淘宝:OceanBase分布式系统负载均衡案例分享
Heroku因“随机调度+Rails单线程处理导致延迟增加的负载均衡失败”的案例之后,我们在思考:在负载均衡测试时发现问题并妥善解决的成功经验有没有?于是,挖掘出“淘宝在双十一压测OB时发现存在严重的随机访问导致负载不均问题,并通过加权算法妥善解决”的成功案例,也就是本文。
 编者按:
编者按:
在CSDN云计算频道日前所做的文章《响应高达6秒 用户揭露Heroku私自修改路由造成高支出》中,网友们认为这是“因随机调度+Rails的单线程处理导致延迟增加的负载均衡失败的案例”。但在负载均衡测试时就能发现问题并妥善解决的成功经验有没有?在随后的微博中,支付宝的@Leverly评论:“去年双11前的压测OB就发现了存在严重的随机访问导致负载不均问题,还好通过加权算法很好的解决了。” 引发了我们的关注,于是有了本文。重点是淘宝在“双十一”背后,OceanBase分布式系统负载均衡的经验分享。
以下为正文:
云计算所具备的低成本、高性能、高可用性、高可扩展性等特点与互联网应用日益面临的挑战不谋而合,成为近年来互联网领域的热门话题。作为一名技术人员不难理解在云计算的底层架构中,分布式存储是不可或缺的重要组成部分。国外知名的互联网公司如Google、Amazon、Facebook、Microsoft、Yahoo等都推出了各自的分布式存储系统,在国内OceanBase是淘宝自主研发的一个支持海量数据的高性能分布式数据库系统,实现了数千亿条记录、数百TB数据上的跨行跨表事务[1]。
在分布式系统中存在着著名的“短板理论”[2],一个集群如果出现了负载不均衡问题,那么负载最大的机器往往将成为影响系统整体表现的瓶颈和短板。为了避免这种情况的发生,需要动态负载均衡机制,以达到实时的最大化资源利用率,从而提升系统整体的吞吐。
本文将结合OceanBase的实际应用和大家分享一个去年淘宝双十一前期的准备工作中遇到负载均衡相关案例,抛砖引玉,期望对大家的工作有所启发。
OceanBase架构介绍
OceanBase是一个具有自治功能的分布式存储系统,由中心节点RootServer、静态数据节点ChunkServer、动态数据节点UpdateServer以及数据合并节点MergeServer四个Server构成[1],如图1所示。
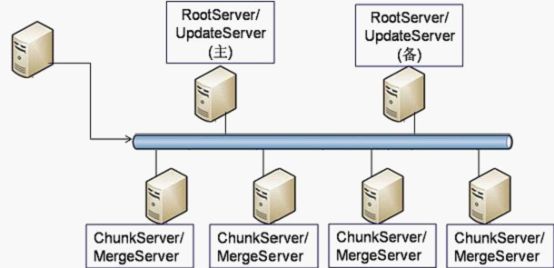
图1 OceanBase 架构图
- Tablet:分片数据,最基本的存储单元,一般会存储多份,一个Table由多个tablet构成;
- RootServer:负责集群机器的管理、Tablet定位、数据负载均衡、Schema等元数据管理等。
- UpdateServer:负责存储动态更新数据,存储介质为内存和SSD,对外提供写服务;
- ChunkServer:负责存储静态Tablet数据,存储介质为普通磁盘或者SSD。
- MergeServer:负责对查询中涉及多个Tablet数据进行合并,对外提供读服务;
在一个集群中,Tablet的多个副本分别存储在不同的ChunkServer,每个ChunkServer负责一部分Tablet分片数据,MergeServer和ChunkServer一般会一起部署。
双十一前期准备
对于淘宝的大部分应用而言,“双十一”就是一年一度的一次线上压测。伴随流量不断刷新着历史新高,对每个系统的可扩展性提出了很大的挑战。为了迎战双十一各产品线对有可能成为瓶颈部分的流量进行预估和扩容成为刻不容缓的任务。在本文要分享的案例中,应用方根据历史数据预估读请求的访问峰值为7w QPS,约为平时的5-6倍,合计每天支持56亿次的读请求。当时OceanBase集群部署规模是36台服务器,存储总数据量为200亿行记录,每天支持24亿次的读请求。
