Flink-cdc写入hudi并使用hive和spark-sql查询(基于flink1.13.5和hudi0.10.0,flink-cdc2.1.1)
一、环境准备
flink1.13.5
flink-cdc 2.1.1
hudi-0.10.0
spark-3.1.2、hadoop-2.6.5、hive-1.1.0(cdh5.16版本)
jar包:
hudi-spark3-bundle_2.12-0.10.0.jar
hudi-flink-bundle_2.11-0.10.0.jar
flink-sql-connector-mysql-cdc-2.1.1.jar
二、flink-cdc写入hudi
1、mysql建表语句
create table users
(
id bigint auto_increment primary key,
name varchar(20) null,
birthday timestamp default CURRENT_TIMESTAMP not null,
ts timestamp default CURRENT_TIMESTAMP not null
);可以通过代码造数据到MySQL
造数程序如下
/**
* @author yt
* @Title:
* @Package
* @Description:
* @date 2021/12/26 11:49
*/
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Random;
public class RandomData {
private String url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&relaxAutoCommit=true&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true";
private String user = "root";
private String password = "123456";
public void Test(){
Connection conn = null;
PreparedStatement pstm = null;
ResultSet rt = null;
try{
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(url,user,password);
String sql = "INSERT INTO users(name) VALUES(?)";
pstm = conn.prepareStatement(sql);
conn.setAutoCommit(false);
Long startTime = System.currentTimeMillis();
for (int n = 1;n <= 1000;n++){
Random rand = new Random();
for (int i = 1;i <=100;i++){
int upCase = rand.nextInt(26)+65;//得到65-90的随机数
int downCase = rand.nextInt(26)+97;//得到97-122的随机数
String up = String .valueOf((char)upCase);//得到A-Z
String down = String .valueOf((char)downCase);//得到a-z
pstm.setString(1,getRandomChar() + up+down);
pstm.addBatch();
}
pstm.executeBatch();
conn.commit();
Thread.sleep(3000);
System.out.println("已经存入"+n*100+"条");
}
Long endTime = System.currentTimeMillis();
System.out.println("用时"+(endTime-startTime));
} catch(Exception e){
e.printStackTrace();
throw new RuntimeException(e);
} finally{
if(pstm != null){
try{
pstm.close();
} catch(SQLException e){
e.printStackTrace();
throw new RuntimeException(e);
}
}
if(conn != null){
try{conn.close();
} catch(SQLException e){
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
}
public static void main(String[] args) {
RandomData u = new RandomData();
u.Test();
}
public static char getRandomChar() {
return (char) (0x4e00 + (int) (Math.random() * (0x9fa5 - 0x4e00 + 1)));
}
}2、启动flink-sql客户端
我们采用集群方式提交任务
1.首先复制hudi-flink-bundle_2.11-0.10.0.jar和flink-sql-connector-mysql-cdc-2.1.1.jar到flink的lib目录下
2.进入flink目录执行
./bin/yarn-session.sh -s 4 -nm cool -d提交一个flink yarn-session任务到yarn

3.启动flink-sql客户端
启动flinksql客户端连接刚才提交的flink任务上
./bin/sql-client.sh embedded -s yarn-session
3、创建 mysql-cdc
在flinksql客户端命令行窗口首先设置checkpoint周期(如果没有设置则不会生成hudi文件)
set execution.checkpointing.interval=300000;设置5分钟,可以更短,按照自己需求
##创建source表从MySQL读取cdc数据
CREATE TABLE mysql_users (
id BIGINT PRIMARY KEY NOT ENFORCED ,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'server-time-zone' = 'Asia/Shanghai',
'database-name' = 'test',
'table-name' = 'users'
);4、创建hudi表
CREATE TABLE hudi_users2
(
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
`partition` VARCHAR(20)
) PARTITIONED BY (`partition`) WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'path' = 'hdfs://beh/hudi/hudi_users2',
'read.streaming.enabled' = 'true',
'read.streaming.check-interval' = '1'
);5、mysql-cdc 写入hudi
INSERT INTO hudi_users2 SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') FROM mysql_users;会提交有一个flink任务

