policy isRetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
nodeb、nodec分别执行一遍上述操作,主机名修改为nodeb、nodec
1.3.2 安装JDK
1、查看安装:
rpm -qa | grep jdk 查看所有已安装jdk
-------------------------------------------------------------------
java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.i686
-------------------------------------------------------------------
#卸载jdk
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.i686
上传jdk,解压、配置环境变量
-------------------------------------------------------------------
export JAVA_HOME=/opt/jdk8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
-------------------------------------------------------------------
二、SSH无密码验证配置
2.1 nodea、nodeb、nodec上生成密钥对
[root@nodea hadoop]# ssh-keygen -t rsa #一路回车就行
Generating public/private rsa key pair.
Enter file in which to save the key (/home/test/.ssh/id_rsa):
Created directory '/home/test/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/test/.ssh/id_rsa.
Your public key has been saved in /home/test/.ssh/id_rsa.pub.
The key fingerprint is:
3a:da:74:04:44:ad:2d:7d:df:b1:f6:5f:96:1b:f6:b2 [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| .o. |
| . . |
| .+ |
| o.o . . |
| .S. . . o |
| o . + .|
| + . . =o|
| + o o.*|
| . . E++|
+-----------------+
--------------------------------------------------
[root@nodea hadoop]# ls -la .ssh
总用量 16
drwx------ 2 usera usera 4096 8月 24 09:22 .
drwxrwx--- 12 usera usera 4096 8月 24 09:22 ..
-rw------- 1 usera usera 1675 8月 24 09:22 id_rsa
-rw-r--r-- 1 usera usera 399 8月 24 09:22 id_rsa.pub
2.2 免密登录配置
2.2.1 配置nodea--》nodeb免密登录
- nodea上执行:
[root@nodea hadoop]# ssh-copy-id root@nodeb 用户名@主机名/ip
The authenticity of host '10.124.84.20 (10.124.84.20)' can't be established.
RSA key fingerprint is f0:1c:05:40:d3:71:31:61:b6:ad:7c:c2:f0:85:3c:cf.
Are you sure you want to continue connecting (yes/no)? yes ##提示是否继续链接,输入yes
Warning: Permanently added '10.124.84.20' (RSA) to the list of known hosts.
[email protected]'s password: ##输入slave的hadoop用户密码
Now try logging into the machine, with "ssh '[email protected]'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
2.2.2 配置nodeb--》nodea免密登录
- nodeb上执行
[root@nodea hadoop]# ssh-copy-id root@nodea 用户名@主机名/ip
The authenticity of host '10.124.84.20 (10.124.84.20)' can't be established.
RSA key fingerprint is f0:1c:05:40:d3:71:31:61:b6:ad:7c:c2:f0:85:3c:cf.
Are you sure you want to continue connecting (yes/no)? yes ##提示是否继续链接,输入yes
Warning: Permanently added '10.124.84.20' (RSA) to the list of known hosts.
[email protected]'s password: ##输入slave的hadoop用户密码
Now try logging into the machine, with "ssh '[email protected]'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
这个时候nodeb下root用户的公钥文件内容会追加写入到nodea下root用户的 .ssh/authorized_keys 文件中
这样做完之后我们就可以免密码登录了
这里需要按照这种模式配置三台机器相互免密登录。例:nodea-》nodea nodea-》nodeb nodea-》nodec
2.3 免密登录测试
执行 ssh nodeb 如果不需要输入nodeb的密码就可远程连接,则配置成功。 否则删除.ssh目录重新配置。
2.4 关闭防火墙
- 如果linux系统是centos7.0以下的版本执行如下命令
#临时关闭防火墙(重启后失效)
service iptables stop
#关闭开机自启防火墙(重启后生效)
chkconfig iptables off
#查看防火墙状态
service iptables status
- 如果linux系统是centos7.0及以上版本,执行如下命令
#临时关闭
systemctl stop firewalld
#禁止开机启动
systemctl disable firewalld
#查看防火墙状态
systemctl status firewalld
三、hadoop集群搭建
3.1 创建文件目录
/opt/apps /root/hadoop/tmp /root/hadoop/var /root/hadoop/dfs/name /root/hadoop/dfs/data
nodea、nodeb、nodec都需要创建
3.2 下载上传hadoop镜像
这里我选择的hadoop-2.8.0 上传到/opt/resource文件夹下,
[root@nodea resource]# tar -zxvf hadoop-2.8.0.tar.gz #解压到当前目录
[root@nodea resource]# mv -r /opt/resource/hadoop-2.8.0 /opt/apps/hadoop-2.8.0
3.3 配置环境变量
[root@nodea hadoop]# vi /etc/profile
-------------------------------------------------------------------
export JAVA_HOME=/opt/jdk8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/apps/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
-------------------------------------------------------------------
[root@nodea hadoop]# source /etc/profile #立即生效
上面1、2、3、4操作只在nodea上面操作
3.4 hadoop配置文件
下面所有配置文件都在/opt/apps/hadoop-2.8.0/etc/hadoop目录下
- 修改 hadoop-env.sh文件
-------------------------------------------------------------------
export JAVA_HOME=${JAVA_HOME}修改为:
export JAVA_HOME=/opt/jdk8
-------------------------------------------------------------------
- 修改yarn-env.sh文件
-------------------------------------------------------------------
修改JAVA_HOME为:
export JAVA_HOME=/opt/jdk8
-------------------------------------------------------------------
- core-site.xml配置
-------------------------------------------------------------------
fs.default.name
hdfs://nodea:9000
hadoop.tmp.dir
/root/hadoop/tmp
Abase for other temporary directories.
