07_Pulsar高级组件基本使用(Connector,Functions,事务)、Function(轻量级计算流程)概念与使用、Connector 连接器概念与使用,其它Connector
2.Apache Pulsar高级
2.1.Pulsar高级组件基本使用(Connector,Functions,事务)
2.1.1.Function(轻量级计算流程)概念与使用
2.1.1.1.Pulsar Function轻量级计算框架
2.1.2.Connector 连接器概念与使用
2.1.2.1.Pulsar Connector 连接器
2.1.2.2.Pulsar Connector连接器 —>Pulsar Flink Connector
2.1.2.3.如何在flink的流式环境中使用Pulsar: sink端
2.1.2.4.schema flink source sink
2.1.2.5.Pulsar Flume Connector
2.1.3.2.Pulsar Transactions(事务支持)
2.Apache Pulsar高级
2.1.Pulsar高级组件基本使用(Connector,Functions,事务)
2.1.1.Function(轻量级计算流程)概念与使用
2.1.1.1.Pulsar Function轻量级计算框架
- Function背景介绍
当我们进行流式处理的时候,很多情况下,我们的需求可能只是下面这些简单的操作:简单的 ETL 操作\聚合计算操作等相关服务。
但为了实现这些功能,我们不得不去部署一整套 SPE 服务。部署成功后才发现需要的仅是 SPE(流处理引擎) 服务中的一小部分功能,部署 SPE 的成本可能比用户开发这个功能本身更困难。由于SPE 本身 API 的复杂性,我们需要了解这些算子的使用场景,明白不同算子之间有哪些区别,什么情况下,应该使用什么算子来处理相应的逻辑。
基于以上原因,我们设计并实现了 Pulsar Functions,在 Pulsar Functions 中,用户只需关心计算逻辑本身,而不需要去了解或者部署 SPE 的相关服务,当然你也可以将 pulsar-function 与现有的 SPE 服务一起使用。 也就是说,在 Pulsar Functions 中,无需部署 SPE 的整套服务,就可以达到与 SPE 服务同样的优势 。
- 什么是Functions
Pulsar Functions 是一个轻量级的计算框架,像 AWS 的 lambda、Google Cloud 的 Functions一样,Pulsar Functions 可以给用户提供一个部署简单、运维简单、API 简单的 FASS(Function as a service)平台。
Pulsar Functions 的设计灵感来自于 Heron 这样的流处理引擎,Pulsar Functions 将会拓展 Pulsar 和整个消息领域的未来。使用 Pulsar Functions,用户可以轻松地部署和管理 function,通过 function 从 Pulsar topic 读取数据或者生产新数据到 Pulsar topic。
引入 Pulsar Functions 后,Pulsar 成为统一的消息投递/计算/存储平台。只需部署一套 Pulsar 集群,便可以实现一个计算引擎,页面简单,操作便捷。
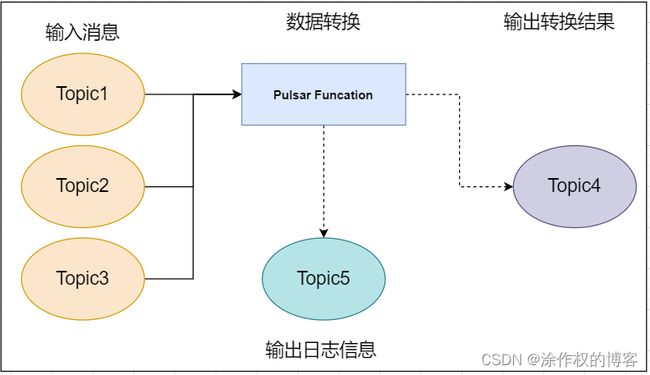
- 什么是Functions
Input topic 是数据的来源,在 Pulsar Functions 中,所有的数据均来自 input topic。当数据进入input topic 中,Pulsar Functions 充当消费者的角色,去 input topic 中消费消息;当从 input topic 中拿到需要处理的消息时,Pulsar Functions 充当生产者的角色往 output topic 或者 log topic 中生产消息。
Output topic 和 log topic 都可以看作是 Pulsar Functions 的输出。从是否会有 output 这个点来看,我们可以将 Pulsar Functions 分为两类,当有输出的时候 Pulsar Functions 会将相应的 output 输出到 output topic中。log topic 主要存储用户的日志信息,当 Pulsar Functions 出现问题时,方便用户定位错误并调试。
综上所述:我们不难看出 Pulsar Functions 充当了一个消息处理和转运的角色。
在使用Pulsar Functions, 可以使用不同的语言来编写,比如Python, Java,Go等。编写方式主要两种:
- 本地模式:集群外部,进行本地运行
- 集群模式:集群内部运行(支持独立模式和集成模式)
如何使用呢?
