ElasticSearch详解
ElasticSearch介绍:
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个基于Restful web接口的分布式全文搜索引擎。ElasticSearch是用Java语言开发的,用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便,根据DB-Engines的排名显示,ElasticSearch是最受欢迎的企业搜索引擎,其次是Apache Solr(也是基于Lucene).
原理与应用:
ElasticSearch的索引结构

右边黑蓝色色部分是原始文档,左边黄色部分是逻辑结构,逻辑结构也是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。
倒排索引
在提到倒排索引之前,先说一下什么是正排索引,比如说我们查字典,根据自己要查的内容一页一页的去查,这就是正排索引(如mysql的条件查询方式)。而倒排索引则是查字典时,根据要查的关键字在目录里面去找,可以显著的提高查询效率。
逻辑结构部分是一个倒排索引表,由三部分组成:
1、将搜索的文档最终以Document方式存储起来。
2、将要搜索的文档内容分词,所有不重复的词组成分词列表。
3、每个分词和docment都有关联。
如下:

现在,如果我们想搜索 包含quick brown词条的文档:
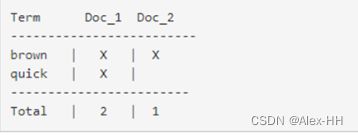
两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳
倒排索引中的分词列表有三个特点:1.分词不可重复。2.语气助词不存入分词。3.没有用到的field不会被存入分词(如图片)
ElasticSearch的安装:
安装的环境(Linux)需求:
1、jdk必须是jdk1.8.0_131以上版本。
2、ElasticSearch 需要至少4096 的线程池和 262144字节以上空间的虚拟内存才能正常启动,所以需要为虚拟机分配至少1.5G以上的内存
3、从5.0开始,ElasticSearch 安全级别提高了,不允许采用root帐号启动
4、Elasticsearch的插件要求至少centos的内核要3.5以上版本
(我这里用的是VMware16Plus,CentOs7)
1、在官网下载ElasticSearch:https://www.elastic.co/cn/
2、设置虚拟机内存:

3、创建用户:
创建用户组:
groupadd elk创建用户admin:
useradd admin
passwd admin将admin用户添加到elk组
usermod -G elk admin为用户分配权限
#chown将指定文件的拥有者改为指定的用户或组 -R处理指定目录以及其子目录下的所有文件
chown -R admin:elk /usr/upload
chown -R admin:elk /usr/local切换用户
su admin4、安装:
ES是Java开发的应用,解压即安装:
tar -zxvf elasticsearch-6.2.3.tar.gz -C /usr/local安装完毕后,看一下ES的目录结构:
bin 目录:可执行文件包
config 目录:配置相关目录
lib 目录:ES 需要依赖的 jar 包,ES 自开发的 jar 包
logs 目录:日志文件相关目录
modules 目录:功能模块的存放目录,如aggs、reindex、geoip、xpack、eval
plugins 目录:插件目录包,三方插件或自主开发插件
data 目录:在 ES 启动后,会自动创建的目录,内部保存 ES 运行过程中需要保存的数据。
配置文件有如下三个:
ES安装目录config中配置文件如下:
elasticsearch.yml:用于配置Elasticsearch运行参数
jvm.options:用于配置Elasticsearch JVM设置
log4j2.properties:用于配置Elasticsearch日志
先来说一下elasticsearch.yml配置文件的相关配置:
cluster.name:
配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name:
节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
path.data:
设置索引数据的存储路径,默认是es_home下的data文件夹,可以设置多个存储路径,用逗号隔开。
path.logs:
设置日志文件的存储路径,默认是es_home下的logs文件夹
network.host:
设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。
http.port: 9200
设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300
集群结点之间通信端口
discovery.zen.ping.unicast.hosts:[“host1:port”, “host2:port”, “…”]
设置集群中master节点的初始列表。
discovery.zen.ping.timeout: 3s
设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。
http.cors.enabled:
是否支持跨域,默认为false
http.cors.allow-origin:
当设置允许跨域,默认为*,表示支持所有域名
JVM.options配置
设置最小及最大的JVM堆内存大小:
在jvm.options中设置 -Xms和-Xmx:
1) 两个值设置为相等
2) 将
Xmx设置为不超过物理内存的一半
默认内存(1g)占用稍多,可以调小一些:
-Xms512m
-Xmx512mlog4j2.properties配置
日志文件设置,ES使用log4j,注意日志级别的配置。(一般不用更改)
启动ES的方式为在bin目录下执行
./elasticsearch
#或
./elasticsearch -d
默认以非后台启动,加上-d则以后台启动
ES没有提供关闭命令,关闭只能通过杀死线程的方式:
ps-ef|grep elasticsearch
kill -9 pid
到这里ES是跑不起来的,还需解决文件创建权限问题、线程开启限制问题、虚拟内存的问题
Linux 默认来说,一般限制应用最多创建的文件是 4096个。但是 ES 至少需要 65536 的文件创建权限。我们用的是admin用户,而不是root,所以文件权限不足。
解决方式:
su root #切换到root用户
vim /etc/security/limits.conf:#修改配置文件,在最后追加如下内容
* soft nofile 65536* hard nofile 65536
默认的 Linux 限制 root 用户开启的进程可以开启任意数量的线程,其他用户开启的进程可以开启1024 个线程。必须修改限制数为4096+。因为 ES 至少需要 4096 的线程池预备。
