flink离线mysql_Flink 流模式跑离线任务
通常的认识是:Flink 流模式跑流任务,批模式跑批任务,用流模式跑离线任务也是个有意思的事情
虽然新版 Flink 已经在 sql 上实现了一定程度的流批一体,但是 DataStream 和 DataSet API 还是相差比较大的
用 Flink 跑离线任务也是机缘巧合(也是必然,毕竟我不会 Spark)
现在的项目组经常会跑历史数据,当然是批模式的,在用 Flink batch 被遇到各种各样的问题困扰之后
深入思考了我们需要跑的历史任务的特性,将流模式的的概念稍微变通一下,也可以达到离线的效果
这一切都有一个前提: Flink 任务的算子,在处理完全部数据后,就自动退出了,基于这个前提,就可以达到离线任务的效果
比如,看下面的 Mysql Source
class MysqlSourceFunction(sql: String) extendsRichSourceFunction[String] {private val logger = LoggerFactory.getLogger("MysqlSourceFunction")private var connection: java.sql.Connection =_private var queryPS: PreparedStatement = null
private var count: Long = 0override def open(parameters: Configuration): Unit={
connection=DriverManager.getConnection(Common.MYSQL_URL, Common.MYSQL_USER, Common.MYSQL_PASS)
queryPS=connection.prepareStatement(sql)
}
override def run(ctx: SourceFunction.SourceContext[String]): Unit={
logger.info("star query userId")//execute sql
val resultSet =queryPS.executeQuery()while(resultSet.next()) {
count+= 1val userId= resultSet.getString(1)
ctx.collect(userId)
}
queryPS.close()
connection.close()
logger.info("query userId finish, load {} item, source exit", count)
}
override def cancel(): Unit={
}
}
任务启动后会从 source 开始执行,MysqlSourceFunction 就是 MySQL 查询数据,
并将查询出来的数据用流的形式,调用 ctx.collect(userId) 一条一条的发送到下游算子,
在处理完数据后,MysqlSourceFunction 的 run 方法执行完成,Flink 会自动将 Source 标记为 “FINISH”
后续的算子也是一样,虽然是流模式的任务,Source 完成后,后续的算子也会依次完成,
跟批模式的区别是,所以算子都是同步执行的,Source 还在继续生产数据,Sink 也在同步的输出之前的数据,
而批的任务必须要上一算子完成,才会开始执行下一个算子。
