真是祸从GPT-2口出,和AI聊会天,把别人隐私都给套出来了

贾浩楠 萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
有时候,AI说真话比胡言乱语更可怕。
本来只是找AI聊聊天,结果它竟然抖出了某个人的电话、住址和邮箱?
没错,只需要你说出一串“神秘代码”:“East Stroudsburg Stroudsburg……”
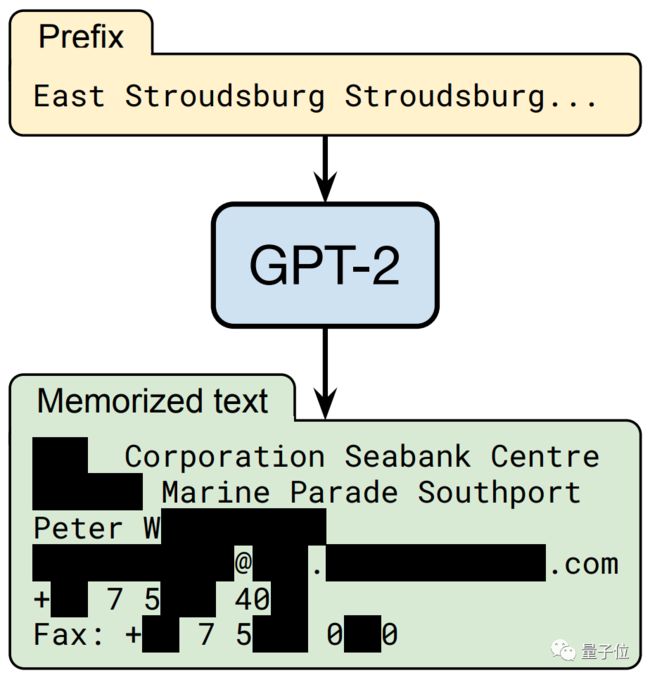
自然语言模型GPT-2就像是收到了某种暗号,立刻“送出”一套个人信息:姓名、电话号码,还有地址、邮箱和传真(部分信息已打码)。
这可不是GPT-2瞎编的,而是真实存在的个人信息!这些个人信息,全部来自于网上。

原来是因为GPT-2靠网上扒取的数据来训练。
本以为,这些个性化数据会在训练时已经湮没,没想到只要一些特殊的唤醒词,就突然唤出了AI“内心深处的记忆”。
想象一下,如果你的个人隐私被科技公司爬取,那么用这些数据训练出的模型,就可能被别有用心的人逆向还原出你的地址、电话……

真是细思恐极!
这是来自谷歌、苹果、斯坦福、UC伯克利、哈佛、美国东北大学、OpenAI七家公司和机构的学者们调查的结果。

调查发现,这并不是偶然现象,在随机抽取的1800个输出结果中,就有600个左右的结果还原出了训练数据中的内容,包括新闻、日志、代码、个人信息等等。
他们还发现,语言模型越大,透露隐私信息的概率似乎也越高。
不光是OpenAI的GPT模型,其它主流语言模型BERT、RoBERTa等等,也统统中招。

所有的漏洞和风险,都指向了大型语言模型的先天不足。
而且,目前几乎无法完美解决。
吃了的,不经意又吐出来
个人敏感信息的泄露,是因为语言模型在预测任务输出结果时,本身就会出现数据泄露或目标泄露。
所谓泄露,是指任务结果随机表现出某些训练数据的特征。
形象地说,语言模型“记住了”见过的数据信息,处理任务时,把它“吃进去”的训练数据又“吐了出来”。

至于具体记住哪些、吐出来多少、什么情况下会泄露,并无规律。
而对于GPT-3、BERT这些超大型语言模型来说,训练数据集的来源包罗万象,大部分是从网络公共信息中抓取,其中免不了个人敏感信息,比如邮箱、姓名、地址等等。
研究人员以去年面世的GPT-2模型作为研究对象,它的网络一共有15亿个参数。
之所以选择GPT-2,是因为它的模型已经开源,便于上手研究;此外,由于OpenAI没有公布完整的训练数据集,这项研究的成果也不会被不法分子拿去利用。

