Thread线程类基本使用(下)
前言:
前一篇文章主要介绍了如何创建新线程和如何查看Java进程中的线程信息等知识,这篇文章接着介绍关于Thread的一些构造方法及方法,这篇文章会用到Thread线程类使用(上),忘记的同学可以康康。
目录
1.Thread类常用构造方法
2.Thread类常用方法详解
2.1获取线程引用方法(currentThread())
2.2休眠线程方法(sleep)
2.3等待线程结束方法(join())
2.4中断线程信息方法(着重讲解interrupt()和isInterrupted())
1.Thread类常用构造方法
常用构造方法

其中前两种构造方法我们在前一篇文章里已经使用过了,这两种构造方法也是最基础构造方法,那我们就来着重介绍第三种和第四种构造方法。
package Boke;
public class demo1 {
public static void main(String[] args) {
//实例化对象并取名
Thread t=new Thread("我的线程");
t.start();
//通过获取线程名字的方法,打印给线程取的名字
System.out.println("新线程名字为 "+t.getName());
System.out.println();
}
}
Thread(Runnable target, String name)
该方法与上一个方法类似,只不过还要传入一个实现Runable接口的实例化对象。
package Boke;
public class demo1 {
public static void main(String[] args) throws InterruptedException {
//使用匿名内部类的方法
Thread t2=new Thread(new Runnable() {
@Override
public void run() {
System.out.println("新线程创建成功");
}
},"我的线程");
t2.start();
Thread.sleep(1000);
System.out.println("新线程名字为 "+t2.getName());
}
}
2.Thread类常用方法详解
2.1获取线程引用方法(currentThread())

这个方法是Thread类中的静态方法,用于获取当前线程对象的的引用,那有的同学可能要杠了,使用this不就直接代表的是当前对象的引用吗?当然这没错,但是如果我们以实例化Runable对象的方式创建对象,那此时this就代表的不是线程引用。而是Runable对象的引用,所以为了这种情况的发生,我们统一使用currentThread()方法就万无一失了。
2.2休眠线程方法(sleep)
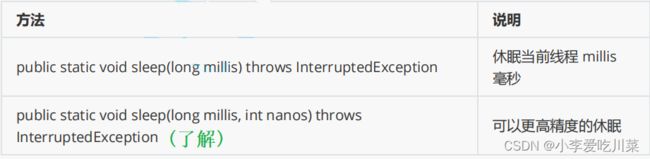
该方法的目的是让调用该方法的线程进入阻塞状态,说到诸塞状态,那不得不说一下操作系统是如何控制线程的参与就绪调度与阻塞 的。

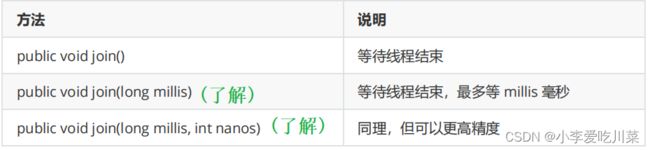
2.3等待线程结束方法(join())
package HUZ;
public class demo1 {
public static int a=0;
private static final long COUNT = 20_0000_0000;
public static void main(String[] args) {
serial();
concurrency();
}
// 1. 单个线程, 串行的, 完成 20 亿次自增.
// 2. 两个线程, 并发的, 完成 20 亿次自增.
private static void serial() {
// 需要把方法执行的时间给记录下来.
// 记录当前的毫秒级时间戳.
long beg = System.currentTimeMillis();
int a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
a = 0;
for (long i = 0; i < COUNT; i++) {
a++;
}
long end = System.currentTimeMillis();
System.out.println("单线程消耗的时间: " + (end - beg) + " ms");
}
private static void concurrency() {
long beg = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
a++;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
a++;
}
});
t1.start();
t2.start();
try {
//通过调用join方法让主线程等待t1和t1线程都结束
//先后调用顺序没事
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("并发执行的时间: " + (end - beg) + " ms");
}
}