如果虚拟机的内存是 1G,最多只能开启 3000+个线程数。至少为虚拟机分配 1.5G 以上的内存。
解决方式
su root
vim /etc/security/limits.conf:
* soft nproc 4096
* hard nproc 4096
解决虚拟内存的问题
ES 需要开辟一个 262144字节以上空间的虚拟内存。Linux 默认不允许任何用户和应用直接开辟虚拟内存。
su root
vim /etc/sysctl.conf:
vm.max_map_count=655360
sysctl -p
ES 中只要启动了任意一个 ES 应用就是启动了一个 ES的 cluster 集群。默认的 ES集群命名为 elasticsearch。如果启动了多个应用(可以在多个节点或单一节点上启动多个应用),默认的ES 会自动找集群做加入集群的过程。
Kibana的管理控制平台的使用和安装
Kibana是ES提供的一个基于Node.js的管理控制台, 可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。
kibana可以用来编辑请求语句的,方便学习操作es的语法。在编写到查询语句时,建议使用kibana进行书写,然后再粘贴到程序中。(不容易出错)
在window中安装Kibana很方便,解压即安装(这里提供好了)
链接:https://pan.baidu.com/s/1b81eWv41bDX45y1LTELlRQ
提取码:zxyy
修改配置文件(config/kibana.yml ):
server.port: 5601
server.host: "0.0.0.0" #允许来自远程用户的连接
elasticsearch.url: http://192.168.204.132:9200 #Elasticsearch实例的URL 启动,运行bin/kibana.bat即可
浏览器访问:http://127.0.0.1:5601
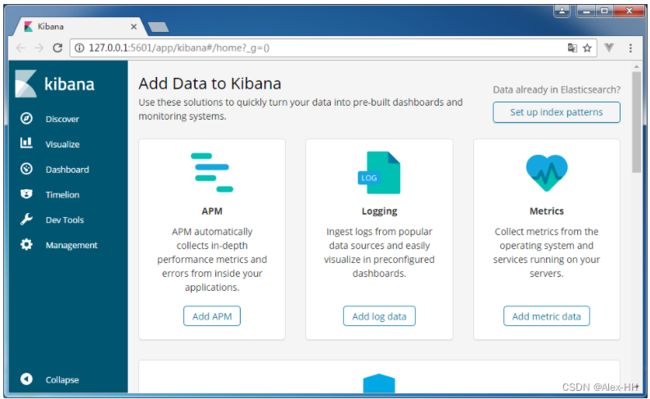
点击DevTools即可进入命令窗口,编写请求语句

Head插件的安装
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等。从ES6.0开始,head插件支持使得node.js运行。
下载地址:GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster
windows系统运行,在安装目录进入cmd窗口
npm run start
head的默认ip和端口为:127.0.0.1:9100
测试访问:

ElasticSearch的语法:
Index管理:
index是索引库,包含若干相似结构的Document数据,相当于数据库的database
创建index,语法为:
PUT /index_name{
"settings": {
"number_of_shards": number,
"number_of_replicas": number
}
}
number_of_shards - 表示一个索引库将拆分成多片分别存储不同的结点,提高了ES的处理能力
number_of_replicas - 是为每个 primary shard分配的replica shard数,提高了ES的可用性
注意:如果只有一台elasticsearch,replicas必须设置为零,这是因为主分片和备份分片放在一台机器上没有意义,如果是集群模式下,有两台elasticsearch,主分片两片,其中一台会分配到主分片0和备份分片1,另一台会分配到主分片1和备份分片0,当其中一台机器宕机后,另一台还持有一个主分片和另一个主分片的备份分片,保证数据的完整性,并且备份分片会自动变成主分片,即由原本的主分片0和备份分片1变成主分片0和主分片1,即使另一台机器重启,它拿到的也是备份分片0和备份分片1,由此可以得出一个结论,主分片可以在同一台机器上,备份分片也可以在同一台机器上,而主分片和该主分片的备份分片不能在同一台机器上。
创建index使用PUT命令而不是POST,可以这样理解,elasticsearch相当于一个大仓库,在这个大仓库里面,分隔出一个小仓库,是在原来的基础上进行修改,所以使用PUT
修改index:
先说一下重点:索引一旦创建,primary shard 数量不可变化,可以改变replica shard 数量。
这里要说一下数据路由(document routing)
当客户端创建document的时候,es需要确定这个document放在该index哪个shard上,这个过程就是document routing。
路由过程:
路由算法:shard = hash(id) %number_of_primary_shards
id:document的_id,可能是手动指定,也可能是自动生成,决定一个document在哪个shard上
number_of_primary_shards:主分片数量。
原因:假如我们的集群在初始化的时候有5个primary shard,我们往里边加入一个document id=5,假如hash(5)=23,这时该document 将被加入 (shard=23%5=3)P3这个分片上。如果随后我们给es集群添加一个primary shard ,此时就有6个primary shard,当我们GET id=5 ,这条数据的时候,es会计算该请求的路由信息找到存储他的 primary shard(shard=23%6=5) ,根据计算结果定位到P5分片上。而我们的数据在P3上。所以es集群无法添加primary shard,但是可以扩展replicas shard。
如果主分片的数量修改,读取的时候则取不到该数据
修改的语法为:PUT /index_name/_settings
PUT /alex-hh/_settings
{
"number_of_replicas" : 1
}
ES 中对 shard 的分布是有要求的,有其内置的特殊算法:
Replica shard 会保证不和他的那个 primary shard 分配在同一个节点上;如过只有一个节点,则此案例执行后索引的状态一定是yellow。
删除index
DELETE /[alex-hh, other_index]
mapping管理:
映射,创建映射就是向索引库中创建field(类型、是否索引、是否存储等特性)的过程,下边是document和field与关系数据库的概念的类比:

注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES6.x 版本之后,type概念被弱化ES官方将在ES7.0版本中彻底删除type。
创建mapping:
语法:
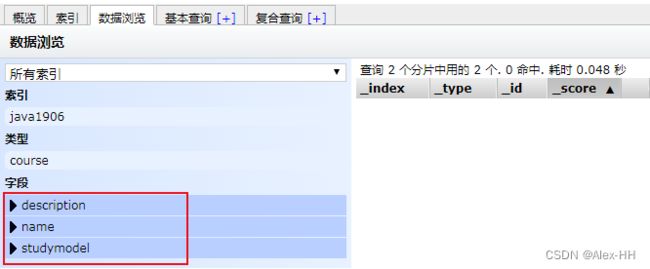
POST /index_name/type_name/_mapping如:
