ABAP READ TABLE
READ TABLE 选项:
READ TABLE
. READ TABLE
WITH KEY = … = . READ TABLE
WITH TABLE KEY = … =
. READ TABLE
WITH KEY = . READ TABLE
WITH KEY . . . BINARY SEARCH. READ TABLE
INDEX . READ TABLE
COMPARING . . . . READ TABLE
COMPARING ALL FIELDS. READ TABLE
TRANSPORTING . . . . READ TABLE
TRANSPORTING NO FIELDS.
关键字说明:
KEY|TABLE KEY: 通过内表的主键字段查找
BINARY SEARCH: 二分法查找,使用该方法时,在READ TABLE之前,必须对内表排序
INDEX: 根据内表索引查找
COMPARING:只查找设置的字段
COMPARING ALL FIELDS:查找内表所有的字段
TRANSPORTING: 只输出设置的字段数据
TRANSPORTING NO FIELDS: 不输出任何数据
1、先了解一下KEY
ABAP的內表和我们真正的DB 表是类似的,有结构有栏位,但是在处理Key上DB表显得更为随意,可以要也可以不要,
而內表如果没有显式声明,会将內表中的所有非数值栏位的栏位都作为KEY,当然也可以显式声明KEY。
With- 这种结构用的地方主要就是在內表的处理上,包括DELETE,READ.
READ 可以用WITH KEY 或者WITH TABLE KEY,但是DELETE只能用WITH TABLE KEY。
2、READ TABLE WITH KEY
使用其他关键字段进行读取。
READ TABLE WITH KEY 传入的是free search key, 支持仅仅传入主键集合的某一个primary key或者secondary key。
READ TABLE WITH KEY 传入的不一定是内表中真正的关键字段,只要是内表行组件即可。
WITH KEY中的检索条件比较符不能使用‘<>’(不等于)。
*变量声明
DATA: BEGIN OF LINE,
COL1 TYPE C,
COL2 TYPE N,
COL3 TYPE I,
END OF LINE.
DATA: LINE2 LIKE LINE.
DATA: ITAB LIKE STANDARD TABLE OF LINE WITH HEADER LINE WITH KEY COL1 COL2 .
*内表赋值
LINE-COL1 = '1'.
LINE-COL2 = '1'.
LINE-COL3 = 10.
APPEND LINE TO ITAB.
LINE-COL1 = '2'.
LINE-COL2 = '2'.
LINE-COL3 = 20.
APPEND LINE TO ITAB.
*结构体内容清空
CLEAR: LINE.
*结构体内容赋值
LINE-COL1 = '1'.
LINE-COL2 = '1'.
"注:这里不能省略下面语句,否则查找不到
LINE-COL3 = 10.
*READ TABLE操作
READ TABLE ITAB INTO LINE2 WITH KEY = LINE.
"READ TABLE ITAB INTO LINE2 WITH KEY COL1 = 1 . "结果一样
"READ TABLE ITAB INTO LINE2 WITH KEY COL2 = 1. "结果一样
"READ TABLE ITAB INTO LINE2 WITH KEY COL3 = 10. "结果一样
WRITE: / SY-SUBRC, LINE2-COL1.
3、READ TABLE WITH TABLE KEY
使用表关键字段进行读取。
READ TABLE WITH TABLE KEY后指定的是table primary key。 如果一个table定义了多个primary key,则必须将所有的key全部在语句中指定,否则会遇到syntax error “key must be completely provided”。
DATA: BEGIN OF LINE,
COL1 TYPE C,
COL2 TYPE N,
COL3 TYPE I,
END OF LINE.
DATA: LINE2 LIKE LINE.
DATA: ITAB LIKE STANDARD TABLE OF LINE WITH HEADER LINE WITH KEY COL1 COL2 .
LINE-COL1 = '1'.
LINE-COL2 = '1'.
LINE-COL3 = 10.
APPEND LINE TO ITAB.
LINE-COL1 = '2'.
LINE-COL2 = '2'.
LINE-COL3 = 20.
APPEND LINE TO ITAB.
CLEAR: LINE.
LINE-COL1 = '1'.
LINE-COL2 = '1'.
"注:这里不能省略下面语句,否则查找不到
LINE-COL3 = 10.
READ TABLE ITAB INTO LINE2 WITH TABLE KEY COL1 = 1 COL2 = 1. "只能这样写,主键必须写全
WRITE: / SY-SUBRC, LINE2-COL1.
4、TRANSPORTING NO FIELDS
READ TABLE
INTO WITH KEY [TRANSPORTING …|ALL FIELDS|NO FIELDS].
关键字TRANSPORTING NO FIELDS 用于read table with key
一般用于读取内表的时候,只是判断该内表中是否有次数据 不需要读取到工作区中。
READ TABLE LT_DATA INDEX 1 TRANSPORTING NO FIELDS.
此处是判断内表LT_DATA的第一行是否有数据,一般接下来都是用
IF sy-subrc = 0 判断该表中是否有次数据
DATA: BEGIN OF LINE,
COL1 TYPE I,
COL2 TYPE I,
END OF LINE.
DATA ITAB LIKE SORTED TABLE OF LINE WITH UNIQUE KEY COL1.