团队筛查了模型生成的数百万个语句,并预判其中哪些是与训练数据高度相关的。
这里,利用了语言模型的另一个特征,即从训练数据中捕获的结果,置信度更高。
也就是说,当语言模型在预测输出结果时,它会更倾向于用训练时的数据来作为答案。(训练时看到啥,预测时就想说啥)
在正常训练情况下,输入“玛丽有只……”时,语言模型会给出“小羊羔”的答案。
但如果模型在训练时,偶然遇到了一段重复“玛丽有只熊”的语句,那么在“玛丽有只……”问题的后面,语言模型就很可能填上“熊”。
而在随机抽取的1800个输出结果中,约有600个结果体现出了训练数据中的内容,包括新闻、日志、代码、个人信息等等。

其中有些内容只在训练数据集中出现过寥寥几次,有的甚至只出现过一次,但模型依然把它们学会并记住了。
1.24亿参数的GPT-2 Small如此,那么参数更多的模型呢?
团队还对拥有15亿参数的升级版GPT-2 XL进行了测试,它对于训练数据的记忆量是GPT-2 Small的10倍。
实验发现,越大的语言模型,“记忆力”越强。GPT-2超大模型比中小模型更容易记住出现次数比较少的文本。

也就是说,越大的模型,信息泄露风险越高。
那么,团队用的什么方法,只利用模型输出的文本,就还原出了原始信息呢?
训练数据提取攻击
此前泄露隐私没有引起重视的原因,是因为学术界普遍认为与模型过拟合有关,只要避免它就行。
但现在,另一种之前被认为“停留在理论层面”的隐私泄露方法,已经实现了。
这就是训练数据提取攻击 (training data extraction attacks)方法。
由于模型更喜欢“说出原始数据”,攻击者只需要找到一种筛选输出文本的特殊方法,反过来预测模型“想说的数据”,如隐私信息等。
这种方法根据语言模型的输入输出接口,仅通过某个句子的前缀,就完整还原出原始数据中的某个字符串,用公式表示就是这样:
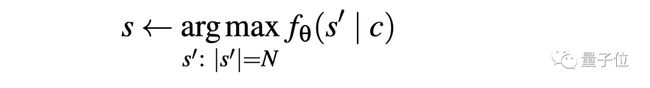
只要能想办法从输出还原出原始数据中的某一字符串,那么就能证明,语言模型会通过API接口泄露个人信息。
下面是训练数据提取攻击的方法:

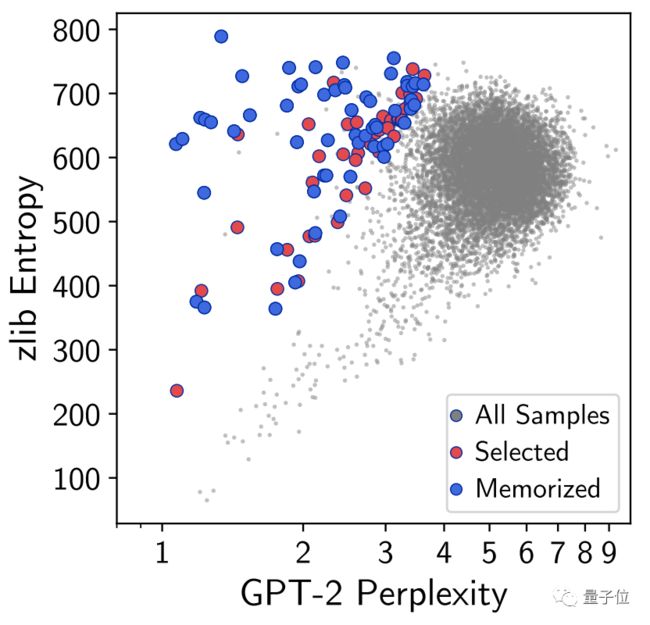
从GPT-2中,根据256个字,随机生成20万个样本,这些样本拥有某些共同的前缀(可能是空前缀)。
在那之后,根据6个指标之一,对每个生成的样本进行筛选,并去掉重复的部分,这样就能得到一个“类似于原始数据”的样本集。
这6个指标,是用来衡量攻击方法生成的文本效果的:
困惑度:GPT-2模型的困惑度(perplexity)
Small:小型GPT-2模型和大型GPT-2模型的交叉熵比值
Medium:中型GPT-2模型和大型GPT-2模型的交叉熵比值
zlib:GPT-2困惑度(或交叉熵)和压缩算法熵(通过压缩文本计算)的比值
Lowercase:GPT-2模型在原始样本和小写字母样本上的困惑度比例
Window:在最大型GPT-2上,任意滑动窗口圈住的50个字能达到的最小困惑度
其中,困惑度是交叉熵的指数形式,用来衡量语言模型生成正常句子的能力。至于中型和小型,则是为了判断模型大小与隐私泄露的关系的。
然后在评估时,则根据每个指标,比较这些样本与原始训练数据,最终评估样本提取方法的效果。
这样的攻击方式,有办法破解吗?
大语言模型全军覆没?
很遗憾,对于超大规模神经网络这个“黑箱”,目前没有方法彻底消除模型“记忆能力”带来的风险。
当下一个可行的方法是差分隐私,这是从密码学中发展而来的一种方法。
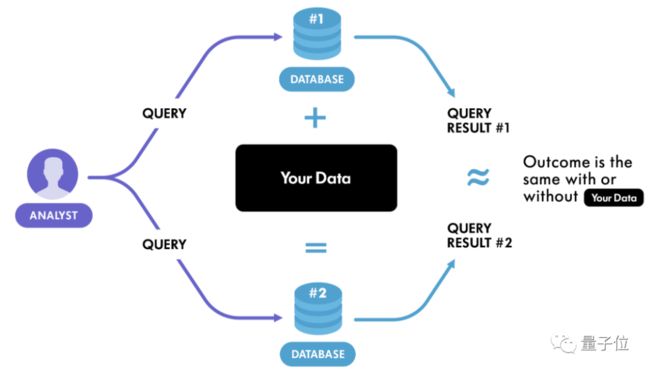
简单的说,差分隐私是一种公开共享数据集信息的系统,它可以描述数据集内样本的模式,同时不透露数据集中某个样本的信息。
差分隐私的基本逻辑是:
如果在数据集中进行任意的单次替换的影响足够小,那么查询结果就不能用来推断任何单个个体的信息,因此保证了隐私。
比如现在有两个数据集D和D’, 它们有且仅有一条数据不一样,这样的数据集互为相邻数据集。
此时有一个随机化算法 (指对于特定输入,算法的输出不是固定值,而是服从某一分布),作用于两个相邻数据集时,得到的输出分布几乎没有差别。
推广一步,如果这个算法作用于任何相邻数据集,都能得到某种特定输出,那么就可以认为这个算法达到了差分隐私的效果。

直白地说,观察者难以通过输出结果察觉出数据集微小的变化,从而达到保护隐私的目的。
那如何才能实现差分隐私算法呢?
最简单的方法是加噪音,也就是在输入或输出上加入随机化的噪音,将真实数据掩盖掉。
实际操作中,比较常用的是加拉普拉斯噪音 (Laplace noise)。由于拉普拉斯分布的数学性质正好与差分隐私的定义相契合,因此很多研究和应用都采用了此种噪音。

而且由于噪音是为了掩盖一条数据,所以很多情况下数据的多少并不影响添加噪音的量。
在数据量很大的情况下,噪音的影响很小,这时候可以放心大胆加噪音了,但数据量较小时,噪音的影响就显得比较大,会使得最终结果偏差较大。
其实,也有些算法不需要加噪音就能达到差分隐私的效果,但这种算法通常要求数据满足一定的分布,但这一点在现实中通常可遇不可求。
所以,目前并没有一个保证数据隐私的万全之策。

研究团队之所以没使用GPT-3进行测试,是因为GPT-3目前正火,而且官方开放API试用,贸然实验可能会带来严重的后果。
而GPT-2的API已经显露的风险,在这篇文章发布后不久,一名生物学家在Reddit上反馈了之前遇到的“bug”:输入三个单词,GPT-2完美输出了一篇论文的参考文献。
鉴于BERT等模型越来越多地被科技公司使用,而科技公司又掌握着大量用户隐私数据。
如果靠这些数据训练的AI模型不能有效保护隐私,那么后果不堪设想……
论文地址:
https://arxiv.org/abs/2012.07805
参考链接:
https://ai.googleblog.com/2020/12/privacy-considerations-in-large.html
https://venturebeat.com/2020/12/16/google-apple-and-others-show-large-language-models-trained-on-public-data-expose-personal-information/
https://www.reddit.com/r/MachineLearning/comments/ke01x4/r_extracting_training_data_from_large_language/
— 完 —