POST /alex-hh/course/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
效果如图:
查询mapping语法:
GET /index_name/type_name/_mapping
删除mapping语法:
DELETE /index_name/type_name/_mapping
mapping一旦创建,可以新增,但不可修改
Document管理
es中的document相当于MySQL数据库中表的记录
创建document语法有POST和PUT两种;
POST语法
POST /index_name/type_name/id(null)POST /alex-hh/course/1
{
"name":"python从入门到放弃",
"description":"人生苦短,我用Python",
"studymodel":"201002"
}POST /alex-hh/course
{
"name":".net从入门到放弃",
"description":".net程序员谁都不服",
"studymodel":"201003"
}
如果指定了id,则按指定的id生成document,如未指定,则es自动生成id
PUT语法:
PUT/index_name/type_name/id{field_name:field_value}
PUT /alex-hh/course/2
{
"name":"php从入门到放弃",
"description":"php是世界上最好的语言",
"studymodel":"201001"
}
注意:POST语法和PUT语法的区别是,POST语法只会创建这个字段,如果已经存在,则报错,而PUT语法会判断该字段是否存在,如果不存在则创建,存在则修改。
关于返回结果的解析
{
"_index": "test_index", 新增的 document 在什么 index 中,
"_type": "my_type", 新增的 document 在 index 中的哪一个 type 中。
"_id": "1", 指定的 id 是多少
"_version": 1, document 的版本是多少,版本从 1 开始递增,每次写操作都会+1
"result": "created", 本次操作的结果,created 创建,updated 修改,deleted 删除
"_shards": { 分片信息
"total": 2, 分片数量只提示 primary shard
"successful": 1, 数据 document 一定只存放在 index 中的某一个 primary shard 中
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
查询document:
语法:
GET /index_name/type_name/id或
GET /index_name/type_name/_search?q=field_name:field_value
第一个种是根据id查询,第二种则是根据给定的条件查询,如果不给条件则查询所有
查询结果解析:
{
"took": 1, # 执行的时长。单位毫秒
"timed_out": false, # 是否超时
"_shards": { # shard 相关数据
"total": 1, # 总计多少个 shard
"successful": 1, # 成功返回结果的 shard 数量
"skipped": 0,
"failed": 0
},
"hits": { # 搜索结果相关数据
"total": 3, # 总计多少数据,符合搜索条件的数据数量
"max_score": 1, # 最大相关度分数,和搜索条件的匹配度
"hits": [# 具体的搜索结果
{
"_index": "alex-hh",# 索引名称
"_type": "course", # 类型名称
"_id": "1",# id 值
"_score": 1, # 匹配度分数,本条数据匹配度分数
"_source": { # 具体的数据内容
"name": "php从入门到放弃",
"description": "php是世界上最好的语言",
"studymodel": "201001"
}, {
"_index": "alex-hh",
"_type": "course",
"_id": "2",
"_score": 0.13353139,
"_source": {
"name": "php从入门到放弃",
"description": "php是世界上最好的语言",
"studymodel": "201001"
}
}, {
"_index": "alex-hh",
"_type": "course",
"_id": "6ljFCnIBp91f7uS8FkjS",
"_score": 0.13353139,
"_source": {
"name": ".net从入门到放弃",
"description": ".net程序员谁都不服",
"studymodel": "201003"
}
}
]
}
}
删除Document
ES中执行删除时,先标记指定删除的Document为deleted状态,而不是直接物理删除(和逻辑删除有些类似)。当ES存储空间不足或工作空闲时,才会执行物理删除操作,被标记为deleted状态的数据不会被查询搜索到(注意:ES中删除Index,也是标记,后续才会执行物理操作。所有的标记都是为了NRT(近实时) 实现)
语法:DELETE /index_name/type_name/id
执行:DELETE /alex-hh/course/2
看看返回结果:
{
"_index": "alex-hh",
"_type": "course",
"_id": "2",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
ik分词器安装使用
使用IK分词器可以实现对中文分词的效果。
下载IK分词器:(Github地址:GitHub - medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary.)
第一步下载zip:

安装之后第二步:
解压,并将解压的文件拷贝到ES安装目录的plugins下的ik(重命名)目录下,重启es
随后来Kibana做个测试
POST /_analyze
{
"text":"中华人民共和国人民大会堂",
"analyzer":"ik_smart"
}
拆分的结果为:中华人民共和国、人民大会堂
这是因为ik分词器有两种分词模式
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民大会堂、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
但分词器到这里还不算完善,比如一些专有名词或网络名词,词库里面是没有的,也就只能最细粒度的拆分,配置自定义词库可以解决这个问题。
iK分词器自带了两个词典,其中的main.dic的文件为扩展词典,stopword.dic为停用词典
可以在扩展词典中加入名词,处在停用词典中的词将不会被存入分词列表