DO 4 TIMES.
LINE-COL1 = SY-INDEX.
LINE-COL2 = SY-INDEX ** 2.
INSERT LINE INTO TABLE ITAB.
ENDDO.
READ TABLE ITAB WITH KEY COL2 = 16 TRANSPORTING NO FIELDS.
WRITE: 'SY-SUBRC =', SY-SUBRC,
/ 'SY-TABIX =', SY-TABIX.
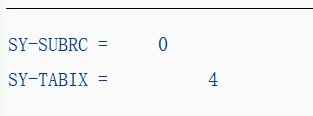
5、TRANSPORTING读取一行的部分字段
系统根据
… NO FIELDS表示不传输任何组件,此种情况下,READ语句只影响系统字段 SY-SUBRC 和 SY-TABIX(前提条件是索引表),并且在TRANSPORTING NO FIELDS情况下,如果指定了
DATA: BEGIN OF LINE,
COL1 TYPE I,
COL2 TYPE I,
END OF LINE.
DATA ITAB LIKE SORTED TABLE OF LINE WITH UNIQUE KEY COL1.
DO 4 TIMES.
LINE-COL1 = SY-INDEX.
LINE-COL2 = SY-INDEX ** 2.
INSERT LINE INTO TABLE ITAB.
ENDDO.
CLEAR LINE.
READ TABLE ITAB WITH TABLE KEY COL1 = 3 INTO LINE TRANSPORTING COL2."主键没有被传输
WRITE: 'SY-SUBRC =', SY-SUBRC,
'SY-TABIX =', SY-TABIX.
WRITE: / LINE-COL1, LINE-COL2.
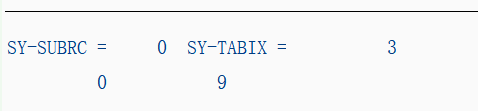
6、COMPARING比较读取的单行内容
READ TABLE
INTO [COMPARING …|ALL FIELDS].
系统根据(关键字段)读取指定的单行并先存储到工作区中,读取行之后,将表与工作区中的相应组件进行比较。
…
… ALL FIELDS表示比较所有组件
如果系统找根据指定
DATA: BEGIN OF LINE,
COL1 TYPE I,
COL2 TYPE I,
END OF LINE.
DATA ITAB LIKE HASHED TABLE OF LINE WITH UNIQUE KEY COL1.
DO 3 TIMES.
LINE-COL1 = SY-INDEX.
LINE-COL2 = SY-INDEX ** 2.
INSERT LINE INTO TABLE ITAB.
ENDDO.
LINE-COL1 = 2.
LINE-COL2 = 3.
READ TABLE ITAB FROM LINE INTO LINE COMPARING COL2.
WRITE: 'SY-SUBRC =', SY-SUBRC.
WRITE: / LINE-COL1, LINE-COL2.

DATA: BEGIN OF LINE,
COL1 TYPE I,
COL2 TYPE I,
COL3 TYPE I,
END OF LINE.
DATA ITAB LIKE LINE OCCURS 10.
DO 10 TIMES.
LINE-COL1 = SY-INDEX.
LINE-COL2 = SY-INDEX ** 2.
LINE-COL3 = SY-INDEX ** 3.
APPEND LINE TO ITAB.
ENDDO.
*CALL METHOD CL_DEMO_OUTPUT=>DISPLAY( ITAB ).
CLEAR: LINE.
LINE-COL1 = 2.
LINE-COL2 = 4.
"只要根据关键字或索引条件在内表中读取到相应数据,不管该数据行是否
"与COMPARING 指定的字段相符,都会覆盖存储到工作区中。
READ TABLE ITAB INTO LINE INDEX 4 COMPARING COL1 COL2.
WRITE: / SY-SUBRC, SY-TABIX,LINE-COL1,LINE-COL2,LINE-COL3.
CLEAR: LINE-COL3.
"也可以使用关键字KEY来读取指定行再进行比较
READ TABLE ITAB INTO LINE WITH KEY COL1 = 4 COL2 = 16 COMPARING COL1 COL2.
WRITE: / SY-SUBRC, SY-TABIX,LINE-COL1,LINE-COL2,LINE-COL3.

7、表的访问方式
目前內表的访问,主要有Index、Binary Search(二元法)、线性、Hash算法等。
访问表可以用WITH KEY 或WITH KEY - BINARY SEARCH或 WITH TABLE KEY。
內表的访问和內表的类型有直接的关系,具体情況如下:
Standard Table:线性访问
标准表:顺序搜索,查找时间会随着条目的增加而线性增加
Sorted Table :BinarySearch
排序表:二分查找,查找时间会随着条目的增加而对数级增加
Hashed Table :Hash算法
哈希表:使用哈希算法进行查询,查找时间不依赖于条目数
我们在使用Standard Table时,如果访问表使用With Key或With Table Key的效率都会比 With key — Binary Search 差,因为前面两个都是采用线性方式,With Table key 很多人会理解成DB的INDEX访问,那么在理解內表的时候就要稍微变通一下。如果使用的是Sorted table, 则默认使用Binary Search,你也可以在语法中加Binary Search 但是加不加都是一样的效果。
如果不用READ TABLE呢?