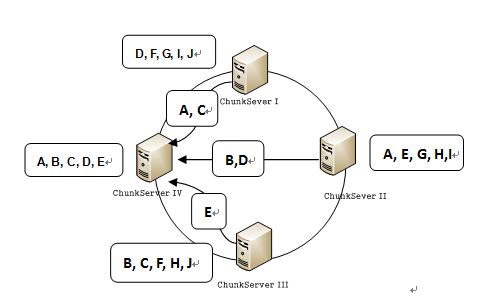
当前集群的读取性能远不能满足需求,我们首先进行了一次扩容,上线了10台Chunkserver/Mergeserver服务器。由于OceanBase本身具有比较强的可扩展性,为集群加机器是一件非常简单的操作。中心节点Rootserver在新机器注册上线后,会启动Rebalance功能以Tablet为单位对静态数据进行数据迁移,见下图的示意,最终达到所有ChunkServer上数据分片的均衡分布。

表 1. 某Table的Tablet列表
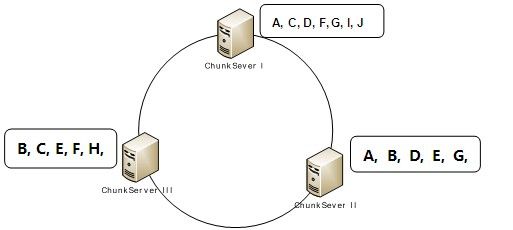
图2.1 Tablet在三台ChunkServer上的分布

图2.2加入一台机器Tablet迁移后的分布
扩容完成后引入线上流量回放机制进行压力测试,以验证当前集群的性能是否可以满足应用的双十一需求。我们使用了10台服务器,共2000-4000个线程并发回放线上读流量对集群进行压测,很快发现集群整体的QPS在达到4万左右后,压测客户端出现大量超时现象,平均响应延迟已经超过阈值100ms,即使不断调整压力,系统的整体QPS也没有任何增大。此时观察整个集群机器的负载状态发现只有极个别服务器的负载超高,是其他机器的4倍左右,其他机器基本处于空闲状态,CPU、网络、磁盘IO都凸现了严重的不均衡问题。
负载不均衡导致了整体的吞吐取决于负载最高的那台Server,这正是前文提到的典型 “短板理论”问题。
负载不均问题跟踪
客户端连接到OceanBase之后一次读请求的读流程如下图所示:

图3 客户端到OceanBase的读流程图
- Client 从RootServer获取到MergeServer 列表;
- Client将请求发送到某一台MergeServer;
- MergeServer从RootServer获取请求对应的ChunkServer位置信息;
- MergeServer将请求按照Tablet拆分成多个子请求发送到对应的ChunkServer;
- ChunkServer向UpdateServer请求最新的动态数据,与静态数据进行合并;
- MergeServer合并所有子请求的数据,返回给Client;
OceanBase的读请求流程看起来如此复杂,实际上第1步和第3步中Client与RootServer以及MergeServer与RootServer的两次交互会利用缓存机制来避免,即提高了效率,同时也极大降低了RootServer的负载。
分析以上的流程可知,在第2步客户端选择MergeServer时如果调度不均衡会导致某台MergeServer机器过载;在第4步MergeServer把子请求发送到数据所在的ChunkServer时,由于每个tablet会有多个副本,选择副本的策略如果不均衡也会造成ChunkServer机器过载。由于集群部署会在同一台机器会同时启动ChunkServer和MergeServer,无法简单区分过载的模块。通过查看OceanBase内部各模块的提供的监控信息比如QPS、Cache命中率、磁盘IO数量等,发现负载不均问题是由第二个调度问题引发,即MergeServer对ChunkServer的访问出现了不均衡导致了部分ChunkServer的过载。
ChunkServer是存储静态Tablet分片数据的节点,分析其负载不均的原因包含如下可能:
- 数据不均衡: ChunkServer上数据大小的分布是不均衡的,比如某些节点因为存储Tablet分片数据量多少的差异性而造成的不均衡;