首先,需要修改Pulsar中相关的配置:
[root@node1 bin]# cd /export/server/pulsar-2.8.1/conf/
[root@node1 conf]# vim broker.conf
内容如下:
# Enable Functions Worker Service in Broker
functionsWorkerEnabled=false 更改为:true
注意:三台节点都需要调整
接着,重启Broker即可:
cd /export/server/pulsar-2.8.1/bin
./pulsar-daemon stop broker
./pulsar-daemon start broker
最后通过:./pulsar-admin brokers list pulsar-cluster 查看broker列表
注意:三台节点都需要执行,依次都停止,然后依次启动
如何使用呢?
最后,测试是否可用
bin/pulsar-admin functions create \
--jar examples/api-examples.jar \
--classname org.apache.pulsar.functions.api.examples.ExclamationFunction \
--inputs persistent://public/default/exclamation-input \
--output persistent://public/default/exclamation-output \
--tenant public \
--namespace default \
--name exclamation
输出结果:
"Created successfully"
检查是否按照预期触发函数运行:
[root@node1 pulsar-2.8.1]# bin/pulsar-admin functions trigger --name exclamation --trigger-value "hello world"
hello world!
如何使用呢?
[root@node1 pulsar-2.8.1]# bin/pulsar-admin functions
Usage: pulsar-admin functions [command] [command options]
Commands:
localrun Run a Pulsar Function locally, rather than deploy to a
Pulsar cluster)
Usage: localrun [options]
Options:
--auto-ack
Whether or not the framework acknowledges messages automatically
--batch-builder
BatcherBuilder provides two types of batch construction methods,
DEFAULT and KEY_BASED. The default value is: DEFAULT
--broker-service-url
The URL for Pulsar broker
--classname
The class name of a Pulsar Function
--client-auth-params
Client authentication param
--client-auth-plugin
Client authentication plugin using which function-process can
connect to broker
--cpu
The cpu in cores that need to be allocated per function
instance(applicable only to docker runtime)
--custom-runtime-options
A string that encodes options to customize the runtime, see docs
for configured runtime for details
--custom-schema-inputs
The map of input topics to Schema properties (as a JSON string)
--custom-schema-outputs
The map of input topics to Schema properties (as a JSON string)
--custom-serde-inputs
The map of input topics to SerDe class names (as a JSON string)
The namespace of a Pulsar Function
* -s, --state
The FunctionState that needs to be put
--tenant
The tenant of a Pulsar Function
trigger Trigger the specified Pulsar Function with a supplied value
Usage: trigger [options]
Options:
--fqfn
The Fully Qualified Function Name (FQFN) for the function
--name
The name of a Pulsar Function
--namespace
The namespace of a Pulsar Function
--tenant
The tenant of a Pulsar Function
--topic
The specific topic name that the function consumes from that you
