深入理解Flink滑动窗口机制与延迟数据处理策略
一、Flink窗口概述
流式计算是一种用于处理无界数据流的数据处理引擎,而无界数据流是指一种不断增长的本质上无限的数据集,而窗口是将无界数据流切割成有界数据流的一种手段,Window就是其中的核心。
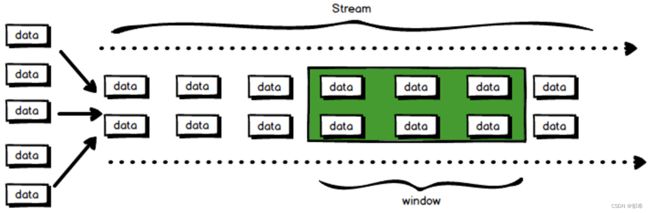
二、窗口类型
Window主要可以分为TimeWindow(按照时间生成窗口)和CountWindow(按照指定的数据量生成窗口)两种,这里分析的窗口类型主要以TimeWindow为主。
-
滚动窗口(Tumbling Window):
滚动窗口依据固定的窗口长度对数据进行切片,将每个元素分配到一个指定大小的窗口中,滚动窗口大小是固定的且窗口中的数据不会出现重叠,适合做每个时间段的聚合统计(滚动窗口是滑动窗口的一种特殊情况)
代码实现:
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window = map.keyBy(t -> t.f0).window(
// 第一个参数表示窗口长度,第二个参数表示时区的偏移量
TumblingProcessingTimeWindows.of(Time.seconds(3), Time.seconds(1))
);
-
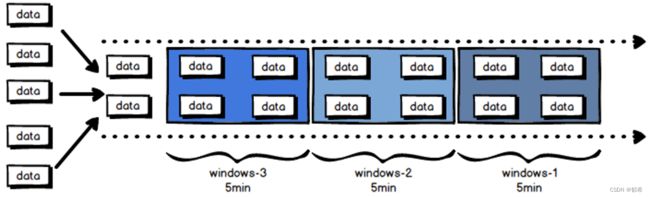
滑动窗口(Sliding Window):
滑动窗口由固定的窗口长度和滑动间隔组成,将数据分配到固定长度的窗口中,窗口的大小可以通过参数来配置,另一个参数控制滑动窗口开始的频率。因此,若滑动参数小于窗口大小时窗口会发生重叠,在这种情况下会存在重复数据。

代码实现:
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window = map.keyBy(t -> t.f0).window(
// 第一个参数表示窗口长度,第二个参数表示窗口的滑动频率
SlidingProcessingTimeWindows.of(Time.seconds(3), Time.seconds(1))
);
-
会话窗口(Session Window):
会话窗口由一系列事件组合一个指定时间长度的间隙组成,即一段时间没有接收到新数据就会生成新的窗口,此时之前的窗口的数据会进行计算。

代码实现:
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window = map.keyBy(t -> t.f0)
// 设置一个时间间隔,超过这个时间间隔就会产生一个新的窗口,而旧的窗口会执行计算
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)));
三、延迟数据处理策略
-
时间语义:
窗口的作用是为了周期性获取数据,所以需要将原始数据流切分成多个窗口,由于网络抖动和数据传输的不稳定性,可能会导致数据迟到、乱序等延迟数据的问题,为了解决这个问题Flink引入了时间相关的概念:
① EventTime:事件时间即数据产生的时间,一般存储在数据内容之中(Flink1.12版本之后数据默认的时间语义)
② Ingestion Time:即数据进入Flink的时间
③ Processing Time:即数据处理的当前时间,与机器相关(Flink1.12版本之前数据默认的时间语义)

代码实现:(已过时不推荐使用)
StreamExecutionEnvironment.getExecutionEnvironment().setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
-
Watermark:
Watermark是Flink中一种特殊的标记数据,当采集到Flink中的数据是乱序的,就意味着触发窗口计算时数据可能是不完整的,所以需要在数据采集队列中增加标记,表示指定时间的窗口数据全部到达,这里的标记就称之为Watermark(水位标记),Watermark记录的时间点必须单调递增。

