性能优化的实践派与学院派
一提到应用程序性能优化,大部分人都会想到更换编程语言、缓存、消息队列、分库分表、NoSql(Hbase、ES、Redis...),就像大多数人认为的「缓存就是性能优化中的万金油」。
(以缓存为例)利用缓存做性能优化的案例非常多,从基础的操作系统到数据库、分布式缓存、本地缓存等。它们表现形式各异,却有着共同的朴素的本质:弥补CPU的高算力和IO的读写慢之间的巨大鸿沟。
和架构选型类似,每引入一个组件,都会导致复杂度的上升。以缓存为例,它带来性能提升的同时,也带来一些问题,需要开发者设计和权衡。
在初期业务量小的时候,数据库能承担读写压力,应用可以直接和DB交互,架构简单且强壮。
经过一段时间发展后,业务量迎来了大规模增长,此时DB查询压力和耗时都在增长。此时引入分布式缓存,在减少DB压力的同时,还提供了更高的QPS。
再往后发展,分布式缓存也成为了瓶颈,高频的QPS是一笔负担;另外缓存驱逐以及网络抖动会影响系统的稳定性,此时引入本地缓存,可以减轻分布式缓存的压力,并减少网络以及序列化开销。
随着时间的推移系统越来越庞大,可能缓存需要的硬件资源已经跟服务本身持平,换一种说法,极端情况下,即便不做任何修改,直接横向扩容服务,也能达到当前处理能力。但是通过增加中间件的方式,凭空多出一坨服务。
这种优化方式通常有一个特点,前期见效特别快,而且对于降低时延有很好的效果,但同时会消耗一定的硬件资源,另外伴随着中间件的引入,需要额外的维护成本。
通过上述架构调整的方式做优化称为为「实践派」,他的一大特点就是引入另外一个组件来降低当前组件压力,系统设计哲学「如无必要勿增实体」,关键点在于引入之后是否能够带来更高的价值。比如我们常见的虚拟机、容器化等,虽然在操作系统层面引入了一个第三方组件,却带来了安全性、可扩展性、资源调度等极大收益。
另一部人喜欢在局部进行优化,比如常见的降低算法复杂度、进程间通信(IPC)、管道、事件、并行、批量、多线程、池化,比如我们常见的连接池、epoll替换select、lz4/zstd算法替换gzip压缩等都是类似的思路。
在做这种优化的过程中,往往在局部着手,看到一个函数调用必然想到另外一个更快的函数调用、看到一个递归总要想办法改成for循环...
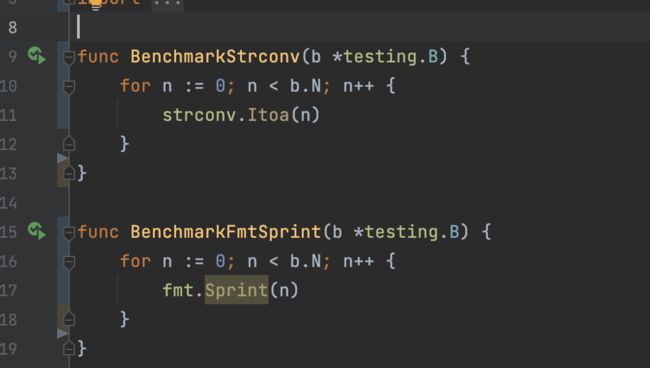
goarch: amd64
pkg: main
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkStrconv-12 41988014 27.41 ns/op
BenchmarkFmtSprint-12 13738172 81.19 ns/op(以Golang字符串转换为例)可以看到strconv每次执行只用了27.41纳秒,而fmt.Sprint则是81.19纳秒,strconv的性能是fmt.Sprint的三倍,那为什么strconv要更快呢?如果你用pprof或者benchmem会发现 fmt 需要更多的内存分配,因为fmt.Sprint则是通过反射来实现,需要类型转换,性能上有所损耗,而strconv是通过不断取余拼接字符串得到结果。
解决了一个性能问题,理论会带来的一定性能提升,但是当放到服务器上运行一下,发现没有任何效果,因为对于 3GHz的 CPU,每秒可以执行几十亿次计算,这块函数的执行速度在ns范围内,根本不是应用程序的短板,所以很难看到效果。
这种性能优化的方式往往会带来一些隐形的收益,在短时间内很难直接看到优化结果,即便如此,我们还是要在日常开发中注意本地函数的细节性能消耗,大的性能问题都是从一点一滴积累出来的。
要想带来比较明显的性能优化方式,可以使用profile、perf采样函数执行性能消耗,通过火焰图观察整体代码中消耗点。针对主要消耗点进行优化,这样能够对整体性能提升带来明显的效果。
这种性能优化方式通常需要花费大量的精力和时间调整算法和分析代码执行,反反复复,非常考验技术人员的耐心和基础技术能力。
这种不进行大的架构调整,并且不引入第三方服务的性能优化的方式,一般称之为「学院派」,这种性能优化方式需要在现有应用程序做算法优化,一旦得到优化会带来极大的收益。
其实对于三高系统的设计无论是学院派还是实践派,其背后的哲学原理都是一样的,都是符合某种层面上的「时空转换」。
比如我们常用缓存、中间件来提高服务的性能,减少卡顿,这就是典型的用空间换时间。同时我们也会偶尔用压缩技术,压缩一个文件,然后在读取的时候再进行解压缩。这就是典型的用时间换空间。
貌似性能优化总是在做时空转换,那有没有从空间到时间都得到性能提升的优化呢?也不是没有。但优化的代价可能是工程复杂度和人力成本,更巧妙的代码通常也意味着不够直接,更难读懂,更难扩展和维护,同时也可能是针对特定情形的优化,使得解决方案的通用性降低。乍一看,这种优化让人更容易接受。比如一个简单的排序,我们最开始用的是冒泡排序,相信每个程序员都会编写这个双层for循环的冒泡排序,后来改成了快速排序,我们假设快排就是比冒泡排序优秀,时间复杂度空间复杂度都更低。但同时快排的代码更难写,也更难读懂,接手的同学根本不理解这个算法怎么实现的,也不敢改,那后续来了需求要修改一下排序的某个逻辑,同学一下子就慌了,最后改了一个星期终于改好,硬着头皮上了。如果是用冒泡排序,相信这个同学很快就能满足新的改动需求。
当然笔者并不是要表达保持现状,不进行必要的优化,不去探索更优秀更简单的算法。而是说,每次优化都是有代价的,只不过你没有意识到优化带来的负面作用。在优化过程中不仅仅要考虑技术层面的架构复杂度、代码复杂度,更要考虑后续的维护成本和工程复杂度。
如果这个系统是纽交所的交易系统,要求把时延稳定在us以内,投入更多的硬件资源、同时扩充更多的中间件也在所不惜。如果这是一个内部服务,对时延没有太多的要求,同时占用非常多硬件资源,这就要想办法从算法和当前系统入手,降低硬件资源的使用是首要任务。非必要不引入第三方系统。所以说性能优化在不同的时间、不同的应用程序、甚至不同的负责人,会存在不同的优化目标。
上述也介绍性能优化分为实践派和学院派,其实这些派别根本不重要,重要的是要分析和明确优化的重点和目标,以此又会牺牲什么为代价,确定好了再做性能优化。如果分析不清就盲目优化,就有可能得不到预想效果或进行「反向优化」,同时还给应用程序的未来埋了不确定的坑。

原创不易,随手关注或者”在看“,诚挚感谢!