want to inject the data to
--trigger-file
The path to the file that contains the data with which you want to
trigger the function
--trigger-value
The value with which you want to trigger the function
bin/pulsar-admin functions
属性说明:
functions:可选值:
localrun: 创建本地function进行运行
create: 在集群模式下创建
delete: 删除在集群中运行的function
get: 获取function的相关信息
restart: 重启
stop : 停止运行
start: 启动
status: 检查状态
stats: 查看状态
list: 查看特定租户和名称空间下的所有的function
--classname: 设置function执行类
--jar 设置function对应的jar包
--inputs : 输入的topic
--output : 输出的topic
--tenant : 设置function运行在那个租户中
--namespace: 设置function运行在那个名称空间中
--name : 定义function的名称
接下来, 我们尝试编写一个function的操作, 基于Pulsar Function完成流式计算操作:
案例需求:
使用Pulsar Function读取某一个Topic中旧期(格式为:yyyy/MM/dd HH/mm/ss)数据,读取后,对数据进行日期转换(格式为:yyyy-MM-dd HH:mm:ss)
首先加入依赖:
<dependency>
<groupId>org.apache.pulsargroupId>
<artifactId>pulsar-functions-apiartifactId>
<version>2.8.1version>
dependency>
接着编写程序:
package com.toto.learn.functions;
import org.apache.pulsar.functions.api.Context;
import org.apache.pulsar.functions.api.Function;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @author tuzuoquan
* @version 1.0
* @ClassName WordCountFunction
* @description TODO
* @date 2022/8/24 23:55
**/
public class WordCountFunction implements Function<String,String> {
private SimpleDateFormat format1 = new SimpleDateFormat("yyyy/MM/dd HH/mm/ss");
private SimpleDateFormat format2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public String process(String input, Context context) throws Exception {
Date oldDate = format1.parse(input);
return format2.format(oldDate);
}
}
对项目程序进行打包部署:
将上面的jar包放到服务器
构建function
[root@node1 pulsar-2.8.1]# mkdir -p /export/server/pulsar-2.8.1/functions (3个节点)
cd /export/server/pulsar-2.8.1/functions
将pulsar-base-1.0-SNAPSHOT.jar上传到该目录下
[root@node1 functions]# scp -r pulsar-base-1.0-SNAPSHOT.jar root@node2:$PWD
pulsar-base-1.0-SNAPSHOT.jar 100% 15KB 692.7KB/s 00:00
[root@node1 functions]# scp -r pulsar-base-1.0-SNAPSHOT.jar root@node3:$PWD
pulsar-base-1.0-SNAPSHOT.jar 100% 15KB 11.8MB/s 00:00
[root@node1 functions]#
bin/pulsar-admin functions create \
--jar functions/pulsar-base-1.0-SNAPSHOT.jar \
--classname com.toto.learn.functions.WordCountFunction \
--inputs persistent://public/default/wd_input \
--output persistent://public/default/wd_output \
--tenant public \
--namespace default \
--name wordcount
"Created successfully"
启动function
trigger触发启动,并向函数发送数据测试
[root@node1 pulsar-2.8.1]# bin/pulsar-admin functions trigger --name wordcount --trigger-value "2021/10/10 15/30/30"
2021-10-10 15:30:30