io.file.buffer.size
4096
-------------------------------------------------------------------
- hdfs-site.xml配置
dfs.name.dir
/root/hadoop/dfs/name
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
dfs.data.dir
/root/hadoop/dfs/data
Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
dfs.replication
2
dfs.permissions
false
need not permissions
dfs.block.size
134217728
dfs.http.address
nodea:50070
dfs.secondary.http.address
nodea:50090
dfs.webhdfs.enabled
true
-------------------------------------------------------------------
- mapred-site.xml配置
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
-------------------------------------------------------------------
mapred.job.tracker
nodea:49001
mapred.local.dir
/root/hadoop/var
mapreduce.framework.name
yarn
mapreduce.jobhistory.webapp.address
nodea:19888
-------------------------------------------------------------------
- yarn-site.xml配置
-------------------------------------------------------------------
yarn.resourcemanager.hostname
nodea
The address of the applications manager interface in the RM.
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
The address of the scheduler interface.
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
The https adddress of the RM web application.
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
2048
默认是 8182MB
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.vmem-check-enabled
false
-------------------------------------------------------------------
- slave配置
-------------------------------------------------------------------
nodeb
nodec
-------------------------------------------------------------------
6. 配置文件拷贝到从机
[root@nodea hadoop]# scp -r /opt/apps root@nodeb:/opt/apps/hadoop2.8.0
[root@nodea hadoop]# scp -r /opt/apps root@nodec:/opt/apps/hadoop2.8.0
7. 配置nodeb、nodec环境变量
[root@nodea hadoop]# vi /etc/profile 配置环境变量
-------------------------------------------------------------------
export JAVA_HOME=/opt/jdk/jdk1.7.0_67
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/apps/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
-------------------------------------------------------------------
[root@nodea tmp]# source /etc/profile
[root@nodea tmp]# hadoop version
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /opt/hadoop/apps/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar
四、运行hadoop
4.1 格式化namenode
在nodea上面执行 hadoop namenode -format,对hdfs进行格式化
[root@nodea hadoop]# cd /opt/apps/hadoop-2.8.0/bin
[root@nodea hadoop]# ./hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
18/06/11 19:41:36 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = nodeb/127.0.0.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.1
STARTUP_MSG: classpath = /opt/hadoop/apps/hadoop-2.7.1/etc/hadoop:/opt/hadoop/apps/hadoop-2.7.1/share/hadoop/common/lib/commons-configuration-1.6.jar..........................
compiled by 'jenkins' on 2015-06-29T06:04Z
STARTUP_MSG: java = 1.7.0_67
************************************************************/
18/06/11 19:41:36 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
18/06/11 19:41:36 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-93f976dc-7a83-43c6-bb55-38c6f900b76e
18/06/11 19:41:38 INFO namenode.FSNamesystem: No KeyProvider found.
18/06/11 19:41:38 INFO namenode.FSNamesystem: fsLock is fair:true
18/06/11 19:41:38 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
18/06/11 19:41:38 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
18/06/11 19:41:38 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
18/06/11 19:41:38 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Jun 11 19:41:38
18/06/11 19:41:38 INFO util.GSet: Computing capacity for map BlocksMap
18/06/11 19:41:38 INFO util.GSet: VM type = 64-bit
18/06/11 19:41:38 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
18/06/11 19:41:38 INFO util.GSet: capacity = 2^21 = 2097152 entries
18/06/11 19:41:38 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
18/06/11 19:41:38 INFO blockmanagement.BlockManager: defaultReplication = 2
18/06/11 19:41:38 INFO blockmanagement.BlockManager: maxReplication = 512
18/06/11 19:41:38 INFO blockmanagement.BlockManager: minReplication = 1
18/06/11 19:41:38 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
18/06/11 19:41:38 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false
18/06/11 19:41:38 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
18/06/11 19:41:38 INFO blockmanagement.BlockManager: encryptDataTransfer = false
18/06/11 19:41:38 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
18/06/11 19:41:38 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
18/06/11 19:41:38 INFO namenode.FSNamesystem: supergroup = supergroup
18/06/11 19:41:38 INFO namenode.FSNamesystem: isPermissionEnabled = false
18/06/11 19:41:38 INFO namenode.FSNamesystem: HA Enabled: false
18/06/11 19:41:38 INFO namenode.FSNamesystem: Append Enabled: true
18/06/11 19:41:38 INFO util.GSet: Computing capacity for map INodeMap
18/06/11 19:41:38 INFO util.GSet: VM type = 64-bit
18/06/11 19:41:38 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
18/06/11 19:41:38 INFO util.GSet: capacity = 2^20 = 1048576 entries
18/06/11 19:41:38 INFO namenode.FSDirectory: ACLs enabled? false
18/06/11 19:41:38 INFO namenode.FSDirectory: XAttrs enabled? true
18/06/11 19:41:38 INFO namenode.FSDirectory: Maximum size of an xattr: 16384
18/06/11 19:41:38 INFO namenode.NameNode: Caching file names occuring more than 10 times
18/06/11 19:41:38 INFO util.GSet: Computing capacity for map cachedBlocks
18/06/11 19:41:38 INFO util.GSet: VM type = 64-bit
18/06/11 19:41:38 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
18/06/11 19:41:38 INFO util.GSet: capacity = 2^18 = 262144 entries
18/06/11 19:41:38 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
18/06/11 19:41:38 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
18/06/11 19:41:38 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
18/06/11 19:41:38 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
18/06/11 19:41:38 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
18/06/11 19:41:38 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
18/06/11 19:41:38 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
18/06/11 19:41:38 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
18/06/11 19:41:38 INFO util.GSet: Computing capacity for map NameNodeRetryCache
18/06/11 19:41:38 INFO util.GSet: VM type = 64-bit
18/06/11 19:41:38 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
18/06/11 19:41:38 INFO util.GSet: capacity = 2^15 = 32768 entries
18/06/11 19:41:38 INFO namenode.FSImage: Allocated new BlockPoolId: BP-2047832718-127.0.0.1-1528771298722
18/06/11 19:41:38 INFO common.Storage: Storage directory /opt/hadoop/apps/hadoopdata/hdfs/name has been successfully formatted.