如果不想用其自带的,也可以在ik分词器的config目录下新建一个扩展名为.dic的文件(注意文件格式为utf-8(不要选择utf-8 BOM))
配置方式为:打开IKAnalyzer.cfg.xml

Field详细介绍
field的核心数据类型其实有很多,但常用的就几种,如文本,数字
1、文本和数字数据类型有以下几种
文本:text、keyword(往索引目录写不进行分词)
数字:integer、long、float、double
2、field的属性(重点)
type:数据类型,如:text、long
analyzer:往索引目录写或搜索时的分词模式,如:analyzer=ik_max_word,analyzer=ik_smart
index:是否往索引目录写,如:true、false
_source:document中是否存储,如:includes,excludestype的使用很简单
如:
"name":{
"type":"text"
}analyzer指定分词模式,这里可以指定索引时和搜索时使用哪种分词模式
"name": {
"type": "text",
"analyzer":"ik_max_word"
}上边指定了analyzer是指在索引和搜索都使用ik_max_word,如果单独想定义搜索时使用的分词器则可以通过 search_analyzer属性。
对于ik分词器建议是索引时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性。
"name": {
"type": "text",
"analyzer":"ik_max_word",#生成索引目录时
"search_analyzer":"ik_smart"#检索时
}index属性指定是否索引
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。 但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置 为false。
"pic": {
"type":"text",
"index":false
}source属性指定是否展示:
如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,比如:商品描述。查看文档内容会再次到mysql或者hbase中取数据,把大字段的内容存在Elasticsearch中只会增大索引,这一点文档数量越大结果越明显,如果一条文档节省几KB,放大到亿万级的量结果也是非常可观的。
如果只想存储某几个字段的原始值到Elasticsearch,可以通过incudes参数来设置,在mapping中的设置如下:
POST /java06/course/_mapping
{
"_source": {
"includes":["description"]
}
}同样,可以通过excludes参数排除某些字段:
POST /java06/course/_mapping
{
"_source": {
"excludes":["description"]
}
}
创建这样一个映射
POST /alex-hh/course/_mapping
{
"_source": {
"includes":["description"]
}
"properties": {
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"description": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"pic":{
"type":"text",
"index":false
}
}
}
插入文档
POST /alex-hh/course/1
{
"name":"python从入门到放弃",
"description":"人生苦短,我用Python",
"pic":"250.jpg"
}
测试查询
GET /java06/course/_search?q=name:放弃
GET /java06/course/_search?q=description:人生
GET /java06/course/_search?q=pic:250.jpg
结果:name和description都支持全文检索,pic不可作为查询条件
keyword关键字字段
上边介绍的text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段往索引目录写时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
例如:插入一个新的映射
POST /alex-hh/course/_mapping
{
"properties": {
"studymodel":{
"type":"keyword"
}
}
}
插入文档
PUT /alex-hh/course/2
{
"name": "java编程基础",
"description": "java语言是世界第一编程语言",
"pic":"250.jpg",
"studymodel": "2010年01月"
}
根据studymodel查询文档:
GET /java06/course/_search?q=studymodel:2010年01月
studymodel是keyword类型,所以查询方式是精确查询。
date日期类型
日期类型不用设置分词器,通常日期类型的字段用于排序。 1)format 通过format设置日期格式,多个格式使用双竖线||分隔, 每个格式都会被依次尝试, 直到找到匹配的
例如: 1、设置允许date字段存储年月日时分秒、年月日及毫秒三种格式。
POST /java06/course/_mapping
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}
插入文档:
PUT /alex-hh/course/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic":"250.jpg",
"timestamp":"2018-07-04 18:28:58"
}
Numeric类型
es中的数字类型经过分词(特殊)后支持排序和区间搜索
插入一个新的映射
POST /alex-hh/course/_mapping
{
"properties": {
"price": {
"type": "float"
}
}
}
插入文档PUT /alex-hh/course/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"pic":"250.jpg",
"price":38.6
}
Spring Boot整合ElasticSearch
ES客户端
ES提供多种不同的客户端:
1、TransportClient
ES提供的传统客户端,官方计划8.0版本删除此客户端。
2、RestClient