源码解析:
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(WatermarkStrategy<T> watermarkStrategy) {
final WatermarkStrategy<T> cleanedStrategy = clean(watermarkStrategy);
// match parallelism to input, to have a 1:1 source -> timestamps/watermarks relationship
final int inputParallelism = getTransformation().getParallelism();
final TimestampsAndWatermarksTransformation<T> transformation = new TimestampsAndWatermarksTransformation<>(
"Timestamps/Watermarks",
inputParallelism,
getTransformation(),
cleanedStrategy);
getExecutionEnvironment().addOperator(transformation);
return new SingleOutputStreamOperator<>(getExecutionEnvironment(), transformation);
}
所谓水位标记数据其实就是为了延长窗口接收数据的终止时间,一旦水位标记进入到窗口范围内,那么窗口就会判断是否终止接收数据。(水位标记时间 ≧ 窗口接收数据终止时间)
⚠️ 水位标记和窗口的关系:所谓的水位标记其实就是预计延迟时间,一般以秒为单位,基本的原则就是认为水位标记数据之前的数据都是有效数据,即使数据延迟到达。
-
乱序数据:
Flink窗口接收到的数据顺序与数据产生时的顺序不一致,称之为乱序数据,可以在从数据中抽取事件时间时指定一个水位标记数据来解决。

源码解析:
static <T> WatermarkStrategy<T> forBoundedOutOfOrderness(Duration maxOutOfOrderness) {
return (ctx) -> new BoundedOutOfOrdernessWatermarks<>(maxOutOfOrderness);
}
-
延迟数据:
数据来到的时间晚于窗口接收数据的终止时间,称之为延迟数据(迟到数据),如果延迟数据来到时窗口已经触发计算,那么窗口不再接收新的数据,此时的数据就会丢失,我们可以在水位标记数据的基础上再次设置一个延迟数据的等待时间来解决这个问题。

源码解析:
@PublicEvolving
public WindowedStream<T, K, W> allowedLateness(Time lateness) {
builder.allowedLateness(lateness);
return this;
}
-
数据丢失:
如果数据由于各方面的因素,在设置的延迟数据等待时间结束时仍未到达,那么数据还是会面临丢失的风险,为了彻底解决这个问题,我们可以采用特殊的侧输出流。
源码解析:
@PublicEvolving
public WindowedStream<T, K, W> sideOutputLateData(OutputTag<T> outputTag) {
outputTag = input.getExecutionEnvironment().clean(outputTag);
builder.sideOutputLateData(outputTag);
return this;
}
四、案例:数据延时处理策略
-
水位传感器对象:
@Data
@ToString
@NoArgsConstructor
@AllArgsConstructor
@Accessors(chain = true)
public class WaterSensor {
private String id; // 编号
private Long ts; // 时间戳
private Integer vc; // 空高
}
-
案例代码:
public class FlinkWindowWatermark {
@SneakyThrows
public static void main(String[] args) {
// 流式数据处理环境
StreamExecutionEnvironment stream = StreamExecutionEnvironment.getExecutionEnvironment();
stream.setParallelism(1);
// 将网络数据流作为数据源
final DataStreamSource<String> socketStream = stream.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<WaterSensor> waterSensor = socketStream.map(line -> {
String[] datas = line.split(" ");
return new WaterSensor().setId(datas[0]).setTs(Long.parseLong(datas[1])).setVc(Integer.parseInt(datas[2]));
});
// 提前定义侧输出流,确保数据不丢失
OutputTag<WaterSensor> lateData = new OutputTag<WaterSensor>("LateData") { };
final SingleOutputStreamOperator<String> process = waterSensor.assignTimestampsAndWatermarks(WatermarkStrategy
// 指定水位标记
.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2))
// 从数据中抽取事件时间
.withTimestampAssigner((record, ts) -> record.getTs() * 1000L)
)
.keyBy(ws -> ws.getId())
// 窗口时间的划分:[0s~5s), [5s~10s), [10s~15s)...
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 解决延迟数据问题
.allowedLateness(Time.seconds(3))
// 侧输出流解决数据丢失
.sideOutputLateData(lateData)
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
@Override
public void process(String value, Context context, Iterable<WaterSensor> iterable, Collector<String> out) {
StringBuilder builder = new StringBuilder();
builder.append("时间窗口范围:{").append(context.window().getStart()).append("-").append(context.window().getEnd()).append("}\n");
for (WaterSensor sensor : iterable) {
builder.append(sensor).append("\n");
}
out.collect(builder.toString());
}
});
// 获取主流中的数据
process.print("Main:");
// 获取侧输出流中的数据
process.getSideOutput(lateData).print("Late:");
// 调用执行方法,否则流处理逻辑不会执行
stream.execute();
}
}
五、测试与分析
程序执行与分析结果如下图所示: