CBAM论文解读
代码:https://github.com/Jongchan/attention-module
CBAM:convolutional block attention module,表示卷积模块的注意力机制模块,是一种结合了空间(spatial)和通道(channel)的注意力机制模块,相比于senet只关注通道(channel)的注意力机制可以取得更好的效果。
基于传统VGG结构的CBAM模块,需要在每个卷积层后面加该模块。

channel attention module:通道注意力模块
特征的每一个通道都表明一个专门的检测器,所以,通道注意力是关注什么样的特征是有意义的,为了汇总空间特征,作者采用了全局平均池化和最大池化两种方式来分别利用不一样的信息。
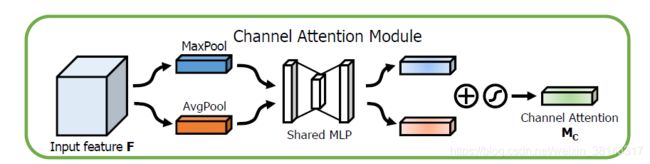
将输入的特征图input feature F: C*H*W,分别经过maxpool和avgpool得到两个C*1*1的通道描述。,然后分别经过MLP(MLP是一个两层的神经网络,第一层神经元个数为C/r,激活函数为Relu,第二层神经元个数为C.这两个层的神经网络是共享的),将MLP输出的特征进行基于elementwise的加和操作(由一系列的实验可得,element-wise summation 即逐元素相加perform是最好的),再经过sigmoid激活操作,生成最终的channel attention 特征图M_c。将该channel attention 特征图M_c和input feature F做elementwise的乘法操作,生成缩放后的新特征,这个新特征为spatial attention 模块需要的输入特征。

空间注意力模块
在通道注意力模块以后,咱们再引入空间注意力模块来关注哪里的特征是有意义的。与通道注意力类似,给定一个输入的特征图input feature F‘: C*H*W,先分别进行一个通道维度的平均池化和最大池化获得两个1*H*W的通道描述,并将这两个描述按照通道拼接在一块儿,而后,通过一个7*7的卷积层,激活函数为sigmoid,获得权重系数M_s.最后拿权重系数和输入特征图F'相乘便可获得缩放后的新特征。
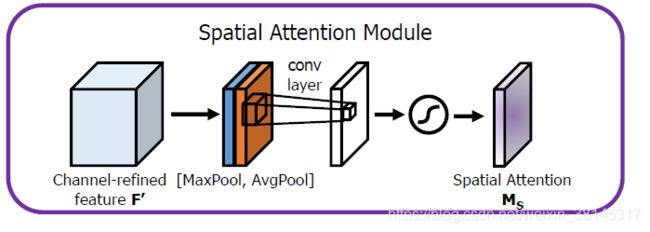
将channel attention 模块输出的特征图作为本模块的输入特征图,首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel做concat操作,然后经过一个卷积操作,降维为1个channel,再经过sigmoid生成spatial attention feature.最后将该feature和该模块的输入feature做乘法,得到最终生成的特征
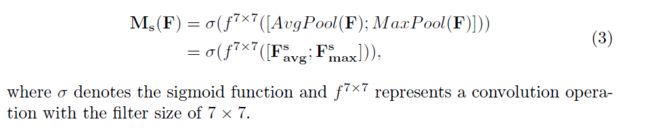
7*7的卷积核比3*3的卷积核效果更好。
两个注意力通道的组合形式
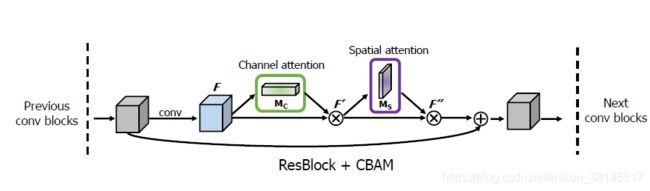
通道注意力和空间注意力这两个模块能够以并行或者顺序的方式组合在一块儿,课时作者发现顺序组合而且将通道注意力放在前面能够取得更好的效果。
实验结果
CBAM与ResNet网络结构组合
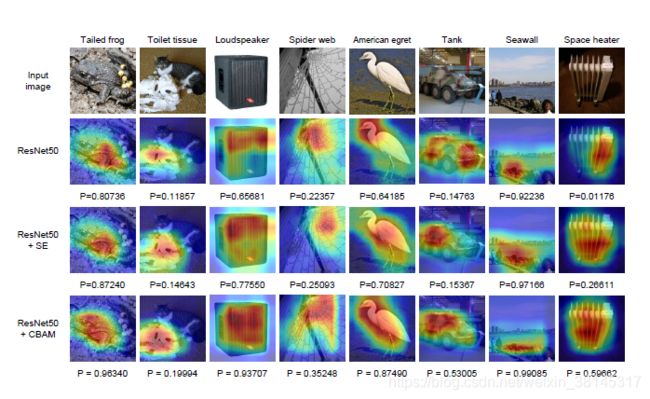
利用Grad-CAM对不一样的网络进行可视化后,能够发现,引入CBAM后,特征覆盖到了待识别物体的更多部位,而且最终判别物体的几率也更高,这代表注意力机制的确让网络学会了关注重点信息。
结论:
引入CBAM能提升目标检测和物体分类的精度,所以能够在神经网络中引入这一机制,并且花费的计算开销和参数大小都比较少。
代码实现:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16):
super().__init__()
self.maxpool=nn.AdaptiveMaxPool2d(1)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.se=nn.Sequential(
nn.Conv2d(channel,channel//reduction,1,bias=False),
nn.ReLU(),
nn.Conv2d(channel//reduction,channel,1,bias=False)
)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result=self.maxpool(x)
avg_result=self.avgpool(x)
max_out=self.se(max_result)
avg_out=self.se(avg_result)
output=self.sigmoid(max_out+avg_out)
return output
class SpatialAttention(nn.Module):
def __init__(self,kernel_size=7):
super().__init__()
self.conv=nn.Conv2d(2,1,kernel_size=kernel_size,padding=kernel_size//2)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result,_=torch.max(x,dim=1,keepdim=True)
avg_result=torch.mean(x,dim=1,keepdim=True)
result=torch.cat([max_result,avg_result],1)
output=self.conv(result)
output=self.sigmoid(output)
return output
class CBAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,kernel_size=49):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(kernel_size=kernel_size)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
residual=x
out=x*self.ca(x)
out=out*self.sa(out)
return out+residual
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)#经过CBAM注意力模块后,输入维度保持不变