RestClient是官方推荐使用的,它包括两种:REST Low Level Client和 REST High Level Client。ES在6.0之后提供REST High Level Client, 两种客户端官方更推荐使用 REST High Level Client,不过当前它还处于完善中,有些功能还没有。
开始搭建工程:
pom.xml依赖配置
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.3.2.RELEASE
com.bjpowernode
springboot_elasticsearch
1.0-SNAPSHOT
6.2.3
org.springframework.boot
spring-boot-starter-web
org.elasticsearch.client
elasticsearch-rest-high-level-client
${elasticsearch.version}
org.springframework.boot
spring-boot-starter-test
application.yml
spring:
elasticsearch:
rest:
uris:
- http://192.168.204.132:9200
app启动类:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ElasticsearchApp {
public static void main(String[] args) {
SpringApplication.run(ElasticsearchApp.class, args);
}
}在kibana上写好es语句
PUT /spring-boot/course/_mapping
{
"settings":{
"number_of_shards" : 2,
"number_of_replicas" : 0
}
}POST /spring-boot/course/_mapping
{
"_source": {
"excludes":["description"]
},
"properties": {
"name": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"description": {
"type": "text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_smart"
},
"studymodel": {
"type": "keyword"
},
"price": {
"type": "float"
},
"pic":{
"type":"text",
"index":false
}
}
}
测试类:
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = {ElasticsearchApp.class})
public class IndexWriterTest {
@Autowired
private RestHighLevelClient restHighLevelClient;
//创建索引库
@Test
public void testCreateIndex() throws IOException {
//创建“创建索引请求”对象,并设置索引名称
CreateIndexRequest createIndexRequest = new CreateIndexRequest("spring-boot");
//设置索引参数
createIndexRequest.settings("{\n" +
" \"number_of_shards\" : 2,\n" +
" \"number_of_replicas\" : 0\n" +
" }", XContentType.JSON);
createIndexRequest.mapping("course", "{\r\n" +
" \"_source\": {\r\n" +
" \"excludes\":[\"description\"]\r\n" +
" }, \r\n" +
" \"properties\": {\r\n" +
" \"name\": {\r\n" +
" \"type\": \"text\",\r\n" +
" \"analyzer\":\"ik_max_word\",\r\n" +
" \"search_analyzer\":\"ik_smart\"\r\n" +
" },\r\n" +
" \"description\": {\r\n" +
" \"type\": \"text\",\r\n" +
" \"analyzer\":\"ik_max_word\",\r\n" +
" \"search_analyzer\":\"ik_smart\"\r\n" +
" },\r\n" +
" \"studymodel\": {\r\n" +
" \"type\": \"keyword\"\r\n" +
" },\r\n" +
" \"price\": {\r\n" +
" \"type\": \"float\"\r\n" +
" },\r\n" +
" }\r\n" +
"}", XContentType.JSON);
//创建索引操作客户端
IndicesClient indices = restHighLevelClient.indices();
//创建响应对象
CreateIndexResponse createIndexResponse =
indices.create(createIndexRequest);
//得到响应结果
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}
}再来测试删除
编辑删除语句
DELETE /spring-boot
测试类添加方法
//删除索引库
@Test
public void testDeleteIndex() throws IOException {
//创建“删除索引请求”对象
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("java06");
//创建索引操作客户端
IndicesClient indices = restHighLevelClient.indices();
//创建响应对象
DeleteIndexResponse deleteIndexResponse =
indices.delete(deleteIndexRequest);
//得到响应结果
boolean acknowledged = deleteIndexResponse.isAcknowledged();
System.out.println(acknowledged);
}测试添加文档
POST /spring-boot/course/1
{
"name":"spring cloud实战",
"description":"本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。",