从上可以看出日期格式出现了变化
此外, 也可以通过代码向input对应的Topic发送消息, 并消费output对应的Topic中数据, 也是可以看到function可以正常处理的。
2.1.2.Connector 连接器概念与使用
2.1.2.1.Pulsar Connector 连接器
虽然可以使用 Pulsar 消费者和生产者 API 编写代码(例如,从数据库同步数据时,先查询数据,再使用
Pulsar 的 API 将数据发布至 Pulsar),但这种方法耗时费力。因此,Pulsar 提出了 Connector (也称为
Pulsar IO),用于解决 Pulsar 与周边系统的集成问题,帮助用户高效完成工作。

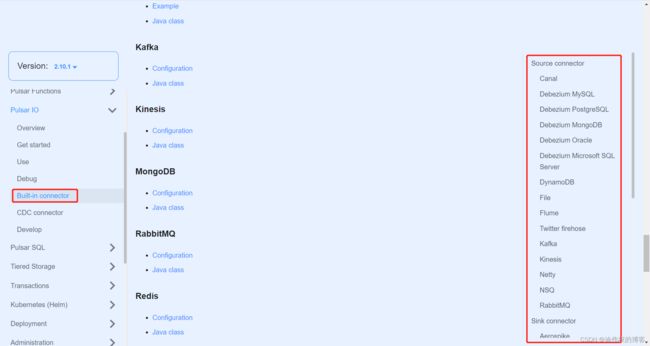
这张图非常直观地描述了 Pulsar IO 的组成。
Pulsar IO分为输入(Input)和输出(Output)两个模块。
输入:代表数据从哪里来,通过Source实现数据输入。数据的来源可以是数据库(例如MySQL、Oracle、MongoDB)、文件、日志或自定义系统等。
输出:代表数据往哪里去,通过Sink实现数据输出。数据的输出可以是数据仓库、数据库等。
而目前Pulsar支持非常多的Connector,可以参考以下几个网站:
http://pulsar.apache.org/docs/zh-CN/io-connectors/#source-connector
http://pulsar.apache.org/docs/zh-CN/io-connectors/#sink-connector
目前我们主要介绍 Pulsar flink Connector 和 Pulsar Flume Connector
其他的连接器的使用方式, 基本是类似的

2.1.2.2.Pulsar Connector连接器 —>Pulsar Flink Connector
Pulsar Flink Connector是Apache Pulsar和Apache Flink(数据处理引擎)的集成,它允许Flink从Pulsar读取数据
,并向Pulsar写入数据,并提供精确一次的源语义和至少一次的汇聚语义。

如何使用pulsar Flink Connector, 首先在pom中加入相关的依赖环境:(注意: 还需要添加 pulsar客户端包)
<repositories>
<repository>
<id>aliyunid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<releases><enabled>trueenabled>releases>
<snapshots>
<enabled>falseenabled>
<updatePolicy>neverupdatePolicy>
snapshots>
repository>
repositories>
<dependencies>
<dependency>
<groupId>org.apache.pulsargroupId>
<artifactId>pulsar-client-allartifactId>
<version>2.8.1version>
dependency>
<dependency>
<groupId>org.apache.pulsargroupId>
<artifactId>pulsar-functions-apiartifactId>
<version>2.8.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>1.13.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.11artifactId>
<version>1.13.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.11artifactId>
<version>1.13.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-commonartifactId>
<version>1.13.1version>
dependency>
<dependency>
<groupId>io.streamnative.connectorsgroupId>
<artifactId>pulsar-flink-connector_2.11artifactId>
<version>1.13.1.5-rc1version>
<exclusions>
<exclusion>
<groupId>org.apache.pulsargroupId>
<artifactId>pulsar-client-allartifactId>
exclusion>
exclusions>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.1version>
<configuration>
<target>1.8target>
<source>1.8source>
configuration>
plugin>
plugins>
build>
2.1.2.3.如何在flink的流式环境中使用Pulsar: sink端
- 前置准备:装nc工具
yum -y install nc
- 发送数据:
nc -lk 44444
例如:
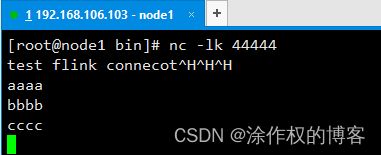
编写FlinkFromPulsarSink,内容如下:
package com.toto.learn.connector.flink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSink;
import org.apache.flink.streaming.util.serialization.PulsarPrimitiveSchema;
import java.util.Optional;
import java.util.Properties;
/**
* @author tuzuoquan
* @version 1.0
* @ClassName FlinkFromPulsarSink
* @description TODO
* @date 2022/8/25 23:44
**/
public class FlinkFromPulsarSink {
public static void main(String[] args) throws Exception {
//1.创建flink的流式处理的核心类对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.添加source组件:监控某一个端口号,从端口号读取数据操作
DataStreamSource<String> streamSource = env.socketTextStream("node1", 44444);
//3.添加转换的组件
//4.添加sink的组件: 如何将处理后的数据输出到Pulsar中
FlinkPulsarSink<String> pulsarSink = new FlinkPulsarSink<String>(
"pulsar://node1:6650,node2:6650,node3:6650",
"http://node1:8080,node2:8080,node3:8080",
Optional.of("persistent://toto_pulsar_t/toto_pulsar_n/t_topic1"),
new Properties(),
new PulsarPrimitiveSchema<>(String.class)
);
streamSource.addSink(pulsarSink);
//5.启动flink程序
env.execute("flinkPulsarSink");
}
}
观察消费者消费数据情况:
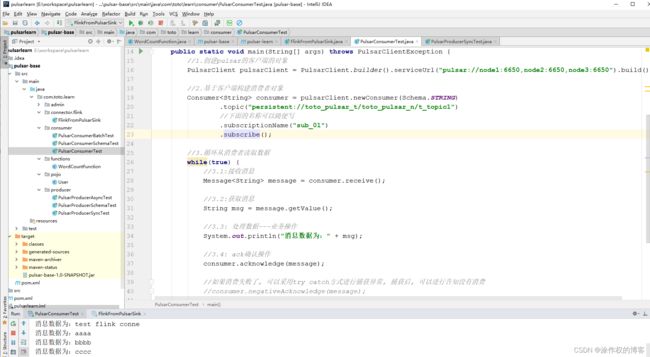
FlinkFromPulsarSink的内容如下:
package com.toto.learn.connector.flink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSink;
import org.apache.flink.streaming.util.serialization.PulsarPrimitiveSchema;
import java.util.Optional;
import java.util.Properties;
/**
* @author tuzuoquan
* @version 1.0
* @ClassName FlinkFromPulsarSink
* @description TODO
* @date 2022/8/25 23:44
**/
public class FlinkFromPulsarSink {
public static void main(String[] args) throws Exception {
//1.创建flink的流式处理的核心类对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.添加source组件:监控某一个端口号,从端口号读取数据操作
DataStreamSource<String> streamSource = env.socketTextStream("node1", 44444);
//3.添加转换的组件
//4.添加sink的组件: 如何将处理后的数据输出到Pulsar中
FlinkPulsarSink<String> pulsarSink = new FlinkPulsarSink<String>(
"pulsar://node1:6650,node2:6650,node3:6650",
"http://node1:8080,node2:8080,node3:8080",
Optional.of("persistent://toto_pulsar_t/toto_pulsar_n/t_topic1"),
new Properties(),
new PulsarPrimitiveSchema<>(String.class)
);
streamSource.addSink(pulsarSink);
//5.启动flink程序
env.execute("flinkPulsarSink");
}
}
启动nc工具:
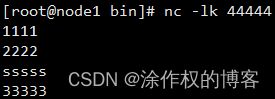
借助:启动FlinkFromPulsarSink
nc工具发送数据的时候,可以看到:
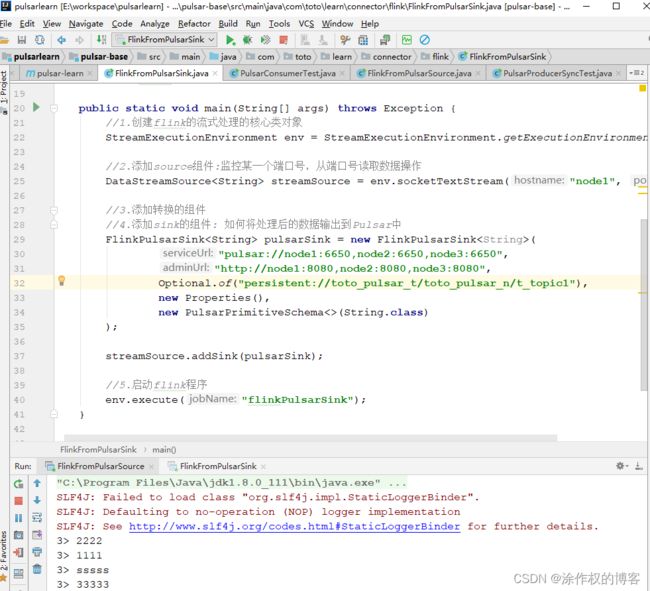
2.1.2.4.schema flink source sink
package com.toto.learn.connector.flink;
import com.toto.learn.pojo.User;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSink;
import org.apache.flink.streaming.connectors.pulsar.FlinkPulsarSource;
import org.apache.flink.streaming.connectors.pulsar.config.RecordSchemaType;
import org.apache.flink.streaming.connectors.pulsar.internal.AvroDeser;
import org.apache.flink.streaming.connectors.pulsar.internal.AvroSer;