18/06/11 19:41:39 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/06/11 19:41:39 INFO util.ExitUtil: Exiting with status 0
18/06/11 19:41:39 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at nodea/127.0.0.1
************************************************************/
4.2 启动服务
有两种启动方式
4.2.1 启动所有服务
[root@nodea tmp]# cd /opt/hadoop/apps/hadoop-2.7.1/sbin/
[root@nodea tmp]# ./start-all.sh #启动所有服务
- nodea上执行:
[root@nodea sbin]# jps 主
11952 ResourceManager
11532 NameNode
11775 SecondaryNameNode
13233 Jps
- nodeb、nodec上执行
[root@nodeb sbin]# jps
10626 DataNode
10928 Jps
10795 NodeManager
4.2.2 分别启动服务
- nodea、nodeb、nodec上分别执行,启动namenode、datanode
nodea:/opt/hadoop/apps/hadoop-2.7.1/sbin/hadoop-daemon.sh start namenode
nodeb:/opt/hadoop/apps/hadoop-2.7.1/sbin/hadoop-daemons.sh start datanode
nodec:/opt/hadoop/apps/hadoop-2.7.1/sbin/hadoop-daemons.sh start datanode
- 运行yarn
nodea:/opt/hadoop/apps/hadoop-2.7.1/sbin/start-yarn.sh
- 运行hdfs:
nodea:/opt/hadoop/apps/hadoop-2.7.1/sbin/start-dfs.sh
五、测试hadoop
5.1 测试hdfs
hdfs访问网址:http://nodea:50070
put命令上传文件
#hdfs上创建文件夹
hadoop fs -mkdir -p /movie
#先创建上这个文件夹,下面集成hbase需要用到
hadoop fs -mkdir -p /movie
#上传文件
hadoop fs -put /opt/tt.txt /movie
#查看movie下文件
hadoop fs -ls /movie
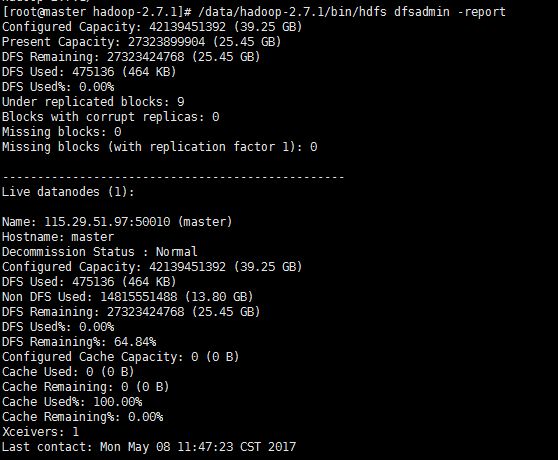
5.2 查看集群状态
[root@nodea hadoop]# /opt/hadoop/apps/hadoop-2.7.1/bin/hdfs dfsadmin -report
5.3 测试YARN
可以访问YARN的管理界面,验证YARN,访问地址:http://nodea:8088,如图:
5.4 测试mapreduce
不想编写mapreduce代码。幸好Hadoop安装包里提供了现成的例子,在Hadoop的share/hadoop/mapreduce目录下。运行例子:
[root@nodea hadoop]# /opt/apps/hadoop-2.8.0/bin/hadoop jar /opt/hadoop/apps/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 5 10
结果如图:  转存失败重新上传取消
转存失败重新上传取消
5.5 测试查看HDFS
访问地址:http://nodea:50070
六、配置运行Hadoop中遇见的问题
6.1 JAVA_HOME未设置
启动的时候报:
localhost:Error:JAVA_HOME is not set or could not be found
则需要/opt/hadoop/apps/hadoop-2.7.1/etc/hadoop/hadoop-env.sh,添加JAVA_HOME路径
6.2 ncompatible clusterIDs
由于配置Hadoop集群不是一蹴而就的,所以往往伴随着配置——>运行——>。。。——>配置——>运行的过程,所以DataNode启动不了时,往往会在查看日志后,发现以下问题: 此问题是由于每次启动Hadoop集群时,会有不同的集群ID,所以需要清理启动失败节点上data目录(比如我创建的/home/jiaan.gja/hdfs/data)中的数据。
6.2 启动hadoop后datanode、namenode能正常启动但是datanode无法连接namenode
查看datanode log日志发现报错信息如下:
2018-06-11 10:43:33,970 WARNorg.apache.hadoop.hdfs.server.datanode.DataNode: Problem connecting to server:nodea/192.168.47.130:8020
2018-06-11 10:43:55,009 INFOorg.apache.hadoop.ipc.Client: Retrying connect to server:nodea/192.168.47.130:8020. Already tried 0 time(s); retry policy isRetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
2018-06-11 10:43:56,012 INFOorg.apache.hadoop.ipc.Client: Retrying connect to server:nodea/192.168.47.130:8020. Already tried 1 time(s); retry policy isRetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
其中datanode与namenode的Ip都可以ping通。
其实根本原因还是无法连接到202.106.199.36:9000 相应ip的相应端口。
解决方法:
- 修改主机名文件
vi /etc/hosts 将#后面的内容删除掉
-------------------------------------------------------------------
#127.0.0.1 localhost localhost.localdomain localhost4
#127.0.0.1 localhost
#127.0.0.1 nodea
192.168.47.130 nodea
192.168.47.129 nodeb
192.168.47.131 nodec
-------------------------------------------------------------------
- 关闭防火墙
- 如果linux系统是centos7.0以下的版本执行如下命令
#临时关闭防火墙(重启后失效)
service iptables stop
#关闭开机自启防火墙(重启后生效)
chkconfig iptables off
- 如果linux系统是centos7.0及以上版本,执行如下命令
#临时关闭
systemctl stop firewalld
#禁止开机启动
systemctl disable firewalld
6.4 hdfs使用put上传文件报错 报错信息如下:
[root@nodea init.d]# hadoop fs -put /opt/movie/test.txt /movie
18/06/19 01:21:41 INFO hdfs.DFSClient: Exception in createBlockOutputStream
java.net.NoRouteToHostException: No route to host
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSOutputStream.createSocketForPipeline(DFSOutputStream.java:1508)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1284)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1237)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:449)
18/06/19 01:21:41 INFO hdfs.DFSClient: Abandoning BP-1117584636-127.0.0.1-1529392562608:blk_1073741825_1001
18/06/19 01:21:41 INFO hdfs.DFSClient: Excluding datanode DatanodeInfoWithStorage[192.168.47.130:50010,DS-8dacdd17-e096-4dd0-a5b7-9b7ed189cb4a,DISK]
18/06/19 01:21:41 INFO hdfs.DFSClient: Exception in createBlockOutputStream
java.net.NoRouteToHostException: No route to host
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.hdfs.DFSOutputStream.createSocketForPipeline(DFSOutputStream.java:1508)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.createBlockOutputStream(DFSOutputStream.java:1284)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1237)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:449)
18/06/19 01:21:41 INFO hdfs.DFSClient: Abandoning BP-1117584636-127.0.0.1-1529392562608:blk_1073741826_1002
18/06/19 01:21:41 INFO hdfs.DFSClient: Excluding datanode DatanodeInfoWithStorage[192.168.47.131:50010,DS-570f444b-a0ef-45d7-bc4c-66e6f7c84871,DISK]
18/06/19 01:21:41 WARN hdfs.DFSClient: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /movie/test.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1550)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:3110)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3034)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:723)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:492)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:969)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043)
at org.apache.hadoop.ipc.Client.call(Client.java:1476)
at org.apache.hadoop.ipc.Client.call(Client.java:1407)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy14.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock(ClientNamenodeProtocolTranslatorPB.java:418)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy15.addBlock(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.locateFollowingBlock(DFSOutputStream.java:1430)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.nextBlockOutputStream(DFSOutputStream.java:1226)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:449)
put: File /movie/test.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s) are excluded in this operation.
这个是由于防火墙没有关闭,关闭防火墙就可以了
关闭防火墙
- 如果linux系统是centos7.0以下的版本执行如下命令
#临时关闭防火墙(重启后失效)
service iptables stop
#关闭开机自启防火墙(重启后生效)
chkconfig iptables off
- 如果linux系统是centos7.0及以上版本,执行如下命令
#临时关闭
systemctl stop firewalld
#禁止开机启动
systemctl disable firewalld
七 注意事项
详细过程参见官方文档,这里只介绍常见的一些问题:
-
首先是版本的选择,一般选择cloudera 的cdh版,注意相互之间的兼容性,否则出现莫名其妙的问题都不知道怎么解决。
-
配置ssh五密码访问时要注意,.ssh目录的权限问题,跟各个开发包一样,各节点必须一致,否则会出现启动Hadoop时让手动输密码。
-
在配置conf下文件时要注意,某些属性的值必须是hadoop程序有写权限的目录,比如:hadoop.tmp.dir
-
Hadoop-env.sh中要配置JAVA_HOME,不管profile或.bash_profile有没配置
-
hive的配置只要关联正确hadoop的namenode即可,元数据库可用默认的derby,也可通过修改配置实用mysql
-
hbase的master最好不用作regionserver。
-
zk的连接数要改的大一点,默认是30个,并且尽量与hadoop node节点分开,因为hadoop的暂时负担过重等异常会严重影响zk与hbase的正常工作,比如导致zk长时间选举不出leader,hbase 各节点会相继挂掉。
-
安装oozie依赖ext包,因为console会用到这个框架,console的时间默认显示GMT格式,看着很别扭,但不知道怎么改成 GMT +8 北京时间,who can tell me?
-
sqoop解压后,要配置SQOOP_HOME,hdfs需要跟那种类型的RDB交互就下相应的JDBC驱动,放入lib下。
-
hadoop,hbase,需要在各自的集群中每个节点都安装,zookeeper根据需要安装,一般奇数个,数量越多,选举负担中,但数量越少,系统稳定性下降,使用时跟据实际情况选择方案,hive,oozie,sqoop只需要在需要执行客户端程序的机器上安装,只要能连上hadoop。
zookeeper集群安装配置
单机版安装配置并设置开机启动请参考:http://blog.csdn.net/pucao_cug/article/details/71240246
一 zookeeper集群进行配置
1.1 资源上传
上传zookeeper安装包资源到/opt/resources
1.2 创建目录
/opt/apps/zookeeper /opt/apps/data /opt/apps/dataLog
在/opt/apps/data中创建myid文件 vi /opt/apps/data/myid
nodea myid内容上:1
nodeb myid内容上:2
nodec myid内容上:3这里myid内容要和下面配置的zoo.cfg一致,下面会详细说明
:wq保存
1.3 解压
tar -zxvf zookeeper-3.4.10.tar.gz
mv zookeeper-3.4.10 /opt/apps/zookeeper/zookeeper-3.4.10
1.4 配置zoo.cfg
cd /opt/apps/zookeeper/zookeepre-3.4.10/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
-------------------------------------------------------------------
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
dataDir=/opt/apps/zookeeper/data
dataLogDir=/opt/apps/zookeeper/dataLog
server.1=nodea:2888:3888
server.2=nodeb:2888:3888
server.3=nodec:2888:3888
-------------------------------------------------------------------
说明:dataDir和dataLogDir需要自己创建,目录可以自己制定,对应即可。server.1中的这个1需要和nodea这个机器上的dataDir目录中的myid文件中的数值对应。server.2中的这个2需要和nodeb这个机器上的dataDir目录中的myid文件中的数值对应。server.3中的这个3需要和nodec这个机器上的dataDir目录中的myid文件中的数值对应。当然,数值你可以随便用,只要对应即可。2888和3888的端口号也可以随便用,因为在不同机器上,用成一样也无所谓。
1.5 配置环境变量
vi /etc/profile
-------------------------------------------------------------------
export JAVA_HOME=/opt/jdk8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/apps/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export ZOOKEEPER_HOME=/opt/apps/zookeeper/zookeeper-3.4.10
export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
-------------------------------------------------------------------
二 启动、测试集群
2.1 启动集群
三台机器分别执行
zkService.sh start
-------------------------------------------------------------------
Zookeeper JMX enabled by default
using config:/opt/apps/zookeeper/zookeeper-3.4.10/bin../conf/zoo.cfg
Starting zooleeper ... STARTED
-------------------------------------------------------------------
2.2 测试
zkService.sh status
-------------------------------------------------------------------
ZooKeeper JMX enabled by default
Using config:/opt/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
-------------------------------------------------------------------
hbase集群安装配置
一 资源上传、解压缩
1.1 创建目录
/root/hbase/tmp
/root/hbase/pids
/opt/apps/hbase
nodea、nodeb、nodec上面都需要创建目录
1.2 资源上传、解压
上传到/opt/resource目录下
tar -zxvf hbase-1.2.6.1.tar.gz
mv hbase-1.2.6.1 /opt/apps/hbase/hbase-1.2.6.1
二 hbase安装配置
2.1 配置环境变量
vi /etc/profile
-------------------------------------------------------------------
# /etc/profile
# System wide environment and startup programs, for login setup
# Functions and aliases go in /etc/bashrc
# It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates.
pathmunge () {
case ":${PATH}:" in
*:"$1":*)
;;
*)
if [ "$2" = "after" ] ; then
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
esac
}
if [ -x /usr/bin/id ]; then
if [ -z "$EUID" ]; then
# ksh workaround
EUID=`id -u`
UID=`id -ru`
fi
USER="`id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
fi
# Path manipulation
if [ "$EUID" = "0" ]; then
pathmunge /usr/sbin
pathmunge /usr/local/sbin
else
pathmunge /usr/local/sbin after
pathmunge /usr/sbin after
fi
HOSTNAME=`/usr/bin/hostname 2>/dev/null`
HISTSIZE=1000
if [ "$HISTCONTROL" = "ignorespace" ] ; then
export HISTCONTROL=ignoreboth
else
export HISTCONTROL=ignoredups
fi
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
# By default, we want umask to get set. This sets it for login shell
# Current threshold for system reserved uid/gids is 200
# You could check uidgid reservation validity in
# /usr/share/doc/setup-*/uidgid file
if [ $UID -gt 199 ] && [ "`id -gn`" = "`id -un`" ]; then
umask 002
else
umask 022
fi
for i in /etc/profile.d/*.sh ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done
unset i
unset -f pathmunge
export JAVA_HOME=/opt/jdk8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/apps/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export ZOOKEEPER_HOME=/opt/apps/zookeeper/zookeeper-3.4.10
export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
export HBASE_HOME=/opt/apps/hbase/hbase-1.2.6.1
export PATH=$HBASE_HOME/bin:$PATH
-------------------------------------------------------------------
source /etc/profile
2.2 hbase配置文件
对/opt/hbase/hbase-1.2.6.1/conf目录下的一系列文件做配置。使用命令进入到该目录:
cd /opt/apps/hbase/hbase-1.2.6.1/conf
2.2.1 修改hbase-env.sh文件
vi /opt/apps/hbase/hbase-1.2.6.1/conf/hbase-env.sh
-------------------------------------------------------------------
export JAVA_HOME=/opt/jdk8
export HADOOP_HOME=/opt/apps/hadoop-2.8.0
export HBASE_HOME=/opt/apps/hbase/hbase-1.2.6.1
export HBASE_CLASSPATH=/opt/apps/hbase/hbase-1.2.6.1/etc/hadoop
export HBASE_PID_DIR=/root/hbase/pids
# true代表使用hbase自带zookeeper,false代表使用自己安装的zookeeper
export HBASE_MANAGES_ZK=false
-------------------------------------------------------------------
2.2.2 修改配置文件hbase-site.xml
vi /opt/apps/hbase/hbase-1.2.6.1/conf/hbase-env.sh
-------------------------------------------------------------------
<!--这里要和hadoop配置文件core-site.xml中配置的fs.default.name前面相同 后面多一个hbase文件夹 -->
hbase.rootdir
hdfs://nodea:9000/hbase
The directory shared byregion servers.
<!-- 注意:这里端口号要和zookeeper配置文件zoo.cfg中配置的相同 -->
hbase.zookeeper.property.clientPort
2181
Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
zookeeper.session.timeout
120000
hbase.zookeeper.quorum
nodea,nodeb,nodec
hbase.tmp.dir
/root/hbase/tmp
hbase.cluster.distributed
true
-------------------------------------------------------------------
2.2.3 修改regionservers文件
将该文件内容修改为:
-------------------------------------------------------------------
nodea
nodeb
nodec
-------------------------------------------------------------------
2.3 nodeb、nodec安装hbase
scp -r /opt/apps/hbase/hbase-1.2.6.1 root@nodeb:/opt/apps/hbase/hbase-1.2.6.1
scp -r /opt/apps/hbase/hbase-1.2.6.1 root@nodec:/opt/apps/hbase/hbase-1.2.6.1
3 启动和测试
3.1 启动
Hbase是基于hadoop提供的分布式文件系统的,所以启动Hbase之前,先确保hadoop在正常运行,另外Hbase还依赖于zookkeeper,本来我们可以用hbase自带的zookeeper,但是我们上面的配置启用的是我们自己的zookeeper集群,所以在启动hbase前,还要确保zokeeper已经正常运行。
Hbase可以只在hadoop的某个namenode节点上安装,也可以在所有的hadoop节点上安装,但是启动的时候只需要在一个节点上启动就行了,本例中,我在nodea、nodeb、nodec都安装了Hbase,启动的时候只需要在nodea上启动就OK。
cd /opt/apps/hbase/hbase-1.2.6.1/bin
./start-hbase.sh
#当然如果我们已经配置过环境变量(profile文件),就可以在任意目录下执行:start-hbase.sh来启动hbase
-------------------------------------------------------------------
starting master,logging to /opt/hbase/hbase-1.2.5/logs/hbase-root-master-hserver1.out
Java HotSpot(TM)64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in8.0
Java HotSpot(TM)64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removedin 8.0
hserver3:starting regionserver, logging to /opt/hbase/hbase-1.2.5/logs/hbase-root-regionserver-hserver3.out
hserver2:starting regionserver, logging to/opt/hbase/hbase-1.2.5/logs/hbase-root-regionserver-hserver2.out
hserver2: JavaHotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; supportwas removed in 8.0
hserver2: JavaHotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; supportwas removed in 8.0
hserver3: JavaHotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; supportwas removed in 8.0
hserver3: Java HotSpot(TM)64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removedin 8.0
hserver1:starting regionserver, logging to/opt/hbase/hbase-1.2.5/logs/hbase-root-regionserver-hserver1.out
-------------------------------------------------------------------
3.2 测试
3.2.1 用浏览器访问Hbase状态信息
直接访问地址:http://nodea:16030/
3.2.2 启动hbase的命令行
cd /opt/apps/hbase/hbase-1.2.6.1/bin
执行命令启动Hbase命令行窗口,命令是:
./hbase shell
-------------------------------------------------------------------
2017-05-15 17:52:55,411 WARN [main] util.NativeCodeLoader: Unable to loadnative-hadoop library for your platform... using builtin-java classes whereapplicable
SLF4J: Class path contains multiple SLF4Jbindings.