"studymodel":"201001",
"price":5.6
}
测试类添加方法
//添加文档
@Test
public void testAddDocument() throws IOException {
//创建“索引请求”对象:索引当动词
IndexRequest indexRequest = new IndexRequest("spring-boot", "course", "1");
indexRequest.source("{\n" +
" \"name\":\"spring cloud实战\",\n" +
" \"description\":\"本课程主要从四个章节进行讲解: 1.微服务架构入门 " +
"2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心nacos。\",\n" +
" \"studymodel\":\"201001\",\n" +
" \"price\":5.6\n" +
"}", XContentType.JSON);
IndexResponse indexResponse =
restHighLevelClient.index(indexRequest);
System.out.println(indexResponse.toString());
}批量添加文档
支持在一次API调用中,对不同的索引进行操作。支持四种类型的操作:index、create、update、delete。
语法:
POST /_bulk
{ action: { metadata }}
{ requestbody }
{ action: { metadata }}
{ requestbody }如:
POST /_bulk
{"index":{"_index":"spring-boot","_type":"course"}}
{"name":"php实战","description":"php谁都不服","studymodel":"201001","price":"5.6"}
{"index":{"_index":"spring-boot","_type":"course"}}
{"name":"net实战","description":"net从入门到放弃","studymodel":"201001","price":"7.6"}
测试类添加方法:
@Test
public void testBulkAddDocument() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.add(new IndexRequest("spring-boot", "course").source("{"name":"php实战","description":"php谁都不服","studymodel":"201001","price":"5.6"}",
XContentType.JSON));
bulkRequest.add(new IndexRequest("spring-boot", "course").source("{"name":"net实战","description":"net从入门到放弃","studymodel":"201001","price":"7.6"}",
XContentType.JSON));
BulkResponse bulkResponse =
restHighLevelClient.bulk(bulkRequest);
System.out.println(bulkResponse.hasFailures());
}测试修改文档:
PUT /spring-boot/course/1
{
"price":66.6
}
测试类添加方法:
//更新文档
@Test
public void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("spring-boot", "course", "1");
updateRequest.doc("{\n" +
" \"price\":7.6\n" +
"}", XContentType.JSON);
UpdateResponse updateResponse =
restHighLevelClient.update(updateRequest);
System.out.println(updateResponse.getResult());
}删除文档:
DELETE /spring-boot/coures/1
测试类添加方法:
//根据id删除文档
@Test
public void testDelDocument() throws IOException {
//删除请求对象
DeleteRequest deleteRequest = new DeleteRequest("spring-boot","course","1");
//响应对象
DeleteResponse deleteResponse =
restHighLevelClient.delete(deleteRequest);
System.out.println(deleteResponse.getResult());
}文档搜索(重点重点重点!)
准备环境,向索引库中插入以下数据:
PUT /spring-boot/course/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是由Twitter推出的一个前台页面开发css框架,是一个非常流行的开发框架,此框架集成了多种页面效果。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长css页面开发的程序人员)轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price":38.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}PUT /spring-boot/course/2
{
"name": "java编程基础",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price":68.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}PUT /spring-boot/course/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price":88.6,
"pic":"group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg"
}
准备就绪,先开始简单搜索
简单搜索就是通过url进行查询,以get方式请求ES。
语法:
GET /index_name/type_name/doc_id
GET [/index_name/type_name/]_search[?parameter_name=parameter_value&...]