- 流量不均衡:数据即使是基本均衡的情况下,仍然会因为某些节点存在数据热点等原因而造成流量是不均衡的。
通过对RootServer管理的所有tablet数据分片所在位置信息Metadata进行统计,我们发现各个ChunkServer上的tablet数据量差异不大,这同时也说明扩容加入新的Server之后,集群的Rebalance是有效的(后来我们在其他应用的集群也发现了存在数据不均衡问题,本文暂不解释)。
尽管排除了数据不均衡问题,流量不均衡又存在如下的几种可能性:
- 存在访问热点:比如热销的商品,这些热点数据会导致ChunkServer成为访问热点,造成了负载不均;
- 请求差异性较大:系统负载和处理请求所耗费的CPU\Memory\磁盘IO资源成正比,而资源的耗费一般又和处理的数据量是成正比的,即可能是因为存在某些大用户而导致没有数据访问热点的情况下,负载仍然是不均衡的。
经过如上的分析至少已经确定ChunkServer流量不均衡问题和步骤4紧密相关的,而目前所采用的tablet副本选择的策略是随机法。一般而言随机化的负载均衡策略简单、高效、无状态,结合业务场景的特点进行分析,热点数据所占的比例并不会太高,把ChunkServer上的Tablet按照访问次数进行统计也发现并没有超乎想象的“大热点”,基本服从正太分布。
可见热点Tablet虽访问频率稍高对负载的贡献率相对较大,但是热点tablet的占比很低,相反所有非热点tablet对负载的贡献率总和还是很高的,这种情况就好比“长尾效应”[3]。
负载均衡算法设计
如果把热点ChunkServer上非热点Tablet的访问调度到其他Server,是可以缓解流量不均问题的,因此我们设计了新的负载均衡算法为:以实时统计的ChunkServer上所有tablet的访问次数为Ticket,每次对Tablet的读请求会选择副本中得票率最低的ChunkServer。
同时考虑到流量不均衡的第二个原因是请求的差异较大问题,ChunkServer对外提供的接口分为Get和Scan两种,Scan是扫描一个范围的所有行数据,Get是获取指定一行数据,因此两种访问方式的次数需要划分赋予不同的权重(α,β)参与最终Ticket的运算:
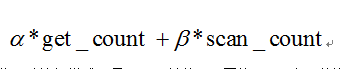
除此之外,简单的区分两种访问模式还是远远不够的,不同的Scan占用的资源也是存在较大差异的,引入平均响应时间(avg_time)这个重要因素也是十分必要的:
{kind=link}
负载均衡算法要求具有自适应性和强的实时性,一方面新的访问要实时累积参与下次的负载均衡的调度,另一方面历史权重数据则需要根据统计周期进行非线性的衰减(y 衰减因子),减少对实时性的影响:

采用新的算法后,很好的缓解了负载不均衡的问题,整体负载提升了1倍,整体QPS吞吐提升到了8w。
小结
负载均衡问题是老生常谈的问题,解决不好就会出现“短板效应”,更甚至引发分布式系统中的连锁反应即“雪崩”,从而演化成系统的灾难。负载均衡的算法也层出不穷,有的出于成本最优,有的是为了最小延迟,有的则是最大化系统吞吐,目的不同算法自然各异,不存在包治百病的良方,并不是越复杂的算法越有效[4],要综合考虑算法所需数据获取的Overhead,更多的是遵循“简单实用”的法则,根据业务场景进行分析和尝试。
正是这种灵活性的策略,对我们的系统设计提出了新的需求,要有一定的机制来监控和验证问题:比如可以实时获取系统运行的各种内部状态和数据,允许选择不同负载均衡算法进行试验等。
Update1:看到楼下网友专业方面的提问,@Leverly 已经进行了回复。有更多交流,不妨直接讨论。共享:)!
3月2日Update2:图2.2已更换(原图右边显示不完全,应为“A,E,G,H,I")。