import org.apache.flink.streaming.connectors.pulsar.internal.PulsarSerializer;
import org.apache.flink.streaming.util.serialization.PulsarSerializationSchemaWrapper;
import java.util.Optional;
import java.util.Properties;
/**
* @author tuzuoquan
* @version 1.0
* @ClassName FlinkFromPulsarSchema
* @description 需求: 基于Flink实现读取一个POJO类型的数据, 将将数据写入到Pulsar中
* @date 2022/8/26 0:49
**/
public class FlinkFromPulsarSchema {
public static void main(String[] args) throws Exception {
//1.创建Flink流式处理的核心环境类对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.添加source组件:从Pulsar中读取数据
Properties props = new Properties();
props.setProperty("topic","persistent://toto_pulsar_t/toto_pulsar_n/t_topic2");
FlinkPulsarSource<User> pulsarSource = new FlinkPulsarSource<User>(
"pulsar://node1:6650,node2:6650,node3:6650",
"http://node1:8080,node2:8080,node3:8080",
AvroDeser.of(User.class),
props
);
DataStreamSource<User> streamSource = env.addSource(pulsarSource);
//3.添加转换处理操作
//4.添加sink的组件:将处理后的数据写出到Pulsar中
streamSource.print();
PulsarSerializationSchemaWrapper<User> pulsarSerialization = new PulsarSerializationSchemaWrapper
.Builder<User>(AvroSer.of(User.class))
.usePojoMode(User.class, RecordSchemaType.AVRO)
.build();
FlinkPulsarSink<User> pulsarSink = new FlinkPulsarSink<User>(
"pulsar://node1:6650,node2:6650,node3:6650",
"http://node1:8080,node2:8080,node3:8080",
Optional.of("persistent://toto_pulsar_t/toto_pulsar_n/t_topic4"),
new Properties(),
pulsarSerialization
);
streamSource.addSink(pulsarSink);
//5.启动flink程序
env.execute("Pulsar connector Flink");
}
}
2.1.2.5.Pulsar Flume Connector
如何基于Flume完成采集数据到Pulsar:
- 第一步: 在windows下载相关源码
- 第二步:执行打包命令:
mvn clean package
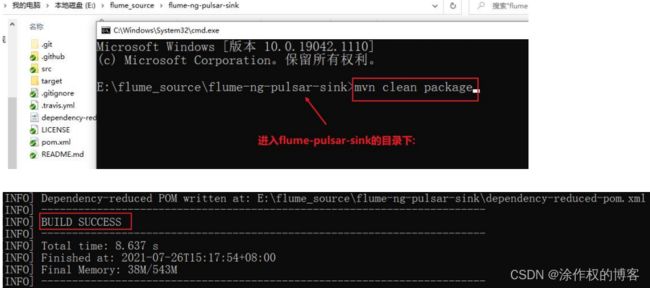
-
此时会产生一个target目录, 进入目录下, 就看到已经打好的包了:

-
第三步: 将jar上传到flume的lib目录下
在安装flume的服务器节点上:
cd${FLUME_HOME}/lib
rz 上传即可 -
第四步: 配置Flume的采集文件
a1.sources = r1
a1.channels = c1
a1.sinks = k1
a1.sources.r1.type = netcat
a1.sources.r1.bind = node1
a1.sources.r1.port = 44444
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.serviceUrl = node1.itcast.cn:6650,node2.itcast.cn:6650,node3.itcast.cn:6650
a1.sinks.k1.topicName = flume-test-topic
a1.sinks.k1.producerName = flume-test-producer
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 第五步: 执行启动Flume
./flume-ng agent -n a1 -c ../conf/ -f ../conf/netcat_source_pulsar_sink.conf -Dflume.root.logger=INFO,console
- 第六步: 执行启动Flume

- 第七步: 观察消费者是否可以正常消费数据
2.1.3.Transactions事务支持相关的操作
2.1.3.1.Pulsar如何实现Exactly-Once
Apache Pulsar 社区在刚刚发布的 Pulsar 2.8.0 版本中实现了一个里程碑式功能:Exactly-once(精确一次)语义。在这之前,我们只能通过在 Broker 端开启消息去重来保证单个 Topic 上的 Exactly-once 语义。随着Pulsar 2.8.0 的发布,利用事务 API 可以在跨 Topic 的场景下保证消息生产和确认的原子性操作。
消息语义主要分为有至少一次,最多一次,精确一次 三种确认方案
至少一次:
Producer通过接收Broker的ACK(消息确认)通知来确保消息成功写入Pulsar Topic。然而,当Producer接收ACK通知超时,或者收到Broker出错信息时,会尝试重新发送消息。如果Broker正好在成功把消息写入到Topic,但还没有给Producer发送ACK时宕机,Producer重新发送的消息会被再次写入到Topic,最终导致消息重新分发至Consumer。
最多一次:
当Producer在接收ACK超时,或者收到Broker出错信息时不重发消息,那就有可能导致这条消息丢失,没有写入到Topic中,也不会被consumer消费到。在某些场景下,为了避免发生重复消息,我们可以容许消息丢失的发生。
精确一次:
保证了即使Producer多次发送同一次消息到服务端,服务端也仅仅会记录一次。Exactly-once语义是最可靠的,同时也是最难理解的。Exactly-once语义需要消息队列服务端,消息生产端和消费端应用三者的协同才能实现。比如,当消费端应用成功消费并且ACK了一条消息之后,又把消费位点回滚到之前的一个消息ID,那么从那个消息ID往后的所有消息都会被消费端应用重新消费到。
Pulsar在最新的版本中, 通过事务API 实现跨topic消息生产和确认的原子性操作, 通过这个功能,Producer可以确保一条消息同时发送到多个 Topic,要么这些消息都发送成功,在所有 Topic上都可以被消费,要么所有消息都不能被消费。这个功能也允许在一个事务操作中对多个 Topic 上的消息进行 ACK 确认,从而实现端到端的Exactly-once 语义。
2.1.3.2.Pulsar Transactions(事务支持)
事务语义允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。在Pulsar中,生产者或消费者能够处理跨多个主题和分区的消息,允许一个原子操作写入多个主题和分区,同时事务中的批量消息可以被以多分区接收、生产和确认,一个事务涉及的所有操作都作为整体成功或失败。事务中几个概念需要大家了解:
事务协调者事务日志:
事务调度器负责维护在事务中互相关联的主题和订阅信息。 事务提交后,事务调度器与主题所在的broker交互完成事务。所有事务元数据都持久化在事务日志中。事务日志由一个pulsar的topic支持。
事务ID:
事务ID是pulsar中用于标记一条事务的标志, 长度为128位字节, 前16为表示事务协调器的id,其余位用于代表事务协调器中一个个的事务, 是递增的, 便于后期定位失败的事务操作。
事务缓存:
事务中产生的消息存储在事务缓冲区中。在事务提交之前,事务缓存中的消息对消费者是不可见的。当事务中止时,事务缓冲区中的消息将被丢弃。
待确认状态:
事务完成前,事务中的消息确认由挂起的确认状态维护。如果消息处于挂起的确认状态,则在消息从挂起的确认状态中删除之前,其他事务无法确认该消息。挂起的确认状态将持久化到挂起的确认日志中。等待由一个pulsar的topic所支持的确认日志返回。新的broker可以从挂起的确认日志中恢复状态,以确保确认不会丢失。
- 第一步: 修改pulsar的broker.conf文件: 开启事务支持
#1257行: 开启事务支持
transactionCoordinatorEnabled=true
#468行:开启批量确认
acknowledgmentAtBatchIndexLevelEnabled=false
- 第二步: 初始化事务协调器元数据,然后将Pulsar(bookie和Broker)进行重启
cd /export/server/pulsar-2.8.1/bin
./pulsar initialize-transaction-coordinator-metadata -cs node1:2181,node2:2181,node3:2181 -c pulsar-cluster
输出结果:
22:50:07.004 [main-EventThread] INFO org.apache.pulsar.metadata.impl.ZKSessionWatcher - Got ZK session watch event: WatchedEvent state:Closed type:None path:null
22:50:07.005 [main] INFO org.apache.zookeeper.ZooKeeper - Session: 0x10009ea312e000b closed
Transaction coordinator metadata setup success
22:50:07.009 [main-EventThread] INFO org.apache.zookeeper.ClientCnxn - EventThread shut down for session: 0x10009ea312e000b
[root@node1 bin]#
- 第三步:在代码中构建一个支持事务的Pulsar的客户端
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://node1:6650,node2:6650,node3:6650")
.enableTransaction(true)
.build();
- 第四步:开启事务支持
Transaction txn = pulsarClient.newTransaction()
.withTransactionTimeout(5, TimeUnit.MINUTES)
.build().get();
- 第五步:执行相关操作:
try {
//3.1.接收消息
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic("persistent://toto_pulsar_t/toto_pulsar_n/t_topic1")
.subscriptionName("my-subscription")
//.enableBatchIndexAcknowledgment(true) //开启批量消息确认
.subscribe();
//3.2 获取消息
Message<byte[]> message = consumer.receive();
System.out.println("消息为:" + message.getTopicName() + ":" + new String(message.getData()));
//3.3 将接收到的消息,处理后,发送到另一个Topic中
Producer<byte[]> producer = pulsarClient.newProducer()
.topic("persistent://toto_pulsar_t/toto_pulsar_n/t_topic4")
.sendTimeout(0, TimeUnit.MILLISECONDS)
.create();
producer.newMessage(txn).value(message.getData()).send();
System.out.println(1111);
//3.4: 确认输入的消息
consumer.acknowledge(message);
//4.如果正常,就提交事务
txn.commit();
} catch (Exception e) {
System.out.println(1111);
//否则就回滚事务
txn.abort();
e.printStackTrace();
}
在测试时, 可以通过在提交数据之前, 制造一个小错误, 让其抛出异常, 观察其是否可以发送成功, 并且在重新跑, 是否还会重新
获取之前数据进行消费操作。
总的结果:
package com.toto.learn.transaction;
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.Message;
import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.PulsarClientException;
import org.apache.pulsar.client.api.Schema;
import org.apache.pulsar.client.api.transaction.Transaction;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
/**
* @author tuzuoquan
* @version 1.0
* @ClassName PulsarTransactionTest
* @description TODO
* @date 2022/8/29 0:19
**/
public class PulsarTransactionTest {
//Pulsar事务的测试操作
public static void main(String[] args) throws PulsarClientException, ExecutionException, InterruptedException {
//1.创建一个支持事务的Pulsar的客户端
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://node1:6650,node2:6650,node3:6650")
.enableTransaction(true)
.build();
//2.开启事务支持
Transaction txn = pulsarClient.newTransaction().withTransactionTimeout(5, TimeUnit.MINUTES)
.build().get();
try {
//3.执行相关的操作
//3.1:接收消息数据
Consumer<String> consumer = pulsarClient.newConsumer(Schema.STRING)
.topic("persistent://toto_pulsar_t/toto_pulsar_n/t_topic1")
.subscriptionName("my-subscription")
.subscribe();
Message<String> message = consumer.receive();
//3.2: 处理数据操作
System.out.println("消息数据为:" + message.getValue());
//3.3: 将处理后的数据,发送到另一个Topic中
Producer<String> producer = pulsarClient.newProducer(Schema.STRING)
.topic("persistent://toto_pulsar_t/toto_pulsar_n/t_topic4")
.sendTimeout(0, TimeUnit.MILLISECONDS)
.create();
producer.newMessage(txn).value(message.getValue()).send();
//额外添加一个异常
//double a = 1/0;
//4.确认消息
consumer.acknowledge(message);
//提交事务
txn.commit();
} catch (Exception e) {
//如果有异常,直接回滚
txn.abort();
e.printStackTrace();
}
}
}