首先,通过上述结果可知对于同一任务,多线程的确有减少时间的作用,观察代码,我们为什么要在多线程处理的方法里加入t1.join()和t2.join呢?原因是因为线程之间是"并发执行的",所以说主线程main在往下执行的过程中,线程t1和t2都在执行,所以为了防止t1和t2还没结束,主线程就已经向下执行到获取当前时间的函数那里从而导致测量时间不准的尴尬场景,我们通过让主线程调用join(),让我们的主线程在t1和t2线程结束之前进入阻塞状态,然后再测量此时的时间就是准确的,拿那这两句代码具体含义是什么呢?首先线程t1,t2哪个先结束我们是不知道的,那第一种情况t1先结束,那执行到t1.join时也就对应t1.join结束,随后执行t2.join对主线程产生阻塞,最后计算的时间就是t2.join完成后的时间,反之则相反。
实例2
通过join方法实现新线程t2等待t1,mian主线程等待新线程t2
package Boke;
public class join {
public static void main(String[] args) {
System.out.println("主线程main,begin");
Thread t1=new Thread(()->{
System.out.println("线程t1,begin");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程t1,end");
});
t1.start();
Thread t2=new Thread(()->{
System.out.println("线程t2,begin");
try {
//让t2等待t1结束,就在线程t2中调用t1.join
t1.join();
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程t2,end");
});
t2.start();
// //让主线程等待t2结束,就在主线程中调用t2.join
try {
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("主线程main,end");
}
}
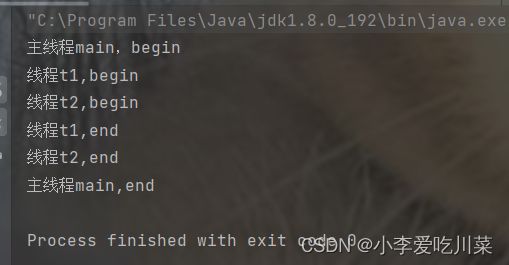
案例小结
如案例所示,如果想让某一个线程结束之前必须需等待另外一个线程执行结束之后才能执行结束,那么只需要在"被迫等待"的线程中让(要等待的线程调用join方法即可)例如我想要main主线程等待某一个自定义线程thread1结束之后才能结束,那么我只需要在main主线程中让thread1线程调用join()方法。
实例3
在案例2的基础上,通过join方法实现main.begin-->t1.begin-->t1.end-->t2.begin-->t2.end-->main.end这种串行的执行方式。
package Boke;
public class join2 {
public static void main(String[] args) {
System.out.println("主线程main,begin");
Thread t1=new Thread(()->{
System.out.println("线程t1,begin");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程t1,end");
});
t1.start();
//让主线程等待t1结束,就在主线程中调用t1.join
//等待t1线程执行结束后在继续执行线程T2
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
Thread t2=new Thread(()->{
System.out.println("线程t2,begin");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程t2,end");
});
t2.start();
// //让主线程等待t2结束,就在主线程中调用t2.join
try {
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("主线程main,end");
}
}

小结

2.4中断线程信息方法(着重讲解interrupt()和isInterrupted())