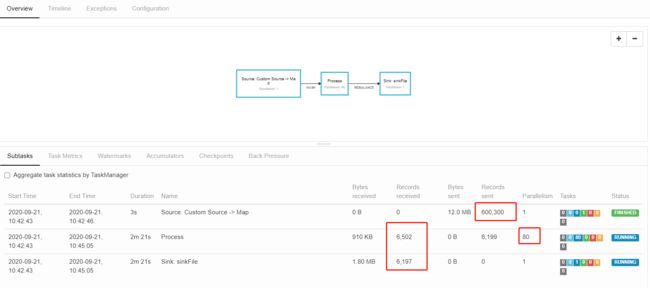
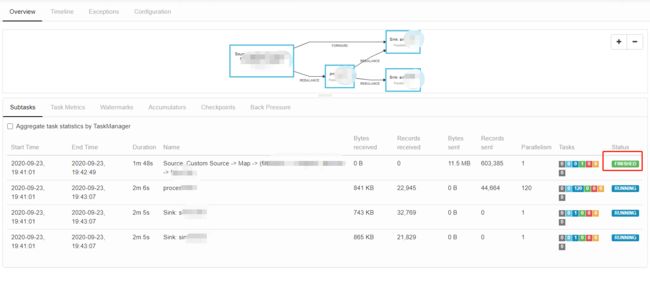
基于这样的前提,开始设计我的跑批任务的流程序。
简单介绍下离线任务要做的东西: 我们主要做的事情是对用户进行实时的检测,并输出一下我们任务有异常的行为数据,判断异常需要对该用户的历史行为进行分析,离线任务就是对用户的历史行为分析的程序。
真正做的事情就是,基于每个用户,从存储引擎中拿出该用户一定时间范围的历史数据,对历史数据统计、分类等处理后,输出处理的结果,用于实时检测程序,Sink 完成后,会自动释放资源,提交对应的输出句柄(比如写 HDFS 会提交文件)。
可以使用流模式来跑这样的离线任务的前提是,离线程序是基于每个用户的历史行为的统计,而不是像 BI 报表分析一样,将所有用户的数据聚合起来再分析。
到这来就简单了,所有这样的离线任务都分成三部分,Source -> Process -> Sink
Source 中根据不同的需求,生产不同的数据
Process 中根据收到的不同的 userId,从存储引擎中拖出所有该用户的数据,所有统计、分类逻辑都在这部分完成
Sink 只负责结果的输出
目前我处理离线数据除了需要用机器学习库的任务,都全部用 Flink 实现,并且性能和资源消耗会比用 Spark 还小(在我不懈的努力(推荐下) 我们组已经有其他人开始尝试用 Flink 这种方式跑离线任务了)
分区策略选择
用这种弄方式跑离线任务和真正的流任务在分区策略的选择上会有所不同,通常在流模式的任务中,在最主要的处理算子都会用keyBy 算子,让下游的算子可以使用 Flink 的 Key State,
而由于流任务并不想批任务一样资源使用达到配置的全部,分区数据倾斜的问题,并不一定会暴露(通常给流任务的资源会大于任务高峰时期的资源,以应对某些情况)。
而在这种流式的离线任务中,数据倾斜的问题就会比较明显的感知到对任务的影响,其中最明显的影响就是导致任务实际需要的时间,大于计算的理论时间。
即使使用 rebalance 这种均衡的分区策略,也会在离线任务数据处理的时间不一致上,影响任务完成的时间。
部分并发完成全部数据标记完成,其他算子还未完成,导致实际完成时间,大于任务启动时,根据数据处理速度计算的大致任务耗时
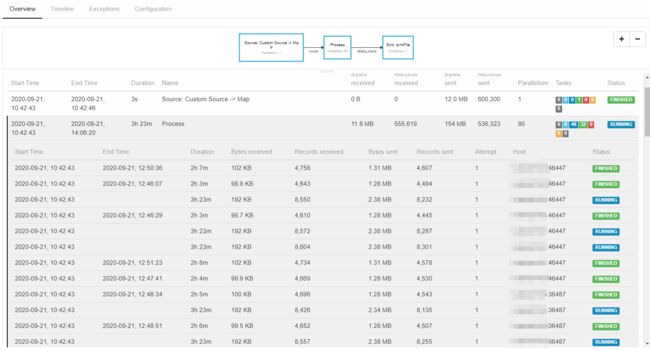
下面图可以看出,数据倾斜导致任务执行时间超过预期的情况,数据少的并发,2小时多点就已经完成了,数据多的现象,跑了 3 个半小时,还没有结束
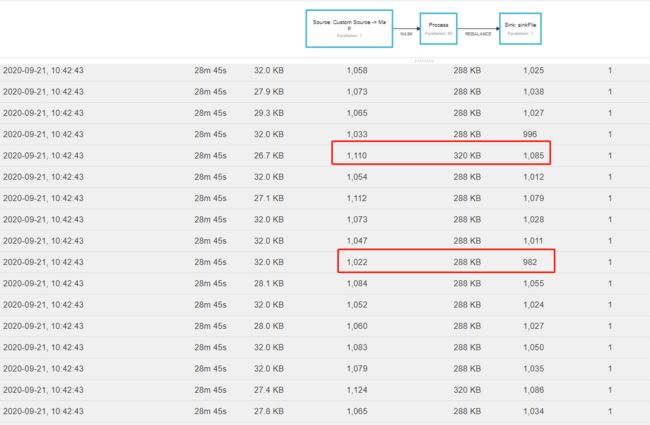
即使在数据均衡的情况下,也会有上面的情况,只是没有这么极端,如下图
甚至集群的负载也会对任务有比较大的影响,之前一次集群某些集群负载很高的时候(服务器的 CPU 达到 90%),会出现,负载高的机器上的任务会比负载低的机器出了慢很多
这些都是影响任务完成时间的因素,当然这些也是影响真正流任务的因素,不过因为流任务高峰时间有限(而且也有削峰的策略),所以影响不太严重。
在流模式的离线任务中由于一直处于最高负载(source 数据生产速度达到最高,很短时间就生产全部数据),所以影响很大。
注: Flink 还不能根据下游算子的处理速度动态的调整上游的数据分区策略
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