flink任务提交成功后,可以查看任务界面
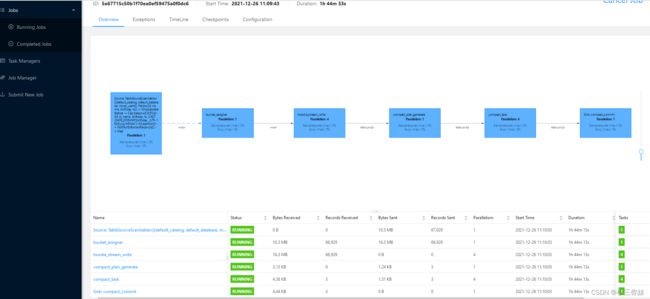
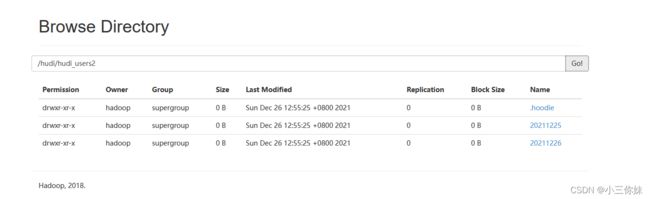
同时可以查看hdfs界面里面hudi数据路径,当然这里要等flink 5次checkpoint之后才能查看到这些目录,一开始只有.hoodie一个文件夹
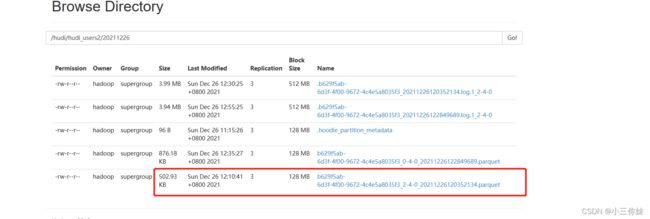
在mysql执行insert、update、detelet等操作,等hudi里面的文件compact成parquet文件后就可以用hive/spark-sql/presto(本文只做了hive和spark-sql的测试)来查询啦,这里有个点要提下:如过没有生成parquet文件,我们建的parquet表是查询不出数据的;
一段时间后查看目录产生了parquet文件
三、hive查询hudi的数据
1、cd $HIVE_HOME
2、mkdir auxlib
3、将hudi-hadoop-mr-bundle-0.10.0.jar拷贝过来

4、输入hive进入hive命令行
1、创建外部表
方式一:INPUTFORMAT是org.apache.hudi.hadoop.HoodieParquetInputFormat 这种方式只会查询出来parquet数据文件中的内容,但是刚刚更新或者删除的数据不能查出来
CREATE EXTERNAL TABLE `hudi_users_2`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://beh/hudi/hudi_users2'; 方式二:INPUTFORMAT是org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat // 这种方式是能够实时读出来写入的数据,也就是Merge On Write,会将基于Parquet的基础列式文件、和基于行的Avro日志文件合并在一起呈现给用户。
CREATE EXTERNAL TABLE `hudi_users_2_mor`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://beh/hudi/hudi_users2'; 2、 添加分区
// 添加分区
alter table hudi_users_2 add if not exists partition(`partition`='20211226') location 'hdfs://beh/hudi/hudi_users2/20211226';
alter table hudi_users_2_mor add if not exists partition(`partition`='20211226') location 'hdfs://beh/hudi/hudi_users2/20211226';3、查询数据
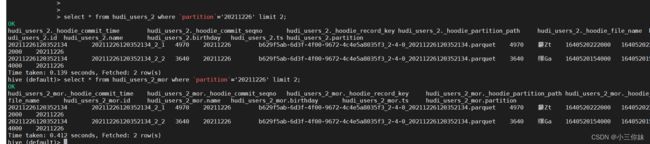
// 查询分区的数据
select * from hudi_users_2 where `partition`='20211226' limit 2;
select * from hudi_users_2_mor where `partition`='20211226' limit 2;因为是简单查询不会提交任务到yarn所以不用分发hudi-hadoop-mr-bundle-0.10.0.jar到每个节点
四、spark-sql查看分析hudi的表
将hudi-spark3-bundle_2.12-0.10.0.jar拷贝到$SPAKR_HOME/jars,每个节点都拷贝一份
本次演示使用spark3.1.2 使用本地模式,所以只需要将hudi-spark3-bundle_2.12-0.10.0.jar放在当前spark的jars目录即可(集群模式则则需要每个节点都有或者是spark配置了spark.yarn.jars 则保证hdfs对应目录存在即可)
进入spark目录
执行spark-sql(配置了环境变量)

执行SQL
select * from hudi_users_2 where `partition`='20211226' and id='2576' limit 2;select * from hudi_users_2 where `partition`='20211226' and id='2567' limit 2;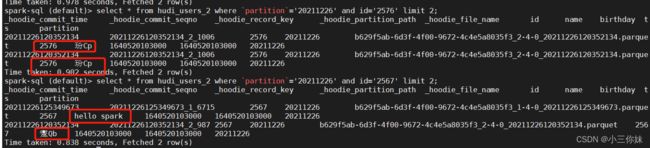
你会发现同一条数据出现两次(id是唯一的)
其中第二次查询是mysql更新后的数据了;
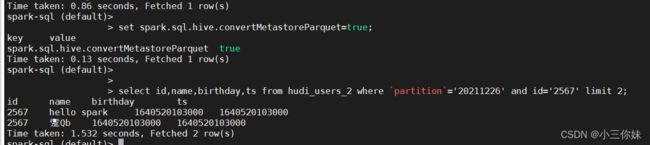
spark-sql想读到实时的hudi数据,必须 set spark.sql.hive.convertMetastoreParquet=false;
更改配置(spark-default.conf文件)重新进入spark-sql命令行查询

此时查询显示正确。
设置回默认查询结果错误。对比可以看到
五、参考
flink-cdc写入hudi,使用hive或者spark-sql统计分析hudi的数据_大黄_sama-CSDN博客_flink写入hudi