SLF4J: Found binding in[jar:file:/opt/hbase/hbase-1.2.5/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in[jar:file:/opt/hadoop/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Seehttp://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help' forlist of supported commands.
Type "exit" toleave the HBase Shell
Version 1.2.5,rd7b05f79dee10e0ada614765bb354b93d615a157, Wed Mar 1 00:34:48 CST 2017
#这里执行list不报错说明安装完成
hbase(main):001:0> list
-------------------------------------------------------------------
这里是因为hbase跟hadoopjar包版本不一致,随便删除一个就可以了
我这里删除了hbasejar包
rm -rf /opt/hbase/hbase-1.2.5/lib/slf4j-log4j12-1.7.5.jar
hive安装配置
一 环境准备
1.1 下载hive
下载地址:http://hive.apache.org/downloads.html
点击上图的Download release now!
1.2 创建文件夹
mkdir -p /opt/apps/hive
1.3 上传、解压
上传到/opt/resource目录中
tar -zxvf apache-hive-2.3.3-bin.tar.gz
mv apache-hive-2.3.3-bin /opt/apps/hive/apache-hive-2.3.3-bin
1.4 配置环境变量
vi /etc/profile
-------------------------------------------------------------------
新增
export HIVE_HOME=/opt/apps/hive/apache-hive-2.3.3-bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=$HIVE_HOME/lib:$CLASSPATH
export PATH=$HIVE_HOME/bin:$PATH
-------------------------------------------------------------------
source /etc/profile
cat /etc/profile
-------------------------------------------------------------------
export JAVA_HOME=/opt/jdk8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/apps/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export ZOOKEEPER_HOME=/opt/apps/zookeeper/zookeeper-3.4.10
export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
export HBASE_HOME=/opt/apps/hbase/hbase-1.2.6.1
export PATH=$HBASE_HOME/bin:$PATH
export HIVE_HOME=/opt/apps/hive/apache-hive-2.3.3-bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=$HIVE_HOME/lib:$CLASSPATH
export PATH=$HIVE_HOME/bin:$PATH
-------------------------------------------------------------------
二 配置hive
2.1 使用hadoop新建hdfs目录
因为在hive-site.xml中有这样的配置:
-------------------------------------------------------------------
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.exec.scratchdir
/tmp/hive
-------------------------------------------------------------------
所以要让hadoop新建/user/hive/warehouse目录,执行命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse
给刚才新建的目录赋予读写权限,执行命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /user/hive/warehouse
让hadoop新建/tmp/hive/目录,执行命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /tmp/hive/
给刚才新建的目录赋予读写权限,执行命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /tmp/hive
检查hdfs目录是否创建成功
$HADOOP_HOME/bin/hadoop fs -ls /user/hive/
$HADOOP_HOME/bin/hadoop fs -ls /tmp/
2.2 hive-site.xml相关的配置
cd /opt/apps/hive/apache-hive-2.1.1-bin/conf
将hive-default.xml.template文件复制一份,并且改名为hive-site.xml,命令是:
cp hive-default.xml.template hive-site.xml
将hive-site.xml文件中的${system:java.io.tmpdir}替换为hive的临时目录,例如我替换为/opt/hive/tmp,该目录如果不存在则要自己手工创建,并且赋予读写权限。文本查找可以使用: /查找内容,按n查找下一个 例如:/system:java.io.tmpdir
如图:
被我替换为了如图:
将${system:user.name}都替换为root,如图:
被替换为:
说明:截图并不完整,只是截取了几处以作举例,你在替换时候要认真仔细的全部替换掉。
修改hive-site.xml数据库相关的配置
搜索javax.jdo.option.ConnectionURL,将该name对应的value修改为MySQL的地址,找一台安装有mysql的机器,填写mysql相关信息例如我修改后是:
-------------------------------------------------------------------
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.1.8:3306/hive?createDatabaseIfNotExist=true
-------------------------------------------------------------------
搜索javax.jdo.option.ConnectionDriverName,将该name对应的value修改为MySQL驱动类路径,例如我的修改后是:
-------------------------------------------------------------------
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
-------------------------------------------------------------------
搜索javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名:
-------------------------------------------------------------------
javax.jdo.option.ConnectionUserName
root
-------------------------------------------------------------------
搜索javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
-------------------------------------------------------------------
javax.jdo.option.ConnectionPassword
123456
--------------------------------------------------------------------
搜索hive.metastore.schema.verification,将对应的value修改为false:
-------------------------------------------------------------------
hive.metastore.schema.verification
false
-------------------------------------------------------------------
2.3 将MySQL驱动包上载到lib目录
将MySQL驱动包上载到Hive的lib目录下,例如我是上载到/opt/apps/hive/apache-hive-2.1.1-bin/lib目录下。
2.4 新建hive-env.sh文件并进行修改
cd /opt/apps/hive/apache-hive-2.1.1-bin/conf
cp hive-env.sh.template hive-env.sh
vi hive-env.sh
-------------------------------------------------------------------
添加
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HIVE_CONF_DIR=/opt/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/opt/hive/apache-hive-2.1.1-bin/lib
-------------------------------------------------------------------
三 启动
3.1 MySQL数据库进行初始化
cd /opt/apps/hive/apache-hive-2.1.1-bin/bin
对数据库进行初始化,执行命令:
[root@nodea bin]# schematool -initSchema -dbType mysql
-------------------------------------------------------------------
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apps/hive/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/apps/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://192.168.1.51:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
-------------------------------------------------------------------
执行成功后,hive数据库里已经有一堆表创建好了
3.2 启动hive
[root@nodea bin]# cd /opt/apps/hive/apache-hive-2.3.3-bin/bin
[root@nodea bin]# ./hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apps/hive/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/apps/hadoop-2.8.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/apps/hive/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show functions
> ;
OK
!