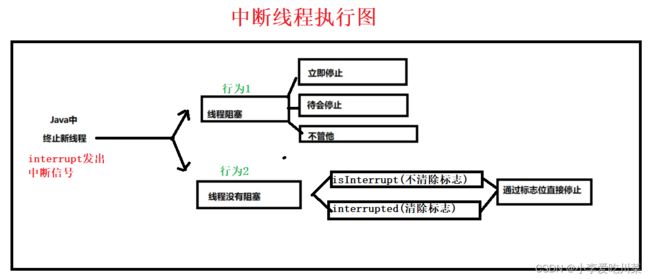
我们在线程执行的过程中,有的情况下这个线程可能触发某种危险的行为,这时候我们就想要这个线程中断停止,那我们就需要使用到intertupt()来发出中断的行为(两种行为,稍后讲),其实上我们在实际使用该方法时,一般是搭配中断标志位来一起使用的,也就是说该方法并不会直接中断线程,还要搭配Thread类中提供的获取标志位方法一起使用。
interrupt()行为1
如果主线程调用interrupt()方法时,我们的线程正处于正常的执行状态时,那interrupt()会立即修改内置的标志位。
interrupt()行为2
如果主线程调用interrupt()方法时,我们的线程正处于阻塞状态,那此时interrupt()方法就会让使线程产生阻塞的方法(例如sleep,join等)抛出异常,当然当异常抛出时,你可以选择处理或者不处理,这就好比你的老妈让你好好学习,但是到底是继续玩游戏还是开始学习这完全由你自己决定,这样子的好处就是线程代码是否退出的决定权给到了线程,我们就可以自己决定是否马上退出,稍后退出,还是不退出。
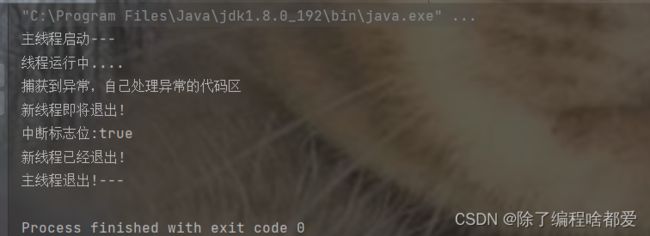
代码示例(清楚标记(isInterrupted))
public class demo4 {
public static void main(String[] args) throws InterruptedException {
System.out.println("主线程启动---");
Thread t = new Thread(() -> {
//其中这里的Thread.currentThread()是用于获取当前线程引用的方法
//以下判断"线程的中断标志位"使用isInterrupted来判断线程的中断标识信息
//当捕获到线程阻塞状态收到中断信息时并抛出异常时,catch语块执行通知并判断线程中断标志位仍为false
while (!Thread.currentThread().isInterrupted()) {
System.out.println("线程运行中....");
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
//interrupt产生行为并且当捕获到异常时进行代码处理的代码区域
//也就是你自己决定是退出还是继续的区域
//捕获到异常说明线程发出中断信息时该线程处于"阻塞状态"
//所以"中断标志"并未被设置为true,需要在进行依次中断通知
//才能将标志位设为true
Thread.currentThread().interrupt();
System.out.println("捕获到异常,自己处理异常的代码区");
// [1] 立即退出
// break;
System.out.println("新线程即将退出!");
// [2] 稍后退出, 此处的 sleep 可以换成任意的用来收尾工作的代码
// try {
// Thread.sleep(3000);
// } catch (InterruptedException ex) {
// ex.printStackTrace();
// }
// break;
// [3] 不退出! 啥都不做, 就相当于忽略了异常.
// [4]不退出,只打印一下异常原因e.printStackTrace();
System.out.println("中断标志位:"+Thread.currentThread().isInterrupted());
}
}
System.out.println("新线程已经退出!");
});
t.start();
Thread.sleep(1000);
//给线程t发送中断信息
t.interrupt();
t.join();
Thread.sleep(2000);
System.out.println("主线程退出!---");
}
} 代码示例(清楚标记(interrupted))
代码示例(清楚标记(interrupted))
public static void main(String[] args) throws InterruptedException {
System.out.println("主线程启动---");
Thread t = new Thread(() -> {
//其中这里的Thread.currentThread()是用于获取当前线程引用的方法
//以下判断"线程的中断标志位"使用interrupted来判断线程的中断标识信息
//当捕获到线程阻塞状态收到中断信息时并抛出异常时,catch语块执行通知并判断线程中断标志位会被清除(true变为false)
while (!Thread.currentThread().isInterrupted()) {
System.out.println("线程运行中....");
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
//interrupt产生行为并且当捕获到异常时进行代码处理的代码区域
//也就是你自己决定是退出还是继续的区域
//捕获到异常说明线程发出中断信息时该线程处于"阻塞状态"
//所以"中断标志"并未被设置为true,需要在进行依次中断通知
//才能将标志位设为true
Thread.currentThread().isInterrupted();
System.out.println("捕获到异常,自己处理异常的代码区");
// [1] 立即退出
// break;
System.out.println("新线程即将退出!");
// [2] 稍后退出, 此处的 sleep 可以换成任意的用来收尾工作的代码
// try {
// Thread.sleep(3000);
// } catch (InterruptedException ex) {
// ex.printStackTrace();
// }
// break;
// [3] 不退出! 啥都不做, 就相当于忽略了异常.
// [4]不退出,只打印一下异常原因e.printStackTrace();
System.out.println("中断标志位:"+Thread.currentThread().isInterrupted());
}
}
System.out.println("新线程已经退出!");
});
t.start();
Thread.sleep(1000);
//给线程t发送中断信息
t.interrupt();
t.join();
Thread.sleep(2000);
System.out.println("主线程退出!---");
}
isTnterrupt()和interrupted()的区别
关于两种设置标志位的方法isTnterrupt()和interrupted()方法的区别虽然在面试过程中不会直接问到,且一般情况下,我们只使用前者,但是正处于学习阶段的我们还是要了解一下他俩之间的区别。
isTnterrupt:当标志位修改后,不会将标志位修改成原来的状态,也就是第一次读到的是true,当修改为false后,接下来读到的都是false。
interrupt:当标志位修改后,会将标志位修改为原来的状态,也就是第一次读到的是true,修改为false后,接下来读到的又会是true.
小结
好啦,这就是Thread线程类的基本使用,快学习起来吧!