例如:
GET /spring-boot/course/_search?q=name:spring&sort=price:desc
注意: 如果查询条件复杂,很难构建搜索条件 ,生产环境中很少使用。 例如:要求搜索条件为商品名称包含手机,价格在 1000~5000之间,销量在每月 500 以上,根据价格升序排列,分页查询第二页,每页 40 条数据:?q=xxxx:xxx&range=xxx:xxx:xxx&aggs&sort&from&size
这里测试通过id查找
GET /spring-boot/course/1
测试类添加方法:
//查询文档
@Test
public void getDoc() throws IOException {
GetRequest getRequest = new GetRequest("spring-boot","course","1");
GetResponse getResponse = restHighLevelClient.get(getRequest);
boolean exists = getResponse.isExists();
System.out.println(exists);
String source = getResponse.getSourceAsString();
System.out.println(source);
}
DSL搜索
DSL(Domain Specific Language)是ES提出的基于json的搜索方式,在搜索时传入特定的json格式的数据来完成不同的搜索需求,DSL比URI搜索方式功能强大,在项目中建议使用DSL方式来完成搜索。
语法:
GET /index_name/type_name/_search
{
"commond":{
"parameter_name" : "parameter_value"
}
}
这里面有七种查询方式:
1.match_all查询
GET /spring-boot/course/_search
{
"query" : {
"match_all" : {}
}
}
上述查询会直接查询出所有文档数据
创建IndexReaderTest测试类
import com.bjpowernode.ElasticsearchApp;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.io.IOException;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = {ElasticsearchApp.class})
public class IndexReaderTest {
@Autowired
private RestHighLevelClient restHighLevelClient;
private SearchRequest searchRequest;
private SearchResponse searchResponse;
@Before
public void init(){
searchRequest = new SearchRequest();
searchRequest.indices("spring-boot");
searchRequest.types("course");
}
@Test
public void testMatchAll() throws IOException {
//2、创建 search请求对象
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("spring-boot");
searchRequest.types("course");
//3、创建 参数构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
//4、设置请求参数
searchRequest.source(searchSourceBuilder);
//1、调用search方法
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
SearchHits searchHits = searchResponse.getHits();
long totalHits = searchHits.getTotalHits();
System.out.println("共搜索到"+totalHits+"条文档");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
@After
public void show(){
SearchHits searchHits = searchResponse.getHits();
long totalHits = searchHits.getTotalHits();
System.out.println("共搜索到"+totalHits+"条文档");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
}
}
}在match_all的基础上可以加入分页条件,这便是第二种查询方式,分页查询:
GET /spring-boot/course/_search
{
"query" : { "match_all" : {} },
"from" : 1, # 从第几条数据开始查询,从0开始计数
"size" : 3, # 查询多少数据
"sort" : [//根据哪个字段排序
{ "price" : "asc" }
]
}
添加测试方法
//分页查询
@Test
public void testSearchPage() throws Exception {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
searchSourceBuilder.from(1);
searchSourceBuilder.size(5);
searchSourceBuilder.sort("price", SortOrder.ASC);
// 设置搜索源
searchRequest.source(searchSourceBuilder);
// 执行搜索
searchResponse = restHighLevelClient.search(searchRequest);
}第三种:match查询
match Query即全文检索,它的搜索方式是先将搜索字符串分词,再使用各各词条从索引中搜索。
其中有两个重要的属性:
query:搜索的关键字
operator:or 表示 只要有一个词在文档中出现则就符合条件,and表示每个词都在文档中出现则才符合条件。
语法如下:
GET /spring-boot/course/_search
{
"query" : {
"match" : {
"name": {
"query": "spring开发",
"operator": "and"
}
}
}
}
上边的搜索的执行过程是: 1、将“spring开发”分词,分为spring、开发两个词 2、再使用spring和开发两个词去匹配索引中搜索。 3、由于设置了operator为and,必须匹配两个词成功时才返回该文档。
添加测试方法:
@Test
public void testMatchQuery() throws Exception {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name", "spring开
发").operator(Operator.AND));
// 设置搜索源
searchRequest.source(searchSourceBuilder);
// 执行搜索
searchResponse = restHighLevelClient.search(searchRequest);
}第四种:multi_match查询
matchQuery是在一个field中去匹配,multiQuery是拿关键字去多个Field中匹配。
语法如下:
GET /spring-boot/course/_search
{
"query": {
"multi_match": {
"query": "开发",
"fields": ["name","description"]
}
}
}
注意:此搜索操作适合构建复杂查询条件,生产环境常用。
添加测试方法
@Test
public void testMultiMatchQuery() throws Exception {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("开发","name","description"));
// 设置搜索源
searchRequest.source(searchSourceBuilder);
// 执行搜索
searchResponse = restHighLevelClient.search(searchRequest);
}第五种:bool查询
布尔查询对应于Lucene的BooleanQuery查询,实现将多个查询组合起来。
它的参数有三个可选项: must:表示必须,多个查询条件必须都满足。(通常使用must)
should:表示或者,多个查询条件只要有一个满足即可。
must_not:表示非。
例如:查询name包括“开发”并且价格区间是50-100的文档
GET /spring-boot/course/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "开发"
}
},
{
"range": {
"price": {
"gte": 50,
"lte": 100
}
}
}
]
}
}
}
添加测试方法:
@Test
public void testBooleanMatch() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//json条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.matchQuery("name","开发"));
boolQueryBuilder.must(QueryBuilders.rangeQuery("price").gte("50").lte(100));
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest);
}第六种:filter查询
过滤查询。此操作实际上就是 query DSL 的补充语法。过滤的时候,不进行任何的匹配分数计算,相对于 query 来说,filter 相对效率较高。Query 要计算搜索匹配相关度分数。Query更加适合复杂的条件搜索。
如:使用bool查询,搜索 name中包含 "开发"的数据,且price在 10~100 之间 1、不使用 filter, name和price需要计算相关度分数:
GET /spring-boot/course/_search
{
"query": {
"bool" : {
"must":[
{
"match": {
"name": "开发"
}
},
{
"range": {# 范围, 字段的数据必须满足某范围才有结果。
"price": {
"gte": 10, # 比较符号 lt gt lte gte
"lte": 100
}
}
}
]
}
}
}
2、使用 filter, price不需要计算相关度分数:
GET /spring-boot/course/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "开发"
}
}
],
"filter": {# 过滤,在已有的搜索结果中进行过滤,满足条件的返回。
"range": {
"price": {
"gte": 10,
"lte": 100
}
}
}
}
}
}
添加测试方法:
@Test
public void testFilterQuery() throws IOException {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.matchQuery("name","开发"));
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gte(10).lte(100))
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
searchResponse = restHighLevelClient.search(searchRequest);
}第七种:highlight查询
高亮显示:高亮不是搜索条件,是显示逻辑,在搜索的时候,经常需要对搜索关键字实现高亮显示。
例如:
GET /spring-boot/course/_search
{
"query": {
"match": {
"name": "开发"
}
},
"highlight": {
"pre_tags": [""],
"post_tags": [""],
"fields": {"name": {}}
}
}
上述语句执行后,返回的结果中,将会把开发标识为红色
添加测试方法:
@Test
public void testHighLightQuery() throws Exception {
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("name", "spring"));
//设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("");
highlightBuilder.postTags("");
highlightBuilder.fields().add(new HighlightBuilder.Field("name"));
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
searchResponse = restHighLevelClient.search(searchRequest);
}
@After
public void displayDoc() {
SearchHits searchHits = searchResponse.getHits();
long totalHits = searchHits.getTotalHits();
System.out.println("共搜索到" + totalHits + "条文档");
SearchHit[] hits = searchHits.getHits();
for (int i = 0; i < hits.length; i++) {
SearchHit hit = hits[i];
String id = hit.getId();
System.out.println("id:" + id);
String source = hit.getSourceAsString();
System.out.println(source);
Map highlightFields = hit.getHighlightFields();
if (highlightFields != null) {
HighlightField highlightField = highlightFields.get("name");
Text[] fragments = highlightField.getFragments();
System.out.println("高亮字段:" + fragments[0].toString());
}
}
} ElasticSearch的集群管理
集群结构图:

ES通常以集群方式工作,这样做不仅能够提高 ES的搜索能力还可以处理大数据搜索的能力,同时也增加了系统的容错能力及高可用。
此处的设置为:每个主分片有两个副本, 如果某个节点挂了也不怕,比如节点1挂了,我们可以查询位于节点3和节点3上的副本0

添加文档过程:
(1)假设用户把请求发给了节点1
(2)系统通过余数算法得知这个’文档’应该属于主分片2,于是请求被转发到保存该主分片的节点3
(3)系统把文档保存在节点3的主分片2中,然后将请求转发至其他两个保存副本的节点。

查询文档过程:
(1) 请求被发给了节点1
(2)节点1计算出该数据属于主分片2,这时候,有三个选择,分别是位于节点1的副本2, 节点2的副本2,节点3的主分片2, 假设节点1负载均衡,采用轮询的方式,选中了节点2,把请求转发。
(3) 节点2把数据返回给节点1, 节点1 最后返回给客户端。
最后说一下集群的状态
节点的status:用三种颜色来展示健康状态
green:索引库的每个 primary shard 和 replica shard 都是 active 的
yellow:索引库的每个 primary shard 都是 active 的,但部分的 replica shard 不是 active 的,如单节点创建备份分配
red:不是所有的 primary shard 都是 active 状态的。