!=
$sum0
%
&
*
+
-
/
<
<=
<=>
<>
=
==
>
>=
^
abs
acos
add_months
hive> desc function sum;
OK
sum(x) - Returns the sum of a set of numbers
Time taken: 0.463 seconds, Fetched: 1 row(s)
hive> create database db_hive_edu;
OK
Time taken: 0.417 seconds
hive> use db_hive_edu;
OK
Time taken: 0.125 seconds
四 测试
4.1 执行简单测试命令
#执行查看sum函数的详细信息的命令:
hive> desc function sum;
OK
sum(x) - Returns the sum of a set of numbers
Time taken: 0.463 seconds, Fetched: 1 row(s)
##新建数据库
hive> create database db_hive_edu;
OK
Time taken: 0.417 seconds
hive> use db_hive_edu;
OK
Time taken: 0.125 seconds
#新建数据表
hive> create table student(id int,name string) row format delimited fields terminated by '\t';
OK
Time taken: 1.485 seconds
4.2 将文件数据写入表中
执行Linux命令(最好是重新打开一个终端来执行):
touch /opt/apps/hive/student.txt
vi /opt/apps/hive/student.txt
-------------------------------------------------------------------
往文件中添加以下内容:列之间用tab间隔
001 zhangsan
002 lisi
003 wangwu
004 zhaoliu
005 chenqi
-------------------------------------------------------------------
说明:ID和name直接是TAB键,不是空格,因为在上面创建表的语句中用了terminated by '\t'所以这个文本里id和name的分割必须是用TAB键(复制粘贴如果有问题,手动敲TAB键吧),还有就是行与行之间不能有空行,否则下面执行load,会把NULL存入表内,该文件要使用unix格式,如果是在windows上用txt文本编辑器编辑后在上载到服务器上,需要用工具将windows格式转为unix格式,例如可以使用Notepad++来转换
hive> load data local inpath '/opt/apps/hive/student.txt' into table db_hive_edu.student;
Loading data to table db_hive_edu.student
OK
Time taken: 2.45 seconds
hive> select * from student;
OK
1 liyan
2 hld
3 ylq
4 ps
5 ss
6 hello
Time taken: 2.01 seconds, Fetched: 6 row(s)
4.3 在界面上查看刚才写入hdfs的数据
http://nodea:50070/explorer.html#/user/hive/warehouse
4.4 在MySQL的hive数据库中查看
在MySQL数据库中执行select语句,查看hive创建的表,SQL是:
SELECT * FROM hive.TBLS
如图:
五 错误和解决
5.1 警告Unable to load native-hadoop library for yourplatform
实际上其实这个警告可以不予理会。
5.2 There are 2 datanode(s) running and 2 node(s) areexcluded in this operation.
报错信息
-------------------------------------------------------------------
hive> load data local inpath '/opt/hive/student.txt' intotable db_hive_edu.student;
Loading data to table db_hive_edu.student
Failed with exceptionorg.apache.hadoop.ipc.RemoteException(java.io.IOException): File/user/hive/warehouse/db_hive_edu.db/student/student_copy_2.txt could only bereplicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s)are excluded in this operation.
atorg.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1559)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
atorg.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:975)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
atjava.security.AccessController.doPrivileged(Native Method)
atjavax.security.auth.Subject.doAs(Subject.java:422)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
FAILED: Execution Error, return code 1 fromorg.apache.hadoop.hive.ql.exec.MoveTask.org.apache.hadoop.ipc.RemoteException(java.io.IOException): File/user/hive/warehouse/db_hive_edu.db/student/student_copy_2.txt could only bereplicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s)are excluded in this operation.
atorg.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1559)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:975)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
atjava.security.AccessController.doPrivileged(Native Method)
atjavax.security.auth.Subject.doAs(Subject.java:422)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
atorg.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
-------------------------------------------------------------------
原因和解决:
原因是你的hadoop中的datanode有问题,没发写入数据,请检查你的hadoop是否正常运行,看是否能正常访问http://nodename的IP地址:50070
如果不正常,请回头检查自己hadoop的安装配置是否正确,hive的安装和配置是否正确。